亚马逊AWS官方博客
如何将您的自定义容器镜像导入Amazon SageMaker Studio notebooks
Amazon SageMaker Studio是第一套用于机器学习(ML)的全集成开发环境(IDE)。Amazon SageMaker Studio可帮助数据科学家们快速启动Studio notebooks以探索数据、构建模型、启动Amazon SageMaker训练作业并部署托管端点。Studio notebooks中随附一组预构建镜像,这些镜像由Amazon SageMaker Python SDK 与IPython运行时或内核的最新版本构成。凭借此项新功能,您可以轻松将自定义镜像导入Amazon SageMaker notebooks当中。在本文中,我们将具体探讨如何将自定义容器镜像导入Amazon SageMaker notebooks。
开发人员与数据科学家一般需要在以下几种不同用例内使用自定义镜像:
- 访问流行机器学习框架(包括TensorFlow、MXNet以及PyTorch等)的特定或最新版本。
- 将本地开发的自定义代码或算法引入Studio notebooks内以进行快速迭代及模型训练。
- 通过API访问数据湖或本地数据存储,且管理员需要在镜像中添加相应驱动程序。
- 访问后端运行时(也称内核);除IPython之外,还有R、Julia或其它环境等。您也可以使用本文中概述的方法安装其他自定义内核。
在大型企业中,机器学习平台管理员往往需要保证安全团队预先批准第三方软件包及代码,而非直接通过互联网下载。在常见的工作流示例中,机器学习平台团队会批准一组要使用的软件包与框架,使用这些软件包构建自定义容器、测试容器中的漏洞,而后将核准后的镜像推送至私有容器注册表内,例如Amazon Elastic Container Registry (Amazon ECR)。现在,机器学习平台团队可以将经过核准的镜像直接附加至Studio域内(请参见以下工作流程图)。您只需在Studio中选定所需的获准自定义镜像即可。在当前版本中,单一Studio域最多可以包含30个自定义镜像,您可以根据需求添加新版本或删除镜像。
现在,我们将逐步介绍如何使用此项功能将自定义容器镜像导入Amazon SageMaker Studio notebooks当中。这里主要演示在互联网上使用时的默认方法,您也可以对其稍加修改以配合Amazon Virtual Private Cloud (Amazon VPC)进行使用。
先决条件
在开始之前,大家需要满足以下先决条件:
- 亚马逊云科技账户。
- 确保用于访问Amazon SageMaker的角色拥有以下Amazon Web Services身份与访问管理(IAM)权限,使Amazon SageMaker Studio能够在Amazon ECR中以smstudio为前缀创建一个repo,并面向此repo进行镜像推送与提取。要使用现有repo,请将其中的Resource部分替换为您的repo ARN。要构建容器镜像,您可以使用本地Docker客户端,或者直接在Amazon SageMaker Studio中创建镜像。本文采用后一种方法。要在Amazon ECR内创建repo,Amazon SageMaker Studio需要使用Amazon CodeBuild;您还需要拥有使用CodeBuild的权限,具体如下所示。
您的Amazon SageMaker角色还应在Amazon CodeBuild中拥有信任策略,具体如下所示。关于更多详细信息,请参阅使用Amazon SageMaker Studio镜像构建CLI在Studio notebooks中构建容器镜像。
- 在您的本地机器上安装Amazon Web Services命令行界面(Amazon CLI)。关于详尽操作说明,请参阅安装Amazon Web Services。
- 准备一个SageMaker Studio域。要创建此域,请使用CreateDomain API或者 create-domain CLI命令。
如果您希望使用自有VPC以安全引入自定义容器,则需要完成以下操作:
- 带有专有子网的VPC。
- 用于以下服务的VPC端点:
- Amazon Simple Storage Service (Amazon S3)
- Amazon SageMaker
- Amazon ECR
- Amazon Security Token Service (Amazon STS)
- 用于构建Docker容器的CodeBuild
要设置上述资源,请参阅使用专用VPC保护Amazon SageMaker Studio连接以及相关GitHub repo。
创建Dockerfile
为了体现数据科学家使用最新框架进行试验的普遍性需求,我们在本次演练中使用以下Dockerfile,其选择最新的TensorFlow 2.3版本作为基础镜像。您也可以使用自己指定的Dockerfile进行替换。目前,Amazon SageMaker Studio已经能够支持多种基础镜像,例如Ubuntu、Amazon Linux 2等等。Dockerfile将安装运行Juypter notebooks所需要的IPython运行时,同时安装Amazon SageMaker Python SDK与boto3。
除了笔记本电脑之外,除了notebooks之外,数据科学家与机器学习工程师们还经常使用各种流行IDE(例如Visual Studio Code或者PyÇharm)在本地notebooks上进行迭代与试验。您可能希望将这些脚本引入云端,借此进行扩展化训练或数据处理。您可以将这些脚本打包进Docker容器之内,并在Amazon SageMaker Studio的本地存储中查看。在以下Dockerfile中,我们复制的train.py 脚本是一套用于在MNIST数据集上训练简单深度学习模型的基础脚本。您也可以使用自己的脚本或包含代码的软件包替换此脚本。
COPY train.py /root/train.py #可以替换为您的自定义脚本或软件包
以下代码为train.py脚本:
除了自定义脚本之外,您也可以添加其他文件,例如可通过Amazon Secrets Manager 或 Amazon Systems Manager Parameter Store访问客户端secrets以及环境变量的Python文件、用于连接私有PyPi repo的config文件、或者其他软件包管理工具。您也可以使用自定义镜像复制脚本,但在这种情况下,Dockerfile中的一切ENTRYPOINT或CMD命令均无法运行。
设置安装文件夹
您需要在本地机器上创建一个文件夹,并向其中添加以下文件:
- 在上一步中创建完成的Dockerfile。
- 名为 app-image-config-input.json 的文件,具体内容如下:
我们将此Dockerfile的后端内核设置为IPython内核,并提供指向Amazon Elastic File System (Amazon EFS)的挂载路径。Amazon SageMaker可以识别出Juypter定义的内核。例如,对于R内核,您可以将之前代码中的Name部分设置为ir。请注意保证其中的Uid、Gid以及内核名称与Docker镜像中的kernelspecs及用户信息相匹配。要获取这些值,请参阅本文档。
- 使用以下内容创建一个名为 default-user-settings.json 的文件。如果您需要添加多个自定义镜像,请直接将其添加至 CustomImages列表。
创建镜像并将其附加至您的Studio域
如果您已经拥有现成的域,则直接使用新镜像进行更新即可。在本节中,我们将演示现有Studio用户如何进行镜像附加。关于启动新用户的说明,请参阅使用IAM登入Amazon SageMaker Studio。
首先,我们使用Amazon SageMaker Studio Docker构建CLI构建Dockerfile,并将其推送至Amazon ECR。请注意,您也可以使用其他方法将容器推送至ECR,例如通过本地Docker客户端以及AWS CLI。
- 使用您的用户信息登录至Studio。
- 将您的Dockerfile、以及其他需要复制到容器当中的代码或依赖项上传至Studio域。
- 导航至包含Dockerfile的文件夹。
- 在终端窗口或notebook内 —>
!pip install sagemaker-studio-image-build
- 导出一个名为IMAGE_NAME的变量,并将其设定为您在 default-user-settings.json当中所指定的值。
sm-docker build . –repository smstudio-custom:IMAGE_NAME
- 如果要使用其他repo,请将以上代码中的smstudio-custom替换为您的repo名称。
Amazon SageMaker Studio将为您构建Docker镜像,将该镜像推送至Amazon ECR当中一个名为smstudio-custom的repo内,并为其标记适当的镜像名称。要进一步自定义此项功能(例如提供详细的文件路径或其他选项),请参阅使用Amazon SageMaker Studio镜像构建CLI在Studio notebooks中构建容器镜像。要让以上pip命令在专用VPC环境下起效,您需要设置互联网路由或访问专用repo内的相应软件包。
- 在之前的安装文件夹中,创建一个名为 create-and-update-image.sh的新文件:
请参阅Amazon CLI以了解可在 create-image API中使用的各项参数的详细信息。要检查当前状态,请导航至您的Amazon SageMaker控制台,并在导航面板中选择Amazon SageMaker Studio。
使用Studio UI附加镜像
您也可以通过UI完成将镜像附加至Studio域的最后一步。在此用例中,UI将处理镜像与镜像版本的创建操作,并使用附加的镜像完成域更新。
- 在Amazon SageMaker控制台上,选择Amazon SageMaker Studio。
在Control Panel页面上,可以看到已经置备完成的Studio域以及您所创建的所有用户配置。
- 选择Attach image。

- 选择要附加新镜像,还是附加原有镜像。
-
-
- 如果您选择Existing image,请从Amazon SageMaker镜像库中选择一个镜像。
- 如果您选择New image,请提供Docker镜像的Amazon ECR注册表路径。此路径需要与Studio域处于同一区域内。ECR repo还需要与您的Studio域处于同一账户内;如果需要跨账户操作,则Studio必须具备相应权限。
-
- 选择Next。

- 在Image name部分,输入名称。
- 在Image display name部分,输入描述性名称。
- 在 Description部分,输入标签定义。
- 在IAM role部分,选择Amazon SageMaker用于向Amazon SageMaker镜像附加Amazon ECR镜像的IAM角色。
- 此外,您也可以对镜像做出其他标记。
- 选择 Next。

- 在Kernel name部分,输入Python 3。
- 选择Submit。

绿色复选框代表镜像已被成功附加至域内。
Amazon SageMaker镜像存储将自动对镜像进行版本控制。您可以选择一个预先附加的镜像,而后选择Detach以分离该镜像及所有相关版本,或者选择Attach image以附加新版本。各镜像的版本数量或分离镜像的功能不受限制。
自定义镜像用户体验
下面,我们尝试Studio的实际用户体验。
- 使用您的用户资料登录至Studio。
- 要启动新活动,请选择Launcher。
- 在Select a SageMaker image to launch your activity部分,选择tf2kernel。

- 选择Notebook图标,使用自定义内核打开一个新notebook。
Notebook内核需要几分钟才能启动完成,之后即可开始使用!
在notebook中测试您的自定义容器
在内核启动并开始运行之后,您即可在notebook中运行代码。首先,我们测试Dockerfile中指定的TensorFlow是否为正确版本。在以下截屏中,可以看到我们刚刚创建的notebook正在使用tf2kernel。
Amazon SageMaker notebooks还会显示本地CPU与内存使用量。
接下来,我们直接在notebook中使用自定义训练脚本。将训练脚本复制到notebook单元中并运行。此脚本会从tf.keras.datasets处下载mnist数据集,并将数据拆分为训练数据集与测试数据集,自定义一项定制化深度神经网络算法,在训练数据集上训练算法,并在测试数据集上测试算法。
要尝试使用TensorFlow 2.3框架,大家可能希望测试新发布的API,例如Keras中提供的预处理实用程序等新功能。在以下截屏中,我们导入了随TensorFlow 2.3版本发布的keras.layers.experimental 库,其中包含用于数据预处理的新API。我们加载其中一个API,而后在notebook中重新运行脚本。
Amazon SageMaker还能够在代码运行过程中动态修改CPU与内存使用率。通过引入自定义容器与训练脚本,此功能使您能够直接在Amazon SageMaker notebook中尝试自定义训练脚本与算法。如果您对Studio notebook中的试验结果感到满意,则可立即启动训练作业。
Docker file中所包含的、使用COPY命令的Python文件或其他自定义文件运行情况如何?Amazon SageMaker Studio会挂载app-image-config-input.json所提供的文件路径中的弹性文件系统,在本示例中我们将其设定为root/data。为了避免Studio覆盖掉需要包含的自定义文件,COPY命令会将train.py文件加载至路径/root当中。要访问此文件,请打开终端或notebook并运行以下代码:
! cat /root/train.py
这时您应看到以下截屏所示的输出结果。
可以看到train.py 文件位于指定位置。
CloudWatch中的日志记录
Amazon SageMaker Studio还会将内核指标发布至Amazon CloudWatch供您进行故障排查。这些指标将被捕捉至/aws/sagemaker/studio命名空间之内。
要访问日志,请在CloudWatch控制台上选择CloudWatch Logs。在Log groups页面中,输入命名空间以查看与Jupyter服务器及内核网关相关的日志记录。
分离镜像或版本
您可以从域中分离镜像或特定镜像版本。
要分离镜像及其全部版本,请在Custom images attached to domain表内选定该镜像,而后选择Detach。
您还可以选择删除镜像及所有版本,这不会影响到Amazon ECR中的镜像。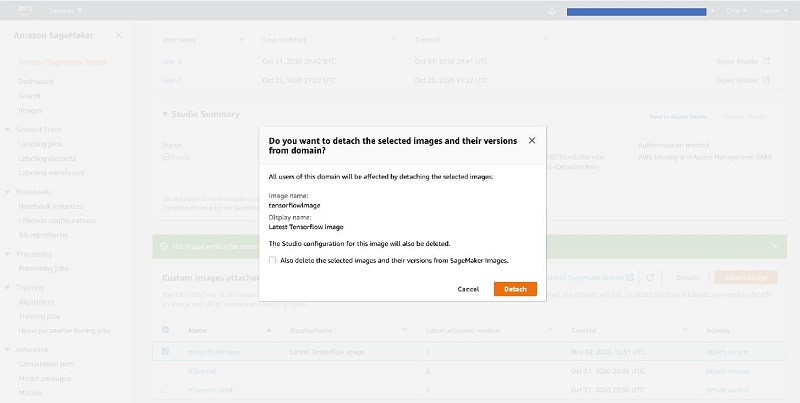
要分离镜像的特定版本,请选定该镜像。在Image details页面上,从Image versions attached to domain表中选择目标镜像版本(一个或者多个版本),而后选择Detach。您会看到如上所示的警告及操作选项。
总结
Amazon SageMaker Studio使您能够更轻松地对机器学习模型进行协作、实验、训练及部署。在这之前,数据科学家往往需要通过公共及私有代码repo以及软件包管理工具才能访问最新机器学习框架、自定义脚本以及软件包。现在,您可以将所有相关代码打包进自定义镜像之内,并使用Studio notebook启动这些镜像。这些镜像可供Studio域内的所有用户使用。您也可以使用此项功能使用Python之外的其他流行语言及运行时,包括R、Julia以及Scala等。您可以在GitHub repo中找到示例文件。关于此项功能的更多详细信息,请参阅自带SageMaker镜像。