Guidance for Advertising Agency Planning Management on AWS
Overview
How it works
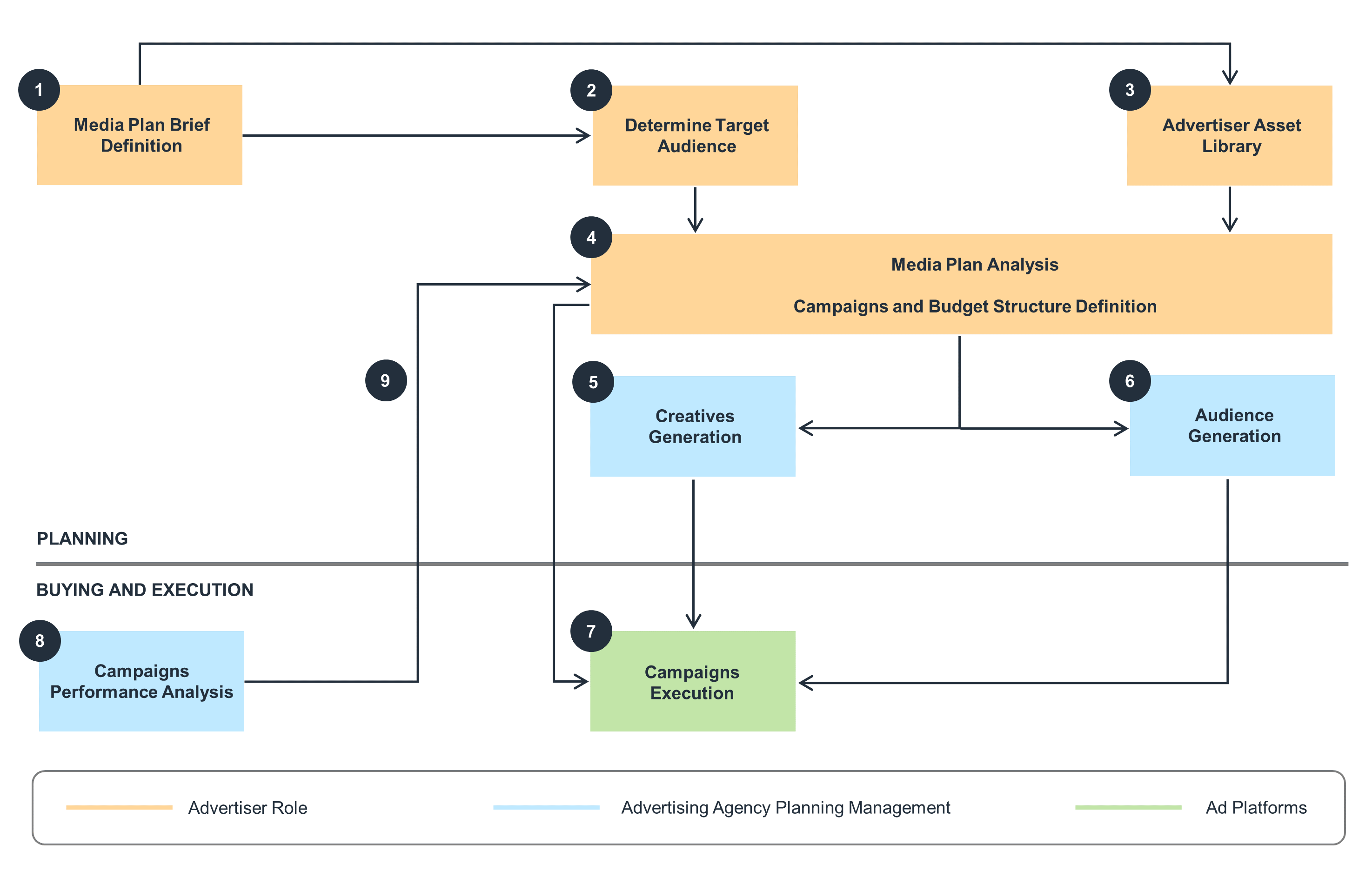
Data flow
This diagram shows the data flow process for advertising agency planning management.
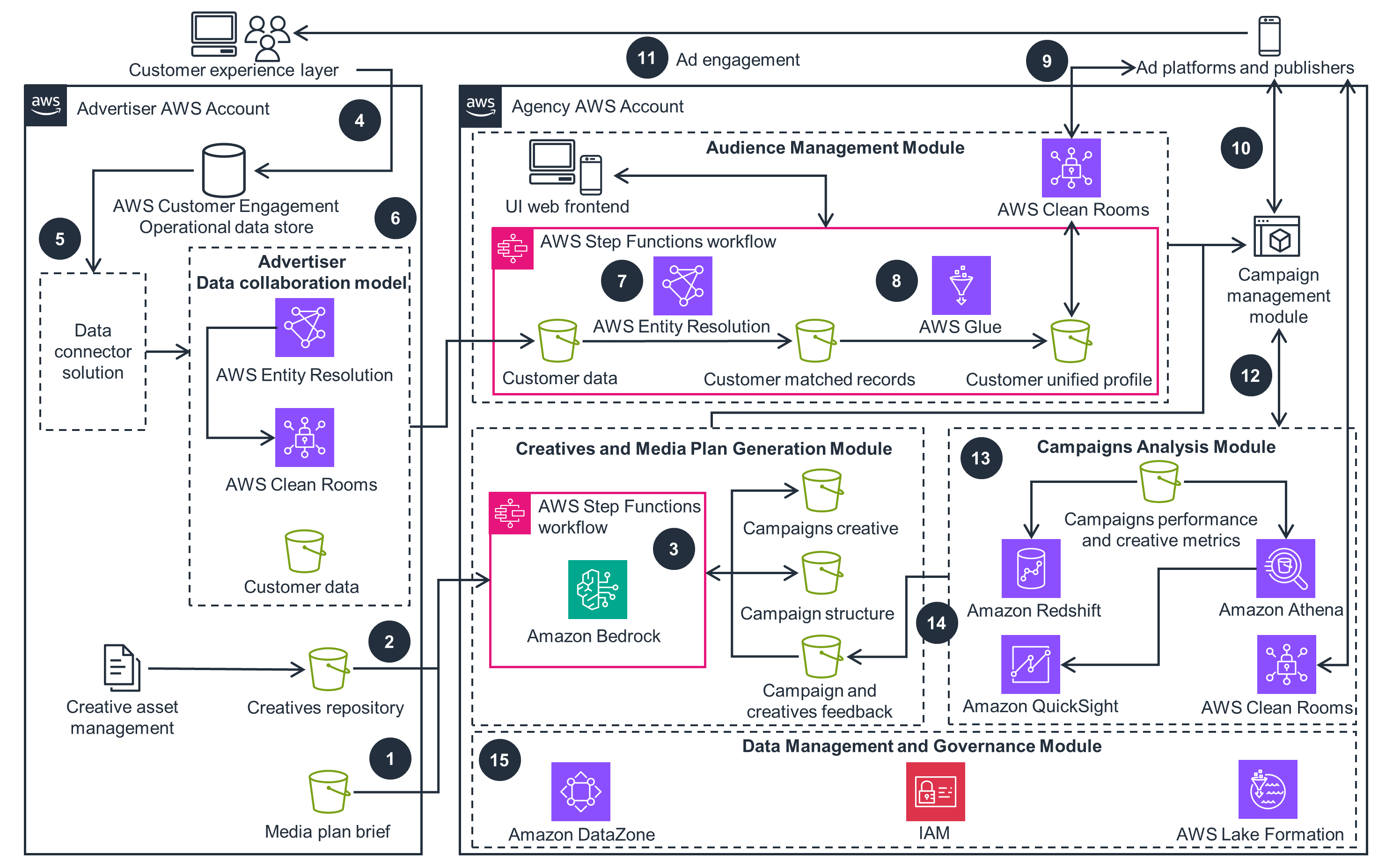
Detailed architecture diagram
This architecture diagram shows how to modernize advertising planning management in detail.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
The Guidance uses Step Functions for workflow orchestration, enabling failure anticipation, source identification, and mitigation. The core services (Amazon Bedrock, AWS Clean Rooms, and AWS Entity Resolution) are fully managed, reducing operational burden. Step Functions interacts with these services using direct integration to perform business operations, monitor data flow, and anticipate failures.
Amazon DataZone streamlines data discovery and sharing while maintaining appropriate access levels. This service creates and manages IAM roles between data producers and consumers, granting or revoking Lake Formation permissions for data sharing. By using IAM, you can help ensure that policies have minimum required permissions to limit resource access, reducing unauthorized access risks.
Step Functions orchestrates workflows by monitoring AWS Entity Resolution workflow status and direct service integration with Amazon Bedrock. Step Functions monitors workflows and automatically handles errors and exceptions with built-in try/catch and retry. It also automatically scales the operations and underlying compute to run the steps of the workflow in response to increase in requests.
You can achieve business use cases in near real-time by invoking LLM models through API calls to Amazon Bedrock. AWS Entity Resolution allows for record matching, using rule-based or machine learning (ML) models on-demand or automatically. As fully managed services that reduce overhead from managing underlying resources, Amazon Bedrock and AWS Entity Resolution enhance performance efficiency through reduced operational burdens.
S3 buckets for the campaign analytics module use the S3 Intelligent-Tiering storage class, reducing costs based on access patterns. By leveraging S3 Intelligent-Tiering, storage costs are reduced based on data access patterns.
You can review QuickSight author and reader account activity to identify and remove inactive accounts. Removing inactive QuickSight accounts minimizes the number of required subscriptions, further optimizing costs.
Athena's query result reuse feature reduces the usage of compute resources for running the same SQL queries on large datasets within a specific time period, returning the same results. This feature minimizes redundant compute resource usage, supporting sustainability efforts.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages