AWS での分析
料金パフォーマンスと規模に合わせて最適化された、あらゆる分析ワークロードに対応する包括的な機能セット
概要
AWS は、あらゆる分析ワークロードに対応する包括的な機能セットを提供します。データ処理や SQL 分析から、ストリーミング、検索、ビジネスインテリジェンスまで、AWS はガバナンスが組み込まれた比類のない料金パフォーマンスとスケーラビリティを提供します。特定のワークロード向けに最適化された目的別サービスを選択するか、または Amazon SageMaker を利用してデータと AI ワークフローを合理化および管理します。 データジャーニーを開始しようとしている場合でも、統合エクスペリエンスをお求めの場合でも、AWS は、データを利用してビジネスを革新するのに役立つ適切な分析機能をお客様に提供します。
AWS の分析で具体的なビジネス成果を上げる
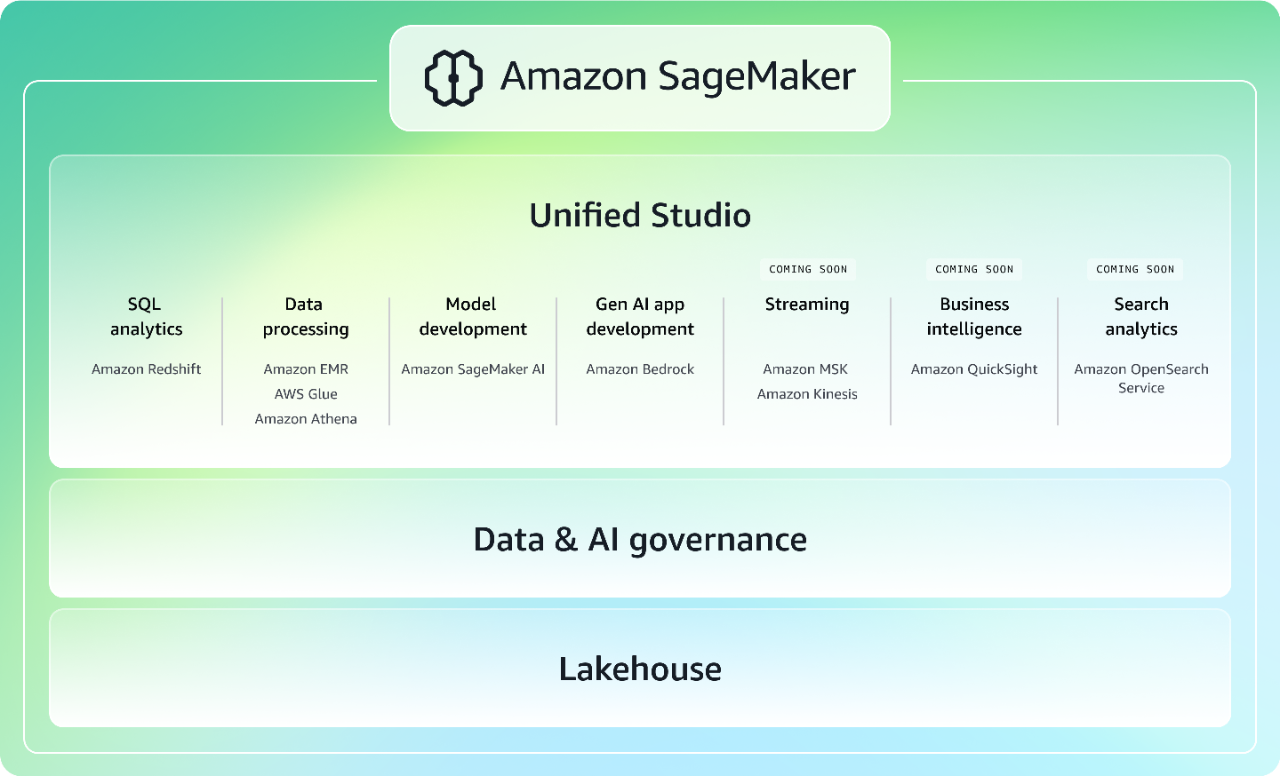
統合エクスペリエンスでデータ、分析、AI を加速する
広く採用されている AWS の機械学習 (ML) と分析機能をまとめた次世代の Amazon SageMaker は、すべてのデータに対する統合アクセスとともに、分析と AI のための統合エクスペリエンスを提供します。モデル開発、生成 AI アプリケーション開発、データ処理、SQL 分析のための使い慣れた AWS ツールを使用して、統合スタジオからより迅速にコラボレーションして構築できます。これは、ソフトウェア開発のための極めて有能な生成 AI アシスタントである Amazon Q Developer によって加速されます。データレイク、データウェアハウス、サードパーティーまたはフェデレーテッドデータソースのいずれに保存されているかにかかわらず、すべてのデータにアクセスし、組み込みガバナンスを活用して、企業のセキュリティニーズに対応できます。SageMaker の詳細
AWS によるマルチクラウド戦略の実現
AWS は、マルチクラウド環境とハイブリッド環境全体でシームレスなデータアクセスと処理を可能にする強力な分析サービスを包括的に提供しています。この柔軟性は、フェデレーションクエリ、データ統合、安全なデータ移動、オープンスタンダードとの互換性によって実現できます。これにより、データの保存場所に関係なく、すべてのデータから洞察を得ることができます。
Amazon Athena では、データをコピーしたり変換したりしなくても、Azure Data Lake Storage、Google Cloud Storage、Microsoft SQL Server など、さまざまな外部データソースに保存されているデータをクエリして分析情報を得ることができます。
AWS Glue は、クラウドストレージ、データベース、分析サービスにまたがる 100 を超えるさまざまなデータソース用のコネクタを使用して、あらゆる規模のすべてのデータの検出、準備、統合を簡素化します。Glue のゼロ ETL 統合により、Salesforce、SAP、Facebook Ads、Instagram Ads などのサードパーティアプリケーションからのデータを、AWS レイクハウス、データレイク、データウェアハウスに直接簡単に取り込んで複製できます。AWS Glue は、Apache Hive、Apache Parquet、Apache Iceberg などのオープンスタンダードをサポートすることで、データの相互運用性も提供します。
次世代の Amazon SageMaker はオープンデータレイクハウスアーキテクチャに基づいて構築されており、AWS 上のデータレイクやデータウェアハウス、Google BigQuery や Snowflake などのフェデレーテッドデータソースへのユニファイドアクセスを提供します。このレイクハウスアーキテクチャは Apache Iceberg と完全に互換性があるため、Iceberg 互換のツールやエンジンを使用してインプレースでデータへのアクセスやクエリを柔軟に行うことができます。
人間と AI のためのアナリティクスの活用
データの保存、クエリ、ストリーミング、処理、管理に特化したサービスを使用して、大規模な分析を強化します。オープンテーブルフォーマット (OTF) からエージェントインフラストラクチャまで、AWS は急速に変化する分析環境に対応する分析エンジンとアプリケーションを進化させています。このセッションでは、AWS が人間のユーザーとエージェントのワークフローの両方向けに構築された最適化されたソリューションをどのように提供しているかをご覧ください。

サービス
|
分析カテゴリ
|
説明
|
AWS のサービスと機能
|
|---|---|---|
|
ストリーミング
|
インフラストラクチャ管理の負担なしに、リアルタイムのデータパイプラインとアプリケーションを構築、拡張、運用します。 |
|
|
データレイクハウス、データウェアハウス、データレイク
|
データレイクハウス、データウェアハウス、データレイクのすべてのデータにアクセスして分析します。 |
|
|
データ処理
|
オープンソースのフレームワークを使用して、分析と AI のためにデータを分析、準備、統合します。 |
|
|
ビジネスインテリジェンス
|
モダンでインタラクティブなダッシュボード、ピクセルパーフェクトなレポート、自然言語クエリ、埋め込み分析を通じて、有意義なインサイトを構築、発見、共有できます。 |
|
|
検索分析
|
ビジネスおよびオペレーションデータのリアルタイム検索、モニタリング、分析を安全に実現します。 |
|
|
データと AI のガバナンス
|
AWS、オンプレミス、およびサードパーティーのソースに保存されているデータをカタログ化、検出、共有、管理します。 |
AWS モダンデータ戦略の全体的な経済的影響
Forrester が報告したように、アマゾンウェブサービスのモダンデータ戦略によって実現されたコスト削減とビジネス上のメリット。
統計情報
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください