亚马逊AWS官方博客
使用 TensorBoard 实现 TensorFlow 训练作业可视化
Original URL: https://aws.amazon.com/cn/blogs/machine-learning/visualizing-tensorflow-training-jobs-with-tensorboard/
TensorBoard 是一款面向TensorFlow用户的开源工具包,可帮助您可视化有关您的模型的广泛的有用信息,从模型图,到损失率、准确率或自定义指标,乃至到权重与偏差的嵌入投射、图像和直方图等。
本文旨在向大家介绍如何在Amazon SageMaker训练作业中使用TensorBoard,如何从TensorFlow训练脚本中写日志到 Amazon Simple Storage Service (Amazon S3),以及如何运行TensorBoard的方法:本地运行,使用在 AWS Fargate上的 Amazon Elastic Container Service (Amazon ECS),或在 Amazon SageMaker notebook 实例中运行。
使用tf.summary生成训练日志
TensorFlow提供的tf.summary模块能够写汇总数据,这些数据可以用来实现监控与可视化功能。该模块的API还提供用于编写标量、音频、直方图、文本以及图像汇总的方法,可跟踪各类有助于剖析训练作业的信息。下面是一个示例命令,输出训练作业第一步的准确率:
tf.summary.scalar('accuracy', 0.45, step=1)
为了要在训练作业完成后使用汇总数据,将相关文件写入到永久存储上很重要。这样,您才能可视化以往训练作业,或者对比超参数调优阶段中的不同作业的运行。将S3存储桶的URI直接传递至create_file_writer方法,tf.summary模块允许您将Amazon S3指定为日志文件的写入目标。见以下代码:
tf.summary.create_file_writer('s3://<bucket_name>/<prefix>')
Keras用户可以将keras.callbacks.TensorBoard作为回调提供给Model.fit()方法。该回调能够提供底层tf.summary API的抽象,并自动收集大量数据。使用TensorBoard回调,您可以收集数据来可视化训练图、指标线图、激活直方图,和运行剖析。见以下代码:
关于如何在训练脚本中收集汇总数据的详细示例,请参阅Amazon SageMaker示例 GitHub repo 上的TensorBoard Keras示例 notebook,或者在 Amazon SageMaker Examples 选项卡中找到正在运行的 Amazon SageMaker notebook实例。该notebook使用TensorFlow 2.2与Keras训练卷积神经网络(CNN),识别CIFAR-10数据集中的图像。该notebook中的代码在本地notebook实例中运行一次训练作业,然后在超参数调优作业中运行10次。全部训练作业都将写同一Amazon S3前缀的日志文件,所以每次运行的日志目标路径都遵从 s3://<bucket_name>/<project_name>/logs/<training_job_name>格式,示例中的<project_name>为 tensorboard_keras_cifar10。

visualizing-tensorflow-training-jobs-with-tensorboard
该notebook也展示了如何在Amazon SageMaker notebook实例之内运行TensorBoard。这种方法存在一些限制;例如,TensorBoard命令阻止notebook运行并且在notebook实例生命周期内一直存在,但是允许您快速访问仪表板并确信训练作业的正确执行。
在以下各节中,将讨论TensorBoard的另外几种运行方式。
在本地设备上运行TensorBoard
如果您希望以本地方式运行TensorBoard,首先需要安装TensorFlow:
pip3 install tensorflow
您也可以直接使用TensorBoard的独立发行版,但在缺少TensorFlow的情况下,其功能会受到限制。在本文中,直接使用TensorFlow发行版中提供的TensorBoard。
假设您的AWS命令行界面(AWS CLI)已安装并配置好,即可运行指向存储了汇总数据的Amazon S3目录的TensorBoard:
AWS_REGION=eu-west-1 tensorboard --logdir s3://<bucket_name>/tensorboard_keras_cifar10/logs/
请注意,您必须指定S3存储桶的所在区域。您可以在Amazon S3控制台上的存储桶列表中,找到正确的区域。
您使用的用户还需要对指定的S3存储桶拥有读取权限。关于向特定用户安全授予S3存储桶访问权限的更多详细信息,请参阅编写IAM策略:如何授予对Amazon S3存储桶的访问权限。
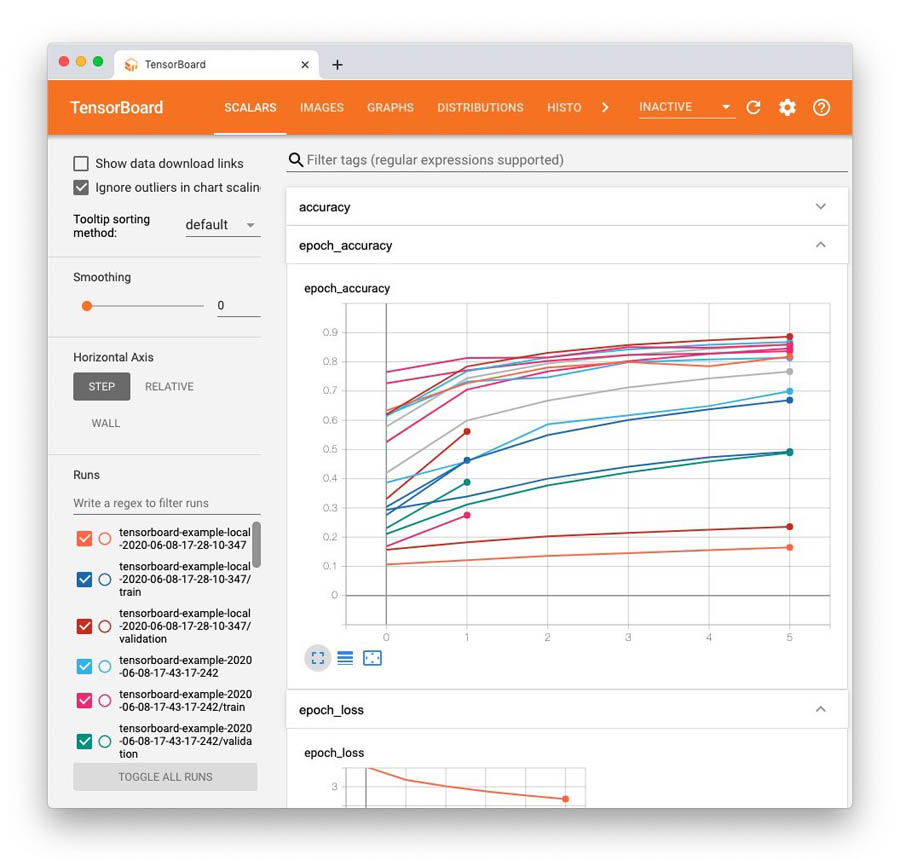
到这里,您应该看到如以下截屏所示的相似内容。

在AWS Fargate上的Amazon ECS中运行TensorBoard
如果您希望持久运行TensorBoard实例以供整个团队访问,则可将其以独立应用程序的形式部署在云端。不需要管理服务器的最简单的方式之一是使用AWS Fargate,它是用于容器的无服务器计算引擎。下图展示了这个架构。
您可以使用AWS CloudFormation 模板中提供的应用程序负载均衡器和全部需要的角色,部署完成一个示例TensorBoard容器镜像:

此模板共包含五项输入参数:
- TensorBoard container image –通过
tensorflow/tensorflow用于标准发行版;如果需要启用Profiler插件,则指定自定义容器镜像。 - S3Bucket – 输入为TensorFlow日志存储所在的存储桶名称。
- S3Prefix – 输入存储桶内的TensorFlow日志路径,例如
tensorboard_keras_cifar10/logs/ - VpcId – 选择部署TensorBoard的VPC。
- SubnetId – 在选定的VPC内选择两个或更多子网。
这个示例解决方案并不包含授权及身份验证机制。请注意,如果将TensorBoard部署至可公开访问的子网中,那么任何能够访问互联网的人都能够访问TensorBoard实例及其中的训练日志。您可以使用以下方法保护TensorBoard:
- 在应用程序负载均衡器中设置授权要求。关于具体操作说明,请参阅 使用应用程序负载均衡器的内置身份验证机制以简化登录流程。
- 部署TensorBoard到私有子网中,通过VPN对其进行访问。关于具体操作说明,请参阅 如何在办公室网络与Amazon Virtual Private Cloud之间创建安全连接?
在完成CloudFormation栈的创建之后,您可以在AWS CloudFormation控制台的Outputs选项卡中,找到已部署TensorBoard的对应链接。

使用自定制TensorBoard容器镜像
因为TensorBoard是TensorFlow发行版的一部分,您可以使用Docker Hub上的官方tensorflow Docker容器镜像。
另外,也可以构建一套带有Profiler TensorBoard插件的定制化镜像,该插件可用来可视化剖析数据:
您可以在本地构建并测试容器:
在容器测试完成之后,您需要将其上传至您所指定的容器镜像库中。受篇幅所限,本文无法涵盖详尽的应用程序部署流程。要设置Amazon ECS与Elastic Load Balancer,请参阅使用AWS Fargate构建、部署及运营容器化应用程序。
总结
在本文中,展示了使用TensorBoard可视化TensorFlow训练作业,以Amazon S3作为日志存储。您可以使用这套解决方案以及对应的示例notebook,通过Amazon SageMaker构建和训练模型,并运行超参数调优作业。此外,您可以使用TensorBoard对不同训练作业中的超参数进行比较,生成并显示分类器混淆矩阵,剖析并可视化训练作业的性能。