使用容器运行机器学习(ML)工作负载已成为一种常见的做法。容器不仅可以完全封装您的训练代码,还能封装整个依赖项堆栈甚至硬件库和驱动程序。您会得到一个一致且可移植的机器学习开发环境。通过容器,在集群上进行扩展会变得更加简单。
2022 年底,AWS 宣布正式推出采用 AWS Trainium 加速器的 Amazon EC2 Trn1 实例,专用于提供高性能的深度学习训练。与其他同类的 Amazon Elastic Compute Cloud(Amazon EC2)实例相比,Trn1 实例可节省高达 50% 的训练成本。此外还发布了 AWS Neuron SDK,用于进一步提升加速能力,向开发人员提供工具来与该技术进行交互,例如编译、运行和配置文件,以实现高性能且经济实惠的模型训练。
Amazon Elastic Container Service(Amazon ECS)是一项完全托管式容器编排服务,可简化容器化应用程序的部署、管理和扩展。只需描述您的应用程序和所需资源,Amazon ECS 就会根据灵活的计算选项,启动、监控和扩展您的应用程序,并自动与您的应用程序所需的其他支持性 AWS 服务相集成。
在这篇博文中,我们将向您展示如何使用 Amazon ECS 来部署、管理和扩展机器学习工作负载,以便在容器中运行机器学习训练作业。
解决方案概览
我们将指导您完成以下大致步骤:
- 使用 AWS CloudFormation 预置由 Trn1 实例组成的 ECS 集群。
- 使用 Neuron SDK 构建自定义容器映像,并将其推送到 Amazon Elastic Container Registry(Amazon ECR)。
- 创建任务定义,以定义要由 Amazon ECS 运行的机器学习训练作业。
- 在 Amazon ECS 上运行机器学习任务。
先决条件
要继续学习接下来的内容,需要熟悉 Amazon EC2 和 Amazon ECS 等核心 AWS 服务。
预置 Trn1 实例组成的 ECS 集群
首先,启动提供的 CloudFormation 模板,这将预置所需的资源,例如 VPC、ECS 集群和 EC2 Trainium 实例。
我们使用 Neuron SDK,在采用 AWS Inferentia 和 Trainium 的实例上运行深度学习工作负载的 SDK。它支持您在端到端机器学习开发生命周期中创建新模型,进行优化,然后将其部署到生产环境中。要使用 Trainium 训练模型,您需要在 EC2 实例上安装 Neuron SDK,ECS 任务将在这些实例上运行,从而映射与硬件关联的 NeuronDevice,以及安装将推送到 Amazon ECR 的 Docker 映像,用于访问训练模型的命令。
标准版本的 Amazon Linux 2 或 Ubuntu 20 没有预安装 AWS Neuron 驱动程序。因此,我们有两个不同的选项。
第一个选项是使用已经安装了 Neuron SDK 的深度学习亚马逊机器映像(DLAMI,Deep Learning Amazon Machine Image)。GitHub 存储库中提供了一个示例。您可以根据操作系统选择 DLAMI。然后,运行以下命令获取 AMI ID:
aws ec2 describe-images --region us-east-1 --owners amazon --filters 'Name=name,Values=Deep Learning AMI Neuron PyTorch 1.13.? (Amazon Linux 2) ????????' 'Name=state,Values=available' --query 'reverse(sort_by(Images, &CreationDate))[:1].ImageId' --output text
输出如下所示:
ami-06c40dd4f80434809
此 AMI ID 可能会随着时间而发生变化,因此请务必使用该命令获取正确的 AMI ID。
现在,您可以更改 CloudFormation 脚本中的这个 AMI ID,然后使用现成的 Neuron SDK。为此,请在 Parameters 中查找 EcsAmiId:
"EcsAmiId": {
"Type": "String",
"Description": "AMI ID",
"Default": "ami-09def9404c46ac27c"
}
第二个选项是在创建堆栈期间,填充 userdata 字段来创建一个实例。您不需要进行安装,因为 CloudFormation 会对其进行设置。有关更多信息,请参阅 Neuron 设置指南。
在这篇博文中,我们使用第 2 个选项,以防您需要使用自定义图片。请完成以下步骤:
- 启动提供的 CloudFormation 模板。
- 对于 KeyName,输入所需密钥对的名称,它将预加载参数。对于本博文,我们使用
trainium-key。
- 输入堆栈的名称。
- 如果您在
us-east-1 区域运行,则可以保留 ALBName 和 AZIds 的默认值。
要查看该区域中哪个可用区提供了 Trn1,请运行以下命令:
aws ec2 describe-instance-type-offerings --region us-east1 --location-type availability-zone --filter Name=instance-type,Values=trn1.2xlarge

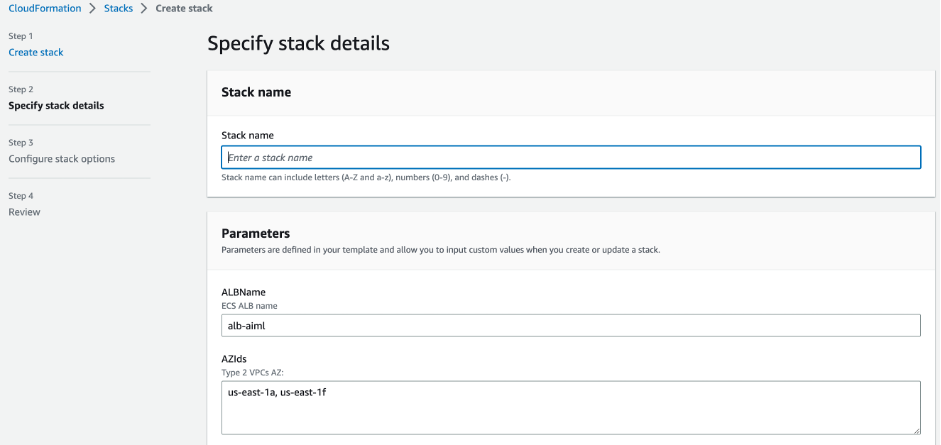
- 选择下一步并完成堆栈的创建。
堆栈完成后,您可以进入下一步。
使用 Neuron SDK 准备并推送 ECR 映像
Amazon ECR 是一个完全托管式容器注册表,提供高性能的托管服务,让您能够在任何地方可靠地部署应用程序映像和构件。我们使用 Amazon ECR 来存储自定义 Docker 映像,该映像包含脚本和 Neuron 软件包,供通过运行在 Trn1 实例上的 ECS 作业训练模型时使用。您可以使用 AWS 命令行界面(AWS CLI)或 AWS 管理控制台创建 ECR 存储库。在本博文中,我们使用的是控制台。请完成以下步骤:
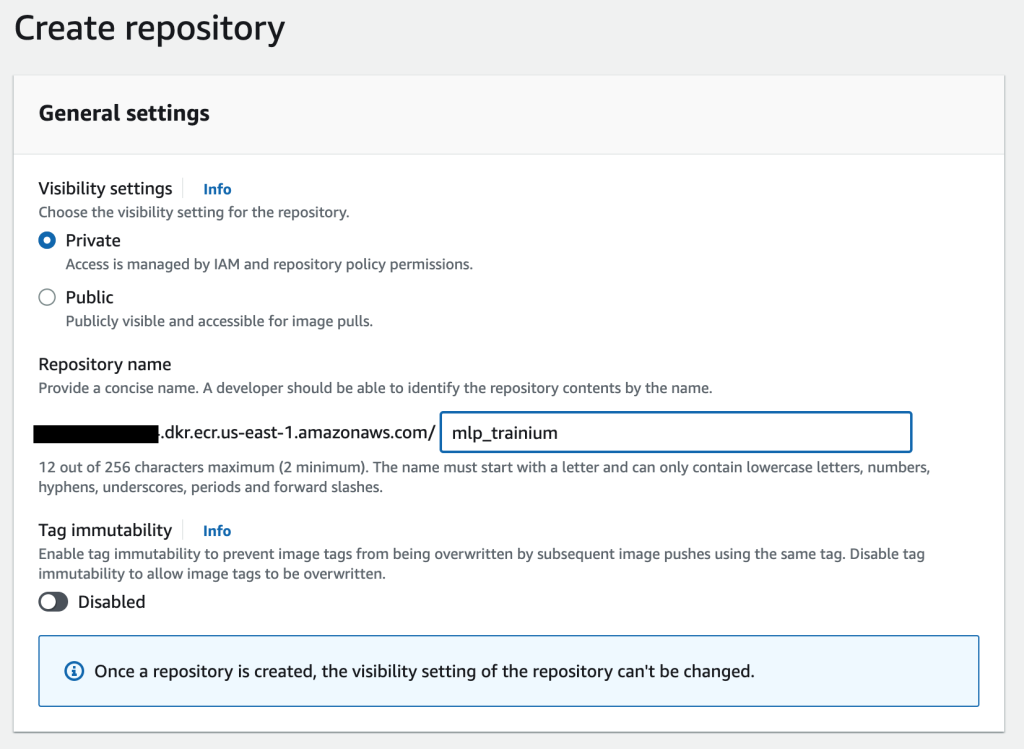
- 在 Amazon ECR 控制台上,创建新存储库。
- 对于可见性设置,选择私有。
- 在存储库名称中,输入名称。
- 选择创建存储库。
现在您有了存储库,我们可以构建并推送一个映像,这个映像可以在本地(笔记本)构建,也可以在 AWS Cloud9 环境中构建。我们训练一个多层感知器(MLP,Multi-Layer Perceptron)模型。要查看原始代码,请参阅多层感知器训练教程。
- 将 train.py 和 model.py 文件复制到项目中。
该项目已经与 Neuron 兼容,因此您无需更改任何代码。
- 5.创建一个 Dockerfile 文件,其中包含安装 Neuron SDK 和训练脚本的命令:
FROM amazonlinux:2
RUN echo $'[neuron] \n\
name=Neuron YUM Repository \n\
baseurl=https://yum.repos.neuron.amazonaws.com \n\
enabled=1' > /etc/yum.repos.d/neuron.repo
RUN rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
RUN yum install aws-neuronx-collectives-2.* -y
RUN yum install aws-neuronx-runtime-lib-2.* -y
RUN yum install aws-neuronx-tools-2.* -y
RUN yum install -y tar gzip pip
RUN yum install -y python3 python3-pip
RUN yum install -y python3.7-venv gcc-c++
RUN python3.7 -m venv aws_neuron_venv_pytorch
# Activate Python venv
ENV PATH="/aws_neuron_venv_pytorch/bin:$PATH"
RUN python -m pip install -U pip
RUN python -m pip install wget
RUN python -m pip install awscli
RUN python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
RUN python -m pip install torchvision tqdm torch-neuronx neuronx-cc==2.* pillow
RUN mkdir -p /opt/ml/mnist_mlp
COPY model.py /opt/ml/mnist_mlp/model.py
COPY train.py /opt/ml/mnist_mlp/train.py
RUN chmod +x /opt/ml/mnist_mlp/train.py
CMD ["python3", "/opt/ml/mnist_mlp/train.py"]
要使用 Neuron 创建自己的 Dockerfile,请参阅在 AWS 机器学习加速器实例上进行开发,在其中可以找到其他操作系统和机器学习框架的指南。
- 6.构建映像,然后使用以下代码将映像推送到 Amazon ECR(提供您的区域、账户 ID 和 ECR 存储库):
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin {your-account-id}.dkr.ecr.{your-region}.amazonaws.com
docker build -t mlp_trainium .
docker tag mlp_trainium:latest {your-account-id}.dkr.ecr.us-east-1.amazonaws.com/mlp_trainium:latest
docker push {your-account-id}.dkr.ecr.{your-region}.amazonaws.com/{your-ecr-repo-name}:latest
之后,应该可以在所创建的 ECR 存储库中看到您的映像版本。
将机器学习训练作业作为 ECS 任务运行
要在 Amazon ECS 上运行机器学习训练任务,您需要先创建任务定义。在 Amazon ECS 中运行 Docker 容器需要任务定义。
- 在 Amazon ECS 控制台的导航窗格中,选择任务定义。
- 在创建新任务定义菜单上,选择使用 JSON 创建新任务定义。

您可以使用以下任务定义模板作为基准。请注意,在映像字段中,您可以使用上一步中生成的映像。确保在字段中包含您的账户 ID 和 ECR 存储库名称。
为确保安装了 Neuron,您可以检查在设备块中是否映射了卷 /dev/neuron0。此命令映射到单个 NeuronDevice,该设备运行在有两个核心的 trn1.2xlarge 实例上。
- 使用以下模板创建任务定义:
{
"family": "mlp_trainium",
"containerDefinitions": [
{
"name": "mlp_trainium",
"image": "{your-account-id}.dkr.ecr.us-east-1.amazonaws.com/{your-ecr-repo-name}",
"cpu": 0,
"memoryReservation": 1000,
"portMappings": [],
"essential": true,
"environment": [],
"mountPoints": [],
"volumesFrom": [],
"linuxParameters": {
"capabilities": {
"add": [
"IPC_LOCK"
]
},
"devices": [
{
"hostPath": "/dev/neuron0",
"containerPath": "/dev/neuron0",
"permissions": [
"read",
"write"
]
}
]
},
,
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-create-group": "true",
"awslogs-group": "/ecs/task-logs",
"awslogs-region": "us-east-1",
"awslogs-stream-prefix": "ecs"
}
}
}
],
"networkMode": "awsvpc",
"placementConstraints": [
{
"type": "memberOf",
"expression": "attribute:ecs.os-type == linux"
},
{
"type": "memberOf",
"expression": "attribute:ecs.instance-type == trn1.2xlarge"
}
],
"requiresCompatibilities": [
"EC2"
],
"cpu": "1024",
"memory": "3072"
}
您也可以在 AWS CLI 上,使用以下任务定义或以下命令完成此步骤:
aws ecs register-task-definition \
--family mlp-trainium \
--container-definitions '[{
"name": "my-container-1",
"image": "{your-account-id}.dkr.ecr.us-east-1.amazonaws.com/{your-ecr-repo-name}",
"cpu": 0,
"memoryReservation": 1000,
"portMappings": [],
"essential": true,
"environment": [],
"mountPoints": [],
"volumesFrom": [],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-create-group": "true",
"awslogs-group": "/ecs/task-logs",
"awslogs-region": "us-east-1",
"awslogs-stream-prefix": "ecs"
}
},
"linuxParameters": {
"capabilities": {
"add": [
"IPC_LOCK"
]
},
"devices": [{
"hostPath": "/dev/neuron0",
"containerPath": "/dev/neuron0",
"permissions": ["read", "write"]
}]
}
}]' \
--requires-compatibilities EC2
--cpu "8192" \
--memory "16384" \
--placement-constraints '[{
"type": "memberOf",
"expression": "attribute:ecs.instance-type == trn1.2xlarge"
}, {
"type": "memberOf",
"expression": "attribute:ecs.os-type == linux"
}]'
在 Amazon ECS 上运行任务
在我们创建了 ECS 集群、将映像推送到 Amazon ECR 并创建任务定义之后,运行任务定义,以在 Amazon ECS 上训练模型。
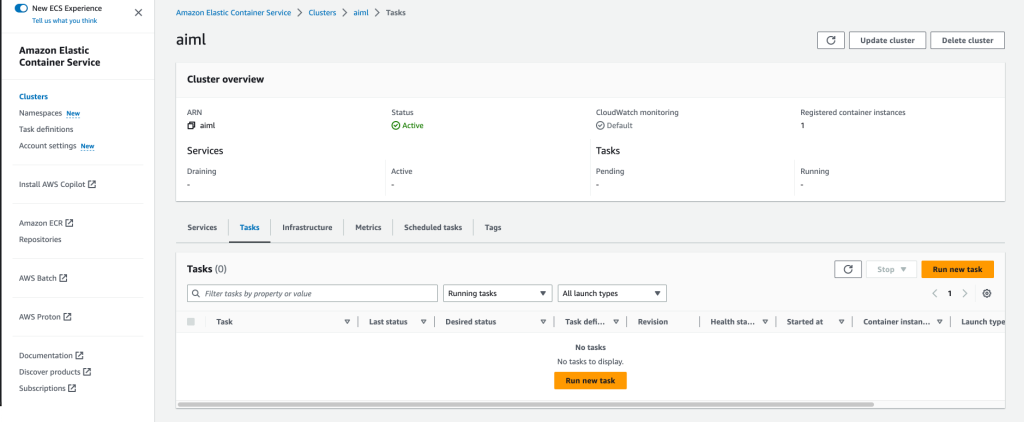
- 在 Amazon ECS 控制台的导航窗格中,选择集群。
- 打开您的集群。
- 在任务选项卡上,选择运行新任务。
- 对于启动类型,选择 EC2。
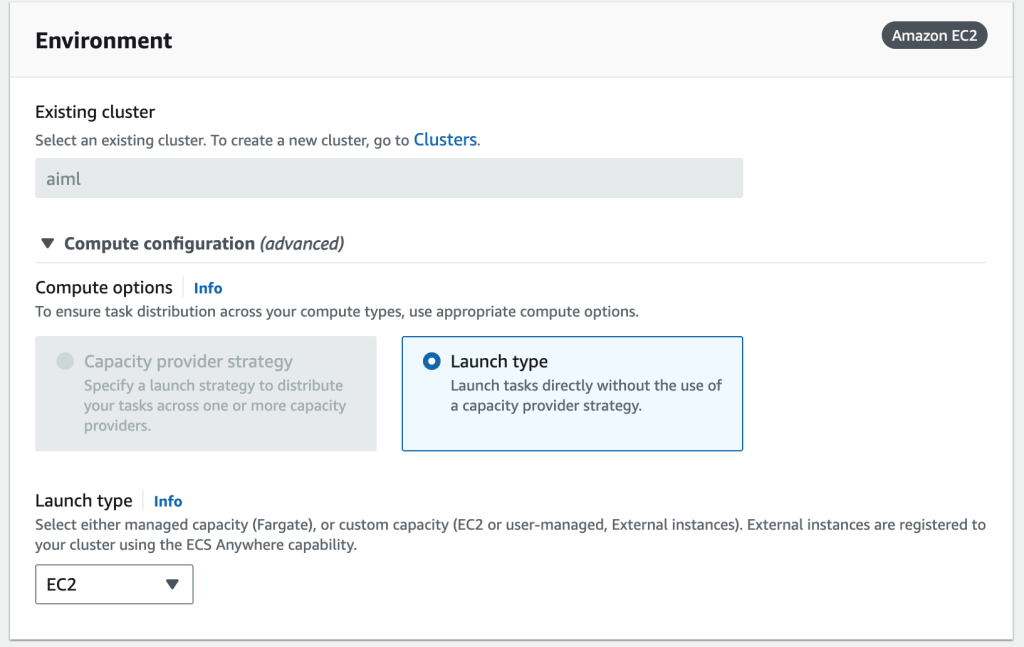
- 对于应用程序类型,选择任务。
- 对于系列,选择您创建的任务定义。
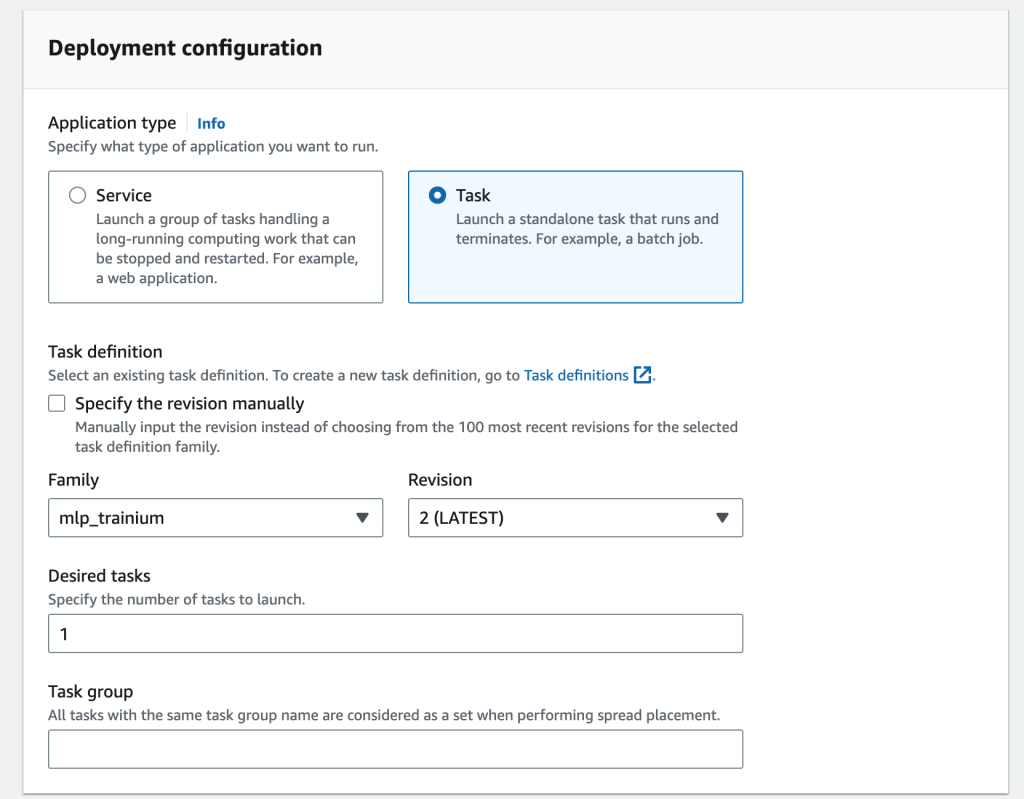
- 在联网部分中,指定由 CloudFormation 堆栈、子网和安全组创建的 VPC。
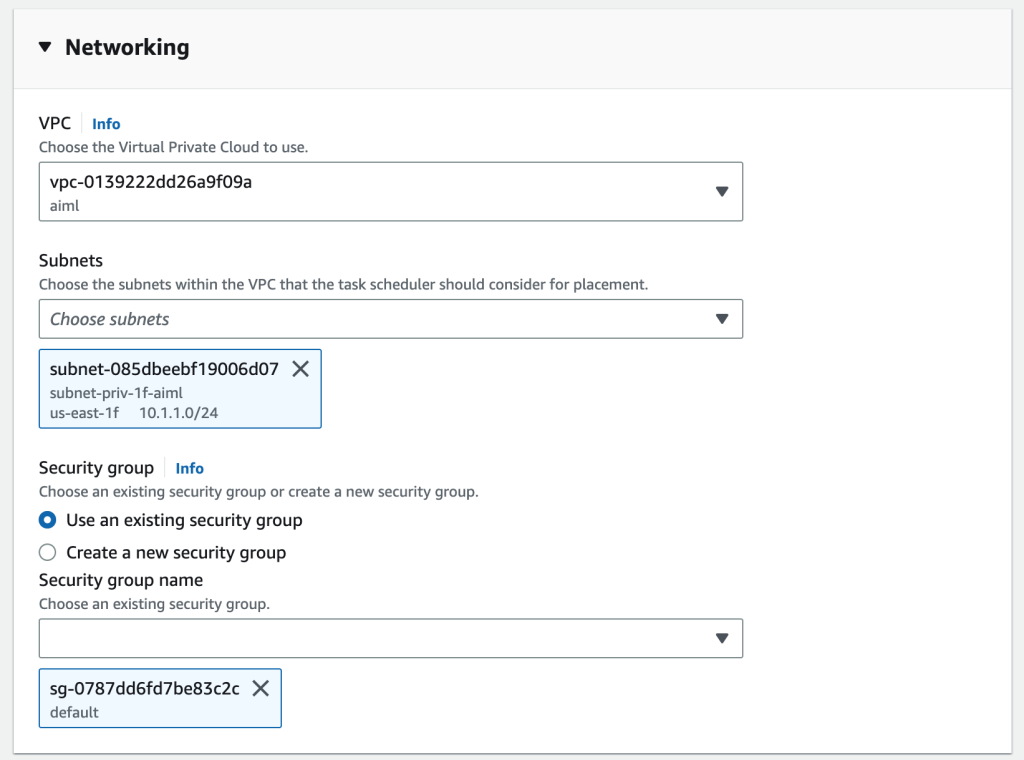
- 选择创建。
您可以在 Amazon ECS 控制台上监控您的任务。

您也可以使用 AWS CLI 运行任务:
aws ecs run-task --cluster <your-cluster-name> --task-definition <your-task-name> --count 1 --network-configuration '{"awsvpcConfiguration": {"subnets": ["<your-subnet-name> "], "securityGroups": ["<your-sg-name> "] }}'
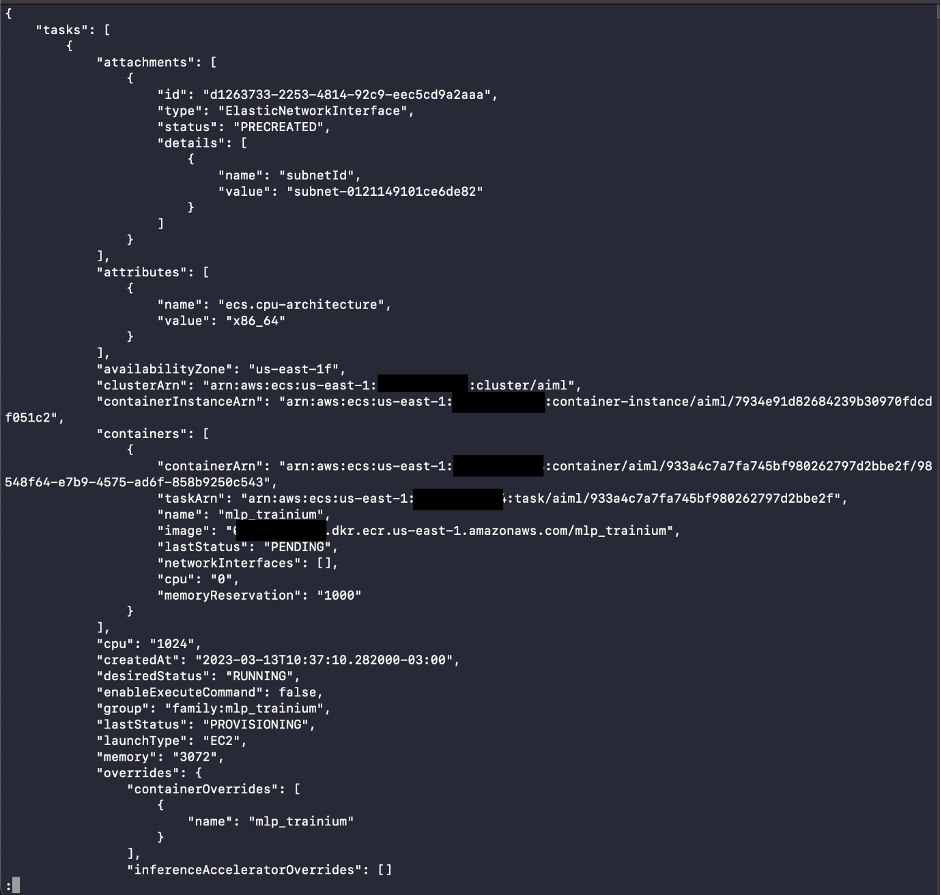
结果将类似以下屏幕截图所示。
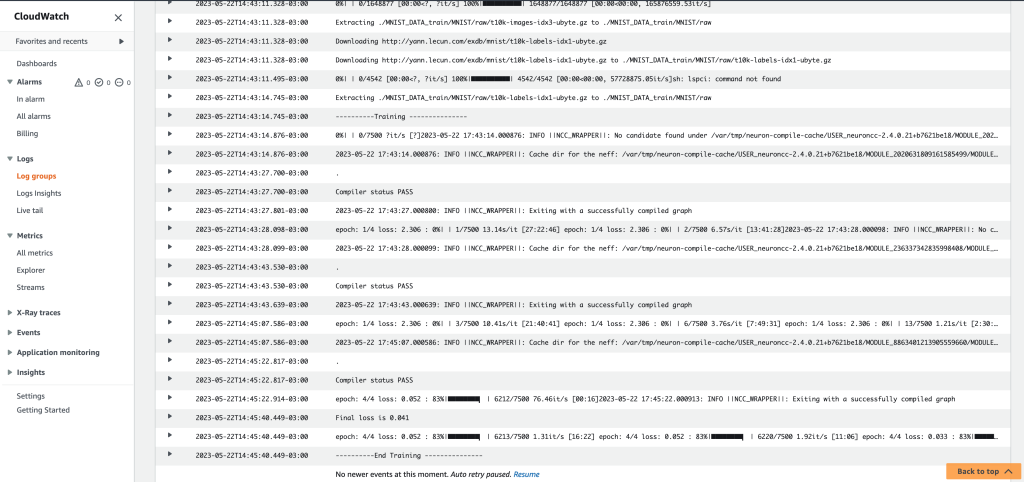
您也可以通过 Amazon CloudWatch 日志组查看训练任务的详细信息。
训练完模型后,可以将其存储在 Amazon Simple Storage Service(Amazon S3)中。
清理
为避免额外开支,您可以将自动扩缩组更改为最低容量,将所需容量更改为零,以便关闭 Trainium 实例。要进行彻底清理,请删除 CloudFormation 堆栈以移除此模板创建的所有资源。
总结
在这篇博文中,我们展示了如何使用 Amazon ECS 部署机器学习训练作业。我们创建了一个 CloudFormation 模板,用于创建由 Trn1 实例组成的 ECS 集群,构建了一个自定义 Docker 映像,将其推送到 Amazon ECR,然后在 ECS 集群上,使用 Trainium 实例运行机器学习训练作业。
有关 Neuron 以及利用 Trainium 所能完成的任务的更多信息,请查看以下资源:
Original URL: https://aws.amazon.com/blogs/machine-learning/scale-your-machine-learning-workloads-on-amazon-ecs-powered-by-aws-trainium-instances/
关于作者
 Guilherme Ricci 是 Amazon Web Services 的初创企业解决方案高级架构师,帮助初创企业进行应用程序的现代化改造和成本优化。他拥有 10 多年的金融领域公司工作经验,目前在与人工智能/机器学习专家团队合作。
Guilherme Ricci 是 Amazon Web Services 的初创企业解决方案高级架构师,帮助初创企业进行应用程序的现代化改造和成本优化。他拥有 10 多年的金融领域公司工作经验,目前在与人工智能/机器学习专家团队合作。
 Evandro Franco 是一名人工智能/机器学习专家级解决方案架构师,就职于 Amazon Web Services。他帮助 AWS 客户在 AWS 上克服与人工智能/机器学习相关的业务挑战。他在技术领域工作了超过 15 年,涉及软件开发、基础设施、无服务器和机器学习等多个领域。
Evandro Franco 是一名人工智能/机器学习专家级解决方案架构师,就职于 Amazon Web Services。他帮助 AWS 客户在 AWS 上克服与人工智能/机器学习相关的业务挑战。他在技术领域工作了超过 15 年,涉及软件开发、基础设施、无服务器和机器学习等多个领域。
 Matthew McClean 领导 Annapurna 机器学习解决方案架构团队,帮助客户采用 AWS Trainium 和 AWS Inferentia 产品。他对生成式 AI 充满热情,在过去 10 年中一直在推动客户采用 AWS 技术。
Matthew McClean 领导 Annapurna 机器学习解决方案架构团队,帮助客户采用 AWS Trainium 和 AWS Inferentia 产品。他对生成式 AI 充满热情,在过去 10 年中一直在推动客户采用 AWS 技术。