Amazon Web Services 한국 블로그
Apache Airflow, Genie 및 Amazon EMR을 통한 빅데이터 워크플로 오케스트레이션 – 1부
AWS에서 빅 데이터 ETL 워크플로를 실행하는 대기업은 많은 내부 최종 사용자를 지원하는 대규모로 운영하며 수천 개의 동시 파이프라인을 실행합니다. 이러한 상황과 새로운 프레임워크 및 빅데이터 프로세싱 프레임워크의 최신 릴리스에 보조를 맞추기 위해 빅 데이터 플랫폼을 지속적으로 업데이트 및 확장해야 하는 필요성에 따라, 빅 데이터 플랫폼의 관리를 간소화할 뿐 아니라 빅 데이터 애플리케이션에 대한 간편한 액세스를 지원하는 효율적인 아키텍처 및 조직적 구조가 요구되고 있습니다.
이 게시물에서는 수천 개의 동시 ETL 워크플로를 지원하고 이를 실현하는 데 필요한 운영 작업을 간소화하기 위한 중앙 집중식 플랫폼 팀의 빅 데이터 플랫폼 유지 관리 작업을 돕는 아키텍처를 소개합니다.
아키텍처 구성 요소
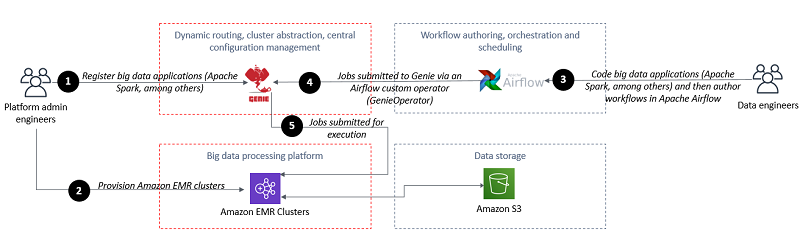
높은 수준에서 보면 이 아키텍처는 Amazon EMR과 함께 두 가지의 오픈 소스 기술을 사용하여 ETL 워크플로 작성, 오케스트레이션 및 실행을 위한 빅 데이터 플랫폼을 제공합니다. Genie는 빅 데이터 작업 동시 제출, 동적 작업 라우팅, 중앙 집중식 구성 관리 및 Amazon EMR 클러스터의 추상화를 위한 중앙 집중식 REST API를 제공합니다. Apache Airflow는 복잡한 데이터 파이프라인에 대한 프로그래밍 방식의 작성, 예약 및 모니터링을 지원하는 작업 오케스트레이션을 위한 플랫폼을 제공합니다. Amazon EMR은 Apache Hadoop, Apache Spark 및 기타 빅 데이터 프레임워크를 실행 및 조정할 수 있는 관리형 클러스터 플랫폼을 제공합니다.
다음 다이어그램은 이 아키텍처를 보여줍니다.
Apache Airflow
Apache Airflow 빅 데이터 워크플로의 작성 및 오케스트레이션을 위한 오픈 소스 도구입니다.
데이터 엔지니어는 Apache Airflow를 통해 DAG(Direct Acyclic Graph)를 정의합니다. DAG는 워크플로를 실행하는 방법을 설명하며 Python으로 작성됩니다. 워크플로는 독립적으로 실행되는 작업을 그룹화하는 DAG 형태로 설계됩니다. DAG는 작업 간의 관계와 종속성을 추적합니다.
오퍼레이터는 워크플로 내의 단일 작업을 정의하는 템플릿을 정의합니다. Airflow는 오퍼레이터에 일반적인 작업을 제공하며, 사용자 정의 작업자를 정의할 수도 있습니다. 이 게시물은 Genie에 작업을 제출하기 위한 사용자 정의 오퍼레이터(GenieOperator)에 대해 설명합니다.
작업은 오퍼레이터의 파라미터화된 인스턴스입니다. 오퍼레이터가 인스턴스화된 후에는 이를 작업이라고 부릅니다. 작업 인스턴스는 작업의 구체적인 실행을 나타냅니다. 작업 인스턴스는 관련된 DAG, 작업 및 시점을 가집니다.
DAG와 작업은 온디맨드로 실행하거나 DAG에 cron 표현식으로 정의된 특정 시간에 실행되도록 예약할 수 있습니다.
Apache Airflow에 대한 추가적인 세부 정보는 Apache Airflow 설명서의 Concepts를 참조하십시오.
Genie
Genie는 Amazon EMR 클러스터에 대한 액세스의 추상화를 통해 구성 관리 기능 및 작업의 동적 라우팅을 제공하는 오픈 소스 도구입니다.
Genie는 Apache Hadoop MapReduce 또는 Apache Spark와 같은 빅 데이터 애플리케이션에서 작업을 제출할 수 있게 해 주는 REST API를 제공합니다. Genie는 클러스터와 해당 클러스터에서 실행되는 명령 및 애플리케이션의 메타데이터를 관리합니다.
Genie는 클러스터에 하나 이상의 태그를 연결하여 처리 중인 클러스터에 대한 액세스를 추상화합니다. 빅 데이터 플랫폼이 지원하는 애플리케이션과 명령에 대한 메타데이터 세부 정보에 태그를 연결할 수도 있습니다. Genie는 특정 태그에 대한 작업 제출을 수신하고, 클러스터/명령 태그의 조합을 사용하여 각 작업을 올바른 EMR 클러스터에 동적으로 라우팅합니다.
Genie의 데이터 모델
Genie는 빅 데이터 환경 내의 리소스와 관련된 메타데이터를 캡처하는 데이터 모델을 제공합니다.
애플리케이션 리소스는 클러스터에 작업을 제출하는 Genie 노드의 빅 데이터 플랫폼이 지원하는 애플리케이션을 설치 및 구성하기 위한, 재사용 가능한 바이너리, 구성 파일 및 설정 파일의 세트입니다. Genie에서 작업을 수신하면, Genie 노드는 애플리케이션에 관련된 모든 종속성, 구성 파일 및 설정 파일을 다운로드하여 작업 디렉터리에 저장합니다. 애플리케이션은 명령에 연결되어 있습니다. 이는 애플리케이션이 명령을 실행하기 전에 필요한 바이너리와 구성을 나타내기 때문입니다.
명령 리소스는 작업을 클러스터에 제출하기 위해 명령줄을 사용할 때의 파라미터 및 명령을 실행할 때 PATH에서 사용 가능해야 하는 애플리케이션을 나타냅니다. 명령 리소스는 메타데이터 구성 요소를 서로 결합해 줍니다. 예를 들어, Hive 명령을 나타내는 명령 리소스는 hive-site.xml을 포함하며 명령을 실행하는 데 필요한 Hive 및 Hadoop 바이너리를 제공하는 일련의 애플리케이션 리소스에 연관됩니다. 그 뿐 아니라, 명령 리소스는 해당 리소스가 실행될 수 있는 클러스터에 연결됩니다.
클러스터 리소스는 연결 세부 정보, 클러스터 상태, 태그 및 추가 속성을 포함한, 실행 클러스터에 대한 세부 정보를 식별합니다. 클러스터 리소스는 자동으로 시작 시 Genie에 등록되고 종료 시 등록 해제될 수 있습니다. 클러스터는 해당 클러스터에서 실행될 수 있는 하나 이상의 명령에 연결됩니다. 명령이 클러스터에 연결된 후에는 Genie가 클러스터에 작업을 제출하기 시작할 수 있습니다.
마지막으로, 작업 리소스에는 작업 요청, 작업 및 작업 실행의 세 가지 유형이 있습니다. 작업 요청 리소스는 작업 실행을 위한 세부 정보가 포함된 요청 제출을 나타냅니다. 요청을 통해 제출된 파라미터를 기반으로 작업 리소스가 생성됩니다. 작업 리소스는 작업과 관련된 명령, 클러스터 및 애플리케이션 등의 세부 정보를 캡처합니다. 그 뿐 아니라, 작업 리소스에는 상태, 시작 시간 및 끝 시간에 대한 정보도 제공됩니다. 작업 실행 리소스는 작업이 어디에서 실행되었는지 이해할 수 있도록 관리 세부 정보를 제공합니다.
자세한 내용은 Genie Reference Guide의 Data Model을 참조하십시오.
Amazon EMR 및 Amazon S3
Amazon EMR은 방대한 양의 데이터를 처리 및 분석하기 위해 AWS에서 Apache Hadoop 및 Apache Spark 같은 빅 데이터 프레임워크의 실행을 간소화해 주는 관리형 클러스터 플랫폼입니다. 자세한 내용은 Amazon EMR 아키텍처 개요 및 Amazon EMR 개요를 참조하십시오.
데이터는 확장 가능한 성능, 사용이 편리한 기능 및 네이티브 암호화 및 액세스 제어 기능을 갖춘 객체 스토리지 서비스인 Amazon S3에 저장됩니다. S3에 대한 세부 정보는 Amazon S3 as the Data Lake Storage Platform을 참조하십시오.
아키텍처 심층 분석
플랫폼 관리 엔지니어와 데이터 엔지니어라는 두 부류의 사용자가 이 아키텍처와 상호 작용합니다.
플랫폼 관리 엔지니어는 모든 구성 요소에 대해 관리자 권한이 있습니다. 이러한 사용자는 클러스터를 추가 및 제거하고, 플랫폼이 지원하는 애플리케이션 및 명령을 구성할 수 있습니다.
데이터 엔지니어는 선호하는 프레임워크(Apache Spark, Apache Hadoop MR, Apache Sqoop, Apache Hive, Apache Pig 및 Presto)를 사용한 빅 데이터 애플리케이션 작성과 DAG를 나타내는 Python 스크립트 작성에 집중합니다.
높은 수준에서 보면 플랫폼 관리 엔지니어 팀은 지원되는 빅 데이터 애플리케이션과 관련 종속성을 준비하고 이를 Genie에 등록합니다. 플랫폼 관리 엔지니어 팀은 시작 시 Genie에 등록되는 Amazon EMR 클러스터를 시작합니다.
플랫폼 관리 엔지니어 팀은 각 Genie 메타데이터 리소스(애플리케이션, 명령 및 클러스터)를 Genie 태그에 연결합니다. 예를 들어, 클러스터 리소스를 environment라는 이름의 태그에 연결할 수 있으며 이 태그의 값은 “Production Environment”, “Test Environment” 또는 “Development Environment”가 될 수 있습니다.
데이터 엔지니어는 워크플로를 Airflow DAG 형태로 작성하고 사용자 정의 Airflow 오퍼레이터(GenieOperator)를 사용하여 Genie에 작업을 제출합니다. 이러한 사용자는 태그의 조합을 사용하여 실행 중인 작업의 유형과 작업이 실행되어야 하는 위치를 식별합니다. 예를 들어, “Production Environment” 태그에 의해 식별된 환경에서 Apache Spark 2.4.3 작업을 실행해야 할 수 있습니다. 이를 수행하려면 Airflow GenieOperator에서 클러스터 및 명령 태그를 다음 코드 형태로 설정합니다.
(cluster_tags=['emr.cluster.environment:production'],command_tags=['type:spark-submit','version:2.4.3'])
다음 다이어그램은 이 아키텍처를 보여줍니다.
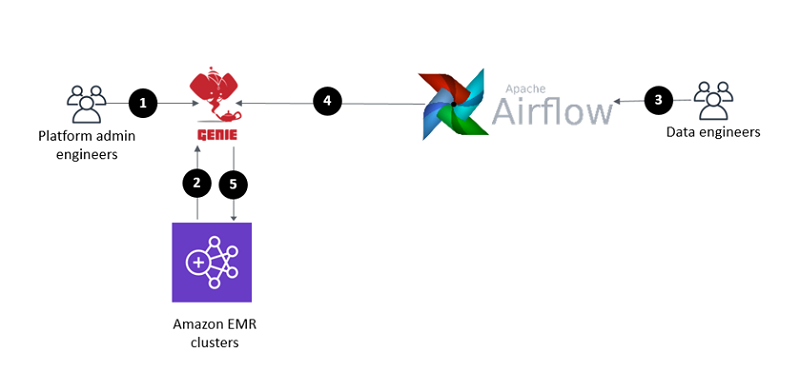 이 다이어그램의 숫자에 해당하는 워크플로는 다음과 같습니다.
이 다이어그램의 숫자에 해당하는 워크플로는 다음과 같습니다.
- 플랫폼 관리 엔지니어가 지원되는 애플리케이션(Spark-2.4.5, Spark-2.1.0, Hive-2.3.5 등)의 바이너리 및 종속성을 준비합니다. 플랫폼 관리 엔지니어가 명령(spark-submit, hive)을 준비합니다. 플랫폼 관리 엔지니어가 애플리케이션과 명령을 Genie에 등록합니다. 또한, 플랫폼 관리 엔지니어는 명령을 단계 2(아래)가 완료된 후 애플리케이션에 연결하고, 명령을 일련의 클러스터에 연결합니다.
- Amazon EMR 클러스터가 시작 시 Genie에 등록됩니다.
- 데이터 엔지니어가 Airflow DAG를 작성하고 Genie 태그를 사용하여 환경, 애플리케이션, 명령 또는 이들의 조합을 참조합니다. 워크플로 코드에서 데이터 엔지니어가 GenieOperator를 사용합니다. GenieOperator가 작업을 Genie에 제출합니다.
- 일정에 따라 워크플로 실행이 트리거되거나 데이터 엔지니어가 수동으로 워크플로 실행을 트리거합니다. 워크플로를 구성하는 작업이 작업 실행 위치를 지정하는 일련의 Genie 태그와 함께 실행을 위해 Genie에 제출됩니다.
- 클라이언트 게이트웨이 역할을 하는 Genie 노드가 모든 바이너리와 종속성이 포함된 작업 디렉터리를 설정합니다. Genie는 제공된 Genie 태그에 연관된 클러스터에 작업을 동적으로 라우팅합니다. Amazon EMR 클러스터가 작업을 실행합니다.
Apache Airflow와 Genie에서 지원하는 승인 및 인증 메커니즘에 대한 자세한 내용은 Apache Airflow 설명서의 Security 및 Genie 설명서의 Security를 참조하십시오. 이 아키텍처 패턴은 SSH 액세스를 Amazon EMR 클러스터에 노출하지 않습니다. EMRFS(EMR 파일 시스템)를 통해 Amazon S3의 데이터에 서로 다른 수준의 액세스를 제공하는 방법에 대한 자세한 내용은 Amazon S3에 대한 EMRFS 요청의 IAM 역할 구성을 참조하십시오.
활용 사례
다음 사용 사례는 이 아키텍처가 제공하는 기능을 시연합니다.
업그레이드 및 배포의 다운타임 없는 관리 및 최신 오픈 소스 릴리스 도입
대규모 조직에서는 데이터 플랫폼을 사용하는 여러 팀이 이기종의 프레임워크와 서로 다른 버전을 사용합니다. 이 아키텍처를 사용하면 다운타임 없는 업그레이드를 지원하고 짧은 시간에 최신 버전의 오픈 소스 프레임워크를 제공할 수 있습니다.
Genie와 Amazon EMR은 이 사용 사례를 지원하는 데 있어 주요 구성 요소입니다. Amazon EMR 서비스 팀이 짧은 출시 주기로 Amazon EMR에서 실행되는 최신 버전의 오픈 소스 프레임워크를 추가하기 위해 최선을 다하므로 귀사는 선호하는 오픈 소스 프레임워크의 최신 기능에 대한 사내 팀의 요구를 충족할 수 있습니다.
새 버전의 오픈 소스 프레임워크를 사용할 수 있게 되면, 이를 테스트하고, 새로 지원되는 버전과 관련 종속성을 Genie에 추가하고, 이전 클러스터의 태그를 새 클로스터로 이전해야 합니다. 새 클러스터는 새 작업 제출을 수신하며 이전 클러스터는 아직 실행 중인 작업을 완료합니다.
그 뿐 아니라, Genie에서 애플리케이션 바이너리 및 관련 종속성의 위치를 중앙 집중화하므로, Genie의 바이너리 및 관련 종속성을 업그레이드하면 모든 업스트림 클라이언트도 자동으로 업그레이드됩니다. Genie를 사용하면 모든 업스트림 클라이언트를 업그레이드할 필요가 없어집니다.
중앙 집중식 구성, 작업 상태, 클러스터 상태 및 로깅 관리
수천 개의 작업과 복수의 클러스터가 존재하는 환경에서는 특정 작업이 어디에서 실행 중인지 식별해야 하고 로깅 세부 정보를 빠르게 액세스해야 합니다. 이 아키텍처는 데이터 플랫폼에서 실행 중인 작업, 작업 로깅, 클러스터 및 관련 구성에 대한 가시성을 제공합니다.
빅 데이터 플랫폼에 대한 프로그래밍 방식의 액세스
이 아키텍처는 Genie의 REST API를 사용한 단일 작업 제출 지점을 지원합니다. 기반 클러스터에 대한 액세스는 클러스터에 대한 관리 작업과 작업 제출 모두를 지원하는 일련의 API를 통해 추상화됩니다. REST API 호출은 비동기식으로 Genie에 작업을 제출합니다. 수락된 경우, 작업 ID가 반환됩니다. 이 작업 ID를 사용하여 작업 상태를 얻을 수 있으며, API 또는 웹 UI를 통해 프로그래밍 방식으로 해당 정보를 출력할 수 있습니다. Genie 노드는 작업 디렉터리를 설정하고 별도 프로세스에서 작업을 실행합니다.
또한 빅 데이터 애플리케이션 및 Apache Airflow DAG를 위해 이 아키텍처를 CI/CD(지속적 통합 및 지속적 전달) 파이프라인에 통합할 수 있습니다.
확장 가능한 클라이언트 게이트웨이 및 동시 작업 제출 지원
Genie 노드는 클라이언트 게이트웨이 역할(엣지 노드)을 하며, 데이터 플랫폼에 작업을 제출하는 데 사용되는 클라이언트 게이트웨이 리소스가 수요를 충당하도록 수평 확장될 수 있습니다. 그 뿐 아니라, Genie에서는 동시 작업의 제출이 허용됩니다.
이 아키텍처를 사용해야 하는 사례
이 아키텍처는 일시적인 클러스터 대신 복수의 대규모 다중 테넌트 프로세싱 클러스터를 사용하는 조직에 권장됩니다. 조직이 언제 일시적인 클러스터 대신 상시 실행되는 클러스터를 사용해야 할지에 대한 설명은 이 게시물의 범위를 벗어납니다(EMR Airflow 오퍼레이터를 사용하면 Genie에 등록되는 Amazon EMR 클러스터를 시작하고 작업을 실행하고 클러스터를 종료할 수 있습니다). 이 아키텍처에는 예약 인스턴스를 사용해야 합니다. 자세한 내용은 예약 인스턴스 사용을 참조하십시오.
이 아키텍처는 많은 사내 팀을 지원하면서 수천 개의 작업을 동시에 실행해야 하는 빅 데이터 플랫폼을 운영 및 유지 관리하는 중앙 플랫폼 팀을 보유하고자 하는 조직에 특히 권장됩니다.
규모가 그렇게 크지 않거나 이 정도 규모로 성장할 것으로 예상되지 않는 조직에게는 이 아키텍처가 적합하지 않습니다. 클러스터 추상화 및 중앙 집중식 구성 관리는 수천 개의 동시 워크플로 및 수백 개 팀으로 구성되어 혼돈스러울 수 있는 환경에 구조화된 액세스를 제공하는 데 이상적입니다.
이 아키텍처는 높은 비율의 다시간 또는 중첩 워크플로 및 이기종 프레임워크(Apache Spark, Apache Hive, Apache Pig, Apache Hadoop MapReduce, Apache Sqoop 또는 Presto)를 지원하는 조직에게도 권장됩니다.
귀사가 Apache Spark만 사용하며 이전에 논의된 권장 사항에 정렬되어 있는 경우에는 이 아키텍처가 여전히 적용될 수 있습니다. 작업 제출을 위한 중앙 집중식 REST API, 클러스터 추상화, 동적 작업 라우팅 또는 중앙 집중식 구성 관리의 필요성을 정당화할 만한 규모가 아닌 조직의 경우 Apache Livy와 Amazon EMR의 조합이 적절한 옵션이 될 수 있습니다. Genie는 엣지 클라이언트 역할을 수행하는 확장 가능한 자체 인프라를 보유하고 있습니다. 이는 Apache Livy와 달리 Genie는 Amazon EMR 마스터 인스턴스 리소스와 경합하지 않음을 의미합니다.
귀사 워크플로의 대부분이 짧은 수명의 작업 몇 개에 불과한 경우, 서버리스 프로세싱 레이어, 서버리스 임시 쿼리 레이어 또는 워크플로별로 전용 임시 Amazon EMR 클러스터를 사용하는 것이 더 적합할 수 있습니다. 귀사 워크플로의 대부분이 짧은 수명의 작업 수천 개로 구성된 경우, 클러스터 시작 및 종료의 필요성을 제거해 주므로 이 아키텍처가 여전히 적용될 수 있습니다.
이 아키텍처는 구성 요소 성능 최적화를 위하 프로세싱 플랫폼의 완전한 제어가 필요한 조직에게 권장됩니다. 그 뿐 아니라, 이 아키텍처는 CI/CD 파이프라인을 통해 워크플로에 중앙 집중식 거버넌스를 적용해야 하는 조직에게 권장됩니다.
서로 다른 오케스트레이션 옵션이나 Airflow를 오케스트레이션 레이어로 도입할 때의 이점을 평가하는 것은 이 게시물의 범위를 벗어납니다. 아키텍처 도입을 고려할 때에는 관련 도구를 도입하기 위한 시간과 기존 보유 기술도 고려해야 합니다. Genie의 오픈 소스 특성은 다른 오케스트레이션 도구와의 통합을 지원할 수도 있습니다. 이 아키텍처를 다른 오케이스테이션 도구와 통합하고자 하는 경우 이러한 경로를 평가하는 것이 옵션이 될 수 있습니다.
마무리
이 게시물에서는 Apache Airflow, Genie 및 Amazon EMR을 사용하여 빅 데이터 워크플로를 관리하는 방법에 대해 소개했습니다. 이 게시물은 아키텍처 구성 요소, 해당 아키텍처가 지원하는 사용 사례 및 사용해야 할 상황에 대한 설명을 제공했습니다. 다음 2부 게시물에서는 데모 환경을 배포하고 Genie를 구성하고 GenieOperator for Apache Airflow를 사용하는 방법을 단계 별로 안내합니다.
 Francisco Oliveira는 AWS의 빅 데이터 솔루션 선임 아키텍트입니다. 오픈 소스 기술과 AWS를 통해 빅 데이터 솔루션을 구축하는 데 초점을 맞추고 있습니다. 그는 여가 시간에 새로운 스포츠와 여행을 즐기며 국립 공원을 탐색하는 것을 좋아합니다.
Francisco Oliveira는 AWS의 빅 데이터 솔루션 선임 아키텍트입니다. 오픈 소스 기술과 AWS를 통해 빅 데이터 솔루션을 구축하는 데 초점을 맞추고 있습니다. 그는 여가 시간에 새로운 스포츠와 여행을 즐기며 국립 공원을 탐색하는 것을 좋아합니다.

Jelez Raditchkov는 AWS에서 NoSQL AWS Professional Services 업무를 선도하고 있습니다. NoSQL, Graph 및 Search 영역에 대한 집중화된 지원을 통해 고객이 원하는 비즈니스 결과를 실현할 수 있도록 돕고 있습니다. 이전에 그는 AWS Professional Services의 수석 데이터 레이크 아키텍트였습니다.
AWS NoSQL 전용 데이터베이스 서비스에 대한 자세한 내용은 https://aws.amazon.com/nosql/을 참조하십시오.