リレーショナルデータベースを簡単・迅速に実現。 Amazon RDS をグラレコで解説
2022-07-04 | Author : 米倉 裕基 (監修 : 新久保 浩二)

はじめに
builders.flash 読者のみなさん、こんにちは ! テクニカルライターの米倉裕基と申します。
本記事では、6 種類の人気のデータベースエンジンを簡単にセットアップ、運用、スケールできるマネージドリレーショナルデータベースサービス「Amazon Relational Database Service (RDS)」をご紹介します。
Amazon RDS (以下、RDS) では、AWS マネジメントコンソール上で数回クリックするだけで使い慣れたデータベースエンジンをクラウド上にデプロイできます。導入や運用が簡単な RDS は、新規で DB サーバーの構築を検討する場合であっても、既存の DB サーバーをクラウドに移行する場合であっても、有力な選択肢になるでしょう。
本記事では、RDS の主な機能と特徴を順番に見ていきます。
※ 本連載では、様々な AWS サービスをグラフィックレコーディングで紹介する awsgeek.com を、日本語に翻訳し、図の解説をしていきます。awsgeek.com は 、Jerry Hargrove 氏が運営しているサイトです。
builders.flash メールメンバー登録
RDB と NoSQL の違いとは ?
DB サーバーを検討する際は、さまざまなデータベースエンジンの種類と特徴を理解した上で、ユースケースに応じて最適なエンジンを選択することが重要です。ここでは、RDS 独自の機能を紹介する前に、主だったデータベースエンジンの種類と特性を簡単に説明します。
従来から使われてきた RDB (リレーショナルデータベース) に加え、近年は RDB よりもスキーマ (データ構造) の自由度が高い NoSQL (非リレーショナルデータベース) と呼ばれるデータベースエンジンも広く使われています。
RDB と NoSQL のどちらがより優れているというものではなく、ユースケースによって適したデータベースは異なります。
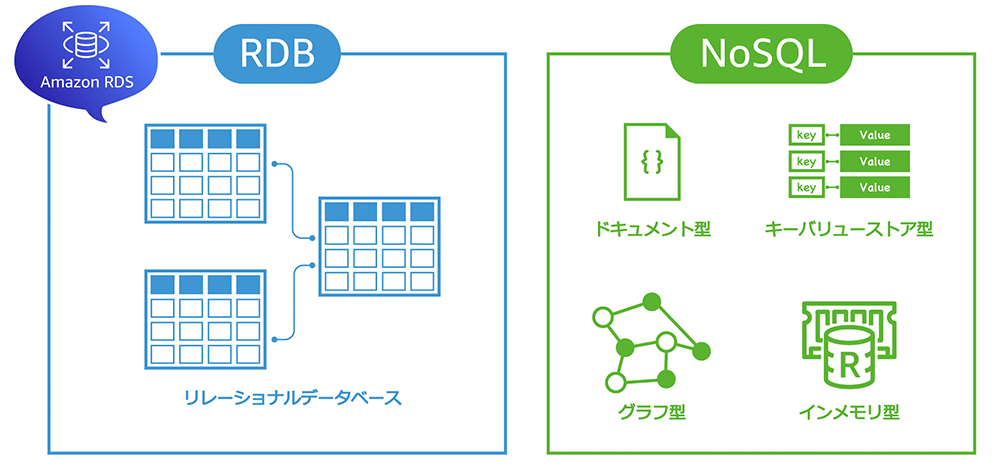
特徴とユースケース
AWS では、RDS が提供するリレーショナルデータベースサービスの他に、NoSQL データベースも複数のサービスを提供しています。たとえば、キーバリューストア型の「Amazon DynamoDB」、ドキュメント型の「Amazon DocumentDB」、グラフ型 の「Amazon Neptune」、インメモリ型の「Amazon MemoryDB for Redis」などは、AWS が提供する代表的な NoSQL データベースサービスです。
AWS が提供する RDB および NoSQL データベースサービスの特徴とユースケースは以下のとおりです。それぞれの特徴を踏まえて、最適なデータベースを選択するための参考にしてください。
|
データベースの種類 |
AWS サービス名 |
特徴 |
ユースケース |
|
|
RDB
|
Amazon RDS |
行と列からなる表形式でデータを管理します。複数の表 (テーブル) の関係性 (リレーション) を定義することで、高度なデータの管理・検索が可能です。データの一貫性や整合性を重視した設計になっており、堅牢なシステムを構築する場合に向いています。 |
- 従来のアプリケーション
|
|
|
NoSQL
|
キーバリュー型 |
Amazon DynamoDB |
キー (データの識別子) とバリュー (データ) の組み合わせでデータを格納するデータモデル。不定型なデータを高速に処理するケースに向いています。 |
- トラフィックの多いウェブアプリケーション
|
|
ドキュメント型 |
Amazon DocumentDB |
JSON データの保存、クエリ、およびインデックスなど、ドキュメントの管理に最適化されたデータベースです。 |
- コンテンツ管理
|
|
|
グラフ型 |
Amazon Neptune |
「ノード」「エッジ」「プロパティ」「ラベル」の4つの要素で構成されるグラフにデータを格納します。データとデータのつながりをグラフとして管理します。 |
- 不正検出
|
|
|
インメモリ型 |
Amazon MemoryDB for Redis |
データをメモリ上に保存するデータベースです。永続的なデータの保存には向かないが、データへの超高速なアクセスが可能です。 |
- キャッシュ
|
2022 年 6 月号の builders.flash では「高速で柔軟な NoSQL データベースサービス。Amazon DynamoDB をグラレコで解説」と題して Amazon DynamoDB の紹介記事を掲載しています。RDB と NoSQL の違いをさらに理解しやすくするために、本記事と合わせてご覧ください。
本記事では、RDS の主な機能や特徴を以下の項目に分けてご説明します。
-
エンジン
-
インスタンス
-
ストレージ
-
バックアップ
-
セキュリティ
-
マルチ AZ 配置
-
リードレプリカ
-
料金
それでは、項目ごとに詳しく見ていきましょう。
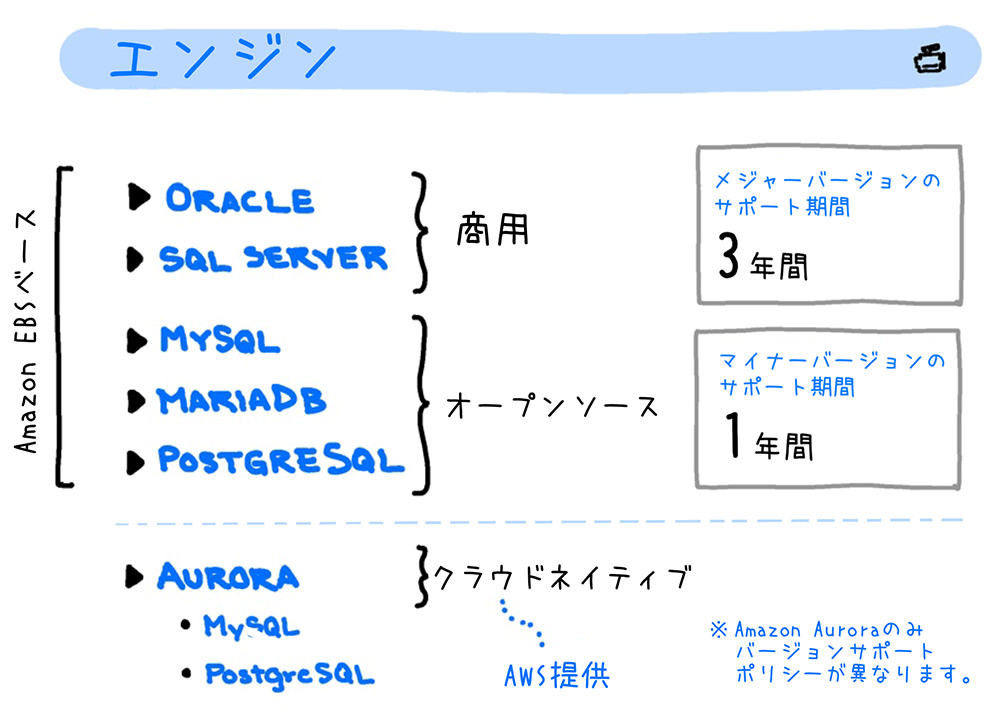
エンジン
RDSでは、商用、オープンソースを問わず、以下の 6 種類のデータベースエンジンが利用できます。
AWS マネジメントコンソールでデータベースを作成する際には、現在作成可能なバージョンをプルダウンから選択できます。
インスタンス
RDS DB インスタンスの CPU 、メモリ、ネットワークキャパシティーなどのパフォーマンスは、インスタンスクラスを選択することで決定されます。
RDS では、「バースト可能クラス」、「標準クラス」、「メモリ最適化クラス」の 3 種類のインスタンスクラスをサポートしています。ユースケースに合わせて最適なインスタンスクラスを選択します。

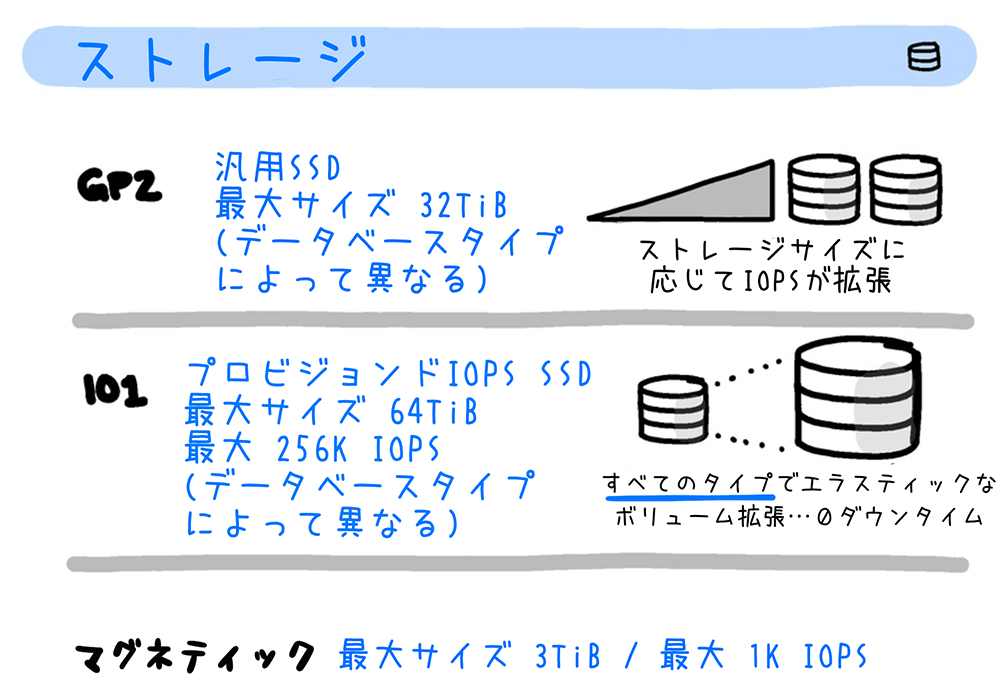
ストレージ
RDS では、汎用 SSD (gp2)、プロビジョンド IOPS SSD (io1) 、およびマグネティックの 3 種類のストレージタイプを提供しています。データサイズと I/O のパフォーマンス、および料金を比較して、最適なストレージタイプを選択します。
ただし、Amazon Aurora では、専用に開発された分散型の共有ストレージアーキテクチャを利用するため、以下で説明する gp2、io1 など EBS ベースのストレージタイプを利用しません。Amazon Aurora のストレージについて詳しくは、「Amazon Aurora ストレージと信頼性」をご覧ください。
ストレージサイズと IOPS
同じストレージタイプでも、データベースエンジンによって割り当て可能なストレージサイズや IOPS (読み込み / 書き込み性能) が異なります。
データベースエンジンごとの割り当て可能なストレージサイズや IOPS は、AWS マネジメントコンソールで確認できます。
RDS のストレージは、Amazon Elastic Block Store (Amazon EBS) を使用しており、ストレージボリュームをエラスティックにスケールすることができます。
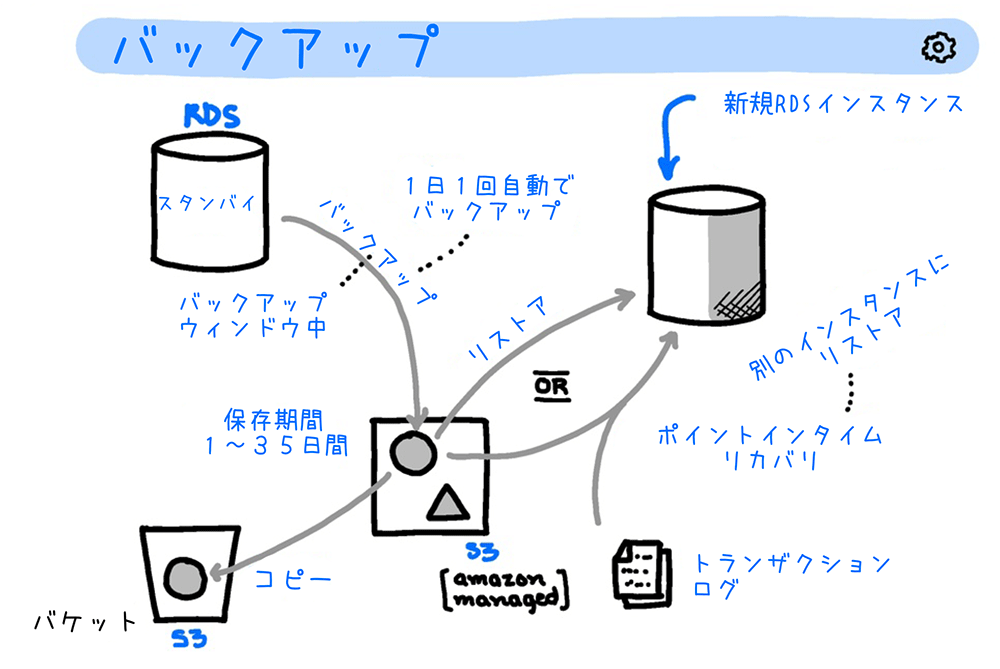
バックアップ
RDS では、データベースの意図しない変更や、障害に備えて、DB インスタンス全体をバックアップする仕組みが備わっています。バックアップデータは、指定された期間が保存され、任意のタイミングで保存時の状態のまま復元することができます。
自動バックアップ機能
RDSには、1 日に 1 回自動でインスタンスのスナップショットを取得する自動バックアップ機能があります。自動バックアップは、バックアップウィンドウ (自動バックアップが実行される時間帯) の間に実行されます。デフォルト設定では、バックアップウィンドウはリージョンごとに定められた 8 時間の時間ブロックから 30 分間がランダムに選択されますが、ユーザーが任意に設定することも可能です。
バックアップの保存期間は、1 日〜 35 日の間で選択できます。スナップショットデータは、AWS が管理する S3 バケットに保存されますが、スナップショット内のデータを任意の S3 バケットにエクスポートして分析に利用することもできます。詳しくは、ユーザーガイドの「Amazon S3 への DB スナップショットデータのエクスポート」(Amazon Aurora の場合はこちら) をご覧ください。
手動スナップショット機能
RDS では、自動バックアップ機能に加え、AWS マネジメントコンソール、AWS CLI、または RDS API を使用して、いつでも手動でスナップショットデータを保存することが可能です。1 日に 1 回の自動バックアップ以外の任意のタイミングでバックアップを実施したい場合に、手動スナップショットを実行します。
手動スナップショットについて詳しくは、ユーザーガイドの「DB スナップショットの作成」(Amazon Aurora の場合はこちら) をご覧ください。
スナップショットデータのリストア
取得したスナップショットデータのリストア (復元) は、AWS マネジメントコンソールで復元したいスナップショットを選択するだけで簡単に行えます。数回のクリックで、DB インスタンスをスナップショット取得時の状態にリストアできます。
なお、スナップショットは新規の DB インスタンスとして復元されます。既存のインスタンスには復元されません。
ポイントインタイムリカバリ
DB インスタンスを、特定時点の状態に復元する機能です。
RDS では 5 分間隔でトランザクションログを S3 にアップロードし、DB インスタンスの状態を継続的に保持します。そのため、直近の 5 分前から自動バックアップで設定した保持期間 (最大 35 日前) までの特定時点の状態まで DB インスタンスを復元できます。
ポイントインタイムリカバリは、スナップショットデータのリストアと同様、新規の DB インスタンスに DB クラスタを復元します。ただし、Amazon Aurora (MySQL 互換エディション) では、同一の DB インスタンスの状態を指定した時間まで巻き戻す DB クラスターのバックトラック という機能が提供されています。
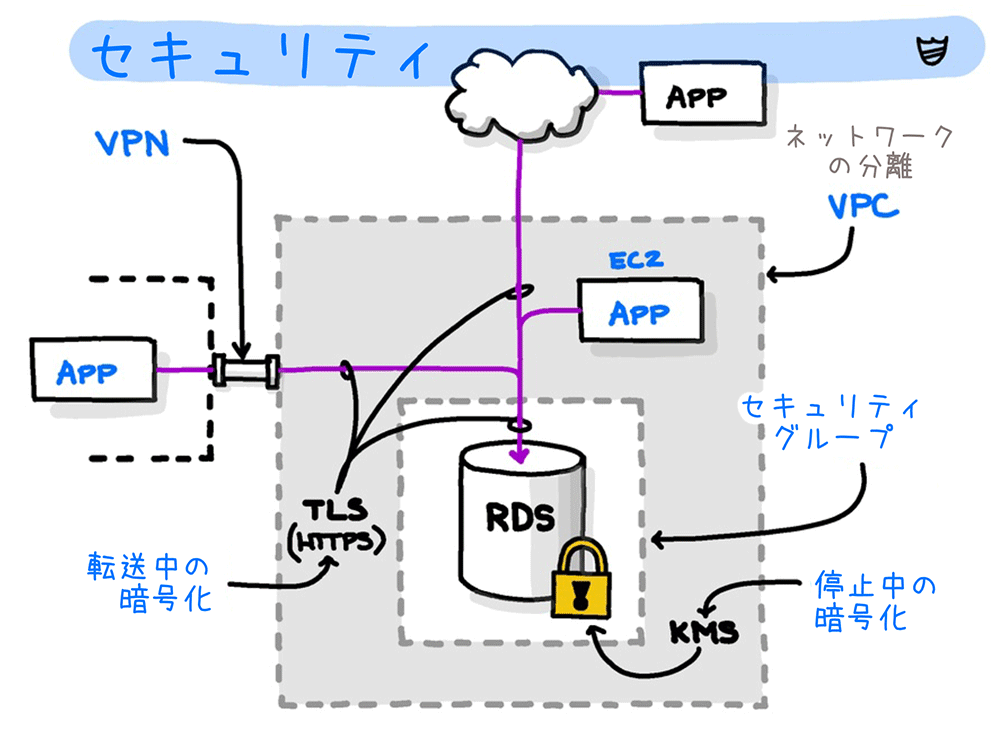
セキュリティ
RDS を含め AWS サービスを利用する上での最重要事項はセキュリティです。特に機密情報を管理することが多いデータベースのセキュリティは注意が必要です。
RDS では、 データベースへのアクセス制御と、DB インスタンス上のリソースおよび DB インスタンス自体の暗号化の両面からセキュリティを確保します。
VPC によるネットワークの分離
RDS DB インスタンスは、AWS クラウド上の他のネットワークから論理的に分離した仮想ネットワーク (Amazon VPC) 内にあります。そのため、Amazon VPC の セキュリティグループ で通信可能なトラフィックの要件を指定することで、DB インスタンスへのインバウンドトラフィック、アウトバウンドトラフィックを制御できます。
RDS のデフォルト設定では、パブリックアクセスは許可されていないため、VPC 外部のネットワークからのアクセスは遮断されます。VPC 外部のアプリケーションからプライベート RDS DB インスタンスにアクセスするには、AWS Site-to-Site VPN を使うか、Amazon EC2 インスタンスを踏み台ホスト として使います。
ネットワークとリソースの暗号化
RDS では、ストレージ内の DB インスタンス、自動バックアップ、リードレプリカ、スナップショットを AES-256 暗号化アルゴリズムで暗号化します。暗号化および復号化に使用するカスタマーマネージドキーは、AWS Key Management Service (AWS KMS) で管理できます。
また、RDS はSSL または TLS 接続をサポートしています。SSL/TLS を使って通信することで、クライアントと DB インスタンス間を転送するデータを暗号化できます。
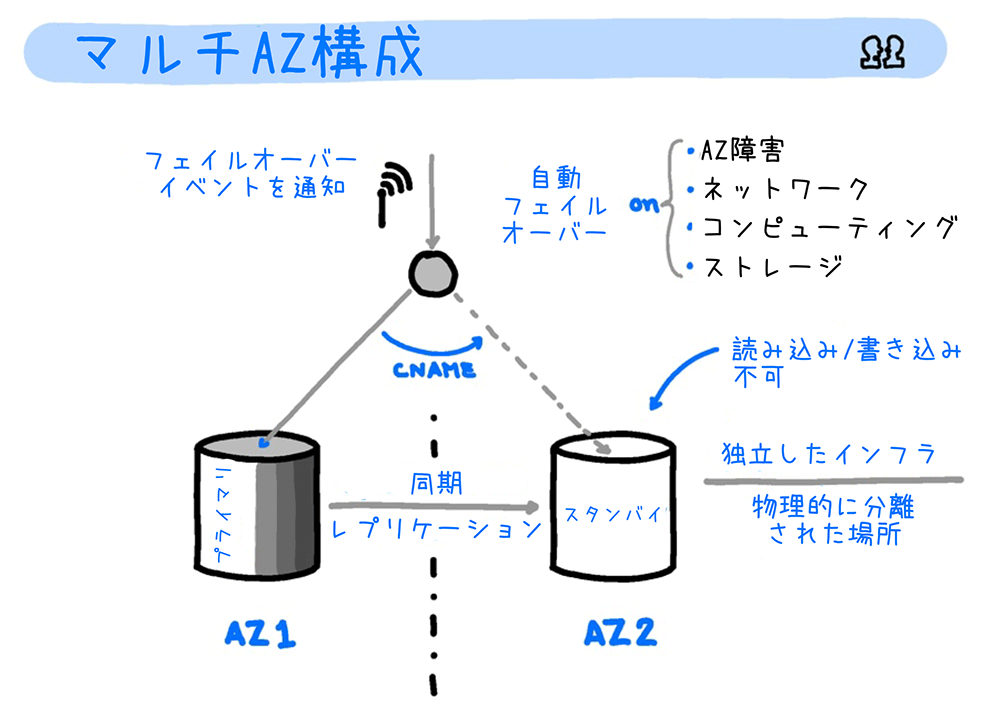
マルチ AZ 配置
マルチ AZ 配置オプションを選択した場合、データの読み書きを行うプライマリ DB インスタンスと、データが同期的にレプリケートされるスタンバイ DB インスタンスが、それぞれ別の AZ (アベイラビリティーゾーン) に配置されます。
プライマリ DB インスタンスで障害が発生すると、すぐにスタンバイ DB インスタンスを昇格させて プライマリ DB インスタンスとして稼働させることができるため、高い耐障害性と可用性を実現できます。
自動フェイルオーバー
マルチ AZ 配置では、プライマリ DB インスタンスのダウンや、メンテナンス、AZ の障害などの異常を検知すると、自動でスタンバイ DB インスタンスにフェイルオーバーする自動フェイルオーバー機能を備えています。
自動フェイルオーバーは通常 60 秒 ~ 120 秒の間 (Amazon Aurora の場合は 30 秒以内) で実行され、手動によるフェイルオーバーと比べ障害発生時のダウンタイムを短くできます。
自動フェイルオーバーは、DB インスタンスの接続ポイント名 (CNAME) を切り替えることで、スタンバイ DB インスタンスをプライマリ DB インスタンスに昇格させます。
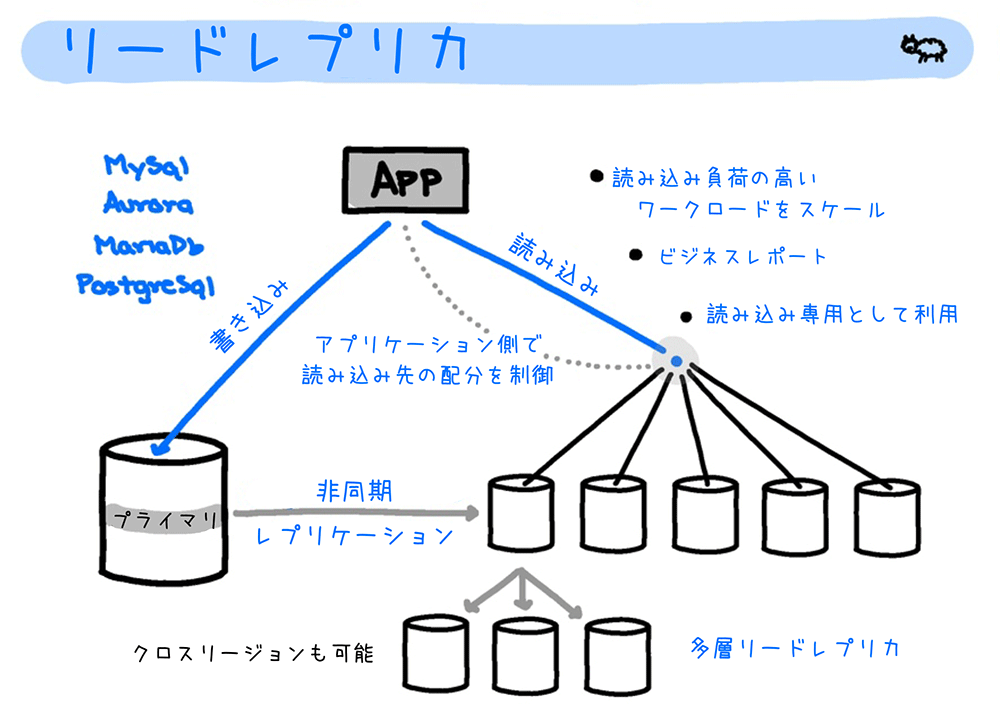
リードレプリカ
リードレプリカとは、プライマリ DB インスタンスのレプリカ (複製) DB インスタンスのことです。
リードレプリカは、読み込み専用の DB インスタンスとして機能し、書き込みは行いません。リードレプリカのデータは、プライマリ DB インスタンスから非同期にレプリケート (コピー) することで更新されます。
スケーラビリティの向上
予備の DB インスタンスを作成するという点では、リードレプリカは マルチ AZ 配置と類似したオプションと言えます。ただし、マルチ AZ 配置の役割が耐障害性と可用性の向上であるのに対し、リードレプリカの主な役割は読み込み処理量のスケールアウトです。
リードレプリカは、読み込み頻度の高いワークロードを、最大 5 台 (Amazon Aurora の場合は 15 台) のリードレプリカで負荷分散することで、パフォーマンスを維持します。
リードレプリカについて詳しくは、RDS ユーザーガイドの「リードレプリカの使用」をご覧ください。
多層リードレプリカ
MySQL、MariaDB および PostgreSQL を使用している場合、リードレプリカからさらに 2 層目のリードレプリカを作成できます。多層的にリードレプリカを作成することで、1 層目のリードレプリカの負荷を 2 層目のリードレプリカに分散することができます。リードレプリカは、最大 3 層目まで作成できます。PostgreSQL による多層リードレプリカのサポートは、2022 年 5 月にサポートが開始されたばかりです。詳しくは こちら をご覧ください。
※ 2022 年 7 月現在、Amazon Aurora、Oracle、SQL Server では多層リードレプリカはサポートされていません。
クロスリージョンリードレプリカ
クロスリージョンレプリケーションとは、複数のリージョン間でデータをレプリケートし、データの冗長化を実現する機能です。RDS では、プライマリ DB インスタンスとは異なる AWS リージョンにリードレプリカを作成することで、クロスリージョンレプリケーションを構成できます。
クロスリージョンリードレプリカを作成することで、災害対策ソリューションの確保、データベースの読み込みワークロードのスケーリング、およびリージョン間での DB インスタンスの移行が容易になります。
クロスリージョンリードレプリカは、Amazon Aurora (MySQL 互換エディション)、MariaDB、MySQL、Oracle、PostgreSQL で作成できます。2022 年 7 月現在、SQL Server ではサポートされていません。クロスリージョンリードレプリカについて詳しくは、「別の AWS リージョンでのリードレプリカの作成」をご覧ください。
なお、クロスリージョンリードレプリカと類似した機能として、Amazon Aurora (MySQL および PostgreSQL 互換エディション) の場合、複数のリージョンをまたぐ DB レプリカインスタンスを構成するグローバルデータベースを作成できます。グローバルデータベースについて詳しくは、「Amazon Aurora Global Database の使用」をご覧ください。
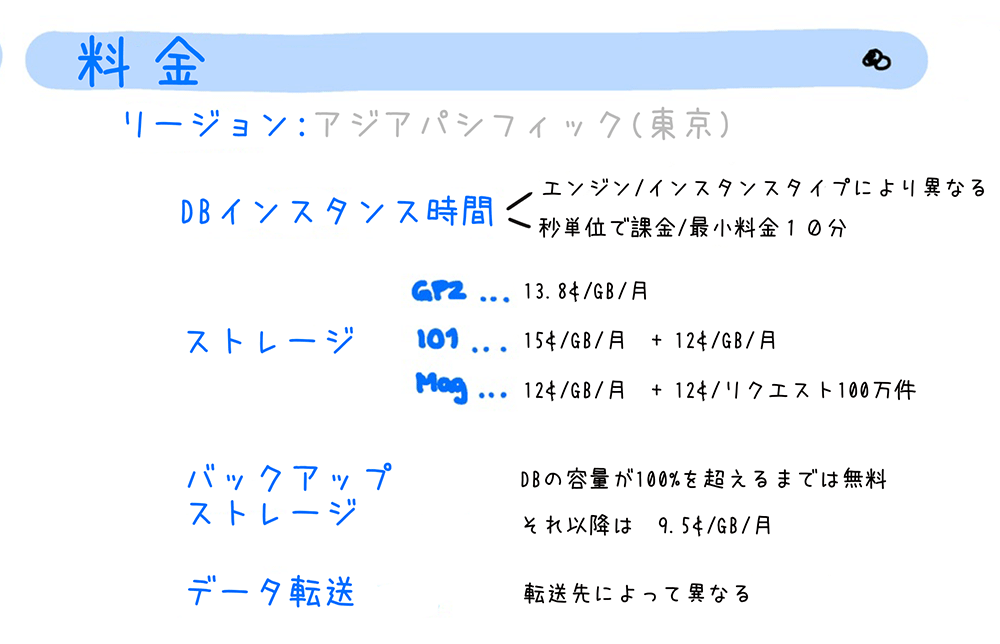
料金
RDB の利用料金は、 DB インスタンスや、データベースストレージ、バックアップストレージ、バックトラック、スナップショットのエクスポート、データ転送などに対して課金されます。
他の AWS サービスと同様、リージョンによって単価が異なります。図内の料金は、「アジアパシフィック (東京)」リージョンのものです。
DB インスタンス
DB インスタンスの利用料金は、1 秒ごとに課金され、10 分未満の場合は 10 分の料金が発生します。料金単価は、データベースエンジンの種類と DB インスタンスクラス (db.t3.micro や db.m4.large など) により異なります。
データベースストレージ
ストレージの種類によって異なる単価で課金されます。
- 汎用 SSD ストレージ (gp2) :
月当たりのストレージ容量 (GiB) に従って課金されます。 - プロビジョンド IOPS ストレージ (io1) :
月当たりのストレージ容量 (GiB)と、プロビジョンドされた IOPS (読み込み / 書き込み処理量) に対して課金されます。 - マグネティックストレージ :
月当たりのストレージ容量 (GiB)と、I/O (書き込み/読み込み) に対して課金されます。
Amazon Aurora は、「ストレージ」で述べたとおり gp2 や io1 など EBS ベースのストレージではなく、専用の Aurora ストレージを利用します。Aurora ストレージは、GB / 月単位で、I/O 消費量は 100 万件のリクエストごとに課金されます。
バックアップストレージ
バックアップストレージとは、自動バックアップや、手動スナップショットで取得したバックアップデータを保存するストレージです。バックアップストレージの使用料は、データベースストレージの使用量が 100% を超えるまでは発生しません。100% を超えた時点で、バックアップに使用したストレージ容量が月単位で課金されるようになります。
データ転送
RDS へのデータ受信、および RDS からのデータ送信に対して課金されます。
インターネットから RDS へのデータ受信、RDS からインターネットへのデータ送信、RDS から別の AWS サービスへのデータ転送によって料金単価は異なります。
バックトラックや、スナップショットのエキスポートなどその他の料金体系について詳しくは、「Amazon RDS の料金」ページから対象のエンジンを選択して料金表をご参照ください。
まとめ
前述のとおり、ユースケースに応じて最適なデータベースを選択するには、データベースごとの特徴と相違点をよく理解することが重要です。本グラレコ記事では、RDB と NoSQL の比較と RDS ならではの機能を 8 つの項目に分けてご紹介しました。
データベースのセットアップ・運用・スケーリングは手間がかかるだけでなく、わずかなミスがビジネスに直結するミッションクリティカルな作業です。その点 RDS は、マネージドリレーショナルデータベースサービスとして、負荷分散やバックアップ、OS のパッチ適用などの処理を AWS 側に任せることができます。
本記事を読んで RDS に興味を持たれた方、実際に使ってみたいと思われた方は、ぜひ製品ページの「Amazon RDS」も合わせてご覧ください。
全体図
最後に、全体の図を見てみましょう。
著者プロフィール / 監修者プロフィール

米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。
趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。
現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

新久保 浩二
アマゾン ウェブ サービス ジャパン合同会社
シニアソリューションアーキテクト データベーススペシャリスト
20 年以上データベース (特に RDBMS) 関連の開発、プリセールス、コンサルタントとしてビジネスに携わってきました。現在は、AWS でデータベースを利用される際の支援やチューニング、最適化などを主に担当しています。趣味は自宅近くの海で、まったりと🍺を飲むことです。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages