亚马逊AWS官方博客
AWS DeepLens – 通过新式摄像机获得深度学习实践经验
我以前说过,“活到老,学到老”是我的人生信条之一。技术变革的速度越来越快,您也需要加快学习速度,迅速掌握全新技能。
在我职业生涯的大部分时间里,人工智能一直是一个学术课题,实际应用和实际部署始终是“若即若离”。但随着机器学习 (包括计算机视觉和深度学习) 实际应用的不断增多,可以肯定地说,现在是获得实践经验和掌握新技能的时候了!此外,物联网和无服务器计算也备受瞩目。虽然这两者的提出时间不算早,但它们必将在未来占据一席之地,是您最该掌握的众多技能之一。
新的 AWS DeepLens
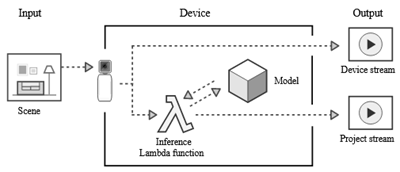 今天我将跟大家介绍一下 AWS DeepLens – 一种直接在设备上运行深度学习模型的新式视频摄像机。您可以使用它构建炫酷的应用程序,同时获得人工智能、物联网和无服务器计算方面的实践经验。AWS DeepLens 结合了先进的硬件和精密的机载软件,让您能够在应用程序中使用 AWS Greengrass、AWS Lambda、其他 AWS AI 及基础设施服务。
今天我将跟大家介绍一下 AWS DeepLens – 一种直接在设备上运行深度学习模型的新式视频摄像机。您可以使用它构建炫酷的应用程序,同时获得人工智能、物联网和无服务器计算方面的实践经验。AWS DeepLens 结合了先进的硬件和精密的机载软件,让您能够在应用程序中使用 AWS Greengrass、AWS Lambda、其他 AWS AI 及基础设施服务。
我们先从硬件谈起。此设备包含众多强大功能。它配备一个可拍摄 1080P 视频的 400 万像素摄像头,以及一个 2D 麦克风阵列。其搭载的 Intel Atom® 处理器提供超过 100 GLOPS 的计算能力,每秒足以通过机载深度学习模型对数十帧传入视频进行运算。DeepLens 具有完善的连接能力,提供双频 Wi-Fi、USB 及微型 HDMI 端口。最后,这部小巧的设备具有 8 GB 内存,能够运行您的预训练模型和代码,提供无与伦比的强大能力。
在软件方面,AWS DeepLens 运行的是 Ubuntu 16.04,预装 Greengrass Core (Lambda 运行时、消息管理器等)。它还提供专为此设备优化的 MXNet 版本,并具备使用 TensorFlow、Caffe2 等其他框架的灵活性。Intel® clDNN 库提供一套用于计算机视觉和其他人工智能工作负载的深度学习基元,利用 Intel Atom® 处理器的特殊功能加快推理。
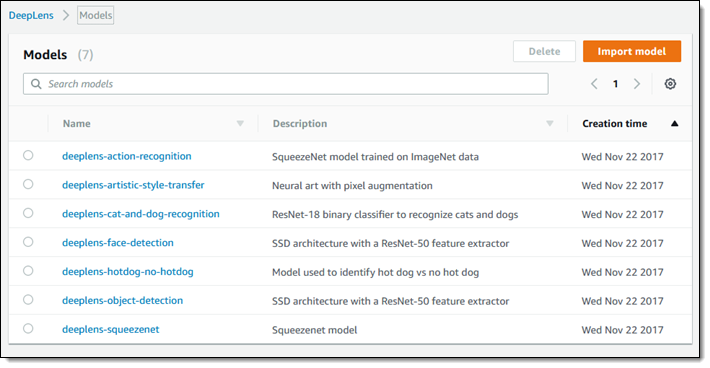
我们还为您提供数据!当构建在 AWS DeepLens 上运行的应用程序时,您可以使用一组预训练模型进行图像检测和识别。这些模型将帮助您检测猫、狗、人脸、众多家用和日常物品、动作和行动,甚至是热狗。我们将继续训练和完善这些模型。下面是最初的一组模型:
所有这些硬件、软件和数据汇集到一起,使 AWS DeepLens 成了边缘设备的典型示例。借助这些位于现场和靠近动作的眼睛、耳朵和十分强劲的大脑,它能够通过机载深度学习模型快速、低延迟地运行传入视频和音频,并利用云完成计算密集度更高的高阶处理。例如,您可以在 DeepLens 上进行面部检测,然后让 Amazon Rekognition 处理面部识别工作。
这是个利用现成工具进行学习的绝佳机会!我们还为其提供了大量的示例代码 (Lambda 函数),您可以按原样使用,进行分解和学习,或基于这些示例代码编写自己的函数。当构建出一些很酷且有用的东西时,您可以按生产形式部署它们。我们确保 AWS DeepLens 强大又安全 – 每个设备都有唯一的证书,通过 IAM 精细控制对 AWS 服务和资源的访问。
注册设备
下面,我们演练一下注册设备和使设备做好使用准备的过程。首先,打开 DeepLens 控制台,单击 Register device:
为摄像机输入一个名称,然后单击 Next:
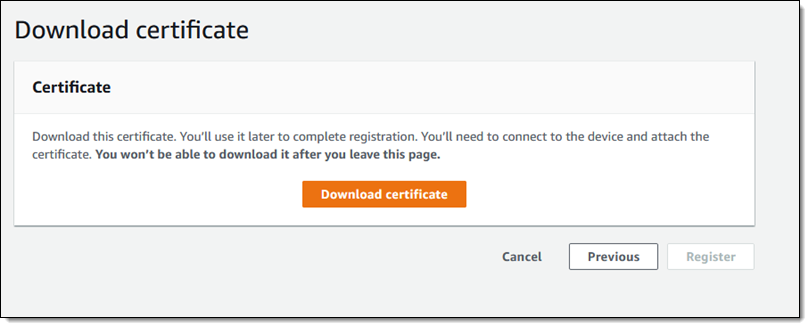
单击 Download certificate 并将其保存到一个安全的地方:
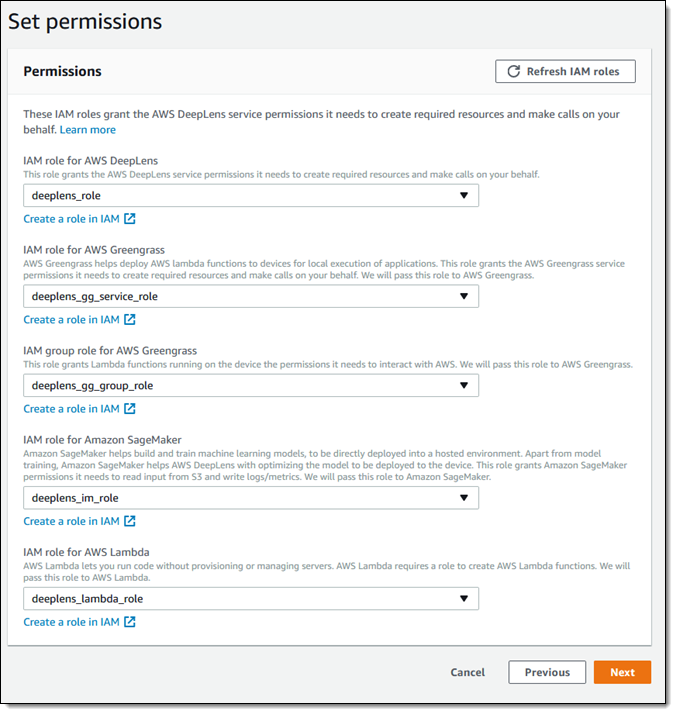
接下来,创建必要的 IAM 角色 (控制台简化了这一操作),在相应菜单中选择每个角色:
现在我可以正常使用 DeepLens 了!打开电源,将笔记本电脑连接到此设备的网络,然后访问内置门户来完成此过程。控制台概述了以下步骤:
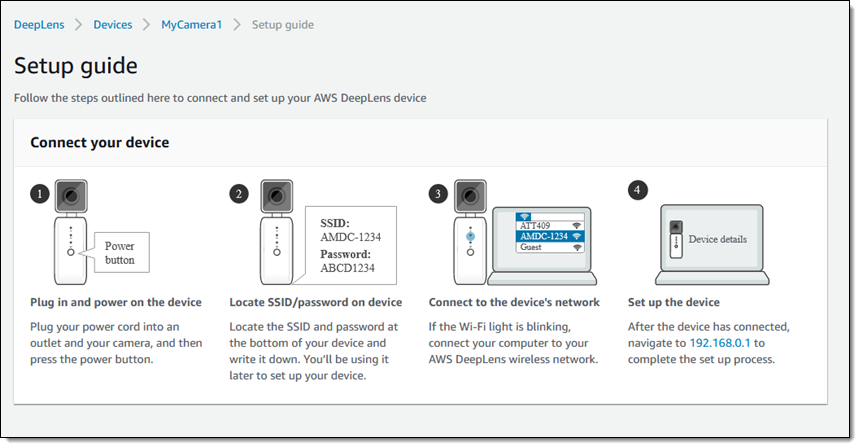
现在,我的 DeepLens 就是一个功能完备的边缘设备。设备上的证书允许其对 AWS 进行安全的签名调用。Greengrass Core 正在运行,准备接受并运行 Lambda 函数。
创建 DeepLens 项目
完成连接和设置工作后,我可以创建第一个项目了。导航到 Projects,然后单击 Create new project:
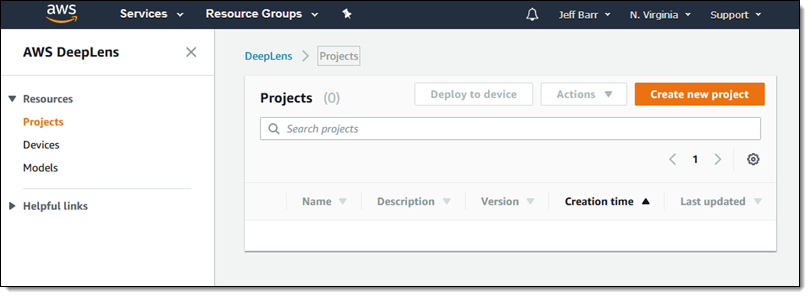
可以选择一个项目模板,或从空白项目开始。我选择了 cat and dog recognition,然后单击 Next:
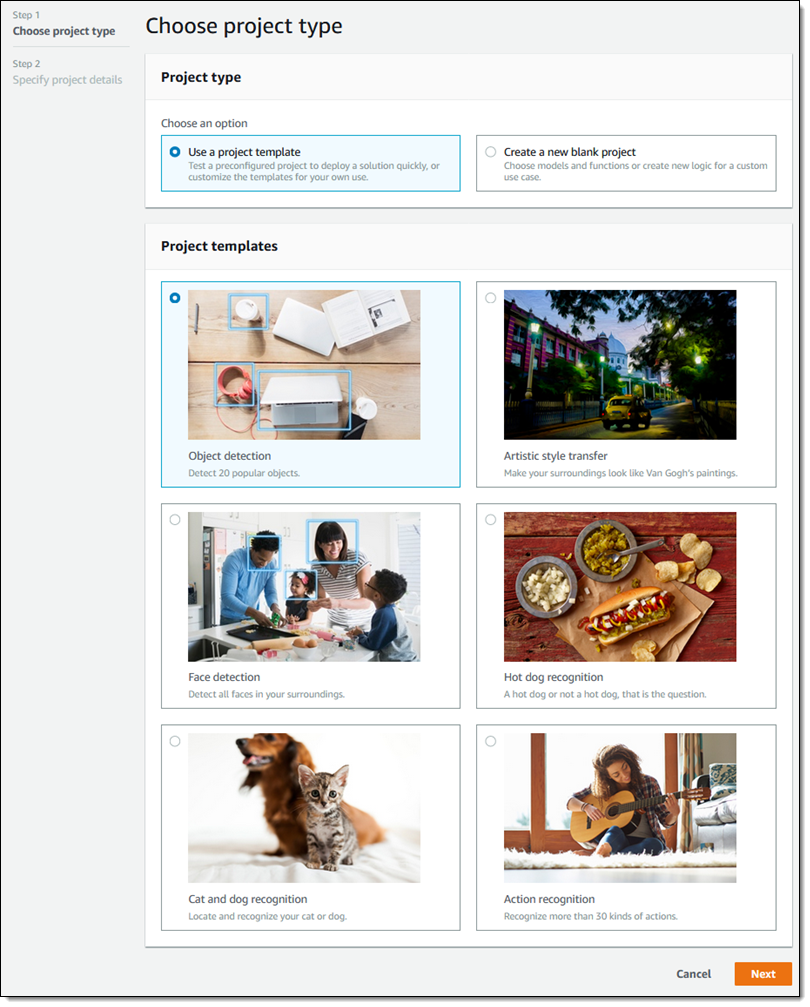
控制台提供了命名和自定义项目的机会。正如您所看到的,这个项目引用了一个 Lambda 函数和我在上文列出的预训练模型之一。默认设置满足我的要求,所以我直接单击 Create:
现在,只需将项目部署到摄像机:
猫/狗识别训练
函数在摄像机上运行,将输出发布到 MQTT 主题。下面是从猫/狗识别函数的内部循环中摘录的一段代码 (删除了一些错误处理内容):
while doInfer:
# 获取视频流中的一帧
ret, frame = awscam.getLastFrame()
numFrames += 1
# 调整帧大小以符合模型输入要求
frameResize = cv2.resize(frame, (224, 224))
# 对调整后的帧运行模型推理
inferOutput = model.doInference(frameResize)
# 以每 100 帧为单位向云发布消息
if numFrames >= 10:
msg = "Infinite inference is running. Sample result of the last frame is\n"
# 将最后一帧的推理结果输出到云
# awsca 模型可以分析某些已知模型的输出
outputProcessed = model.parseResult(modelType, inferOutput)
# 获取可能性最高的前 5 个结果
topFive = outputProcessed[modelType][0:2]
msg += "label prob"
for obj in topFive:
msg += "\n{} {}".format(outMap[obj["label"]], obj["prob"])
client.publish(topic=iotTopic, payload=msg)
numFrames = 0;
就像我之前说的那样,您可以修改此示例代码,也可以从头开始。如您所见,不管使用哪种方式,都可以轻松上手。
我已经迫不及待想要知道您拿到 DeepLens 后会做些什么了。请务必参加在 AWS re:Invent 上举办的 DeepLens 研讨会 (共十六场),不仅可进一步了解 AWS DeepLens,还有机会得到一部 AWS DeepLens 哦!
立即预订
我们将于 2018 年率先向美国市场供应 AWS DeepLens。要了解有关定价和可用性的更多信息,或是想要提前预订,请访问 DeepLens 页面。
— Jeff;