AWS Lambda
Serverless compute for every workload

AWS Lambda today
Invocations / Month
Server to Manage
One service. Multiple ways to run. Scales with your workload.
What can you build with AWS Lambda?
Build and scale any application without managing infrastructure.
Event-driven applications
How do you build applications that scale automatically in response to events?
Connect to 220+ AWS services and respond to events automatically. An object lands in Amazon S3, a record hits Amazon DynamoDB, an API call comes in. Lambda Functions handle the scaling, you handle the logic. Pay only for what runs.
Isolated code execution
How do you build dedicated isolation for every tenant, user, and session?
Run untrusted or third-party code with VM-level isolation. No shared kernel, no shared memory, no shared state between tenants. Three levels of isolation, to per-tenant isolation to full MicroVM environments, so you pick the boundary that fits your threat model.
AI agent orchestration and durable workflows
How do you run multi-step applications and agentic workflows that last hours?
Build multi-step, long-running workflows that can pause, wait for signals, retry on failure, and run for hours. Lambda durable functions gives you the control flow primitives (branching, parallelism, timeouts) without bolting on a separate orchestrator. Works for agentic AI loops, human approval chains, and saga patterns alike.
Real-time data processing
How do you process streaming and batch data at any scale?
Process streams, transform records, and fan out to downstream systems as data arrives. Lambda Functions sits natively on Amazon Kinesis, Apache Kafka, Amazon SQS, and Amazon DynamoDB Streams, so you get sub-second processing without provisioning or tuning throughput. For sustained, high-throughput pipelines, Lambda Managed Instances provide dedicated capacity with predictable latency.
Data analytics, notebooks, and interactive query platforms
How do you give every analyst their own isolated compute environment?
Preserve packages, computed results, and execution context across sessions, with no resets and no re-computation. Lambda MicroVMs launch and resume rapidly with per-tenant isolation, retain state across sessions, and pause automatically when idle so you only pay for active use.
Who’s running on Lambda at scale?
Frequently asked questions
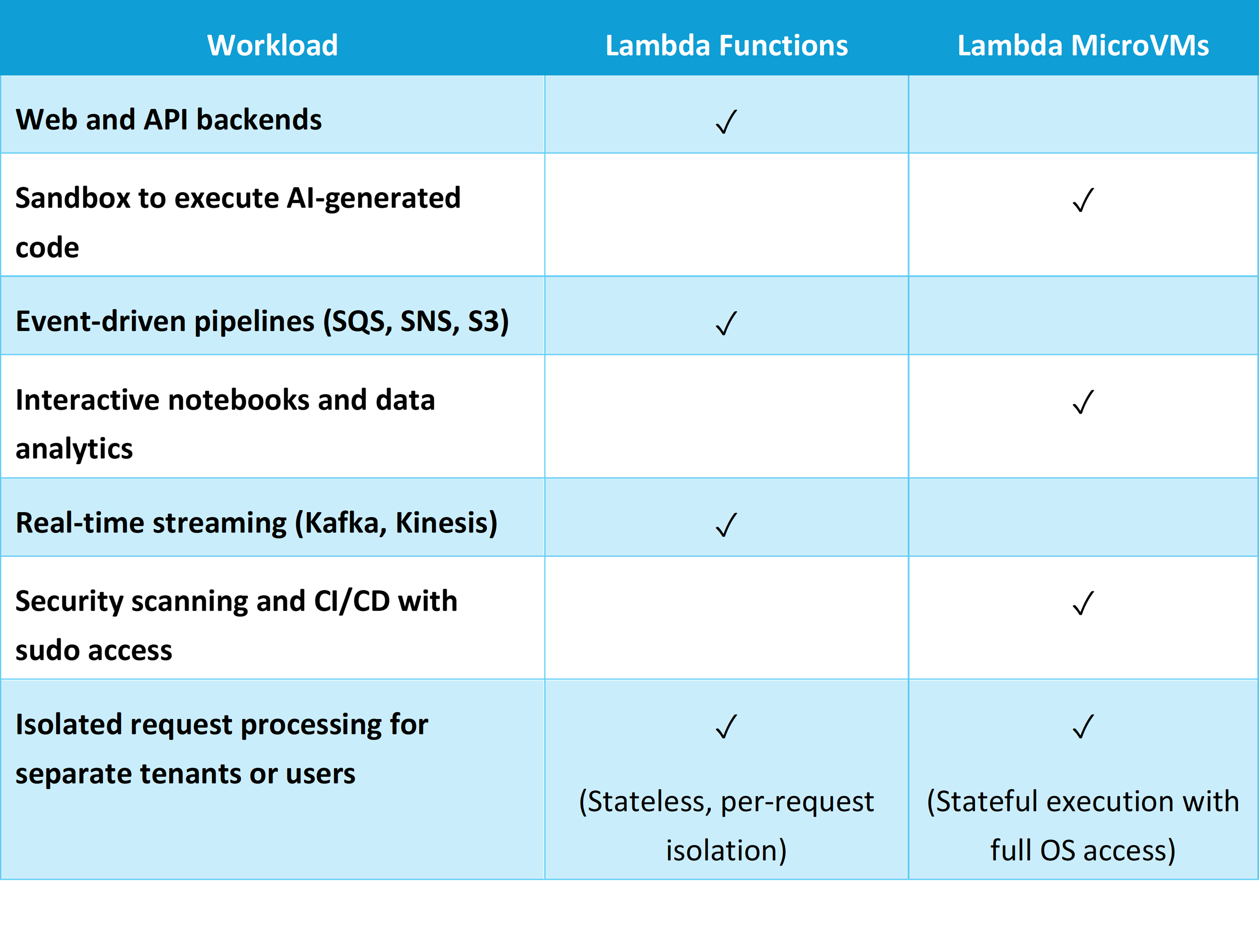
How do I choose between Lambda Functions and Lambda MicroVMs?
Lambda Functions and Lambda MicroVMs are complementary. Choose based on your workload's isolation, state, and lifecycle needs
.
When should I use Lambda Managed Instances?
Lambda runs your functions on fully managed infrastructure by default, with automatic scaling and pay-per-use pricing. Lambda Managed Instances give you dedicated EC2-backed capacity with built-in routing, load balancing, and multi-concurrency. Best for compute-intensive workloads like large-scale data processing, media transcoding, and scientific simulations. Up to 32 GB memory and 16 vCPUs, with no operational overhead.



Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages