データサイエンスと人工知能の違いとは?
データサイエンスと人工知能の違いとは?
データサイエンスと人工知能 (AI) はどちらも、デジタルデータの理解と使用に関連する方法と技法の総称です。現代の組織は、人間の生活のあらゆる側面について、さまざまなオンラインシステムや物理システムから情報を収集しています。テキスト、オーディオ、動画、画像のデータを大量に入手できます。データサイエンスは、統計ツール、方法、テクノロジーを組み合わせて、データから意味を生み出します。人工知能はこれをさらに一歩進め、そのデータを使用して、学習、パターン認識、人間のような表現など、人間の知能に一般的に伴う認知問題を解決します。これは、進むにつれて「学習」する複雑なアルゴリズムの集まりであり、時間が経つにつれて問題の解決が上手になります。
データサイエンスと人工知能の類似点
AI とデータサイエンスの両方に、大量のデータを分析して利用するためのツール、手法、アルゴリズムが含まれています。以下はいくつかの類似点です。
予測アプリケーション
人工知能とデータサイエンステクノロジーはどちらも、以前のデータを分析する際に学習したモデルと方法を適用した結果として、新しいデータに基づいて予測を行います。たとえば、前年のデータに基づいて将来の月次傘の売上を予測することは、データサイエンスにおける時系列データ分析の一例です。
同様に、自動運転車も予測型人工知能システムの一例です。自動運転車が道路を走っているとき、前方の車までの距離と両方の車の速度を計算します。前方の車が急ブレーキをかけることを予測して、衝突を避けられる速度で速度を保ちます。
データ品質要件
AI とデータサイエンステクノロジーはどちらも、トレーニングデータに一貫性がなかったり、偏っていたり、不完全だったりすると、結果の精度が低下します。たとえば、データサイエンスと AI アルゴリズムは次のような場合があります。
- 新しいデータが完全に新しいもので、元のデータセットに含まれていない場合は、そのデータを除外します。
- 入力データにばらつきがない場合は、データセット内の特定の属性を他の属性よりも優先します。
- 入力データが誤っていたため、存在しない情報や架空の情報を作成します。
機械学習
機械学習 (ML) は、データサイエンスと AI の両方のサブタイプと見なされています。つまり、すべての ML モデルはデータサイエンスモデルと見なされ、すべての ML アルゴリズムも AI アルゴリズムと見なされます。すべての AI が ML を使用しているという誤解はよくありますが、そうではありません。複雑な AI ソリューションでは、ML が必ずしも必要というわけではありません。同様に、すべてのデータサイエンスソリューションに機械学習が含まれるわけではありません。
主な違い:データサイエンスと人工知能の比較
データサイエンスには、データを分析して、予測を行うための基礎となるパターンと関心点を特定することが含まれます。応用データサイエンスは、データ分析で使用されるモデルと方法を現実世界の状況の新しいデータに適用して、確率的な出力を提供します。これとは対照的に、AI は応用データサイエンス技術やその他のアルゴリズムを使用して、人間の知能に近い複雑な機械ベースのシステムを構成して実行します。
データサイエンスは、AI やコンピューターサイエンス以外のアプリケーションでも使用できます。
目標
データサイエンスの目標は、既存の統計的および計算的モデルと方法を適用して、収集されたデータに含まれる関心のある点やパターンを理解することです。結果は事前に決定されており、最初から簡単に定義できます。たとえば、データを使用して将来の売上を予測したり、機械の修理準備が整った時期を特定したりできます。
AI の目標は、コンピューターを使用して、人間のインテリジェントな推論と見分けがつかない複雑な新しいデータから結果を生み出すことです。たとえば、クリエイティブなテキストを生成したり、テキストから画像を生成したりするなど、結果は一般的で定義が困難です。問題セットの詳細が大きすぎて正確に定義できず、AI システムが問題を単独で解釈します。
スコープ
結果があらかじめ決まっているため、データサイエンスの範囲は狭くなります。このプロセスは、データから回答できる質問を特定することから始まります。対象範囲には以下が含まれます。
- データ収集と前処理。
- これらの質問に答えるために、適切なモデルとアルゴリズムをデータに適用します。
- 結果の解釈。
これとは対照的に、AI の範囲ははるかに広く、解決する問題によって手順が異なります。このプロセスは、人間がうまく実行し、機械に複製させたい労働集約的な手動タスクまたは複雑な推論タスクを特定することから始まります。範囲には以下が含まれる場合があります。
- 予備データ解析。
- タスクをアルゴリズムコンポーネントに分割してシステムを形成します。
- テストデータを収集して、ロジカルフローの適合性とシステムの複雑さを確認および調整します。
- システムのテスト。

Methods
データサイエンスには、データをモデル化するためのさまざまな手法があります。正しいテクニックを選択するかどうかは、データと提示される質問によって異なります。これらには、線形回帰、ロジスティック回帰、異常検出、二項分類、k-means クラスタリング、プリンシパルコンポーネント分析などが含まれます。統計分析を誤って適用すると、予期しない結果が生じます。
AI アプリケーションは通常、複雑で事前に構築された製品化されたコンポーネントに依存しています。これらには、顔認識、自然言語処理、強化学習、知識グラフ、生成系人工知能 (生成 AI ) などが含まれます。
用途:データサイエンスと人工知能の比較
データサイエンスは、特定の質問に答えるのに役立つ十分な品質データとモデルがあればどこでも適用できます。アプリケーションには以下が含まれます:
- 需要予測。
- 不正検出。
- スポーツオッズ。
- リスク評価。
- エネルギー消費量の予測。
- 収益の最適化。
- 候補者のスクリーニングプロセス。
AI アプリケーションはほぼ無限です。一般的なアプリケーションには以下が含まれます。
- ロボット生産ライン。
- チャットボット。
- バイオメトリクス認識システム。
- 医用画像分析。
- 予知保全。
- 都市計画。
- マーケティングパーソナライゼーション。
キャリア:データサイエンスと人工知能の比較
通常、データサイエンティストの主な焦点は、データを深く掘り下げる技術です。データサイエンティストは、データの収集と処理、データに適したモデルの選択、結果の解釈による推奨事項の作成に取り組む場合があります。作業は特定のソフトウェアやシステム内で行われる場合もあれば、システム自体を構築する場合もあります。
ロールのタイプ
データサイエンスの仕事には、データサイエンティスト、データアナリスト、データエンジニア、機械学習エンジニア、リサーチサイエンティスト、データビジュアライゼーションスペシャリスト、特定分野アナリストの役割などがあります。また、AI にはこれらすべての役割が含まれます。ただし、この分野の範囲が非常に広いため、ソフトウェア開発者、プロダクトマネージャー、マーケティングスペシャリスト、AI テスター、AI エンジニアなど、関連する役割や重点分野は他にもたくさんあります。
スキルセット
データサイエンティストは、統計的手法やアルゴリズム的手法を実用的に適用し、データを評価して分析し、関連する洞察を見つけるスキルを身につけています。データサイエンティストには、統計数学とコンピューターサイエンスのバックグラウンドと、適用可能なツールの習熟度が必要です。
AI 内での役割に応じて、必要なスキルセットは、より技術的なスキルやソフトスキルに基づく場合があります。職種によっては、技術的な経験が不要な場合もあります。たとえば、AI ソフトウェア開発者は、関連するプログラミング言語、ライブラリ、ツールに関する実践的な知識を必要とします。ただし、生成 AI ツールの AI テスターには、言語スキル、創造的思考、およびユーザーがシステムとどのようにやり取りすべきかを理解する必要があります。
キャリアアップ
データサイエンスのツールとワークフローがより自動化され、製品化されるにつれて、純粋なデータサイエンスの役割の数は減少します。純粋なデータサイエンスの役割を求めるデータサイエンスのプロフェッショナルは、学術的でエッジアプリケーションを選ぶ傾向があります。データサイエンティストがツールの運用を担当するアナリストの役割は依然として重要です。データサイエンティストは、下級職から上級職に就き、人事やプロジェクト管理に異動し、最高データ責任者に昇進することさえあります。
AI の役割そのものの焦点にもよりますが、キャリアアップも同様に期待できます。最高技術責任者、最高マーケティング責任者、最高製品責任者などに進むことができます。今後 10 年間にどの仕事が自動化されるかを批判的に考えることは、将来を見据えたキャリアの方向性を決めるのに役立ちます。
相違点の要約:データサイエンスと人工知能の比較
|
データサイエンス |
人工知能 |
|
|
内容 |
データから洞察を得るための統計モデリングとアルゴリズムモデリングの使用。 |
人工知能は、人間の知能を模倣する機械ベースのアプリケーションの広義の用語です。 |
|
こんな方に最適 |
データセットから質問に答える。 |
人工知能は、複雑な人間のタスクを効率的に完了するのに最適です。 |
|
Methods |
線形回帰、ロジスティック回帰、異常検出、二項分類、k-means クラスタリング、プリンシパルコンポーネント分析など。 |
顔認識、自然言語処理、強化学習、知識グラフ、生成 AI など。 |
|
対象範囲 |
データから回答できる事前定義された質問。 |
幅広く、定義が難しい、タスクベースです。 |
|
実装 |
さまざまなツールを使用して、データのキャプチャ、クリーニング、モデル化、分析、レポートを行います。 |
タスク依存。通常、複雑で事前に構築され、製品化されたコンポーネントに依存しています。 |
AWS はデータサイエンスと人工知能の要件にどのように役立ちますか?
AWS には、組織や個人のデータ分析とインテリジェンスの強化と成長に役立つように設計された、データサイエンスと AI の幅広い製品とサービスがあります。
これには、構造化データと非構造化データのための API ベースのデータサイエンスおよび AI モデル、およびデータサイエンスおよび AI ソリューションをエンドツーエンドで作成およびデプロイできるフルマネージド環境が含まれます。
- Amazon SageMaker Studio は、データサイエンスと ML ソリューションを開発するための専用ツールスタックを含む統合開発環境 (IDE) です。
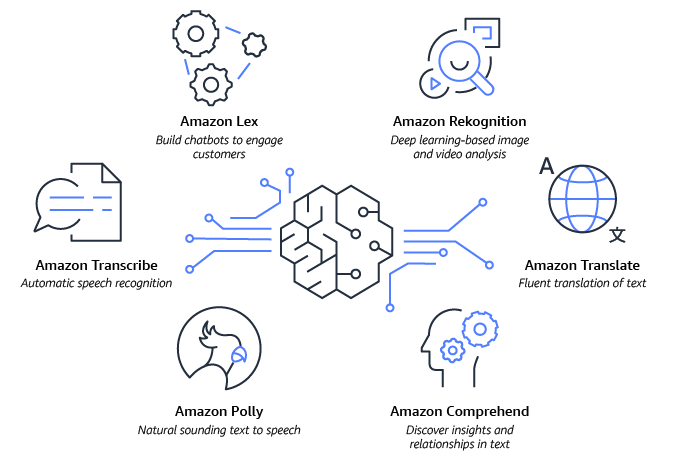
- Amazon Lex は、会話型 AI を使用して独自のチャットボットを構築するのに役立ちます。
- Amazon Rekognition は、画像と動画から情報と洞察を抽出するために、事前にトレーニングされたカスタマイズ可能なコンピュータビジョン (CV) 機能を提供します。
- Amazon Comprehend は、ドキュメント内のテキストから貴重な洞察を導き出し、理解するのに役立ちます。
- Amazon Personalize では、ML を活用してカスタマーエクスペリエンスをパーソナライズできます。
- Amazon Forecast は、時系列予測の実行に役立ちます。
- Amazon Fraud Detector は、不正検知モデルの構築、デプロイ、管理に役立ちます。
AWS では、会話、ストーリー、画像、動画、音楽などの新しいコンテンツやアイデアを生み出すことができる、世界トップクラスの生成 AI ソリューションも提供しており、そのリストは今も増え続けています。生成 AI ソリューションには以下が含まれます。
- Amazon Bedrock は、組織が生成 AI ソリューションを構築および拡張するのに役立ちます。
- AWS Trainium は、生成 AI モデルのトレーニングをより迅速に行うのに役立ちます。
- Amazon Q Developer は、ソフトウェア開発のための生成 AI 搭載アシスタントです。
今すぐアカウントを作成して、AWS で人工知能とデータサイエンスを開始しましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages