- 클라우드 컴퓨팅이란 무엇인가요?
- 클라우드 컴퓨팅 개념 허브
- 데이터베이스
관계형 데이터베이스와 비관계형 데이터베이스의 차이점은 무엇인가요?
관계형 데이터베이스와 비관계형 데이터베이스의 차이점은 무엇인가요?
관계형 데이터베이스와 비관계형 데이터베이스는 애플리케이션을 위한 두 가지 데이터 저장 방법입니다. 관계형 데이터베이스(또는 SQL 데이터베이스)는 데이터를 행과 열이 있는 테이블 형식으로 저장합니다. 열에는 데이터 속성이 포함되고 행에는 데이터 값이 있습니다. 관계형 데이터베이스의 테이블을 연결하여 다양한 데이터 포인트 간의 상호 연결에 대한 심층적인 인사이트를 얻을 수 있습니다. 반면 비관계형 데이터베이스(또는 NoSQL 데이터베이스)는 데이터에 액세스하고 관리하기 위해 다양한 데이터 모델을 사용합니다. 이러한 데이터베이스는 큰 데이터 볼륨, 짧은 지연 시간과 유연한 데이터 모델이 필요한 애플리케이션에 특히 최적화되었으며, 이는 다른 데이터베이스의 데이터 일관성 제한 일부를 완화함으로써 이루어집니다.
관계형 데이터베이스는 데이터를 어떻게 저장하나요?
관계형 데이터베이스는 열과 행이 있는 테이블에 데이터를 저장합니다. 각 열은 특정 데이터 속성을 나타내고 각 행은 해당 데이터의 인스턴스를 나타냅니다.
각 테이블마다 해당 테이블을 고유하게 식별하는 식별자 열인 프라이머리 키를 할당합니다. 프라이머리 키를 사용하여 테이블 간의 관계를 설정합니다. 이 키를 사용하여 행을 다른 테이블의 외래 키로서 테이블 간에 연결할 수 있습니다.
두 테이블이 연결되면 단일 쿼리를 사용하여 두 테이블로부터 데이터를 가져올 수 있습니다. SQL 쿼리를 작성하여 관계형 데이터베이스와 상호 작용합니다.
저장된 데이터의 예
예를 들어 한 소매업체가 모든 제품이 포함된 테이블을 만든다고 가정해 보겠습니다. 이 테이블에는 제품 이름, 설명 및 가격에 대한 열이 있을 수 있습니다. 또 다른 테이블에는 고객, 고객 이름 및 구매 상품에 대한 데이터가 포함되어 있습니다.
다음 표는 이 접근 방식을 보여줍니다.
|
Product_id(프라이머리 키) |
Product_name |
Product_cost |
|
P1 |
Product_A |
100 USD |
|
P2 |
Product_B |
50 USD |
|
P3 |
Product_C |
80 USD |
|
Customer_id |
Customer_name |
Item_purchased(외래 키) |
|
C1 |
Customer_A |
P2 |
|
C2 |
Customer_B |
P1 |
|
C3 |
Customer_C |
P3 |
비관계형 데이터베이스는 데이터를 어떻게 저장하나요?
스키마 없는 데이터를 관리하고 저장하는 방식이 다양하기 때문에 비관계형 데이터베이스 시스템에는 여러 종류가 있습니다. 스키마 없는 데이터는 관계형 데이터베이스에서 요구되는 제약 조건 없이 저장되는 데이터입니다.
다음으로 일반적인 유형의 비관계형 데이터베이스에 대해 설명합니다.
키 값 데이터베이스
키 값 데이터베이스는 데이터를 키-값 페어의 컬렉션으로 저장합니다. 페어에서 키는 고유 식별자 역할을 합니다. 단순한 객체부터 복잡한 집합체에 이르기까지 무엇이든 키와 값이 될 수 있습니다.
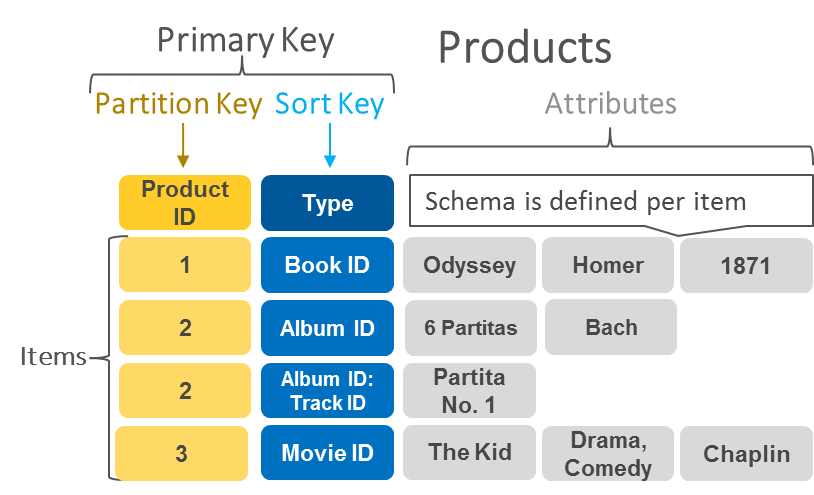
도큐먼트 데이터베이스
도큐먼트 지향 데이터베이스는 개발자가 애플리케이션 코드에 사용하는 것과 동일한 문서 모델 형식을 사용합니다. 유연한 반정형 계층형 JSON 객체로 데이터를 저장합니다.
다음 예는 도큐먼트 데이터베이스에 저장되는 데이터의 형식을 보여줍니다.
|
{ company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
그래프 데이터베이스
그래프 데이터베이스는 관계를 저장하고 탐색하도록 특별히 구축되었습니다. 그래프 데이터베이스는 노드를 사용하여 데이터 엔터티를 저장하고 엣지로는 엔터티 간의 관계를 저장합니다.
엣지에는 항상 시작 노드, 종료 노드, 유형 및 방향이 있습니다. 예를 들어 상위-하위 관계, 작업 및 소유권을 설명할 수 있습니다.

주요 차이점: 관계형 데이터베이스와 비관계형 데이터베이스
관계형 데이터베이스와 비관계형 데이터베이스는 서로 매우 다른 방식으로 데이터를 저장하고 관리합니다. 다음 섹션에서는 구체적인 차이점에 대해 설명합니다.
구조
관계형 데이터베이스는 데이터를 테이블 형식으로 저장하며 데이터 변형 및 테이블 관계에 관한 엄격한 규칙을 따릅니다. 따라서 데이터 무결성과 일관성을 유지하면서 정형 데이터에 대한 복잡한 쿼리를 처리할 수 있습니다.
비관계형 데이터베이스는 더 유연하며, 요구 사항이 변화하는 데이터에 보다 유용합니다. 따라서 이미지, 비디오, 문서 및 기타 반정형 및 비정형 콘텐츠를 저장하는 데 사용할 수 있습니다.
데이터 무결성 메커니즘
원자성, 일관성, 격리 및 내구성(ACID)은 데이터 처리에서 오류나 중단이 발생하더라도 데이터 무결성을 유지할 수 있는 데이터베이스의 기능을 말합니다.
관계형 데이터베이스 모델은 엄격한 ACID 속성을 따릅니다. 즉, 일련의 후속 작업이 항상 함께 완료됩니다. 단일 작업이 실패하면 전체 작업 세트가 실패합니다. 따라서 데이터 정확성이 항상 보장됩니다.
반면 비관계형 데이터베이스는 기본적으로 가용성이 보장되고 소프트 상태이며 궁극적으로 일관된(BASE) 보다 유연한 모델을 제공합니다.
비관계형 데이터베이스는 가용성을 보장하지만 즉각적인 일관성은 보장하지 않습니다. 데이터베이스 상태는 시간이 지남에 따라 변할 수 있으며 결국 일관된 상태가 됩니다. 일부 비관계형 데이터베이스는 ACID 규정 준수와 성능 또는 기타 장단점을 제공할 수 있습니다.
성능
관계형 데이터베이스의 성능은 디스크 하위 시스템에 따라 달라집니다. SSD를 사용하고 디스크를 Redundant Array of Independent Disks(RAID)로 구성하여 디스크를 최적화하면 데이터베이스 성능을 높일 수 있습니다. 성능을 극대화하려면 인덱스, 테이블 구조 및 쿼리도 최적화해야 합니다.
반면 NoSQL 데이터베이스의 성능은 네트워크 지연 시간, 하드웨어 클러스터 크기 및 호출 애플리케이션에 따라 달라집니다. 비관계형 데이터베이스는 다음 몇 가지 방법으로 성능을 높일 수 있습니다.
- 클러스터 크기 증대
- 네트워크 지연 시간 최소화
- 인덱스 및 캐시
NoSQL 데이터베이스는 특정 사용 사례에서 관계형 데이터베이스보다 더 높은 성능과 확장성을 제공합니다.
확장
관계형 데이터베이스 시스템의 엄격한 스키마는 대규모 환경에서 문제를 야기할 수 있습니다. 일반적으로 수직적으로 규모를 조정할 때는 서버에 CPU 또는 RAM 리소스를 추가합니다. 또한 읽기 전용 워크로드를 처리하기 위해 서버 간에 데이터를 복제하여 수평적으로 규모를 조정할 수도 있습니다. 하지만 읽기-쓰기 워크로드의 수평적 규모 조정에는 파티셔닝 및 샤딩과 같은 특수한 전략이 필요합니다.
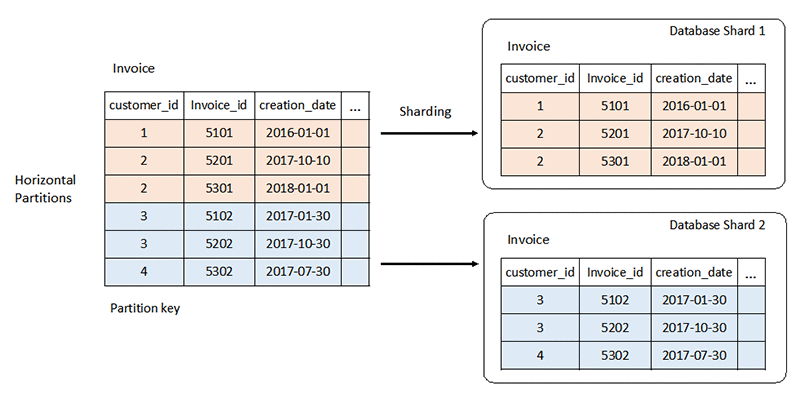
반면 NoSQL 데이터베이스는 확장성이 뛰어납니다. 워크로드를 여러 노드에 보다 손쉽게 분산할 수 있습니다. 이 데이터베이스는 더 작은 세트로 분할하고 여러 노드에 세트를 분산하여 대량의 데이터를 처리할 수 있습니다.

관계형 데이터베이스와 비관계형 데이터베이스의 사용 사례
데이터의 크기, 구조 및 액세스 빈도를 예측할 수 있는 경우 관계형 데이터베이스가 가장 적합합니다. 엔터티 간의 관계가 중요한 경우에도 관계형 데이터베이스 관리 시스템을 선호할 수도 있습니다. 예를 들어 구조와 관계가 복잡한 대규모 데이터 세트가 있는 경우, 분석 및 사용 편의성 측면에서 관계가 잘 드러나기를 원할 것입니다.
반면 비관계형 모델은 형태나 크기가 유연하거나 향후 변경될 수 있는 데이터를 저장하는 데 더 효과적입니다.
또한 데이터 관계가 테이블 형식의 프라이머리 키 및 외래 키 형식에 잘 맞지 않는 경우도 있습니다. 예를 들어 소셜 미디어 네트워크에서 친구와 관계를 모델링하려면 관계형 데이터베이스에 수백 개의 행이 있는 테이블이 필요합니다.
반대로 비관계형 데이터베이스에서는 이를 한 줄로 표현할 수 있습니다. 다음 예는 비관계형 데이터베이스에서 친구 4명이 있는 회원의 데이터 항목을 보여줍니다.
|
Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{member name: “member 1” member friends: “member 2, member 3, member 4, member 5”} |
차이점 요약: 관계형 데이터베이스와 비관계형 데이터베이스
|
카테고리 |
관계형 데이터베이스 |
비관계형 데이터베이스 |
|
데이터 모델 |
테이블 형식. |
키-값, 문서 또는 그래프 |
|
데이터 유형 |
정형. |
정형, 반정형 및 비정형. |
|
데이터 무결성 |
높은 수준으로 전체 ACID 규정 준수. |
최종 정합성 모델. |
|
성능 |
서버에 더 많은 리소스를 추가하는 방식으로 향상됨. |
더 많은 서버 노드를 추가하는 방식으로 향상됨. |
|
규모 조정 |
수평적 규모 조정에는 추가적인 데이터 관리 전략 필요. |
간단하게 수평적 규모 조정 가능. |
AWS는 관계형 및 비관계형 데이터베이스 요구 사항을 어떻게 지원하나요?
Amazon Web Services(AWS)는 관계형 및 비관계형 데이터베이스 요구 사항을 지원하는 다양한 서비스를 제공합니다.
관계형 데이터베이스를 위한 AWS 서비스
Amazon Relational Database Service(RDS)는 클라우드에서 간편하게 관계형 데이터베이스를 설치, 운영 및 규모를 조정할 수 있는 관리형 서비스 컬렉션입니다. 클라우드 데이터베이스는 성능, 규모 조정, 비용 효율성 등 많은 이점을 제공합니다. 다음과 같은 관계형 데이터베이스 엔진을 사용할 수 있습니다.
- SQL 서버의 여러 에디션을 배포할 수 있는 SQL 서버용 아마존 RDS (2014, 2016, 2017 및 2019)
- MySQL용 아마존 RDS, MySQL 커뮤니티 에디션 버전 5.7 및 8.0 지원
- 마리아DB 서버 버전 10.3, 10.4, 10.5 및 10.6을 지원하는 마리아DB용 아마존 RDS
또한 Oracle용 Amazon RDS에는 두 가지 라이선스 모델이 있습니다. 즉, Oracle 라이선스가 없는 경우 별도로 구매할 필요가 없습니다.
비관계형 데이터베이스를 위한 AWS 서비스
AWS는 모든 NoSQL 요구 사항을 충족하는 다양한 NoSQL 데이터베이스 서비스도 제공합니다. 다음은 몇 가지 예시입니다.
- Amazon DynamoDB는 모든 규모의 워크로드에 대해 10밀리초의 일관된 지연 시간을 제공하는 키-값 데이터베이스 서비스입니다.
- Amazon DocumentDB (MondoDB 호환) 는 유연하고 반복적인 개발을 위한 강력하고 직관적인 API를 갖춘 인기 있는 문서 지향 데이터베이스입니다.
- Amazon MemoryDB는 내구성 있는 인 메모리 데이터베이스 서비스입니다. 마이크로초의 읽기 및 쓰기 지연 시간으로 매우 빠른 성능을 제공합니다.
- Amazon Neptune은 고성능 그래프 애플리케이션을 구축하고 실행할 수 있는 완전 관리형 그래프 데이터베이스 서비스입니다.
- Amazon OpenSearch Service는 머신 생성 데이터를 거의 실시간으로 시각화하고 분석할 수 있도록 특별히 구축되었습니다.
지금 계정을 생성하여 AWS에서 관계형 및 비관계형 데이터베이스를 시작하십시오.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages