亚马逊AWS官方博客
在 Amazon EKS 上使用 Kubeflow 进行分布式 TensorFlow 训练
在数十到数百 GB 的大规模数据集上训练大型深度神经网络 (DNN) 通常需要耗费极长的时间。我们的当务之急是寻找可以将训练时间从数天缩短至数小时的解决方案。在多台机器上使用多个 GPU 对 DNN 进行分布式数据并行训练,通常是解决此问题的正确方法。本文的焦点是讨论如何使用 Amazon Web Services (AWS) 上的开源框架和平台进行此类分布式训练。
TensorFlow 是一个开源机器学习库。Kubernetes 是用于管理容器化应用程序的开源平台。Kubeflow 是一个开源工具包,可简化在 Kubernetes 上部署机器学习工作流的过程。Amazon Elastic Kubernetes Service (Amazon EKS) 让在 AWS 上使用 Kubernetes 部署、管理和扩展容器化应用程序更加简便。在 Amazon EKS 上使用 Kubeflow,我们可以利用这些开源技术进行高度可扩展的分布式 TensorFlow 训练。
我们将首先概述关键概念,然后逐步介绍在 EKS 上使用 Kubeflow 进行分布式 TensorFlow 训练所需的步骤。此前一篇讨论 EKS 上的 Kubeflow 的博文有助对此主题的理解。
概念概述
尽管本文中介绍的许多分布式训练概念通常适用于多种类型的 TensorFlow 模型,但我们将着重介绍的是在 Common Object in Context (COCO) 2017 数据集上对 Mask R-CNN 模型进行的分布式 TensorFlow 训练。
模型
Mask R-CNN 模型用于对象实例分割,其中模型生成像素级掩膜(Sigmoid 二进制分类)和以对象类别(SoftMax 分类)注释的目标框(Smooth L1 回归)描绘图像中的每个对象实例。Mask R-CNN 的一些常见用例包括:自动驾驶汽车的感知、表面缺陷检测和地理空间图像分析。
文中选择 Mask R-CNN 模型的关键原因有三个:
- 在大型数据集上进行 Mask R-CNN 的分布式训练可缩短训练时间。
- Mask R-CNN 模型有许多开源 TensorFlow 实现。在本文中,我们将使用 Tensorpack Mask/Faster-RCNN 实现作为主要示例,但也推荐使用高度优化的 AWS 示例 Mask-RCNN。
- Mask R-CNN 模型在 MLPerf 结果中被评估为大型对象检测模型
Mask R-CNN 深层神经网络 (DNN) 架构的示意图如下所示:

图 1.Mask R-CNN DNN 架构示意图(请参阅 Mask R-CNN 论文:https://arxiv.org/pdf/1703.06870.pdf)
分布式训练中的同步 All-reduce 梯度
分布式 DNN 训练的主要挑战在于,在应用梯度来更新跨多个节点的多个 GPU 上的模型权重之前,需要在同步步骤中对所有 GPU 的反向传播过程中计算出的梯度进行 All-reduce(平均化)。
同步 All-reduce 算法需要实现高效率,否则从分布式数据并行训练中获得的任何训练速度提升,都会因同步 All-reduce 步骤的效率低下而荡然无存。
要使同步 All-reduce 算法实现高效率,存在三个主要挑战:
- 该算法需要随着分布式训练集群中节点和 GPU 数量的增加而扩展。
- 该算法需要利用单个节点内的高速 GPU 到 GPU 互连的拓扑。
- 该算法需要通过有效地批处理与其他 GPU 的通信,来有效地交错 GPU 上的计算以及与其他 GPU 的通信。
Uber 的开源库 Horovod 旨在解决以下挑战:
- Horovod 提供了一种高效的同步 All-reduce 算法,它可随着 GPU 和节点数量的增加而扩展。
- Horovod 库利用 Nvidia Collective Communications Library (NCCL) 通信原语,而这些通信原语利用了对 Nvidia GPU 拓扑的了解。
- Horovod 包含 Tensor Fusion,它通过批量处理 All-reduce 数据通信,来高效地将通信与计算交错。
许多机器学习框架(包括 TensorFlow)都支持 Horovod。TensorFlow 分发策略还利用了 NCCL,并提供了使用 Horovod 进行分布式 TensorFlow 训练的替代方法。在本文中,我们将使用 Horovod。
具有八个 Nvidia Tesla V100 GPU、128 – 256 GB GPU 内存、25 – 100 Gbs 网络互连及高速 Nvidia NVLink GPU 到 GPU 互连的 Amazon EC2 p3.16xlarge 和 p3dn.24xlarge 实例非常适合分布式 TensorFlow 训练。
Kubeflow 消息传递接口 (MPI) 训练
分布式 TensorFlow 训练的下一个挑战是在多个节点上合理布置训练算法工作进程,以及将每个工作进程与唯一全局排名相关联。消息传递接口 (MPI) 是广泛用于并行计算的聚合通信协议,在管理跨多个节点的一组训练算法工作进程中非常有用。
MPI 用于在多个节点上布置训练算法进程,并将每个算法进程与唯一的全局和本地排名相关联。Horovod 用于逻辑地将给定节点上的算法进程固定到特定的 GPU。梯度同步 All-reduce 要求将每个算法进程逻辑固定到特定的 GPU。
与本文相关的 Kubeflow 机器学习工具包的特定方面是,Kubeflow 通过 MPI 作业自定义资源定义 (CRD) 和 MPI 运算符部署为消息传递接口 (MPI) 训练提供支持。Kubeflow 通过 MPI 作业和 MPI 运算符在 Amazon EKS 上实现分布式 TensorFlow 训练。TensorFlow 训练作业定义为 Kubeflow MPI 作业,而 Kubeflow MPI 运算符部署根据 MPI 作业定义启动 Pod 以在跨多节点、多 GPU 的 Amazon EKS 集群中进行分布式 TensorFlow 训练。由于本文不对使用 Kubeflow 进行 MPI 训练进行详细探讨,因此我们无需完整部署 Kubeflow。
Kubernetes 资源管理
要在 Amazon EKS 上使用 Kubeflow 进行分布式 TensorFlow 训练,我们需要管理定义 MPI 作业 CRD、MPI 运算符部署和 Kubeflow MPI 作业训练作业的 Kubernetes 资源。在本文中,我们将使用 Helm chart 来管理 Kubernetes 资源,这些资源定义了 Mask R-CNN 模型的分布式 TensorFlow 训练作业。
逐步讲解
下面我们逐步介绍在 EKS 中使用 Kubeflow 进行分布式 TensorFlow DNN 训练的步骤。我们将首先创建一个 EKS 集群,然后将代码和框架打包到 Docker 映像中,将 COCO 2017 数据集暂存在 Amazon Elastic File System (Amazon EFS) 共享文件系统上,最后,使用 EKS 中的 Kubeflow 开始训练作业。
先决条件
- 创建并激活一个 AWS 账户或使用现有的 AWS 账户。
- 从 AWS Marketplace 订阅带有 GPU 支持的经 EKS 优化 AMI。
- 管理服务限制,以便您可以至少启动四个经 EKS 优化、支持 GPU 的 Amazon EC2 P3 实例。
- 为 EC2 实例创建一个 AWS 服务角色,并将用于高级用户访问权限的 AWS 托管策略添加到该 IAM 角色,或创建一个具备执行本文中的步骤所需 IAM 权限的最低权限角色。
- 我们需要一个安装了 AWS CLI 和 Docker 的构建环境。使用包含第 4 步中创建的 IAM 角色的 EC2 实例配置文件,从 AWS 深度学习 AMI (Ubuntu) 启动一个 m5.xlarge Amazon EC2 实例。EC2 实例的 root EBS 卷必须至少为 200 GB。以下所有步骤必须在此 EC2 实例上执行。
- 在您的构建环境中克隆此 GitHub 存储库并执行以下步骤。所有路径都相对于 Git 存储库根目录。有关详细说明,请参见 Git 存储库 README 文件。
- 使用支持 Amazon EKS、Amazon EFS 和 EC2 P3 实例的任何 AWS 区域。在这里,我们假设使用 us-west-2 AWS 区域。
- 在您的 AWS 区域中创建一个 S3 存储桶。
创建支持 GPU 的 Amazon EKS 集群和节点组
要在 EKS 上使用 Kubeflow 实现分布式 TensorFlow 训练,第一步当然是创建 Amazon EKS 集群。有多种云基础设施自动化选项可用于执行此操作,包括:eksctl、Terraform 等。在这里,我们将使用 Terraform。大致了解 Terraform 可能会有所帮助,但并非必要。首先,在构建环境中安装 Terraform。尽管最新版本的 Terraform 可能有效,但本文中使用的是 Terraform v0.12.6。
安装并配置 Kubectl
在 Linux 机器上,从 eks-cluster 目录安装 kubectl 和 aws-iam-authenticator:
./install-kubectl-linux.sh该脚本通过显示 aws-iam-authenticator 的帮助内容来验证 aws-iam-authenticator 是否正常工作。
创建 EKS 集群和工作进程节点组
在随附的 Git 存储库中的 eks-cluster/terraform/aws-eks-cluster-and-nodegroup 目录中,创建一个 EKS 集群:
terraform init如前所述,对于下面的 azs 变量,我们假设使用 AWS 区域 us-west-2。如果选择其他 AWS 区域,请相应地修改 azs 变量。某些 AWS 可用区可能没有所需的 EC2 P3 实例,在这种情况下,以下命令将失败,请使用不同的可用区重新进行尝试。
您可以使用 k8s_version 变量来指定 Kubernetes 版本,如下所示。虽然最新的 Kubernetes 版本应该可以正常工作,但本文使用的是 1.13 版。下一条命令需要使用 Amazon EC2 密钥对。如果尚未创建 EC2 密钥对,请创建一个,并将下面脚本中的 <key-pair> 替换为相应密钥对的名称:
terraform apply -var="profile=default" -var="region=us-west-2" \
-var="cluster_name=my-eks-cluster" \
-var='azs=["us-west-2a","us-west-2b","us-west-2c"]' \
-var="k8s_version=1.13" -var="key_pair=<key-pair>"
保存 terraform apply 命令的摘要输出。以下是已被混淆的摘要输出示例:
EKS Cluster Summary: vpc: vpc-xxxxxxxxxxxx subnets: subnet-xxxxxxxxxxxx,subnet-xxxxxxxxxxxx,subnet-xxxxxxxxxxxx cluster security group: sg-xxxxxxxxxxxxxx endpoint: https://xxxxxxx.gr7.us-west-2.eks.amazonaws.com EKS Cluster NodeGroup Summary: node security group: sg-xxxxxx node instance role arn: arn:aws:iam::xxxxxxx:role/quick-start-test-ng1-role EFS Summary: file system id: fs-xxxxxxxx dns: fs-xxxxxxxx.efs.us-west-2.amazonaws.com
为 EFS 创建持久卷和持久卷声明
作为创建 Amazon EKS 集群的一部分,还将创建 Amazon EFS 实例。我们将使用此 EFS 共享文件系统来暂存训练和验证数据。要访问 Pod 中运行的训练作业中的数据,我们需要为 EFS 定义持久卷和持久卷声明。
要创建名为 kubeflow 的新 Kubernetes 命名空间,请执行以下操作:
kubectl create namespace kubeflow您将需要在上一步中保存的 terraform apply 命令的摘要输出。在 eks-cluster 目录的 pv-kubeflow-efs-gp-bursting.yaml 文件中,将 <EFS file-system id> 替换为保存的 EFS 文件系统 ID 摘要输出,并将 <AWS region> 替换为正在使用的 AWS 区域(例如 us-west-2)并执行:
kubectl apply -n kubeflow -f pv-kubeflow-efs-gp-bursting.yaml进行检查以确保成功创建了持久卷:
kubectl get pv -n kubeflow您应该会看到显示永久卷可用的输出。
执行:
kubectl apply -n kubeflow -f pvc-kubeflow-efs-gp-bursting.yaml创建一个 EKS 持久卷声明。验证持久卷声明是否已成功绑定到持久卷:
kubectl get pv -n kubeflow构建 Docker 映像
接下来,我们需要构建一个包含以下内容的 Docker 映像:TensorFlow、Horovod 库、Nvidia CUDA 工具包、Nvidia cuDDN 库、NCCL 库、Open MPI 工具包和 Mask R-CNN 训练算法代码 Tensorpack 实现。用于构建容器映像的 Dockerfile 使用 AWS 深度学习容器映像作为基础映像。在 container/build_tools 文件夹中,为 AWS 区域自定义 build_and_push.sh shell 脚本。默认情况下,此脚本将映像推送到默认 AWS CLI 配置文件中配置的 AWS 区域。您可以在脚本中进行更改,并将 region 设置为 us-west-2。执行:
./build_and_push.sh构建 Docker 映像并将其推送到您的 AWS 区域中的 Amazon Elastic Container Registry (ECR)。
经优化的 Mask R-CNN
要使用经优化的 Mask R-CNN 模型,请使用 container-optimized/build_tools 文件夹,然后自定义并执行:
./build_and_push.sh暂存 COCO 2017 数据集
接下来,我们将暂存训练 Mask R-CNN 模型所需的 COCO 2017 数据集。在 eks-cluster 文件夹中,自定义 prepare-s3-bucket.sh shell 脚本,以在 S3_BUCKET 变量中指定您的 Amazon S3 存储桶名称,然后执行:
./prepare-s3-bucket.sh这将下载 COCO 2017 数据集并将其上传到您的 Amazon S3 存储桶。进入 eks-cluster 文件夹,在 stage-data.yaml 中自定义 image 和 S3_BUCKET 这两个变量。将您在上一步中创建的 Docker 映像的 ECR URL 用作 image 的值。执行:
kubectl apply -f stage-data.yaml -n kubeflow在选定的 EFS 永久卷声明上暂存数据。等待由上一个 apply 命令启动的 stage-data Pod 被标记为 Completed。可以通过执行以下命令来检查:
kubectl get pods -n kubeflow要验证是否已正确暂存数据,请执行:
kubectl apply -f attach-pvc.yaml -n kubeflow
kubectl exec attach-pvc -it -n kubeflow -- /bin/bash
您将连接到具有已挂载 EFS 持久卷声明的 Pod。验证是否已将 COCO 2017 数据集正确暂存到所连接 Pod 上的 /efs/data 下。验证完数据集后,输入 exit。
创建 Mask R-CNN 训练作业
在继续之前,让我们回顾一下到目前为止所涵盖的内容。我们为 EFS 创建了 EKS 集群、EKS 节点组、持久卷和持久卷声明,并在持久卷上暂存了 COCO 2017 数据集。
接下来,我们将定义一个 Kubeflow MPI 作业,用于启动 Mask R-CNN 训练作业。我们使用 Helm chart 定义 Kubeflow MPI 作业。Helm 是 Kubernetes 的应用程序包管理器。接下来,我们将安装并初始化 Helm。
安装并初始化 Helm
Helm 安装完毕后,请按照以下说明对其进行初始化:
在 eks-cluster 文件夹中,执行:
kubectl create -f tiller-rbac-config.yaml您应该会看到以下两条消息:
serviceaccount "tiller" created clusterrolebinding "tiller" created
执行:
helm init --service-account tiller --history-max 200定义 MPI 作业 CRD
首先,通过在 charts 文件夹中执行以下命令,安装定义 Kubeflow MPI 作业 CRD 的 Helm chart:
helm install --debug --name mpijob ./mpijob/开始训练作业
在 charts/maskrcnn/values.yaml 文件中,自定义 image 值:
image: # ECR image id将您在上一步中创建的 Docker 映像的 ECR URL 用作 image 的值。通过在 chart 文件夹中执行以下命令来开始训练作业:
helm install --debug --name maskrcnn ./maskrcnn/您可以通过执行以下命令监视 Pod 的状态:
kubectl get pods -n kubeflow您应该会看到工作进程 Pod 和启动器 Pod。在所有工作进程 Pod 进入“运行”状态后,将创建启动器 Pod。训练完成后,工作进程 Pod 将自动销毁,并且启动器 Pod 将标记为 Completed。您可以使用 kubectl 检查启动器 Pod 日志,以获取训练日志的实时输出。
经优化的 Mask-RCNN 模型的训练
要训练经优化的 Mask R-CNN 模型,请在 charts/maskrcnn-optimized/values.yaml 文件中,将 image 值设置为相关的 ECR URL 并执行:
helm install –-debug --name maskrcnn-optimized ./maskrcnn-optimized/可视化 Tensorboard 摘要
可以通过部署在 EKS 中的 Tensorboard 服务来可视化训练工作的 Tensorboard 摘要:
kubectl get services -n kubeflow \
-o=jsonpath='{.items[0].status.loadBalancer.ingress[0].hostname}{"\n"}'
使用 Tensorboard 服务的公共 DNS 地址(http://<Tensorboard 服务 dns 名称>/)并在浏览器中访问它,以可视化摘要。在 Kubeflow 作业运行时,通过 Tensorboard 可视化各种算法特定的指标,使我们能够验证训练指标是否朝着正确的方向收敛。如果训练指标表明存在问题,我们可以提早中止训练。下面是在 EKS 上使用 Kubeflow 运行 Mask R-CNN 训练作业实验的 Tensorboard 图。这些图显示了 Mask R-CNN 特定算法指标在 24 个训练周期内的变化情况。
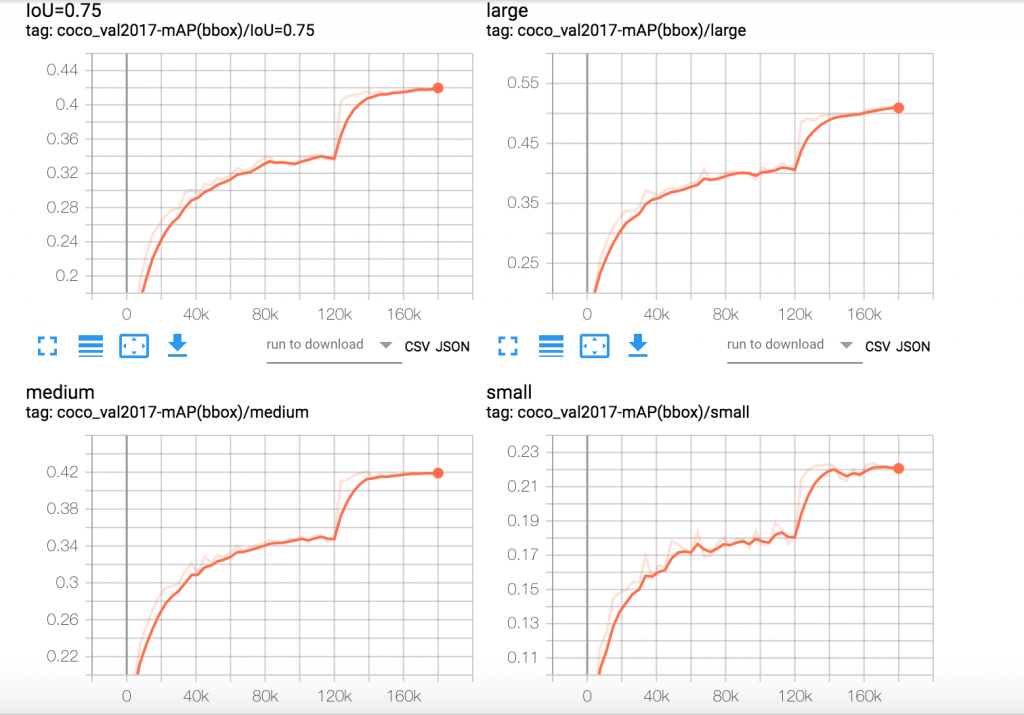
图 2.Mask R-CNN 目标框 mAP
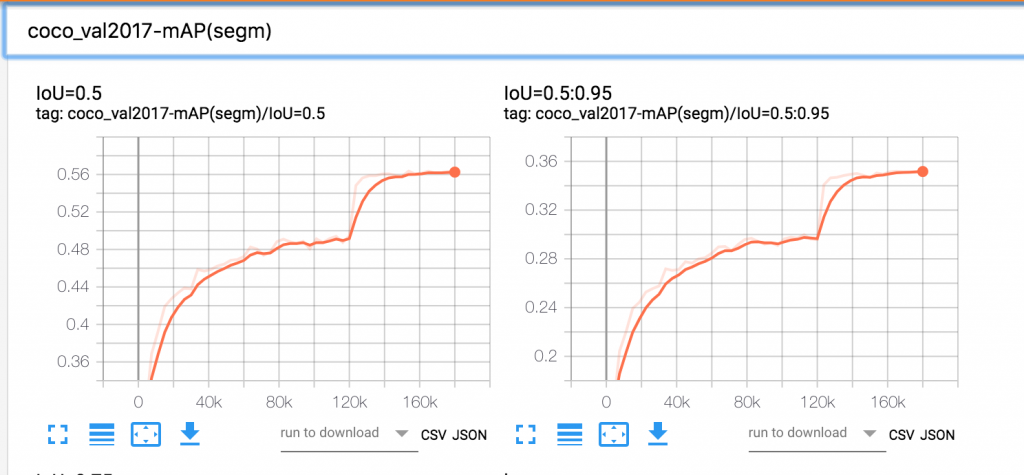
图 3.Mask R-CNN 分割 mAP
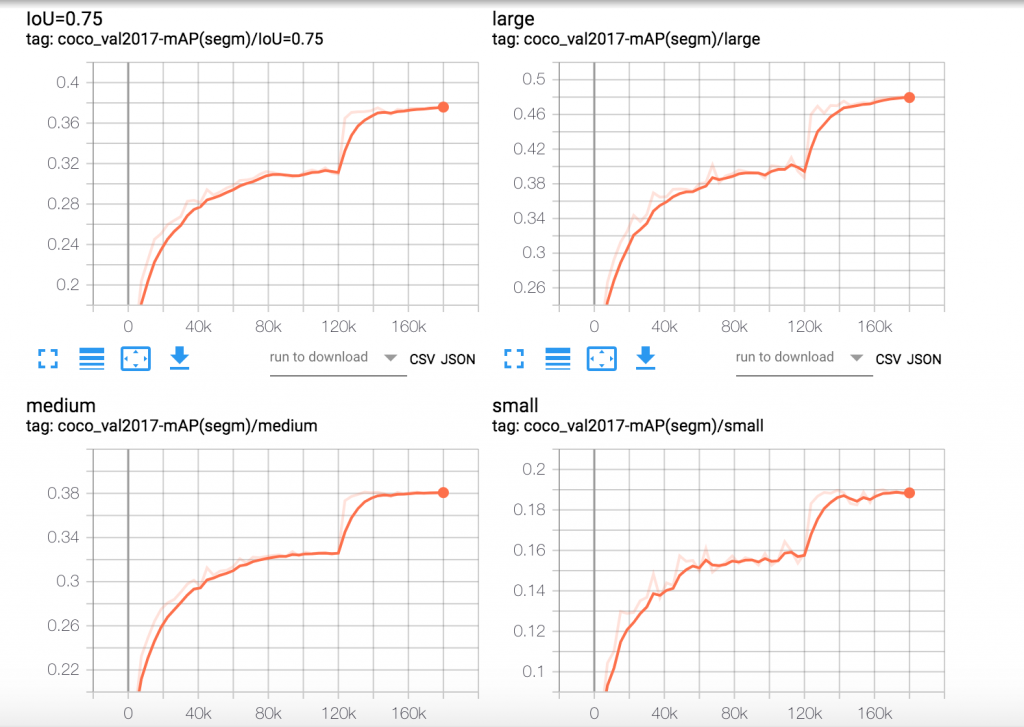
图 4.Mask R-CNN 分割 mAP
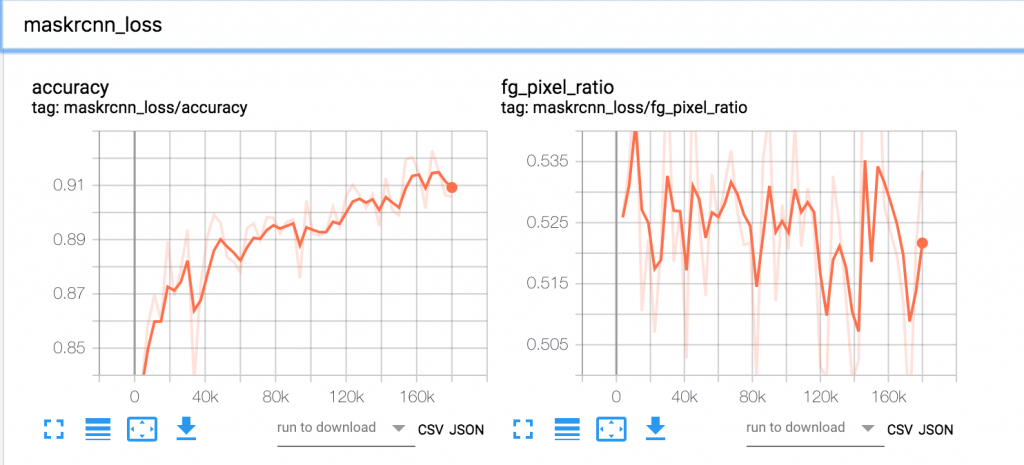
图 5.Mask R-CNN 损失
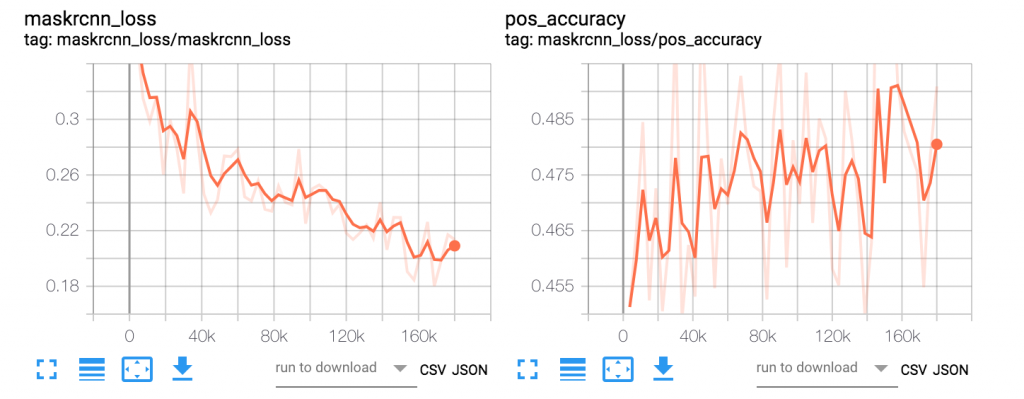
图 6.Mask R-CNN 损失
清理
训练作业完成后,工作进程 Pod 会自动销毁。从 Helm 清理训练作业,请执行:
helm del --purge maskrcnn要销毁 EKS 集群和工作进程节点组,请使用与上面的 terraform apply 命令相同的参数值,在 eks-cluster/terraform/aws-eks-cluster-and-nodegroup 目录中执行以下命令:
terraform destroy -var="profile=default" -var="region=us-west-2" \
-var="cluster_name=my-eks-cluster" \
-var='azs=["us-west-2a","us-west-2b","us-west-2c"]' \
-var="k8s_version=1.13" -var="key_pair=<key-pair>"
小结
对于在大规模数据集上进行大型 DNN 训练而言,在多台机器上使用多个 GPU 进行分布式数据并行训练,通常是减少训练时间的最佳解决方案。
Amazon EKS 上的 Kubeflow 基于开源技术提供了一个高度可用、可扩展且安全的机器学习环境,可用于所有类型的分布式 TensorFlow 训练。在本文中,我们分步骤逐步介绍了如何在 Amazon EKS 上使用 Kubeflow 进行分布式 TensorFlow 训练。