亚马逊AWS官方博客
全新 – Amazon S3 批量操作
 AWS 客户通常会利用 S3 的规模、耐用性、低成本、安全性和存储选项,在单个 Amazon Simple Storage Service (S3) 存储桶中存储数百万或数十亿个对象。此类客户会存储图像、视频、日志文件、备份和其他关键任务数据,并将 S3 用作其数据存储策略的关键部分。
AWS 客户通常会利用 S3 的规模、耐用性、低成本、安全性和存储选项,在单个 Amazon Simple Storage Service (S3) 存储桶中存储数百万或数十亿个对象。此类客户会存储图像、视频、日志文件、备份和其他关键任务数据,并将 S3 用作其数据存储策略的关键部分。
批量操作
今天,我想告诉您有关 Amazon S3 批量操作的信息。您可以使用此新功能以简单直接的方式轻松处理数百、数百万或数十亿的 S3 对象。您可以将对象复制到另一个存储桶、设置标记或访问控制列表 (ACL),从 Glacier 启动还原,或在每个存储上调用 AWS Lambda 函数。
此功能基于 S3 对清单报告的现有支持(请阅读我的 S3 存储管理更新博文以了解更多信息)构建,并可使用报告或 CSV 文件来驱动批量操作。您不必编写代码、设置任何服务器队列或弄清楚如何对工作分区并将其分发给机群。相反,您只需点击几下即可在几分钟内创建一个作业,然后停止操作,静候 S3 使用大量幕后并行来处理工作。您可以使用 S3 控制台、S3 CLI 或 S3 API 创建、监控和管理批处理作业。
快速词汇课程
在开始创建批量作业之前,让我们回顾并介绍几个重要术语:
存储桶 – S3 存储桶包含任意数量的 S3 对象集合,具有可选的随对象版本控制。
清单报告 – 每次运行每日或每周存储桶清单时,都会生成 S3 清单报告。可以将报告配置为包括存储桶中的所有对象,或者侧重以前缀分隔的子集。
Manifest – 用于识别要在批处理作业中处理的对象的列表(清单报告或 CSV 格式的文件)。
批量操作 – 对 Manifest 描述的对象执行所需的操作。将操作应用于对象构成 S3 批量任务。
IAM 角色 –为 S3 提供读取清单报告中的对象、执行所需操作以及编写可选完成报告的权限的 IAM 角色。如果选择“调用 AWS Lambda”函数作为操作,则函数的执行角色必须授予访问所需 AWS 服务和资源的权限。
批处理作业 – 参考上述所有项目。每项作业都有状态和优先级;优先级较高(以数字表示)的工作优先于优先级较低的工作。
运行批处理作业
好的,让我们使用 S3 控制台创建并运行批处理作业! 为准备本篇博文,我在本周早些时候启用了一个 S3 存储桶 (jbarr-batch-camera) 的清单报告,并将报告路由到 jbarr-batch-inventory:
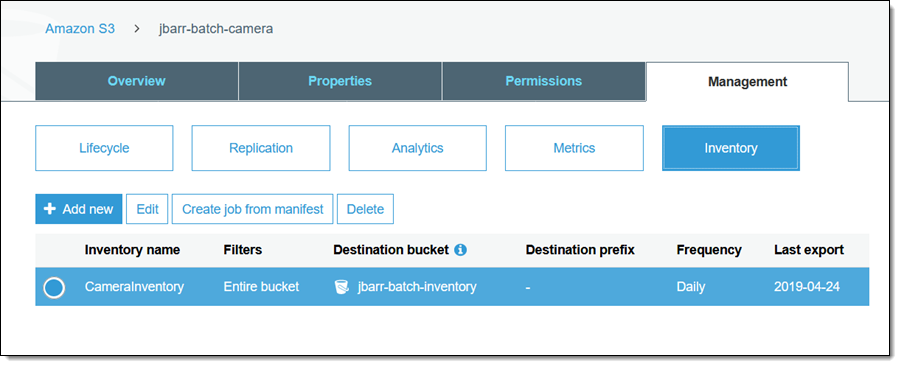
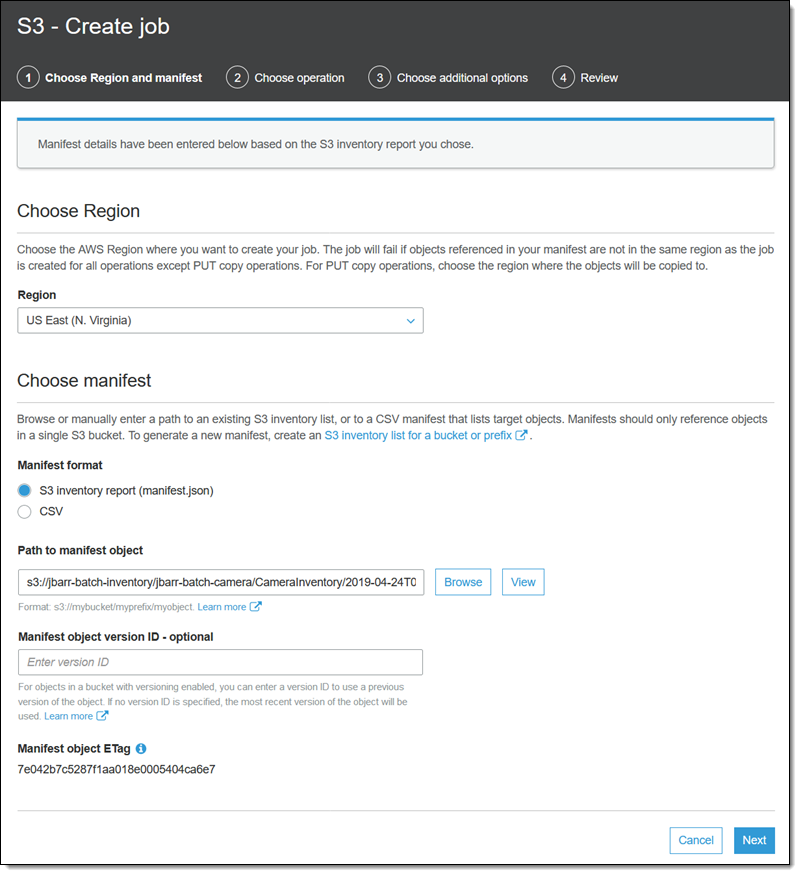
选择所需的清单项目,然后单击从 manifest 创建作业 以开始(也可以在浏览存储桶列表时单击批量操作)。所有相关信息均已填写,但如果需要,我可以选择清单的较早版本(此选项仅在 manifest 存储在已启用版本控制的存储桶中时适用)。单击下一步继续:
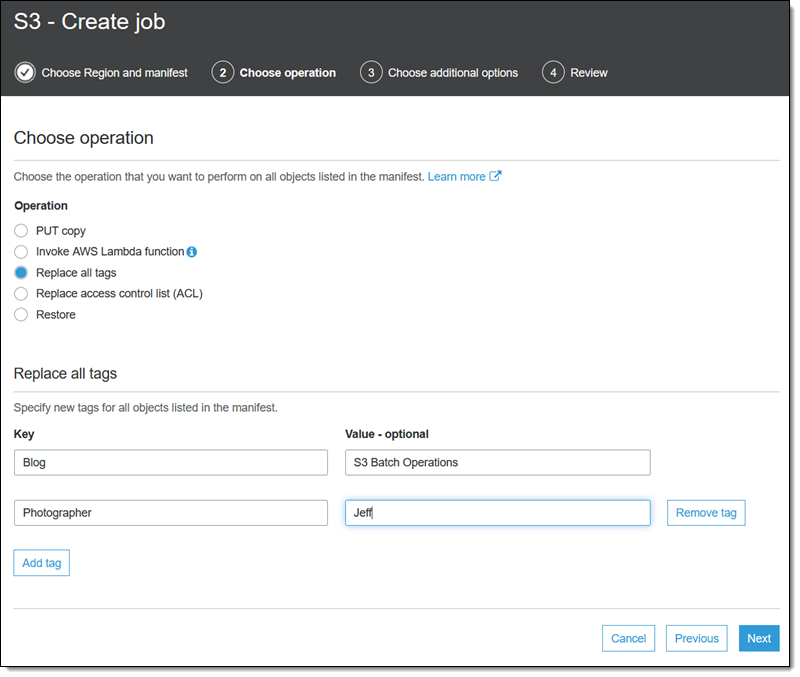
我选择操作(替换所有标签),输入特定的选项(稍后我会查看其他操作),然后单击下一步:
我为作业作输入一个名称,设置其优先级,并请求包含所有任务的完成报告。然后,我为报告选择一个存储桶,并选择一个授予必要权限的 IAM 角色(控制台还显示我可以复制和使用的角色策略和信任策略),然后单击下一步:
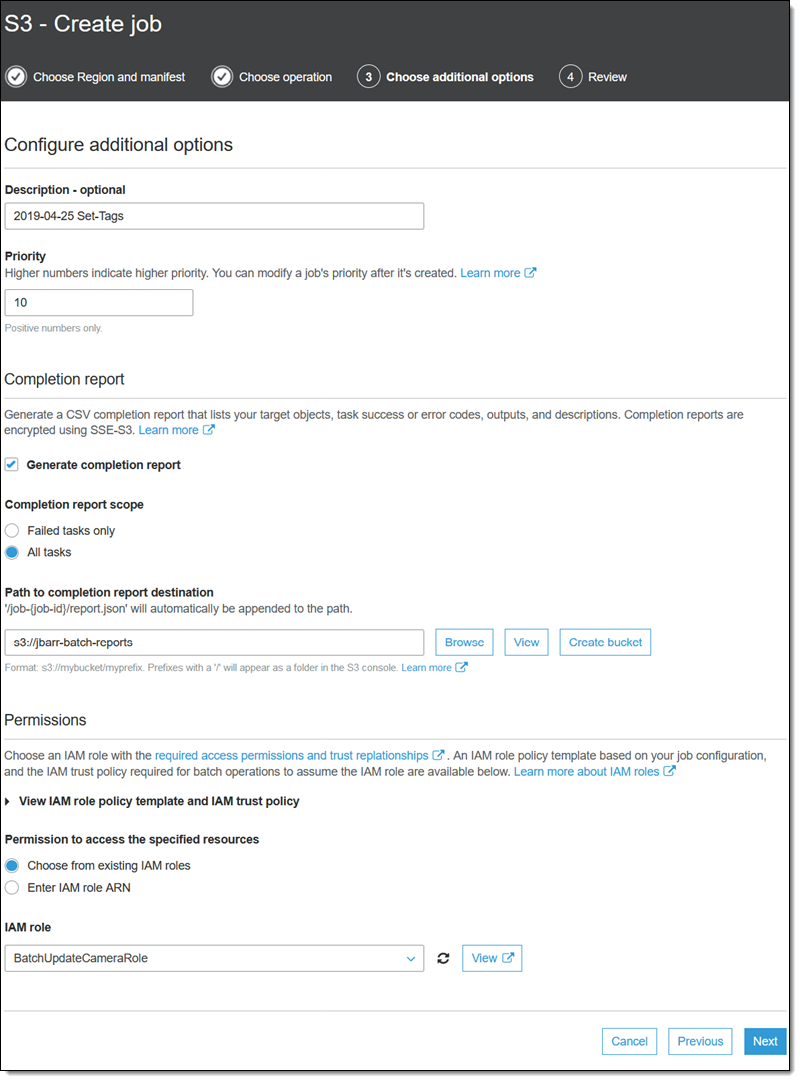
最后,我查看作业,然后单击创建作业:
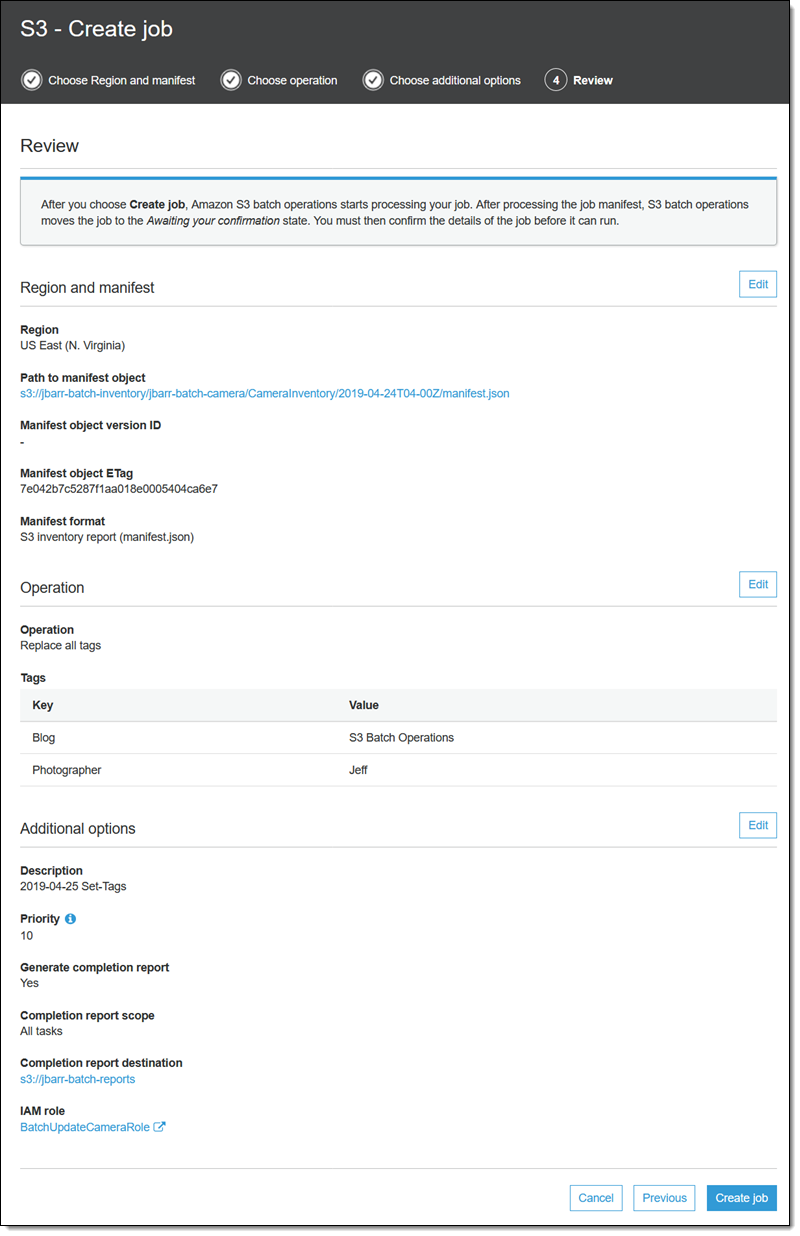
作业进入准备状态。S3 批量操作检查 manifest 并执行其他一些验证,并且作业进入等待您的确认状态(这仅在我使用控制台时发生)。选择作业,然后单击确认并运行:
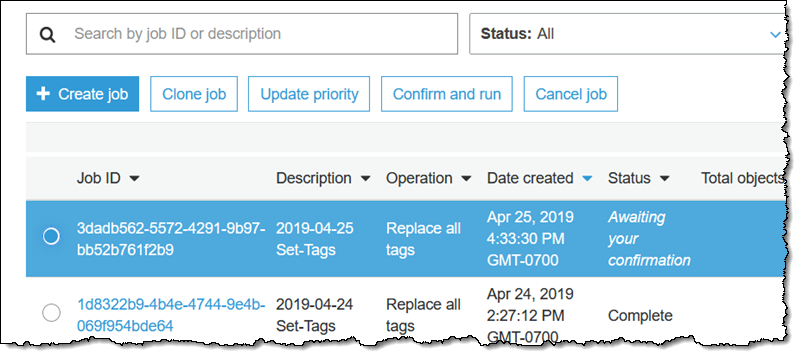
查看确认(未显示)以确保理解要执行的操作,然后单击运行作业。作业进入就绪状态,此后不久开始运行。完成后,作业进入完成状态:
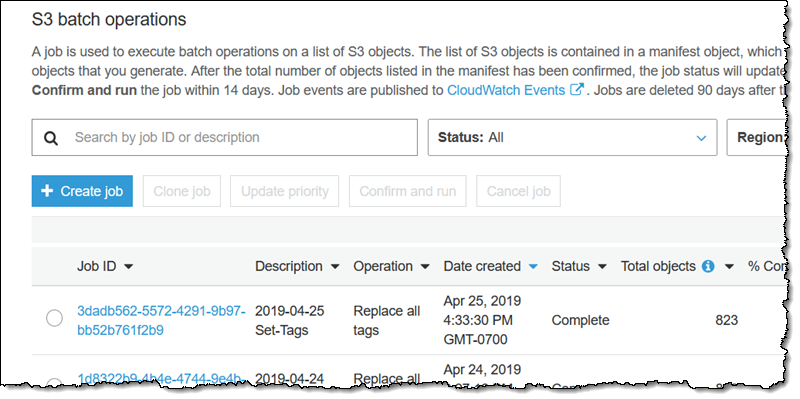
如果正在运行处理大量对象的作业,可以刷新此页面以监视状态。需要特别注意一点:处理完前 1000 个对象后,S3 批量操作会检查并监控整体故障率,如果故障率超过 50%,将停止作业。
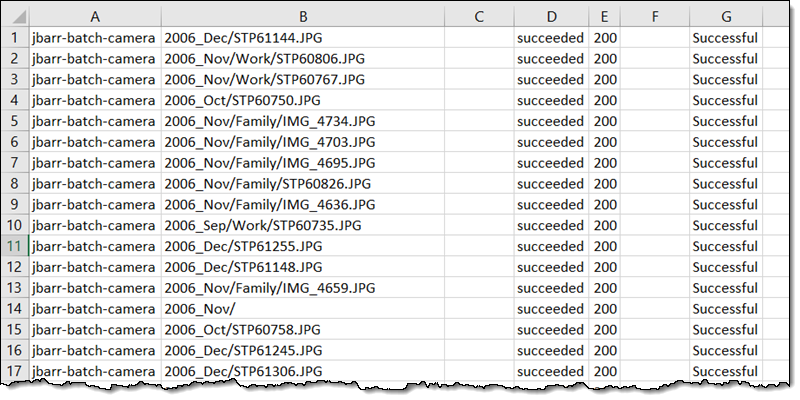
完成报告包含每个对象的一行,如下所示:
其他内置批量操作
我没有足够的空间来为您提供其他内置批量操作的完整运行。以下是一个概览:
PUT 复制操作会复制对象、控制存储类、加密、访问控制列表、标签和元数据:
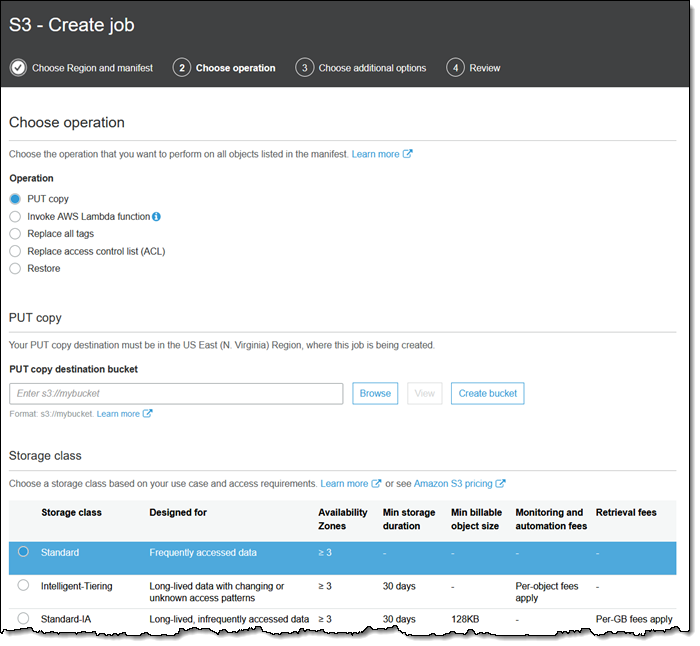
可以将对象复制到同一个存储桶以更改其加密状态。也可以将它们复制到另一个区域,或者复制到另一个 AWS 账户拥有的存储桶。
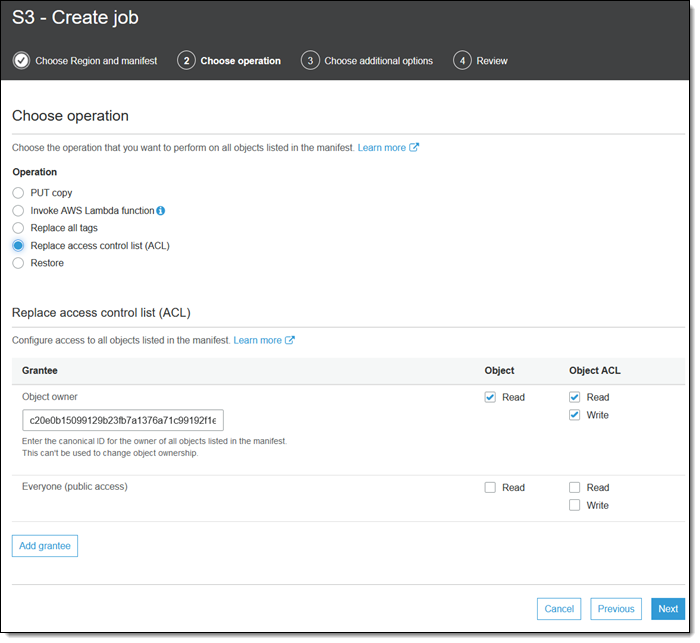
这正是替换访问控制列表 (ACL)操作通过控制授予的权限所做的工作:
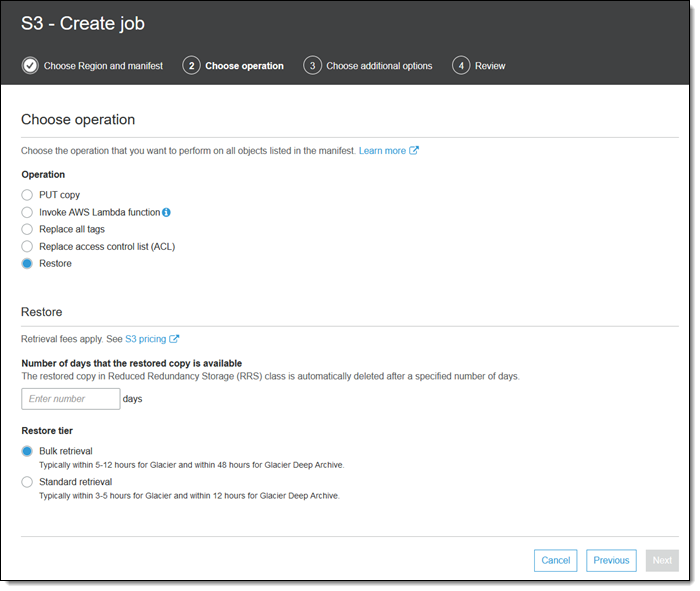
恢复操作从 Glacier 或 Glacier Deep Archive 存储类启动对象级恢复:
调用 AWS Lambda 函数
我已保存最常用的选项。我可以为每个对象调用 Lambda 函数,Lambda 函数可以通过编程方式分析和操作每个对象。该函数的执行角色必须信任 S3 批量操作:
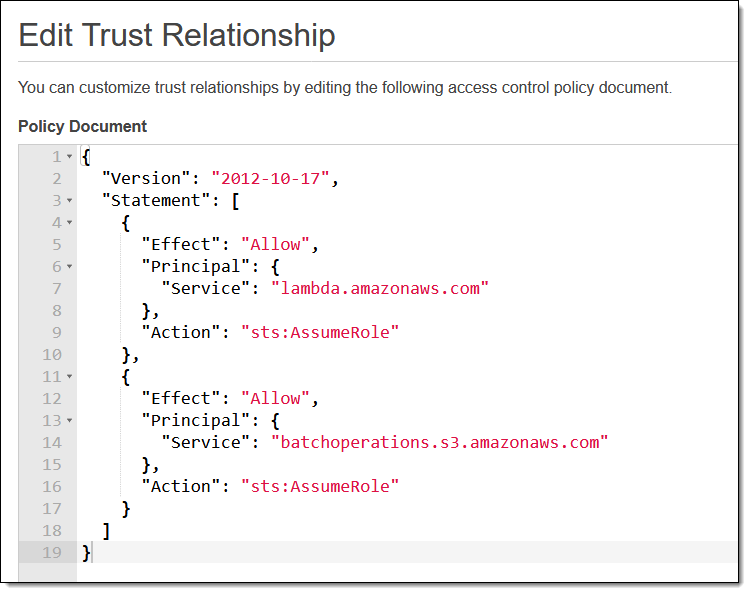
此外,批处理作业的角色必须允许调用 Lambda 函数。
有了必要的角色后,可以创建一个为每个映射调用 Amazon Rekognition 的简单函数:
有了函数后,在创建作业时选择调用 AWS lambda 函数作为操作,并选择 BatchProcessObject 函数:
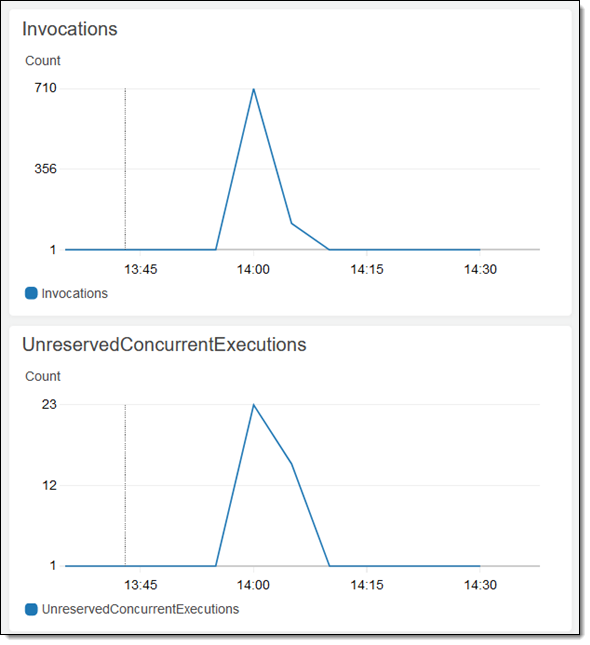
然后像往常一样创建并确认作业。将为每个对象调用此函数,利用 Lambda 的扩展能力,不到一分钟即可运行完此中等大小的作业:
可以在 CloudWatch Logs 控制台中找到“检测到”消息:
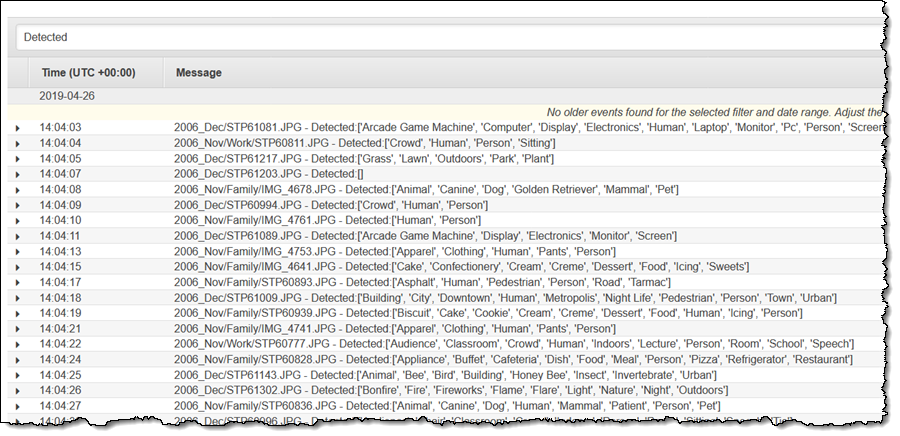
从上述非常简单的示例中可以看出,可对大量 S3 对象轻松运行Lambda 函数,这为各种有趣的应用程序打开了大门。
注意事项
我期待看到和听到您发现的 S3 量操作的用例! 在结束之前,以下列出一些最后的思考:
作业克隆 – 您可以克隆现有作业,微调参数,然后将其重新提交为新作业。您可以使用此选项来重新运行失败的作业或进行任何必要的调整。
编程作业创建 – 您可以将 Lambda 函数附加到生成清单报告的存储桶,并在每次报告到达时创建新的批处理作业。通过编程方式创建的作业不需要确认,并可以立即执行。
CSV 对象列表 – 如果您需要处理存储桶中的对象子集,但无法使用常见前缀来识别它们,则可以创建 CSV 文件并使用其驱动您的作业。您可以从清单报告开始,根据名称筛选对象,或根据数据库或其他参考检查对象。例如,您可能使用 Amazon Comprehend 对所有存储的文档执行情绪分析。您可以处理清单报告以查找尚未分析的文档,并将其添加到 CSV 文件中。
作业优先级 – 您可以在每个 AWS 区域中同时激活多个作业。会优先具有较高优先级的作业,并可能导致暂时暂停现有作业。您可以选择活动作业,然后单击更新优先级以便进行动态更改:
了解更多
以下是一些资源,可帮助您了解有关 S3 批量操作的更多信息:
文档 – 阅读有关创建作业、批量操作和管理批量操作作业的信息。
视频教程 – 观看 S3 批量操作视频教程,了解如何创建作业、管理和跟踪作业以及授予权限。
现已推出
您可以立即在除亚太地区(大阪)外的所有 AWS 商业区域中开始使用 S3 批量操作。在两个 AWS GovCloud(美国)区域中也提供 S3 批量操作。