亚马逊AWS官方博客
宣布推出 AWS Glue DataBrew – 一种可帮助您更快地清理和标准化数据的可视化数据准备工具
为了能够运行分析、构建报告或应用机器学习,您需要确保您使用的数据清晰且格式正确。这就是数据准备步骤,该步骤需要数据分析师和数据科学家编写自定义代码并执行很多手动操作。首先,您需要查看数据、了解存在哪些可能的值,并构建一些简单的可视化,以了解各列之间是否存在相关性。然后,您需要检查超出预期值的异常值,例如天气温度超过 200℉ (93℃) 或卡车速度超过 200 英里/小时 (322 km/h),或数据缺失。很多算法需要将值重新扩展到特定范围,例如 0 到 1 之间或者围绕均值进行归一化。文本字段需要设置为标准格式,并且可能需要词干提取之类的高级转换。
这个工作量很大。因此,我很高兴地宣布 AWS Glue DataBrew 现已推出,该服务是一个可视化数据准备工具,可帮助您将清理和标准化数据的速度最高提高 80%,使您可以更加专注于您所能获得的商业价值。
DataBrew 提供一个可视化界面,让您可以快速连接到您在 Amazon Simple Storage Service (S3)、Amazon Redshift、Amazon Relational Database Service (RDS)、任何 JDBC 可访问数据存储或 AWS Glue Data Catalog 索引的数据中存储的数据。然后,您可以探索数据、查找模式和应用转换。例如,您可以应用联接和透视表、合并不同的数据集或使用函数操作数据。
数据准备就绪后,您可以立即将其与 AWS 和第三方服务结合使用,以获得进一步的见解,例如用于机器学习的 Amazon SageMaker、用于分析的 Amazon Redshift 和 Amazon Athena 以及用于商业智能的 Amazon QuickSight 和 Tableau。
AWS Glue DataBrew 的工作原理
要使用 DataBrew 准备数据,您需要遵照以下步骤:
- 从 S3 或 Glue 数据目录 (S3、Redshift、RDS) 中连接一个或多个数据集。您还可以从 DataBrew 控制台将本地文件上传到 S3 中。支持 CSV、JSON、Parquet 和 .XLSX 格式。
- 创建项目以可视化地探索、了解、合并、清理和标准化数据集中的数据。您可以合并或加入多个数据集。在控制台中,您可以使用价值分布、直方图、盒型图和其他可视化效果快速发现数据中的异常情况。
- 通过在配置文件视图中运行作业,使用 40 多个统计数据为您的数据集生成丰富的数据配置文件。
- 选择列时,您将获得有关如何提高数据质量的建议。
- 您可以使用 250 多种内置转换来清理和标准化数据。例如,您可以删除或替换空值,或创建编码。每个转换都会作为构建 配方的步骤自动添加。
- 然后,您可以保存、发布和对配方进行版本控制,并通过对所有传入数据应用配方来自动执行数据准备任务。要将配方应用于大型数据集或为其生成配置文件,您可以运行作业。
- 在任何时间点,您都可以可视化跟踪和探索数据集与项目、配方和作业运行关联的方式。通过这种方式,您可以了解数据是如何流动的以及发生了哪些变化。此信息称为数据沿袭,可以帮助您在输出中出现错误时找到根本原因。
我们来通过一个快速演示了解下具体的工作原理!
使用 AWS Glue DataBrew 准备样本数据集
在 DataBrew 控制台中,我选择 Projects(项目)选项卡,然后选择 Create project(创建项目)。我把新项目命名为 Comments。此外,还创建了一个新配方,并将使用我接下来将应用的数据转换自动更新该配方。

我选择处理 New dataset(新数据集)并将其命名为 Comments。

我在此选择 Upload file(上传文件),并在下一个对话框中上传为此演示准备的 comments.csv 文件。在生产使用案例中,您可能会在此处连接 S3 或 Glue Data Catalog 中的现有源。在本演示中,我指定 S3 目标来存储上传的文件。我将 Encryption(加密)保留禁用。

comments.csv 文件非常小,但将帮助显示一些常见的数据准备需求以及如何使用 DataBrew 快速完成它们。文件的格式为逗号分隔值 (CSV)。第一行包含列名称。然后,每一行都包含一条文本评论以及客户 (customer_id) 对项目 (item_id) 进行的数值评级。每个项目都是类别的一部分。对于每条文本评论,都指示了总体情绪 (comment_sentiment)。或者,在进行评论时,客户可以启用标记来请求联系以获得进一步支持 (support_needed)。
下面是 comments.csv 文件的内容:
在 Access permissions(访问权限)中,我选择 AWS Identity and Access Management (IAM) 角色,从而为我的输入 S3 存储桶提供 DataBrew 读取权限。DataBrew 控制台中只显示 DataBrew 为信任策略服务主体的角色。要在 IAM 控制台中创建一个角色,请将 DataBrew 选为信任实体。

如果数据集很大,则可以使用采样来限制要在项目中使用的行数。这些行可以在开始和最后选择,也可以通过数据随机选择。您将使用项目创建配方,然后使用作业将配方应用于所有数据。根据您的数据集,您可能不需要访问所有行即可定义数据准备配方。
或者,您可以使用标记来管理、搜索或筛选您使用 AWS Glue DataBrew 创建的资源。
该项目现在正在准备中,几分钟后我就可以开始探索我的数据集。
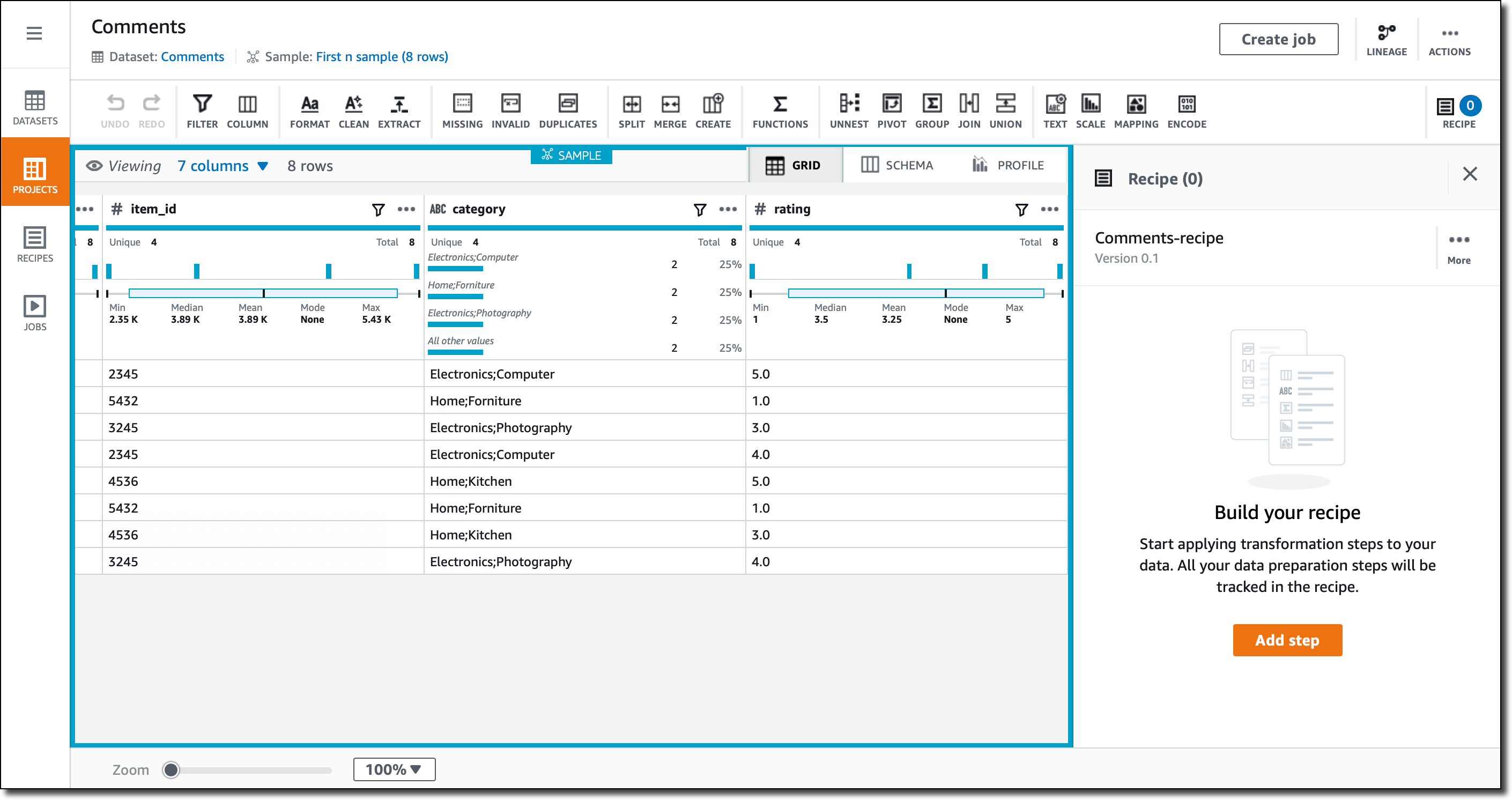
在 Grid(网格)视图(创建新项目时的默认视图)中,我会看到已导入的数据。每一列都列出了已找到的值范围的摘要。对于数字列,给出了统计分布。
在 Schema 视图中,我可以深入了解已推理的 Schema,或者可以选择隐藏一些列。
在 Profile(配置文件)视图中,我可以运行数据配置文件作业,以检查并收集有关数据的统计摘要。这是在结构、内容、关系和推导方面进行的评估。在大型数据集中,这对于了解数据非常有用。对于这个小示例来说,益处是有限的,但是我仍然运行它,将配置文件作业的输出发送到我用来存储源数据的同一 S3 存储桶中的另一个文件夹。
配置文件作业成功后,我可以看到数据集中的行和列摘要、有效的列和行数以及列之间的关联。
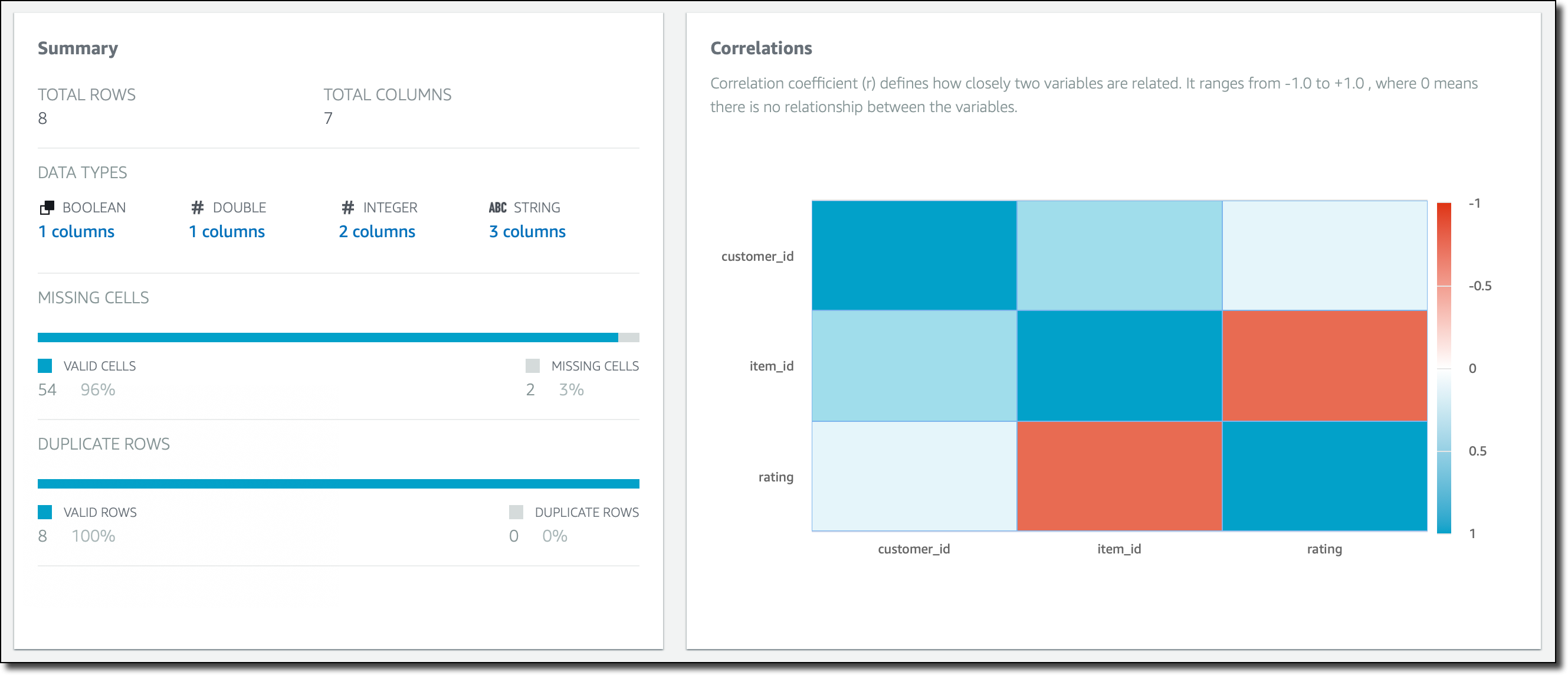
如果我在这里选择列,例如评级,我可以深入了解特定的统计信息及该列的关系。
现在,让我们做一些实际的数据准备。在 Grid(网格)视图中,查看各列。类别包含两条信息,用分号分隔。例如,第一行的类别 是“Electronics;Computers”。 我选择类别列,然后单击列操作(列名右侧的三个小点),然后在那里我可以访问很多可以应用于该列的转换。在此情况下,我选择以单个分隔符拆分列。在应用更改之前,我在控制台中快速预览它们。

我将分号用作分隔符,现在我有两个列 category_1 和 category_2。我再次使用列操作将它们重命名为类别和子类别。现在,在第一行中,类别包含“电子”, 子类别包含计算机。所有这些更改都作为项目配方的步骤添加,以便我能够将它们应用于类似的数据。
评级列包含 1 到 5 之间的值。在很多算法中,我更喜欢将这些值标准化。在列操作中,我使用最小值-最大值标准化来重新调整 0 到 1 之间的值。还有更高级的技术可用,例如平均值或 Z-评分标准化。添加一个新的 rating_normalized 列。
我查看了 DataBrew 为评论列提供的建议。由于它是文本,建议使用标准案例格式,例如小写、大写或句子首字母大写。我选择小写。
评论包含客户编写的自由文本。为了简化进一步的分析,我使用列上的单词标记来删除停止词(例如“a”、“an”、“the”)、展开缩写(因此“don’t”变为“do not”),然后应用词干提取。这些更改的目的地是新列 comment_tokenized。
comment_tokenized 列中仍然有一些特殊字符,例如表情 :-)。在列操作中,我选择清理和删除特殊字符。
我查看了 comment_sentiment 列的建议。有一些缺失的值。我决定用中性情绪填补缺失的值。现在,我仍然有用不同的大小写编写的的值,因此,我按照建议为此列使用小写字母 。
comment_sentiment 列现在包含三个不同的值(正值、负值或中性值),但很多算法更喜欢独热编码,在这种情况下,每一个可能的值都有一个列,且这些列包含 1(如果这是原始值)或者 0。我选择菜单栏中的 Encode(编码)图标,然后选择独热编码列。我保留默认值并应用。三个可能值的三个新列添加上。
support_needed 列被识别为布尔值,它的值会自动格式化为标准格式。我不需要在此执行任何操作。
我的数据集配方现在已准备好发布,可用于处理类似数据的重复作业。我没有太多数据,但是这个配方可以用于更大的数据集。
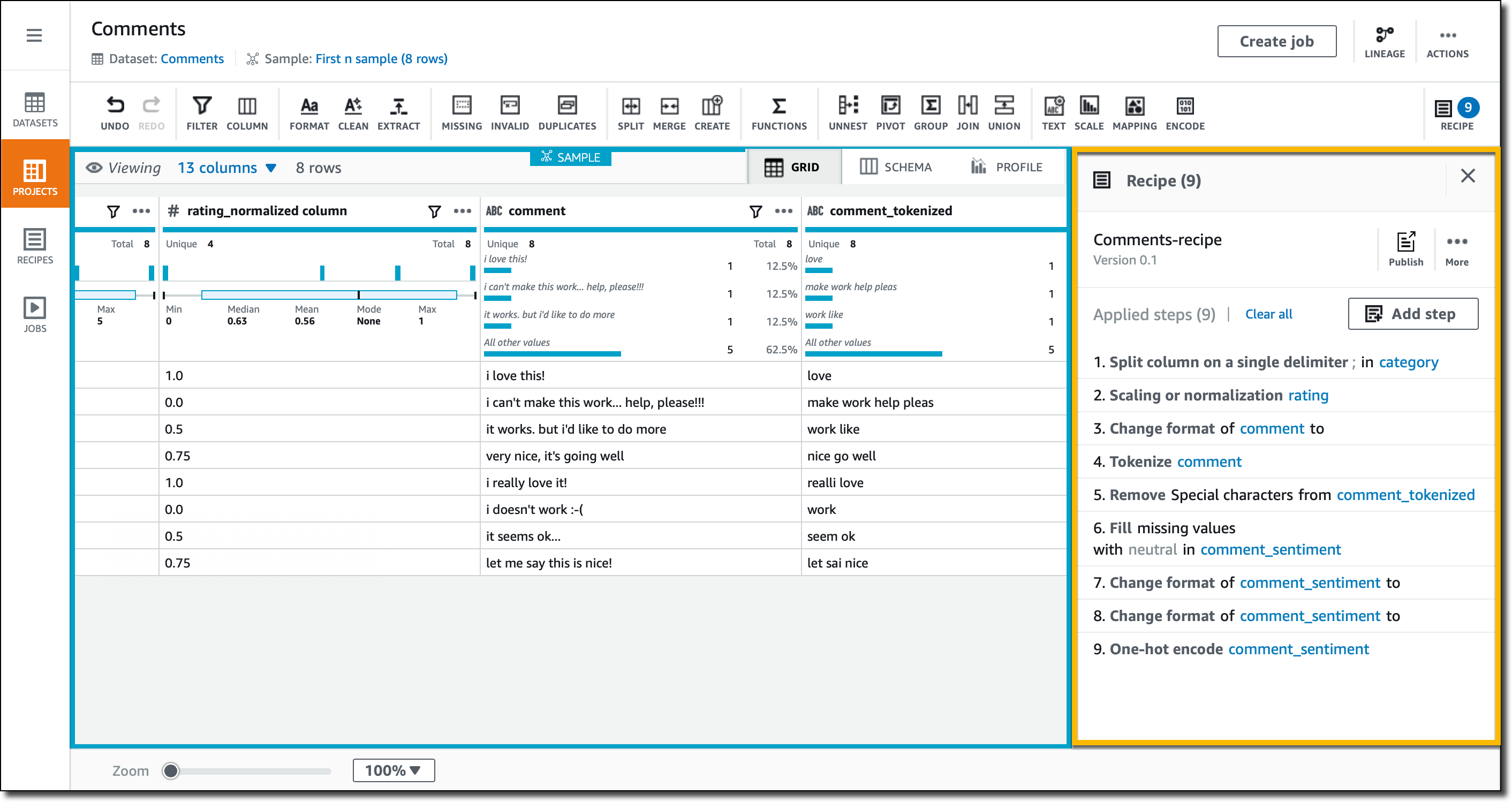
在配方中,您可以找到我刚才应用的所有转换的列表。运行配方作业时,输出数据在 S3 中可用并且可用于分析和机器学习平台,或者使用 BI 工具构建报告和可视化。输出可以使用与输入不同的格式编写,例如使用像 Apache Parquet 这样的列式存储格式。

现已推出
AWS Glue DataBrew 现已在美国东部(弗吉尼亚北部)、美国东部(俄亥俄)、美国西部(俄勒冈)、欧洲(爱尔兰)、欧洲(法兰克福)、亚太地区(东京)、亚太地区(悉尼)推出。
为分析、机器学习或 BI 准备数据从未如此简单。通过这种方式,您可以真正专注于获得适合您业务的见解,而不是编写随后必须维护和更新的自定义代码。
要练习使用 DataBrew,您可以创建新项目并选择提供的示例数据集之一。这是了解所有可用功能以及如何将它们应用于数据的好方法。
了解更多信息并立即开始使用 AWS Glue DataBrew。
– Danilo