亚马逊AWS官方博客
Amazon File Cache — AWS 上用于本地文件系统的高性能缓存
今天我很高兴地宣布,Amazon File Cache 正式发布,这是 AWS 上一项全新高速缓存服务,旨在处理存储在不同位置(包括本地)的文件数据。File Cache 让您的应用程序可以使用快速且熟悉的 POSIX 界面访问文件,从而加速和简化要求严苛的云爆发和混合工作流程,无论原始文件是存在于可通过 NFS v3 访问的任何文件系统上还是 Amazon Simple Storage Service (Amazon S3) 上。
假设您在本地存储基础设施上有一个大型数据集,并且您的月末报告通常需要两到三天才能运行。您想将偶尔出现的工作负载转移到云端,以便在具有更多 CPU 和内存的大型计算机上运行,从而缩短处理时间。但是您还没有准备好将数据集迁移到云端。
设想另一种情况:您可以访问分布在多个区域的 Amazon Simple Storage Service (Amazon S3) 上的大型数据集。想要利用此数据集的应用程序已针对传统(POSIX)文件系统访问进行编码,并使用 awk、sed、pipes 等命令行工具。您的应用程序需要以亚毫秒级别的延迟访问文件。您无法更新源代码以使用 S3 API。
File Cache 有助于应对这些使用场景和许多其他使用场景,考虑视频文件、AI/ML 数据集等的管理和转换。File Cache 在一个或多个区域的 NFS v3 文件系统或 S3 存储桶前创建基于文件系统的缓存。它透明地从源加载文件内容和元数据(例如文件名、大小和权限),并将其作为传统文件系统呈现给您的应用程序。File Cache 会自动释放最近较少使用的缓存文件,以确保最活跃的文件在缓存中可供应用程序使用。
您最多可以将八个 NFS 文件系统或八个 S3 存储桶链接到一个缓存,它们将显示为一组统一的文件和目录。您可以从各种 AWS 计算服务(例如虚拟机或容器)访问缓存。File Cache 和您的本地基础设施之间的连接使用您现有的网络连接,基于 AWS Direct Connect 和/或 Site-to-Site VPN。
使用 File Cache 时,您的应用程序将受益于一致的亚毫秒级延迟、高达数百 GB/s 的吞吐量以及高达每秒数百万次的操作。与 Amazon Elastic Block Store (Amazon EBS) 等其他存储服务类似,性能取决于缓存的大小。缓存大小可以扩展到 PB 级,最小大小为 1.2 TiB。
下面我们来看看它的工作原理
为了向您展示它是如何工作的,我在两个现有的 Amazon FSx for OpenZFS 文件系统上创建了一个文件缓存。在真实场景中,您很可能会在本地文件系统上创建缓存。我选择 FSx for OpenZFS 进行演示是因为我手头没有本地数据中心(我可能应该投资于 seb-west-1)。两个演示 OpenZFS 文件系统都可以从我的 AWS 账户中的私有子网访问。最后,我从 EC2 Linux 实例访问缓存。
首先,打开浏览器并导航到 AWS 管理控制台。我在控制台的搜索栏中搜索“Amazon FSx”,然后单击左侧导航菜单中的缓存。或者,我直接进入控制台的 File Cache 部分。首先,我选择创建缓存。
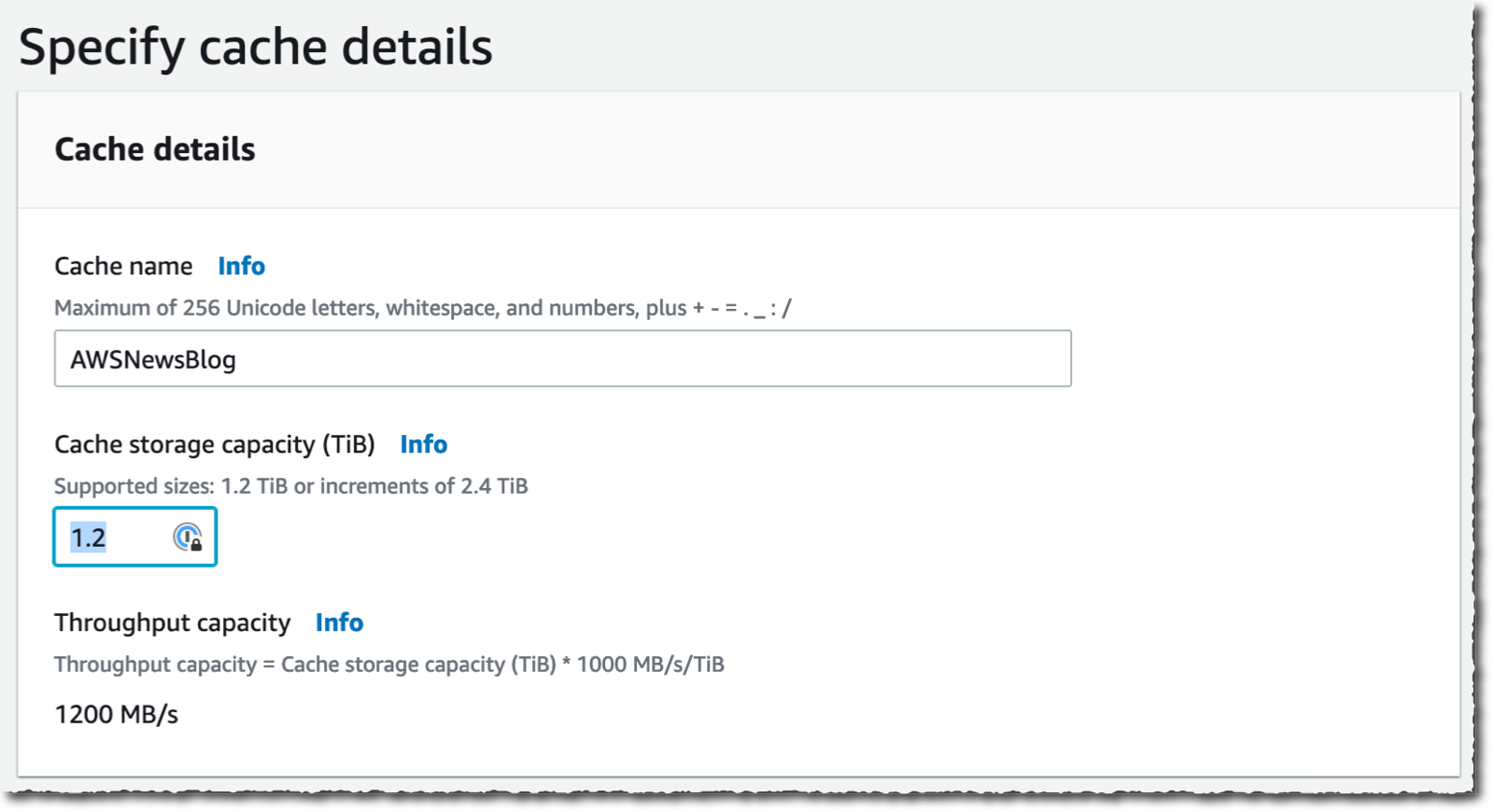
 我为我的缓存输入缓存名称(此演示为 AWSNewsBlog)和缓存存储容量。存储容量以 TiB 表示。最小值为 1.2 TiB 或以 2.4 TiB 为增量。请注意,当您选择较大的缓存大小时,吞吐能力会增加。
我为我的缓存输入缓存名称(此演示为 AWSNewsBlog)和缓存存储容量。存储容量以 TiB 表示。最小值为 1.2 TiB 或以 2.4 TiB 为增量。请注意,当您选择较大的缓存大小时,吞吐能力会增加。
 我检查并接受为联网和加密提供的默认值。对于联网,我可能会选择一个 VPC、子网和安全组来关联我的缓存网络接口。建议将缓存部署在与计算服务相同的子网中,以最大限度地减少访问文件时的延迟。对于加密,我可以使用 AWS KMS 管理的密钥(默认)或选择自己的密钥。
我检查并接受为联网和加密提供的默认值。对于联网,我可能会选择一个 VPC、子网和安全组来关联我的缓存网络接口。建议将缓存部署在与计算服务相同的子网中,以最大限度地减少访问文件时的延迟。对于加密,我可以使用 AWS KMS 管理的密钥(默认)或选择自己的密钥。
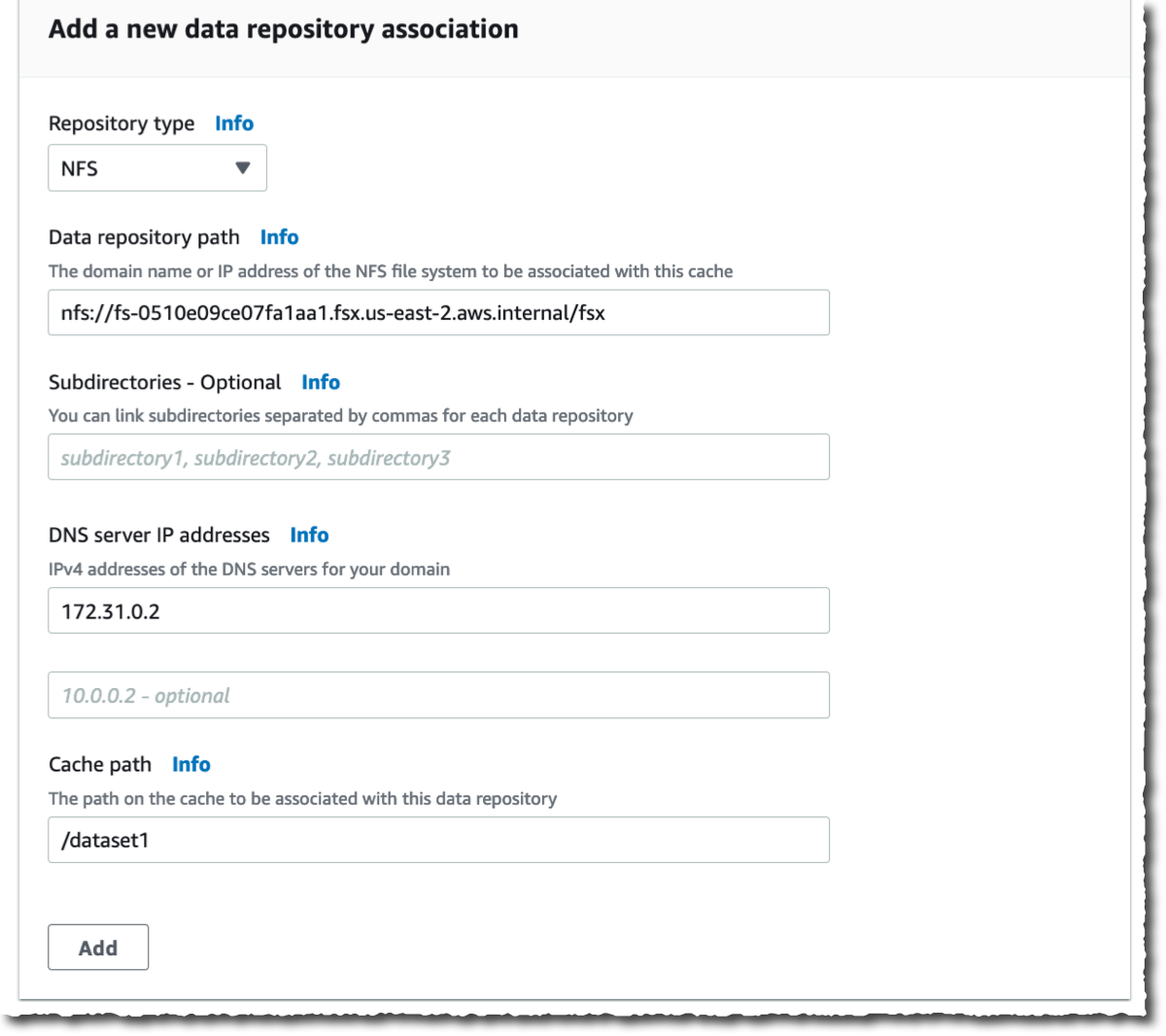
然后,我创建了数据存储库关联。这是缓存和数据来源之间的链接。数据来源可能是 NFS 文件系统、S3 存储桶或前缀。我可能为一个缓存创建多达八个数据存储库关联。缓存的所有数据存储库关联都具有相同的类型:它们全部都是 NFS v3 或者全部都是 S3。如果需要两种类型,则可以创建两个缓存。
在这个演示中,我选择关联我的 AWS 账户上的两个 OpenZFS 文件系统。您可以链接到任何 NFS v3 服务器,包括您在本地已经拥有的服务器。缓存路径允许您选择将源文件系统安装在缓存中的位置。数据存储库路径是指向您的 NFS v3 或 S3 数据存储库的 URL。格式为 nfs://hostname/path 或 s3://bucketname/path。
DNS 服务器 IP 地址允许 File Cache 解析您的 NFS 服务器的 DNS 名称。这在 DNS 解析是私有时很有用,比如在我的例子中。当您关联在 VPC 中部署的 NFS v3 服务器,以及使用 AWS 提供的 DNS 服务器时,您的 VPC 的 DNS 服务器 IP 地址为 VPC 范围 + 2。在我的示例中,我的 VPC CIDR 范围是 172.31.0.0,因此 DNS 服务器 IP 地址是 172.31.0.2。
别忘了点击添加按钮! 否则,您的输入将被忽略。您可以重复该操作以添加更多数据存储库。
 |
 |
输入两个数据存储库后,我选择下一步,然后查看我的选择。准备就绪后,我选择创建缓存。

几分钟后,缓存状态变为 ✅ 可用。

最后一部分是在部署我的工作负载的计算机上安装缓存。File Cache 在后台使用 Lustre。正如我们的文档中所述,我必须先安装适用于 Linux 的 Lustre 客户端。完成后,我选择控制台上的附加按钮以接收下载和安装 Lustre 客户端以及安装缓存文件系统的说明。 为此,我连接到在同一 VPC 中运行的 EC2 实例。然后我输入:
为此,我连接到在同一 VPC 中运行的 EC2 实例。然后我输入:
sudo mount -t lustre -o relatime,flock file_cache_dns_name@tcp:/mountname /mnt这个命令通过两个选项安装我的缓存:
relatime– 维护atime(inode 访问时间)数据,但不是每次访问文件时都进行维护。启用此选项后,仅当自上次更新atime数据(mtime)以来修改了文件或上次访问文件超过一定时间(默认为一天)后,才将atime数据写入磁盘。自动缓存驱逐需要relatime才能正常工作。flock— 为您的缓存启用文件锁定。如果您不想启用文件锁定,请在不使用 flock 的情况下使用 mount 命令。
安装后,在我的 EC2 实例上运行的进程可以照常访问缓存中的文件。正如我在创建缓存时定义的那样,第一个 ZFS 文件系统在 /dataset1 的缓存中可用,第二个 ZFS 文件系统可用作 /dataset2。
$ echo "欢迎来到 File Cache 世界" > /mnt/zsf1/greetings
$ sudo mount -t lustre -o relatime,flock fc-0280000000001.fsx.us-east-2.aws.internal@tcp:/r3xxxxxx /mnt/cache
$ ls -al /mnt/cache
total 98
drwxr-xr-x 5 root root 33280 Sep 21 14:37 .
drwxr-xr-x 2 root root 33280 Sep 21 14:33 dataset1
drwxr-xr-x 2 root root 33280 Sep 21 14:37 dataset2
$ cat /mnt/cache/dataset1/greetings
欢迎来到 File Cache 世界
我可以使用 Amazon CloudWatch 指标和 AWS CloudTrail 日志监控来观察和评估我的缓存的活动和运行状况。
File Cache 资源的 CloudWatch 指标分为三类:
- 前端 I/O 指标
- 后端 I/O 指标
- 缓存前端利用率指标
像往常一样,我可以创建仪表板或定义警报,以便在指标达到我定义的阈值时收到通知。
注意事项
在使用或计划使用 File Cache 时,需要记住几个关键点。
首先,File Cache 会对静态数据进行加密,并支持对传输中数据进行加密。您的数据始终使用 AWS Key Management Service (AWS KMS) 中管理的密钥进行静态加密。您可以使用服务自有密钥或自己的密钥(客户管理的 CMK)。
其次,File Cache 提供了两个用于将数据从数据存储库导入缓存的选项:延迟加载和预加载。延迟加载会在数据尚未缓存时按需导入数据,预加载则会在启动工作负载之前根据用户请求导入数据。默认设置为延迟加载。这对大多数工作负载都很有意义,因为它允许您的工作负载启动,而无需等待元数据和数据被导入缓存。当您的访问模式注重首字节延迟时,预加载会很有帮助。
定价和可用性
使用 File Cache 时没有预付费用或固定价格成本。您需要为预置的缓存存储容量和元数据存储容量付费。定价页面包含详细信息。除了 File Cache 本身之外,您还需要支付 S3 请求费用、AWS Direct Connect 费用以及文件缓存和数据来源之间的可用区间、区域间和互联网出口流量的通常数据传输费用。
File Cache 现已在以下地区推出:美国东部(俄亥俄州)、美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、加拿大(中部)、欧洲(法兰克福)、欧洲地区(爱尔兰)和欧洲地区(伦敦)。
现在就开始构建并创建您的第一个 File Cache 吧!