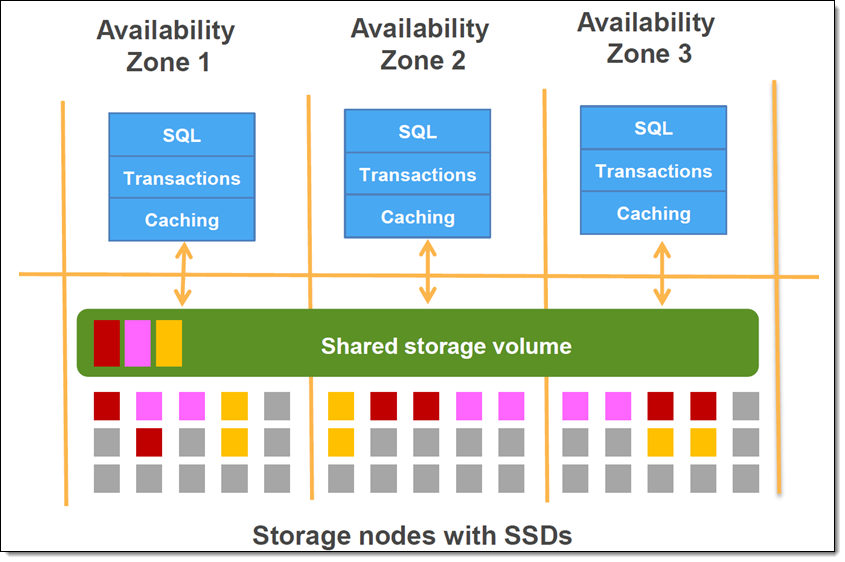
Amazon Aurora는 클라우드에서 제공되는 풍부한 네트워킹, 처리 및 스토리지 리소스를 활용하도록 설계된 관계형 데이터베이스입니다. Aurora에서는 사용자의 MySQL 및 PostgreSQL과 호환성을 유지하면서 최신의 특별히 설계된 분산 스토리지 시스템을 은밀하게 사용할 수 있습니다. 고속 SSD 스토리지에 있는 3개의 개별 AWS 가용 영역에 분산된 수백 개의 스토리지 노드에 데이터가 스트라이프되고, 영역당 2개의 복사본이 생성됩니다. 그림으로 설명하면 다음과 같습니다(Amazon Aurora 시작하기에서 발췌).
새로운 병렬 쿼리
AWS는 Aurora를 출시할 때 동일한 스케일아웃 설계 원칙을 다른 계층의 데이터베이스 스택에 적용할 계획임을 암시했습니다. 오늘은 AWS의 다음 단계에 대해서도 알려 드리겠습니다.
위의 그림에 나온 스토리지 계층의 각 노드에는 다량의 처리 성능도 포함됩니다. 이제 Aurora에서 분석 쿼리(주로 적정 크기의 테이블 전체 또는 다수를 처리하는 분석 쿼리)를 가져와 수백 또는 수천 개의 스토리지 노드에서 두 자릿수에 가까운 속도로 병렬 실행하여 이 처리 성능을 활용할 수 있습니다. 이 새로운 모델에서는 네트워크, CPU 및 버퍼 풀 경합이 감소하므로 혼합된 분석 및 트랜잭션 쿼리를 동일한 테이블에서 동시에 실행하고 두 유형의 쿼리에 대한 처리량을 높은 수준으로 유지할 수 있습니다.
지정된 시간에 활성 상태로 유지될 수 있는 병렬 쿼리 수는 인스턴스 클래스에 따라 결정됩니다.
- db.r*.large – 동시 병렬 쿼리 세션 1개
- db.r*.xlarge – 동시 병렬 쿼리 세션 2개
- db.r*.2xlarge – 동시 병렬 쿼리 세션 4개
- db.r*.4xlarge – 동시 병렬 쿼리 세션 8개
- db.r*.8xlarge – 동시 병렬 쿼리 세션 16개
- db.r4.16xlarge – 동시 병렬 쿼리 세션 16개
aurora_pq 파라미터를 사용하여 글로벌 수준 및 세션 수준에서 병렬 쿼리 사용을 활성화 및 비활성화할 수 있습니다.
병렬 쿼리는 200개가 넘는 유형의 단일 테이블 예측 및 해시 조인에 대한 성능을 개선합니다. Aurora 쿼리 Optimizer는 테이블의 크기와 메모리에 이미 있는 테이블 데이터의 양에 따라 병렬 쿼리 사용 여부를 자동으로 결정합니다. 또한 사용자는 aurora_pq_force 세션 변수를 사용하여 테스트 목적으로 Optimizer를 재정의할 수 있습니다.
병렬 쿼리의 작동 원리
병렬 쿼리 기능을 사용하려면 새 클러스터를 생성해야 합니다. 처음부터 다시 생성하거나 스냅샷을 복원할 수 있습니다.
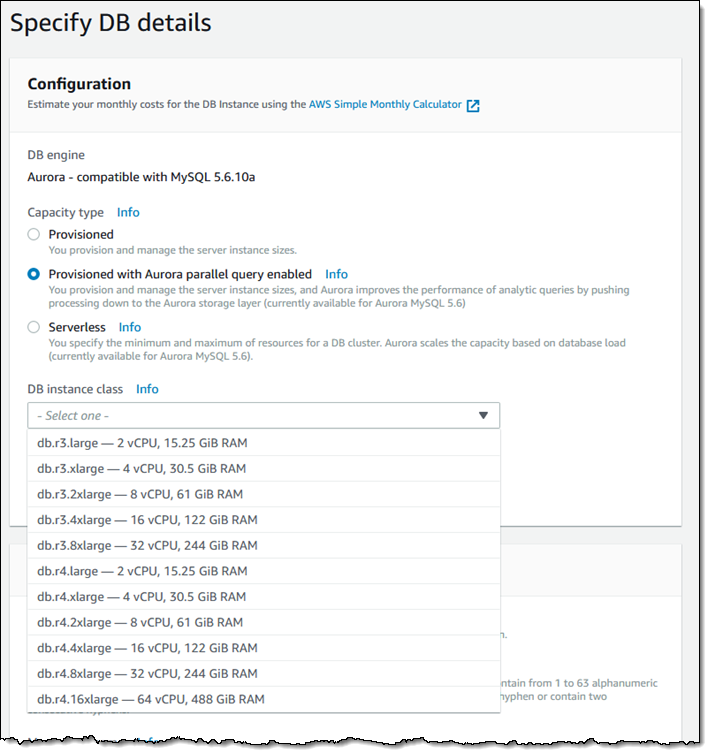
병렬 쿼리를 지원하는 클러스터를 생성하기 위해 [Capacity type]으로 [Provisioned with Aurora parallel query enabled]를 선택합니다.
저는 CLI를 사용하여 테스트에 사용할 100GB 스냅샷을 복원한 다음 TPC-H 벤치마크에서 쿼리 중 하나를 탐색했습니다. 기본 쿼리는 다음과 같습니다.
SELECT
l_orderkey,
SUM(l_extendedprice * (1-l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM customer, orders, lineitem
WHERE
c_mktsegment='AUTOMOBILE'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < date '1995-03-13'
AND l_shipdate > date '1995-03-13'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate LIMIT 15;
EXPLAIN 명령을 사용하면 병렬 쿼리 사용을 포함하여 쿼리 계획을 볼 수 있습니다.
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
| 1 | SIMPLE | customer | ALL | PRIMARY | NULL | NULL | NULL | 14354602 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | orders | ALL | PRIMARY,o_custkey,o_orderdate | NULL | NULL | NULL | 154545408 | Using where; Using join buffer (Hash Join Outer table orders); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) |
| 1 | SIMPLE | lineitem | ALL | PRIMARY,l_shipdate | NULL | NULL | NULL | 606119300 | Using where; Using join buffer (Hash Join Outer table lineitem); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) |
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.01 sec)
Extras 열에서 관련된 부분은 다음과 같습니다.
Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra)
병렬 쿼리를 사용하는 경우 2분이 되기 전에 쿼리가 실행됩니다.
+------------+-------------+-------------+----------------+
| l_orderkey | revenue | o_orderdate | o_shippriority |
+------------+-------------+-------------+----------------+
| 92511430 | 514726.4896 | 1995-03-06 | 0 |
| 593851010 | 475390.6058 | 1994-12-21 | 0 |
| 188390981 | 458617.4703 | 1995-03-11 | 0 |
| 241099140 | 457910.6038 | 1995-03-12 | 0 |
| 520521156 | 457157.6905 | 1995-03-07 | 0 |
| 160196293 | 456996.1155 | 1995-02-13 | 0 |
| 324814597 | 456802.9011 | 1995-03-12 | 0 |
| 81011334 | 455300.0146 | 1995-03-07 | 0 |
| 88281862 | 454961.1142 | 1995-03-03 | 0 |
| 28840519 | 454748.2485 | 1995-03-08 | 0 |
| 113920609 | 453897.2223 | 1995-02-06 | 0 |
| 377389669 | 453438.2989 | 1995-03-07 | 0 |
| 367200517 | 453067.7130 | 1995-02-26 | 0 |
| 232404000 | 452010.6506 | 1995-03-08 | 0 |
| 16384100 | 450935.1906 | 1995-03-02 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (1 min 53.36 sec)
세션에 대한 병렬 쿼리를 비활성화할 수 있습니다. RDS 사용자 지정 클러스터 파라미터 그룹을 사용하면 효과를 장기간 유지할 수 있습니다.
set SESSION aurora_pq=OFF;
병렬 쿼리가 없으니 쿼리가 상당히 느리게 실행됩니다.
+------------+-------------+-------------+----------------+
| l_orderkey | o_orderdate | revenue | o_shippriority |
+------------+-------------+-------------+----------------+
| 92511430 | 1995-03-06 | 514726.4896 | 0 |
...
| 16384100 | 1995-03-02 | 450935.1906 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (1 hour 25 min 51.89 sec)
이 작업은 db.r4.2xlarge 인스턴스에서 수행되었습니다. 다른 인스턴스 크기, 데이터 세트, 액세스 패턴 및 쿼리는 다르게 수행됩니다. 쿼리 Optimizer를 재정의하고 병렬 쿼리를 테스트 목적으로 사용할 수도 있습니다.
set SESSION aurora_pq_force=ON;
주요 사항
다음은 Amazon Aurora 병렬 쿼리에 대한 탐색을 시작할 때 알아야 할 몇 가지 정보입니다.
엔진 지원 – MySQL 5.6에 대한 지원이 출시됩니다. 현재 MySQL 5.7 및 PostgreSQL에 대한 지원을 작업 중입니다.
테이블 형식 – 테이블 행 형식은 COMPACT여야 하며 파티셔닝된 테이블은 지원되지 않습니다.
데이터 유형 – TEXT, BLOB 및 GEOMETRY 데이터 유형은 지원되지 않습니다.
DDL – 테이블에는 보류 중인 고속 온라인 DDL 작업이 없어야 합니다.
요금 – 병렬 쿼리는 추가 요금 없이 사용할 수 있습니다. 그러나 병렬 쿼리를 사용하려면 스토리지에 직접 액세스해야 하므로 IO 비용이 증가할 수 있습니다.
지금 사용 시작
지금 바로 이 기능을 사용할 수 있으며 오늘부터 사용을 시작할 수 있습니다.
— Jeff;