Amazon Web Services 한국 블로그
Amazon Elasticsearch Service 메모리 자동 조정(Auto-Tune) 기능 사용하기
얼마 전 Amazon Elasticsearch Service의 클러스터 리소스를 자동으로 최적화하여 성능과 가용성을 개선하기 위해 메모리 자동 조정(Auto-Tune) 기능을 출시하였습니다.
Elasticsearch는 Java Virtual Machine(JVM)에서 실행되며, 많은 수집 볼륨과 검색 워크로드를 지원하는 경우 메모리 설정 조정은 필수적입니다. 자동 조정의 적응형 시스템은 수신 워크로드 성능에 영향을 미치는 리소스 병목 현상을 식별하고 필요한 확장 및 성능을 지원하기 위해 클러스터에서 적절한 수정 작업을 수행합니다.
클러스터의 기존 노드 내에서 Elasticsearch 리소스와 메모리를 다시 크기 조정하고 다시 할당하면서 최대 클러스터 성능, 효율성 및 가용성을 보장하여 이를 달성할 수 있습니다. 예를 들어, 힙 크기, 대량 대기열 크기 및 가비지 수집 설정을 조정하면 수집 처리량을 늘릴 수 있고, 캐시 크기를 변경하면 검색의 테일 지연 시간을 개선하며, 읽기 및 대량 대기열 크기를 조정하면 검색 워크로드의 가용성을 높이고 거부 수를 줄일 수 있습니다.
이 글에서는 Amazon ES의 메모리 자동 조정 기능에 대해 자세히 살펴 보고, 사용해 보는 방법을 알려드리려고 합니다.
적응형 리소스 관리
자동 조정 기능을 통한 적응형 리소스 관리는 모든 클러스터에서 실행되는 폐쇄 루프 제어 시스템입니다. 이 시스템에 대한 입력은 Open Distro for Elasticsearch Performance Analyzer 플러그인에서 제공하는 OS, JVM 및 Elasticsearch 클러스터의 세분화 된 메트릭입니다. 이러한 메트릭은 실시간으로 처리되고 각 노드에서 로컬 평가를 수행하는 분산 의사 결정 트리에 제공됩니다.
이러한 평가의 결과는 리더 노드의 의사 결정 구성 요소에서 사용되며,이 구성 요소는 모니터링을 통해 적절한 자동 조정 작업으로 변환합니다. 시스템은 성능보다 안정성을 우선시하여 확장 가능한 탄력적인 시스템을 제공합니다. 자동 조정은 서비스의 운영 클러스터에서 얻은 학습과 커뮤니티에서 공유 한 교훈을 기반으로합니다. 다음 다이어그램은 피드백 제어 루프를 보여줍니다.
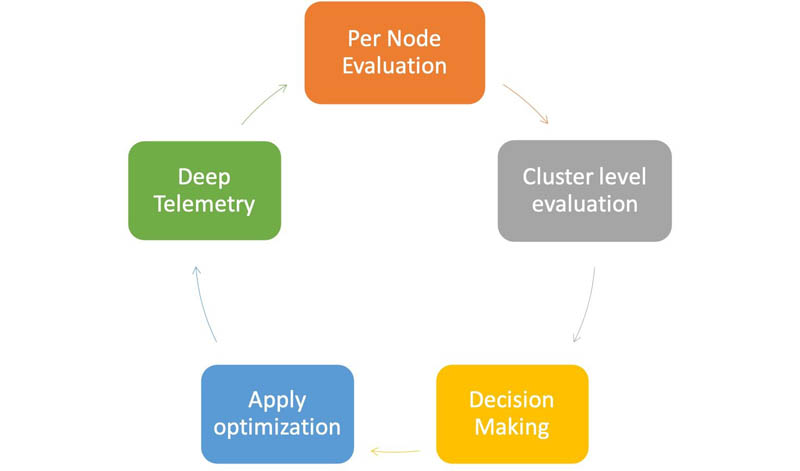
메모리 구성
자동 조정은 애플리케이션 워크로드에 맞게 다음 클러스터 리소스의 크기를 자동으로 늘리거나 줄입니다.
스레드 풀 큐 검색 및 쓰기
이상적인 큐잉 이론에서 모든 요청이 동일하고 처리하는 데 같은 시간이 걸린다면 큐는 튜닝이 거의 필요 없이 일정한 속도로 이동합니다. 실제로 실제 요청은 CPU 요구 사항, 메모리 소비 및 처리 된 데이터 양에 따라 다릅니다. 비슷한 크기의 문서를 사용한 대량 쓰기와 같은 유사한 요청조차도 스레드 스케줄링, 가비지 콜렉션 또는 세그먼트 병합과 같은 백그라운드 작업으로 인해 처리 시간이 다양할 수 있으며, CPU주기를 두고 경쟁하는 요소입니다.
실제 워크로드는 본질적으로 “폭발적”으로 일어납니다. 리소스가 충분한 클러스터에서 대기열이 클수록 거부 횟수가 줄어들고 처리량이 늘어날 수 있습니다. 반대로 메모리 및 CPU 경합으로 인해 이미 포화 상태 인 클러스터에 더 많은 요청이 있으면 시스템에 과부하가 걸립니다. 그리고, 요청이 누적되어 지연 시간이 늘어납니다. 이러한 경우 들어오는 요청을 조기에 거부하면 시스템에 대한 부담이 완화됩니다. 자동 조정 기능은 안정적인 클러스터에서 가능한 최고의 처리량을 얻기 위해 스레드 풀 대기열 크기를 모니터링하고 조정합니다. Elasticsearch 7.9 이전 버전에서 검색 및 대량 대기열의 기본값은 각각 1,000과 200입니다. 자동 조정은 수집 및 쿼리 워크로드 패턴에 따라 이러한 값을 조정합니다.
필드 데이터 캐시
필드 데이터 캐시는 힙 데이터 구조에서 텍스트 집계를 위한 필드 데이터와 키워드에 대한 글로벌 서수 매핑을 캐싱하여 집계 쿼리의 속도를 높입니다. 하지만, 구축 비용이 많이 들기 때문에 필드 데이터 캐시가 허용되는 최대 크기에 도달하지 않는 한 Elasticsearch는 자동으로 값을 제거하지 않습니다. 기본적으로 캐시는 제한되지 않습니다. 자동 조정은 캐시 크기를 적절하게 조정하여 관련 있는 경우, 더 빠른 집계를 위해 클러스터를 최적화하는 동시에 오래된 워크로드 패턴에 포함 된 귀중한 리소스를 확보합니다. 이 글을 쓰는 시점에서 필드 데이터 캐시 크기는 모든 Amazon ES 버전에서 제한되지 않습니다.
샤드 요청 캐시
샤드 요청 캐시는 샤드에서 로컬 검색 결과를 캐시하여 자주 생성되는 검색 쿼리의 속도를 높입니다. 이는 일관된 쿼리 패턴이있는 워크로드 및 롤오버 인덱스의 샤드와 같이 자주 업데이트되지 않는 샤드에 특히 유용합니다. 자동 조정은 캐시 별 메트릭을 모니터링하여 최상의 성능을 위해 요청 캐시를 최적화합니다. 샤드 요청 캐시의 기본값은 JVM 힙 크기의 1 %입니다.
JVM 생성 크기 조정
이전 버전의 Elasticsearch는 가비지 콜렉션에 CMS를 사용했습니다. 이후 버전은 G1GC로 이동했습니다. CMS 가비지 콜렉터는 세대 별 가비지 콜렉션 시스템으로, 힙 공간은 각각 수명이 짧은 개체와 수명이 긴 개체에 대해 젊은 세대와 오래된 세대로 분할됩니다. 적절한 젊은 세대와 이전 세대의 크기 비율을 구성하는 것은 워크로드의 특성과 생성되는 개체의 종류에 따라 매우 구체적 일 수 있습니다.
기본적으로 JVM은 사용 가능한 CPU 코어 수를 기반으로 내부 휴리스틱에서 이 비율을 구성합니다. 자동 조정 기능은 여러 JVM, 메모리 및 가비지 콜렉션 관련 메트릭을 모니터링하여 클러스터 메모리에 대한 적절한 비율을 결정합니다. 이러한 조정 작업에는 JVM을 다시 시작해야합니다.
JVM 힙 크기 조정
자동 조정 기능은 Elasticsearch JVM에 더 많은 힙 공간을 추가하는 것이 클러스터에 도움이되는지도 평가합니다. 이들 집합에서 힙 크기를 확장하고 가비지 컬렉션을 G1로 전환하는 것과 관련된 조정 작업 중 하나가 힙 크기가 클수록 더 잘 작동한다는 것을 확인했습니다.
캐시 지우기
마지막으로, 캐시 지우기 작업은 클러스터의 힙이 극도로 경합 될 때만 적용되는 메모리 회수 작업입니다. 이 작업은 모든 캐시를 지우고 메모리를 확보하여 클러스터를 안정화합니다.
자동 조정 기능 시작하기
Amazon ES의 AWS 관리 콘솔 , AWS Command Line Interface (AWS CLI) 또는 SDK를 통해 자동 조정을 지금 활성화 할 수 있습니다. 자동 조정 작업을 예약할 수도 있습니다. Elasticsearch 서버 프로세스를 다시 시작하지 않고 클러스터에 동적으로 적용됩니다. 대기열 및 캐시 조정 작업을 할 수 있습니다.
자동 조정을 활성화 한 후, 의사 결정 트리가 안정성 또는 성능을 향상시킬 기회를 식별하면 시스템이 대기열 및 캐시 조정을 자동으로 적용합니다. JVM 변경은 Elasticsearch를 다시 시작해야하므로 예약 작업으로 해야합니다. 시스템은 정의 된 유지 관리 기간 동안 JVM 생성 크기 조정 또는 JVM 힙 크기 조정을 적용합니다. 반복 또는 일회성 유지 관리 기간을 정의 할 수 있습니다. 자동 조정이 비활성화 된 도메인의 경우 관련 조정 작업을 사용할 수있을 때 콘솔 알림을 계속 사용할 수 있습니다. Amazon CloudWatch 지표를 통해 자동 조정 작업을 추적 할 수도 있습니다.
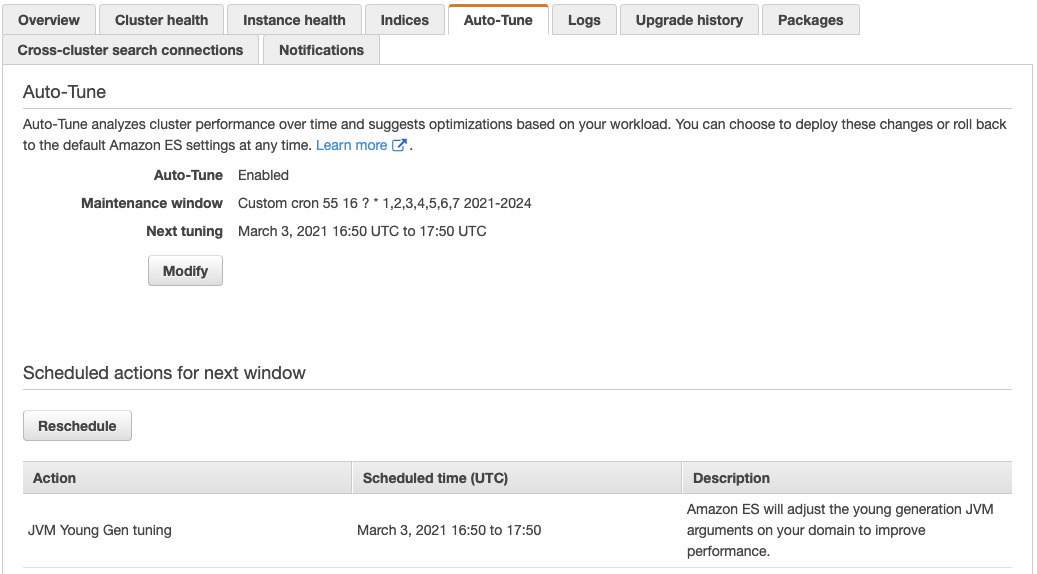
다음 스크린 샷은 향후 유지 관리에 적용 할 JVM 새 버전 조정 권장 사항을 보여줍니다.
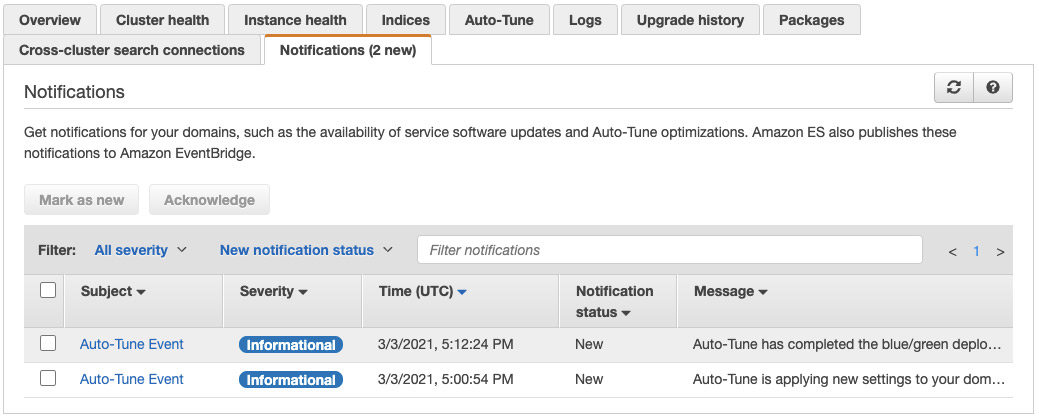
또한, 다음 스크린 샷과 같이 예약 된 조정이 시작되고 완료 될 때 알려줍니다.
자동 조정 적용에 대한 결과
자동 조정 작업으로 변경된 결과를 예시로 살펴보겠습니다. 다음 플롯은 프로덕션 클러스터에서 세대 크기 조정의 효과를 보여줍니다.
첫 번째 도표는 자동 조정 작업이 2021 년 3 월 6 일 18:00에 시작되기 전에 이전 세대 공간에서 JVM 점유가있는 톱니 형태 패턴을 보여줍니다. 이 톱니 모양의 패턴은 검색 워크로드에 의해 생성 된 수명이 짧은 개체의 수가 작은 젊은 세대 크기로 인해 불필요하게 이전 세대 공간으로 승격되었음을 나타냅니다. 자동 조정 조정을 통해 최대 및 평균 JVM 사용량이 이전 수준의 1/4로 떨어졌습니다.

다음 도표는 가비지 콜렉션 스레드가 CPU 사용량에 미치는 영향을 보여줍니다. 자동 조정 이전에는 가비지 수집기 스레드에서 CPU를 사용했습니다 (녹색으로 표시됨). 튜닝 후, 노드에서 샤드 쿼리 (분홍색으로 표시)의 중요한 기능에 더 많은주기가 할당되었습니다.

다음 도표는 힙이 더 큰 크기로 재구성되고 가비지 콜렉터가 G1GC로 전환 된 JVM 개선 사항을 보여줍니다. 거의 100 %에 달했던 전체 최대 힙 사용량이 약 50 % 감소했습니다.

리소스 관리 시스템의 목표는 클러스터에있는 기존 노드의 메모리 사용률을 최적화하는 것입니다. 그러나, 워크로드가 클러스터의 리소스 제한을 완전히 포화 시키면 노드 확장 만 클러스터 균형을 맞추는 데 도움이 될 수 있습니다. 예를 들어 생성 크기를 조정하여 가비지 수집 오버 헤드를 최적화 할 때 일부 클러스터에서 많은 경합 힙도 노출되어 클러스터가 적절하게 확장되어야한다는 것을 알았습니다.
마무리
자동 조정 기능을 통해 힙 크기, 대량 대기열 크기 및 가비지 콜렉션 설정을 조정하면 수집 처리량이 향상되는 것을 살펴보았습니다. 캐시 크기를 변경하면 검색에 대한 테일 지연 시간이 향상됩니다. 읽기 및 대량 대기열 크기를 조정하면 검색 및 수집 워크로드에 대한 거부가 줄어들고 가용성이 높아질 수 있습니다.
그러나, 이것은 빙산의 일각에 불과합니다. 자체 적응 형 폐쇄 피드백 루프는 흥미로운 가능성을위한 길을 열어줍니다. 자동 조정은 각 샤드, 인덱스 및 스레드 수준 세분화에서 리소스 풋 프린트를 모니터링합니다. 앞으로 몇 달 내에 이 프레임 워크를 확장하여 클러스터를 효과적으로 관리 할 수 있는 더 나은 통찰력과 리소스를 제공 할 계획입니다. 고객을 위한 차세대 적응 형 클라우드 컴퓨팅을 구축하기 위해 도메인 지식과 운영 전문 지식을 제공하게되어 기쁘게 생각합니다.
 Vigya Sharma 는 Amazon Web Services의 선임 소프트웨어 엔지니어입니다. Vigya는 분산 시스템에 열정적이며 대규모 시스템 문제를 해결하는 것을 좋아합니다.
Vigya Sharma 는 Amazon Web Services의 선임 소프트웨어 엔지니어입니다. Vigya는 분산 시스템에 열정적이며 대규모 시스템 문제를 해결하는 것을 좋아합니다.
 Joydeep Sinha 는 Amazon Web Services에서 검색 서비스를 담당하는 선임 소프트웨어 엔지니어입니다. 그는 분산 및 자율 데이터베이스에 관심이 있습니다.
Joydeep Sinha 는 Amazon Web Services에서 검색 서비스를 담당하는 선임 소프트웨어 엔지니어입니다. 그는 분산 및 자율 데이터베이스에 관심이 있습니다.
 Paul White 는 Amazon Web Services에서 검색 서비스를 담당하는 선임 소프트웨어 엔지니어입니다. 그는 분산 및 자율 시스템에 관심이 있습니다.
Paul White 는 Amazon Web Services에서 검색 서비스를 담당하는 선임 소프트웨어 엔지니어입니다. 그는 분산 및 자율 시스템에 관심이 있습니다.
 Balaji Kannan 은 Amazon Web Services에서 검색 서비스를 담당하는 엔지니어링 관리자입니다.
Balaji Kannan 은 Amazon Web Services에서 검색 서비스를 담당하는 엔지니어링 관리자입니다.
 Karthik Mohanasundaram 은 Amazon Web Services에서 검색 서비스를 담당하는 엔지니어링 관리자입니다.
Karthik Mohanasundaram 은 Amazon Web Services에서 검색 서비스를 담당하는 엔지니어링 관리자입니다.
이 글은 AWS Bigdata 블로그의 Introducing Auto-Tune in Amazon ES 한국어 번역본입니다.