Amazon Web Services ブログ
Amazon SageMaker は k近傍 (kNN) 分類および回帰のサポートを開始しました
Amazon SageMaker が、分類と回帰の問題を解決するため、ビルトイン k-Nearest-Neighbor (kNN) アルゴリズムのサポートを開始したことをご報告します。kNN は、マルチクラス分類、ランキング、および回帰のためのシンプルで、解釈しやすい、そして驚くほど強力なモデルです。
kNN の導入
kNN の背後にある考えは、類似したデータポイントは、少なくともほとんどの時間、同じクラスを持つ必要があるというものです。この方法はとても直感的で、レコメンデーションシステム、異常検出、画像 / テキスト分類を含む多くの分野で実証されています。
例えば、「人物」、「動物」、「屋外」、「海」、「日没」など、考えうる 2000 のタイプのうちの 1 つとして、あるイメージを分類する場合を考えてみましょう。画像間の適切な距離関数が与えられると、ラベル付けされていない画像の分類は、最近傍に割り当てられたラベル、すなわち距離関数に従ってそれに最も近いラベルの付いた画像によって決定されます。
あまり見られませんが、kNN の別の使用法は、回帰問題です。ここでの目的は、クエリのクラスを決定するのではなく、むしろ連続する数字 (例えば、特定の人の給与、ある実験にかかるコストなど) を予測することです。クエリの予測は、その近傍のラベルの関数として設定されます。通常は、平均として、そして時には外れ値を特定する方法としての平均値または幾何平均として、設定されます。
どんな時に kNN を使用するか?
kNN 分類と回帰の使用を考えている場合に、考慮すべきいくつかのメリットとデメリットについてご紹介します。
メリット
予測品質: kNN クラシファイヤー (分類器) は、例えばクラス間の線形分離を必要とする線形クラシファイヤーとは対照的に、空間の非構造化パーティションを回復することができます。また、空間の異なる密度にも適応することができ、放射基底関数 (RBF) カーネルによるサポートベクターマシン (SVM) 分類といった方法よりも安定しています。 2D データの下記の 2 つの例は、ラベルの付いたデータによって与えられた空間の異なるパーティションおよびその空間上の kNN モデルの予測を示しています。
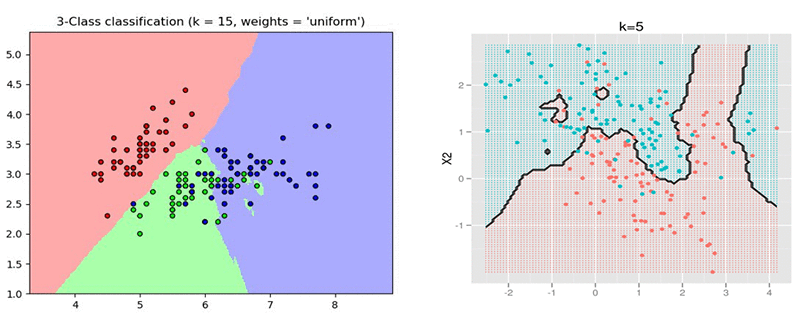
短いサイクル: kNN のもうひとつの利点は、トレーニングがほとんど、あるいは全く必要ないことです。つまり、深いネットワークや SVM、または線形関数などの多くのトレーニング手順を必要とするクラシファイヤーと比較すると、入力データセットの考えられる様々なメトリック / 修正に対する反復が、潜在的に高速であることを意味しています。
多くの出力クラス: kNN は非常に多くのクラスをシームレスに処理できます。比較すると、交差エントロピー損失を伴う線形モデルまたはディープニューラルネットワークは、考えられる各クラスのスコアを明確に計算し、最良のものを選択しなければなりません。例えば、画像または特徴のセットによって花の種類を認識するタスクを想像してください。10 万個のラベルが付いた特徴の例と 5,000 個の花の種類の例があります。それぞれの花の種類を識別するのに、5,000 個のパラメータセットを明確に学習するモデルはどれもすぐに過学習してしまう傾向があり、誤った答えを生む可能性があります。
解釈能力: kNNモデルの予測は、既存のオブジェクトとの類似性に基づいています。その結果、「なぜこの例は、クラス X を与えられたのか?」という質問が生じます。それには「類似の項目には X というラベルが付けられているから。」と答えます。例えば、ローンに関連するリスクを評価するモデルを考えてみましょう。この例では、X、Y、および Z に関してすでに評価され、それらに最も類似していた 10 人の顧客のうち 8 人が高いリスクを有することが判明したため、顧客は高いリスクと判断されました。最近傍を見ると、例のような X とラベルの付いた例に類似したオブジェクトが表示され、予測が意味を成すかどうかを判断できるのです。
デメリット
コストの高い推論: kNN の大きな欠点は、推論にコストがかかることです。入力クエリのラベルを推測するにはそれに最も近いデータ点を見つける必要があります。単純な解決策は、全てのデータ点をメモリに保存し、クエリが与えられると、そのデータ点と全てのデータ点との間の距離を計算するというものです。具体的な量の場合、トレーニングセットに d 次元の n 個のデータ点が含まれていた場合、このプロセスにはクエリごとの O(nd) 回の演算と O(nd) 個のメモリが必要です。大規模なデータセットの場合、コストがかかる可能性があります。このコストは削減することができます。それについては後で詳しく説明しますが、一般的に言って、Linear Learner (線形学習器) や決定木などの代替アルゴリズムと比較して、コストはまだ大きいといえます。
推論コストの削減
先に述べたように、推論は kNN でかなりコストがかかることがあります。そのコストを軽減するのに利用される一般的なアプローチは、全て Amazon SageMaker kNN でサポートしています。
サブサンプリング: 推論コスト削減のための、とてもシンプルでありながら、ほとんどの場合非常に有効な方法は、データをサブサンプルすることです。他の学習設定と同じように、実際に必要なデータ点より多くのデータ点がある可能性があります。例えば、1000 万個のデータ点のデータセットを利用できるかもしれませんが、10 万個のデータ点でも十分な仕事をすることができます。
次元削減: L2 やコサイン距離などある程度の距離では、クエリ点とあらゆるデータ点間の距離をほぼ同じに保ちながら、データ点の次元を縮小することができます。近似の品質は、出力の次元のみに依存します。小さな次元は粗近似を意味しますが、次元を縮小しながら距離の近似を十分に得ることができるケースはよくあります。この方法の主な欠点は、出力が密であることです。そのため、非常にまばらなデータや初めからデータの次元が低い場合は、これが最善の方法ではない可能性があります。
量子化: 空間と計算のオーバーヘッドを削減する別の方法は、より低い精度で作業することです。Float16、固定小数点精度 (整数)、またはバイナリ値に変更することができます。直積量子化と呼ばれる似たような方法がありますが、(https://lear.inrialpes.fr/pubs/2011/JDS11/jegou_searching_with_quantization.pdf)、個々の数ではなく小さいグループの数を量子化します。このテクニックによって、単一ビットの量子化よりもさらにスペースと計算を節約できます。この方法の大きな欠点は、その保証がデータに依存し、ハイパーパラメータを調整する必要があることです。そうは言うものの、これらのテクニックは大変一般的なもので、経験的に証明されています。
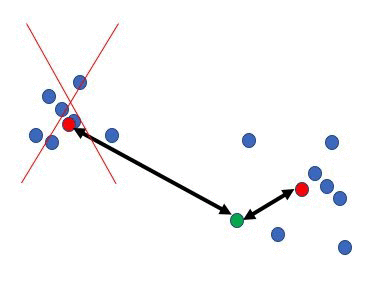
リージョンのすばやい回避: 上記の方法は、各データ点からクエリまでの距離を計算する時間を短縮するのに役立ちます。これは、クエリごとのランタイムが、一部の p << d に対して O(nd) ではなく O(np) になることを意味します。データ点の数 n が非常に大きい場合、これらのアプローチは役に立たず、何か他のことを行う必要があります。データ点を迅速に不適格にする一般的なアプローチは、クラスタリングによるものです。クラスタの中心がクエリから遠く離れている場合、全てのデータ点を調べることなく、クラスタ全体を不適格にすることができます。このテクニックでは、データは一般的に k 平均法クラスタリングを使って、m << n 個の中心点を得るために前処理しておく必要があります。次に、クエリが到着すると、全ての中心点までの距離を計算し、クエリから遠く離れた中心点を持つクラスタに属する全ての点は無視されます。 このプロセスを次の図に示します。ここで、クエリは緑色の点で、データ点は青色、クラスタの中心点は赤色です。左側にあるクラスタは、単一距離計算によって除去されます。
Amazon SageMaker kNN
Amazon SageMaker kNN にはトレーニングフェーズと推論フェーズがあります。トレーニングフェーズでは、データ点を 1 台のマシンに収集し、検索インデックスを作成します。検索インデックスは、クエリ点の (近似) 最近傍を取得するために使用されるオブジェクトです。推論フェーズでは、あらかじめ構築しているインデックスによって提供される最近傍に基づいて、クエリの予測を生成します。
トレーニング
トレーニングプロセスは、複数のマシンで実行できます。 トレーニング中、各マシンはデータのシャードを処理します。マシンは、インデックスするべきデータ点の大きなサンプルを集合的に取得します。Sample_size ハイパーパラメータをデータ点の数以上または等しい値に設定することで、全てのデータ点が考慮されることに留意ください。サンプルを通信する前に、マシンは次元削減テクニックを呼び出すことで、各点の空間を縮小することができます。これはハイパーパラメータの dimension_reduction_type および dimension_reduction_target を使って設定でき、これで、テクニックと標的範囲を決定します。
データ点のサンプルを収集した後、それを処理してインデックスを作成します。現在、Amazon SageMaker kNN は、FAISS インデックスをサポートしており、そのハイパーパラメータを平面化します。FAISS は、CPU および GPU ハードウェアをサポートする L2 とコサイン距離に最適化したオープンソース近似最近傍探索ツールです。現在サポートしているインデックスタイプは、「Flat」、「IVFFlat」、「IVFPQ」です。ドキュメントの中で、各インデックスタイプに関連する異なったハイパーパラメータについて述べています。
推論
先に説明したように、データ点を収集し、インデックスを前処理した後、このモデルで推論を行うことが可能となります。推論は CPU または GPU マシン上で行うことができます。経験則として、比較的少量のアイテムをクエリする必要がある場合、つまり遅延が問題になる可能性があるがスループットはそうでない場合は、CPU マシンが推奨されます。一方、大量のクエリのために高いスループットが必要な場合は、GPU マシンを使用することが望ましい場合があります。 インデックスが非常に大きい場合は、GPU マシンの推論も推奨します。例えば、データに 100 万個のデータ点と brute-force (“Flat”) インデックスが 1,000 個の次元データで必要な場合、GPU の推論は、特にクエリのバッチが与えられた場合には、遅延が縮小する可能性があります。以下では、GPU や CPU を含むいくつかのハードウェアタイプの推論ランタイムを測定するノートブックの例を示します。
クエリに対して提供される出力は、最近傍の集合ではなく、予測です。分類問題においては、最も可能性の高いクラスです。回帰問題では、回帰値を返します。 カスタム予測と探索的解析を可能にするため、冗長推論モードを実装しています。このモードでは、最近傍のラベルおよび距離も返すことが可能です。以下の詳細な例では、冗長モードを使用して、予測を決定する近傍の数 k の最適値を決定する方法を示します。
注目すべき隆起点
サンプルサイズ: 一般的なシナリオは、1000 万点のデータセットの場合、k の最良値は、例えば 5000 のオーダーの中にあります。 このような場合、k = 50 と共に 10 万点を含むデータのサブサンプルは、実際にはほぼ同じ精度かもしれませんが、推論時間は一桁以上高速となります。経験則として、k の値が大きいと考える場合、サンプリングは同じような精度を維持しながら、推論のコストを削減できる可能性は高くなります。
次元削減: データに 10,000 を超える次元の入力ベクトルが含まれている場合は、前処理に次元削減テクニックを使用することを推奨します。このテクニックで、出力品質にほとんど影響を与えずに、データの次元を 1000 から 5000 のオーダーに減らすことができます。
実例: kNN による分類
kNN のユースケースの例を見てみましょう。 マルチクラス問題のデータを含む covtype データセットをダウンロードします。kNN モデルをトレーニングし、それをテストセットに適用します。この例をご自分で実行するには、Jupyter ノートブックをご参照ください。ノートブックでは、kNN の異なるハイパーパラメータをより掘り下げた例とともに、こちらの例を見ることができます。
データセット
UCI Machine Learning Repository Covertype データセット (covtype) を使います (著作権 Jock A. Blackard、およびコロラド州立大学)。これはラベル付きのデータセットで、各エントリは地理的領域を、ラベルは森林被覆の一種を表しています。7 つの考えうるラベルがあり、kNN を用いてマルチクラス分類問題を解くことを目指します。
まず、データセットをダウンロードして一時フォルダに移します。
データの前処理
生データがあるので、それを処理してみましょう。最初にデータを Numpy 配列にロードし、無作為にトレーニングに分割し、90/10 の分割を使用してテストします。
Amazon S3 へアップロード
通常、データセットは大きく、Amazon S3 にありますので、データを Amazon S3 に recordio-protobuf 形式で書き込んでみましょう。まず、データをラップする IO バッファを作成し、Amazon S3 にアップロードします。Amazon S3 バケットとプレフィックスの選択は、異なるユーザーや異なるデータセットに対して変更する必要があることに注意してください。
テストデータを提供することもできます。こうして、トレーニングログからモデルのパフォーマンスを評価することが可能です。この機能を使用するため、テストデータを Amazon S3 にもアップロードしましょう。
トレーニング
ここで少し、SageMaker で Machine Learning のトレーニングと予測がどのように機能しているかを高いレベルで説明します。まず、モデルをトレーニングする必要があります。これは、ラベルの付いたデータセットとトレーニングプロセスを導くハイパーパラメータが与えられ、モデルを出力するプロセスです。トレーニングの終了後、エンドポイントを設定します。エンドポイントは、ラベルのないデータ点またはデータ点のミニバッチを含むリクエストがある場合、予測または予測のリストを返すウェブサービスです。
Amazon SageMaker では、トレーニングは、エスティメーターと呼ばれるオブジェクトを使って行います。エスティメーターを設定する際には、トレーニングデータの (Amazon S3 内にある) 場所、モデルをシリアル化する出力ディレクトリへの (Amazon S3 内にある) パス、トレーニングプロセス中に使用するマシンタイプといった一般的なハイパーパラメータ、およびインデックスタイプなどの kNN 固有のハイパーパラメータを指定します。エスティメーターを初期化した後は、実際のトレーニングを行うために fit メソッドを呼び出すことができます。
トレーニングの準備が整いましたので、トレーニングジョブを開始する便利な機能から始めます。
次に、実際のトレーニングジョブを実行します。ここでは、デフォルトのハイパーパラメータを使用します。
トレーニングジョブでテストセットを述べたことに注意してください。テストセットが提供されると、トレーニングジョブは単にモデルを生成するだけでなく、テストセットに適用し精度を報告します。ログでは、テストセット上のモデルの精度を見ることができます。全ログをノートブックで見ることができます。
エンドポイントの設定
これでトレーニングしたモデルができたので、推論を実行する準備が整いました。そして、 knn_estimator オブジェクトには、モデルのホスティングに必要なあらゆる情報が含まれています。次のコードでは、エスティメーターを指定すると、モデルをホストするエンドポイントを設定する便利な機能を提供します。エスティメーターオブジェクト以外にも、エスティメーターの名前 (文字列) と instance_type を提供できます。 instance_type は、モデルをホストするマシンタイプです。これは、トレーニングジョブのハイパーパラメータ設定によって決して制限されることはありません。
推論
プレディクター (推論器) が準備できたので、テストデータセットで使用してみましょう。次のコードはテストデータセットで実行され、精度と平均遅延を計算するものです。これは、データを 100 個のバッチに分割します。サイズはそれぞれ約 500 です。次に、各バッチが推論サービスに与えられ、予測を行います。全ての予測が終わったら、テストセットの真のラベルをもとに正確性を計算します。
エンドポイントの削除
これで、最終的なクリーンアップを除き、こちらの例は完了です。エンドポイントを設定して、クラウド内で仮想マシンを開始しました。これが削除されない限り、仮想マシンは依然実行しています。つまり、そのコストを支払っていることになります。エンドポイントが不要になったら、削除できます。次のコードで、それを正確に行いましょう。
まとめ
kNN の推論エンドポイントをトレーニングし、ホストする方法を見てきました。完全なゼロ調整を行うと、covtype データセットで 92.2% の精度を得ることができます。kNN モデルの予測能力を把握するための基準点として、線形モデルは約 72.8% の精度を達成します。ここで考察していない、高度な問題がいくつかあります。ランタイム / 遅延、モデルのチューニングなどの問題をもっと掘り下げたり、精度とランタイム効率を考慮したい方は、(https://github.com/awslabs/amazon-sagemaker-examples/blob/master/introduction_to_amazon_algorithms/k_nearest_neighbors_covtype/k_nearest_neighbors_covtype.ipynb) をご参照ください。
ブログ投稿者について
 Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野としては、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野としては、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
 Amir Sadoughi は、AWS AI SageMaker Algorithms チームのシニアソフトウェア開発エンジニアです。分散システムと機械学習の共通点に関するテクノロジーに情熱を注いでいます。
Amir Sadoughi は、AWS AI SageMaker Algorithms チームのシニアソフトウェア開発エンジニアです。分散システムと機械学習の共通点に関するテクノロジーに情熱を注いでいます。