AWS Türkçe Blog
Düşük Maliyetli, Yüksek Performanslı Üretken Yapay Zeka Çıkarımı için Amazon EC2 Inf2 Bulut Sunucuları Genel Kullanıma Sunuldu
Orijinal makale: Link (Antje Barth)
Derin öğrenmedeki (Deep Learning – DL) yenilikler, özellikle de büyük dil modellerinin (Large Language Models – LLMs) hızlı büyümesi, sektörü kasıp kavurdu. DL modelleri, milyonlarca parametreden milyarlarca parametreye ulaştı ve heyecan verici yeni yetenekler sergiliyor. Üretken yapay zeka veya sağlık ve yaşam bilimlerinde ileri araştırma gibi yeni uygulamaları besliyorlar. AWS, bu tür DL iş yüklerini uygun ölçekte hızlandırmak için çipler, sunucular, veri merkezi bağlantısı ve yazılım genelinde yenilikler yapıyor.
AWS re:Invent 2022’de, AWS tarafından tasarlanmış en son makine öğrenimi çipi olan AWS Inferentia2 tarafından desteklenen Amazon EC2 Inf2 bulut sunucularının ön izlemesini duyurduk. Inf2 bulut sunucuları, yüksek performanslı DL çıkarım uygulamalarını küresel ölçekte çalıştırmak için tasarlanmıştır. Bu sunucular GPT-J veya Open Pre-trained Transformer (OPT) dil modelleri gibi üretken yapay zekadaki en son yenilikleri dağıtmak için Amazon EC2’daki en uygun maliyetli ve enerji açısından verimli seçeneklerdir.
Bugün, Amazon EC2 Inf2 bulut sunucularının artık genel kullanıma sunulduğunu duyurmaktan heyecan duyuyorum!
Inf2 bulut sunucuları, Amazon EC2’da hızlandırıcılar arasında ultra yüksek hızlı bağlantıyla ölçeklenebilir dağıtılmış çıkarımı destekleyen çıkarım için optimize edilmiş ilk bulut sunucularıdır. Artık yüz milyarlarca parametreye sahip modelleri Inf2 bulut sunucularında birden çok hızlandırıcıda verimli bir şekilde dağıtabilirsiniz. Amazon EC2 Inf1 bulut sunucularıyla karşılaştırıldığında, Inf2 bulut sunucuları 4 kata kadar daha yüksek aktarım hızı ve 10 kata kadar daha düşük gecikme sağlar. İşte yeni Inf2 bulut sunucularıyla kullanıma sunduğumuz temel performans iyileştirmelerini vurgulayan bir infografik:
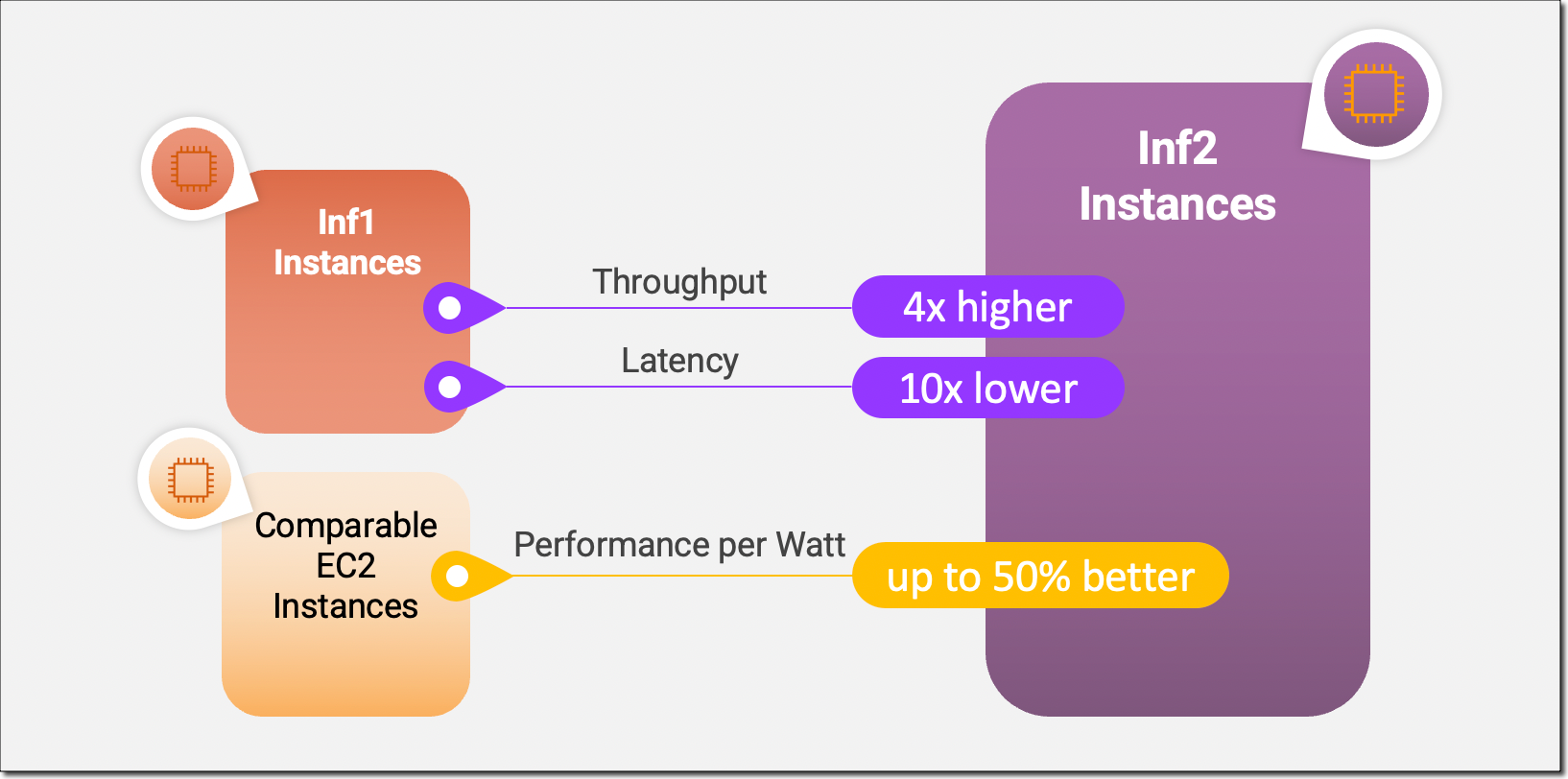
Yeni Inf2 Bulut Sunucusunda Öne Çıkanlar
Inf2 bulut sunucuları bugün dört boyutta mevcuttur ve 192 vCPU’lu 12 adede kadar AWS Inferentia2 çipi tarafından desteklenmektedir. BF16 veya FP16 veri türlerinde birleşik 2,3 petaFLOPS bilgi işlem gücü sunarlar ve çipler arasında ultra yüksek hızlı NeuronLink ara bağlantısına sahiptirler. NeuronLink, büyük modelleri birden fazla Inferentia2 çipinde ölçeklendirir, iletişim darboğazlarını önler ve daha yüksek performanslı çıkarım sağlar.
Inf2 bulut sunucuları, her Inferentia2 çipinde 32 GB yüksek bant genişliğine sahip bellek (high-bandwidth memory – HBM) ve 9,8 TB/s toplam bellek bant genişliği ile 384 GB’a kadar paylaşımlı hızlandırıcı bellek sunar. Bu tür bant genişliği, belleğe bağlı büyük dil modellerinde çıkarımı desteklemek için özellikle önemlidir.
Altta yatan AWS Inferentia2 çipleri, DL iş yükleri için özel olarak oluşturulduğundan Inf2 bulut sunucuları, diğer karşılaştırılabilir Amazon EC2 bulut sunucularına kıyasla watt başına yüzde 50’ye kadar daha iyi performans sunar. AWS Inferentia2 silikon yeniliklerini bu blog yazısının ilerleyen kısımlarında daha ayrıntılı olarak ele alacağım.
Aşağıdaki tablo, Inf2 örneklerinin boyutlarını ve özelliklerini ayrıntılı olarak listeler.
| Bulut sunucusu ismi
|
vCPU’lar | AWS Inferentia2 Çipleri | Hızlandırıcı Belleği | NeuronLink | Bulut sunucusu Belleği | Bulut sunucusu Ağ Bağlantısı |
| inf2.xlarge | 4 | 1 | 32 GB | N/A | 16 GB | Up to 15 Gbps |
| inf2.8xlarge | 32 | 1 | 32 GB | N/A | 128 GB | Up to 25 Gbps |
| inf2.24xlarge | 96 | 6 | 192 GB | Evet | 384 GB | 50 Gbps |
| inf2.48xlarge | 192 | 12 | 384 GB | Evet | 768 GB | 100 Gbps |
AWS Inferentia2 İnovasyonu
AWS Trainium çiplerine benzer şekilde, her bir AWS Inferentia2 çipinde, çok hızlandırıcılı çıkarım gerçekleştirirken hesaplama ve iletişim operasyonlarını paralel hale getirmek için iki adet geliştirilmiş NeuronCore-v2 motoru, HBM yığınları ve özel toplu bilgi işlem motorları bulunur.
Her NeuronCore-v2, DL algoritmaları için özel olarak oluşturulmuş özel skaler, vektör ve tensör motorlarına sahiptir. Tensör motoru, matris işlemleri için optimize edilmiştir. Skaler motor, ReLU (rectified linear unit – düzeltilmiş lineer birim) işlevleri gibi öge bazında işlemler için optimize edilmiştir. Vektör motoru, toplu normalleştirme veya havuzlama dahil olmak üzere, öge bazında olmayan vektör işlemleri için optimize edilmiştir.
Ek AWS Inferentia2 çip ve sunucu donanımı yeniliklerinin kısa bir özetini burada bulabilirsiniz:
- Veri Tipleri – AWS Inferentia2, FP32, TF32, BF16, FP16 ve UINT8 dahil çok çeşitli veri türlerini destekler, böylece iş yükleriniz için en uygun veri türünü seçebilirsiniz. Ayrıca, modelin bellek ayak izini ve G/Ç gereksinimlerini azalttığı için özellikle büyük modellerle ilgili olan yeni yapılandırılabilir FP8 (cFP8) veri türünü de destekler. Aşağıdaki resim, desteklenen veri türlerini karşılaştırır.

- Dinamik Yürütme, Dinamik Giriş Şekilleri – AWS Inferentia2, dinamik yürütmeye olanak tanıyan yerleşik genel amaçlı dijital sinyal işlemcilerine (digital signal processors – DSPs) sahiptir, bu nedenle kontrol akışı operatörlerinin ana sunucuda açılmasına veya yürütülmesine gerek yoktur. AWS Inferentia2, metin işleyen modeller gibi bilinmeyen giriş tensör boyutlarına sahip modeller için önemli olan dinamik giriş şekillerini de destekler.
- Özel Operatörler – AWS Inferentia2, C++ ile yazılmış özel operatörleri destekler. Neuron Custom C++ Operatörleri, NeuronCores üzerinde doğal olarak çalışan C++ özel operatörleri yazmanıza olanak tanır. CPU özel operatörlerini Neuron’a geçirmek ve yeni deneysel operatörleri uygulamak için standart PyTorch özel operatör programlama arayüzlerini kullanabilirsiniz, bunların hepsini NeuronCore donanımı hakkında derinlemesine bilgi sahibi olmadan yapabilirsiniz.
- NeuronLink v2 – Inf2 bulut sunucuları, çipler arasında doğrudan ultra yüksek hızlı bağlantı (NeuronLink v2) ile dağıtılmış çıkarımı destekleyen Amazon EC2’daki çıkarım için optimize edilmiş ilk bulut sunucusudur. NeuronLink v2, tüm çiplerde yüksek performanslı çıkarım hatlarını çalıştırmak için all-reduce gibi toplu iletişim (collective communications – CC) operatörlerini kullanır.
Aşağıdaki Inf2 dağıtılmış çıkarım karşılaştırmaları, kıyaslamalı çıkarım için optimize edilmiş Amazon EC2 bulut sunucuları üzerinden OPT-30B ve OPT-66B modelleri için aktarım hızı ve maliyet iyileştirmelerini göstermektedir.

Şimdi size Amazon EC2 Inf2 bulut sunucularını kullanmaya nasıl başlayacağınızı göstereyim.
Inf2 Bulut Sunucularını Kullanmaya Başlayın
AWS Neuron SDK, AWS Inferentia2’yu PyTorch gibi popüler makine öğrenimi (ML) çerçevelerine entegre eder. Neuron SDK, bir derleyici, çalışma zamanı ve profil oluşturma araçları içerir ve yeni özellikler ve performans optimizasyonları ile sürekli olarak güncellenir.
Bu örnekte, mevcut PyTorch Neuron paketlerini kullanarak Hugging Face‘ten önceden eğitilmiş bir BERT modelini bir EC2 Inf2 bulut sunucusunda derleyip konuşlandıracağım. PyTorch Neuron, PyTorch XLA yazılım paketini temel alır ve PyTorch işlemlerinin AWS Inferentia2 talimatlarına dönüştürülmesini sağlar.
Inf2 bulut sunucunuza SSH ile bağlanın ve PyTorch Neuron paketlerini içeren bir Python sanal ortamını etkinleştirin. Neuron tarafından sağlanan bir AMI kullanıyorsanız, aşağıdaki komutu çalıştırarak önceden yüklenmiş ortamı etkinleştirebilirsiniz:
Now, with only a few changes to your code, you can compile your PyTorch model into an AWS Neuron-optimized TorchScript. Let’s start with importing torch, the PyTorch Neuron package torch_neuronx, and the Hugging Face transformers library.
Şimdi, kodunuzda yalnızca birkaç değişiklikle PyTorch modelinizi AWS Neuron için optimize edilmiş bir TorchScript’te derleyebilirsiniz. torch, PyTorch Neuron paketi torch_neuronx ve Hugging Face transformers kitaplığını içe aktarmayla başlayalım.
Ardından, belirteç oluşturucuyu (tokenizer) ve modeli oluşturalım.
Modeli örnek girdilerle test edebiliriz. Model, girdi olarak iki cümle bekler ve çıktısı, bu cümlelerin birbirinin açılımı olup olmadığıdır.
Çıktı şuna benzer görünmelidir:
Şimdi, torch_neuronx.trace() yöntemi, işlemleri derleme için Neuron Compiler’a (neuron-cc) gönderir ve derlenen yapıtları bir TorchScript grafiğine yerleştirir. Yöntem, modeli ve bir dizi örnek girdiyi bağımsız değişken olarak bekler.
Örnek girdilerimizle Neuron tarafından derlenen modeli test edelim:
Çıktı şuna benzer görünmelidir:
Bu kadar. Yalnızca birkaç satırlık kod değişikliğiyle bir PyTorch modelini derleyip bir Amazon EC2 Inf2 bulut sunucusunda çalıştırdık. Hangi DL model mimarilerinin AWS Inferentia2 ve mevcut model destek matrisi için uygun olduğu hakkında daha fazla bilgi edinmek için AWS Neuron belgelerini ziyaret edin.
Şimdi Kullanılabilir
Inf2 bulut sunucularını bugün AWS US East (Ohio) ve US East (N. Virginia) Bölgelerinde İsteğe Bağlı, Rezerve Edilmiş ve Spot Bulut Sunucuları olarak veya bir Tasarruf Planının parçası olarak başlatabilirsiniz. Amazon EC2’da her zaman olduğu gibi yalnızca kullandığınız kadar ödersiniz. Daha fazla bilgi için Amazon EC2 fiyatlandırmasına bakabilirsiniz.
Inf2 bulut sunucuları, AWS Deep Learning AMI’leri kullanılarak dağıtılabilir ve konteyner görüntüleri, Amazon SageMaker, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS) ve AWS ParallelCluster gibi yönetilen hizmetler aracılığıyla kullanılabilir.
Daha fazla bilgi edinmek için Amazon EC2 Inf2 bulut sunucuları sayfamızı ziyaret edin ve lütfen AWS re:Post for EC2‘ya veya her zamanki AWS Destek kişileriniz aracılığıyla geri bildirim gönderin.