Amazon Web Services ブログ
Auto Scaling が Amazon SageMaker で使用できます
AWS ML プラットフォームチーム担当製品マネージャーである Kumar Venkateswar は、Amazon SageMaker でオートスケールの発表の詳細を共有します。
Amazon SageMaker により、何千もの顧客が容易に Machine Learning (ML) モデルを構築、訓練、およびデプロイすることができました。当社は Amazon SageMaker のオートスケール対応により、本番稼働の ML モデルの管理をさらに容易にしました。インスタンスの必要があるスケールと照合するために数多くのインスタンスを手動で管理する代わりに、SageMaker に AWS Auto Scaling ポリシーに基づいてインスタンスの数を自動的にスケールさせることができます。
SageMaker は多くの顧客のために ML プロセスの管理を容易にしました。顧客がマネージド型 Jupyter ノートブックとマネージド型配布トレーニングを利用するのを見てきました。SageMaker は、マシン学習をアプリケーションに統合するため、顧客が推論のために SageMaker ホスティングにモデルをデプロイしたのを見てきました。SageMaker はこのことを容易にします。推論ホスト上でオペレーティングシステム (OS) または枠組みをパッチすることについて考える必要はなく、アベイラビリティーゾーン全体で推論ホストを設定する必要はありません。SageMaker にモデルをデプロイするだけで、残りの部分は処理されます。
今まで、エンドポイント (または本番バリアント) ごとのインスタンスの数とタイプを指定して、推論に必要なスケールを求める必要がありました。推論の容量が変更された場合、その変更に対応するために、ダウンタイムの発生なしに、各エンドポイントに対応するインスタンスの数またはタイプ、もしくはその両方を変更できます。プロビジョニングの変更が容易であることに加えて、顧客は SageMaker の管理機能をさらに容易にするために私たちが行っている方法を尋ねてきました。
Amazon SageMaker の Auto Scaling を使用して、SageMaker コンソールで、AWS Auto Scaling API と AWS SDK では、さらに容易になります。現在、推論容量を詳しくモニタリングし、対応するエンドポイントの設定を変更することが必要な代わりに、顧客は AWS Auto Scaling を使用してスケーリングポリシーを設定できます。Auto Scaling はインスタンスの数を、Amazon CloudWatch メトリックとポリシーにより定義されるターゲット値を使用して、実際のワークロードに対応して上下させて調整します。このように、顧客は低コストで予測可能なパフォーマンスを維持するために、推論の容量を自動的に調整できます。インスタンスごとのターゲット推論スループットを指定し、各実動バリアントのインスタンス数の上限と下限を指定するだけです。SageMaker により、Amazon CloudWatch アラームを使用してインスタンスごとのスループットをモニタリングし、必要に応じてプロビジョニングされたキャパシティーを調整します。
Auto Scaling でエンドポイントを設定した後で、SageMaker は配置されたモデルを引き続きモニタリングして、インスタンス数を自動的に調整します。SageMaker はアプリケーショントラフィックで変更することに対応して、スループットを希望のレベル内に維持します。このことにより、本番稼働中のモデルの管理が容易になり、ピーク時の負荷を管理するために十分な容量をプロビジョニングする必要がなくなり、モデルの導入コストを削減できます。代わりに、最小限の予想トラフィックと最大ピーク字に対応するように制限を設定すると、Amazon SageMaker はこれらの制限内でコストを最小限に抑えることができます。
開始する方法はSageMaker コンソールを開きます。既存のエンドポイントについて、まずエンドポイントにアクセスして、設定を修正します。
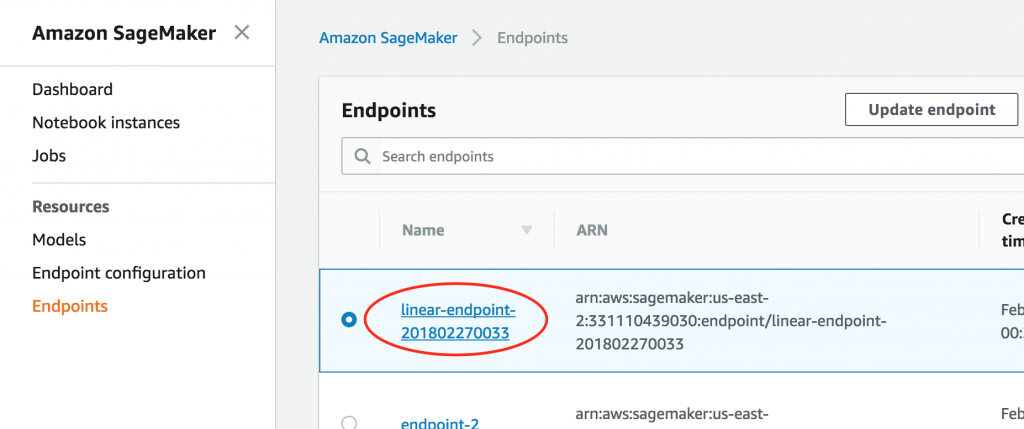
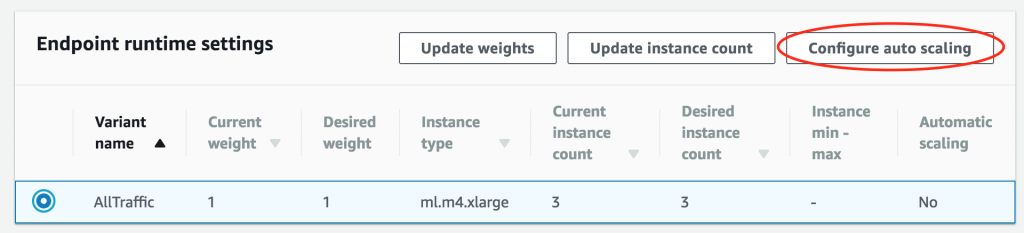
次に、[Endpoint runtime settings (エンドポイントランタイム設定)] セクションまでスクロールし、[Configure auto scaling (Auto Scaling の設定)] を選択します。
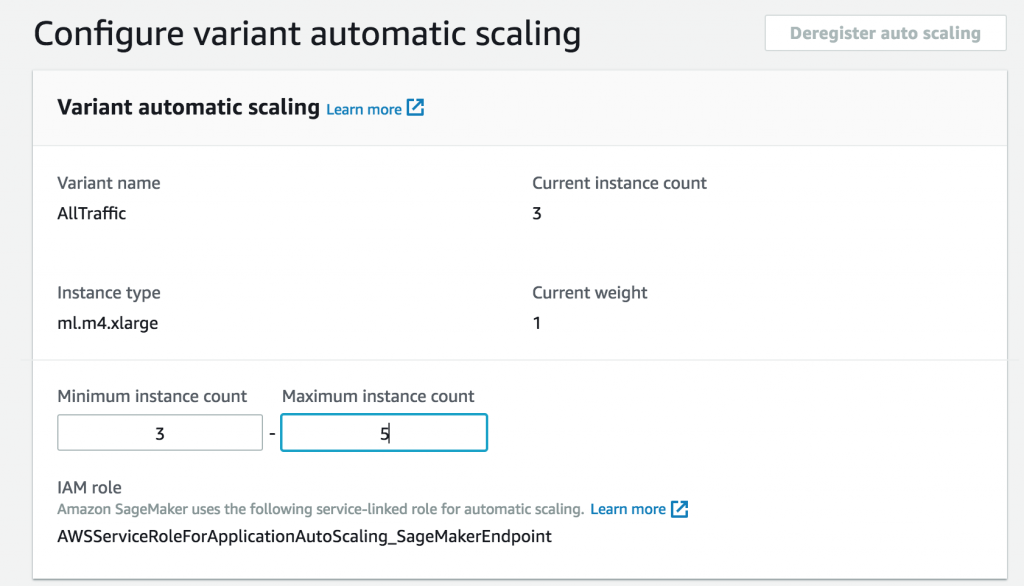
まず、インスタンスの最小と最大数を設定します。
次に、前のロードテストを指定して、さらにインスタンスを追加するインスタンスごとスループットを選択します。
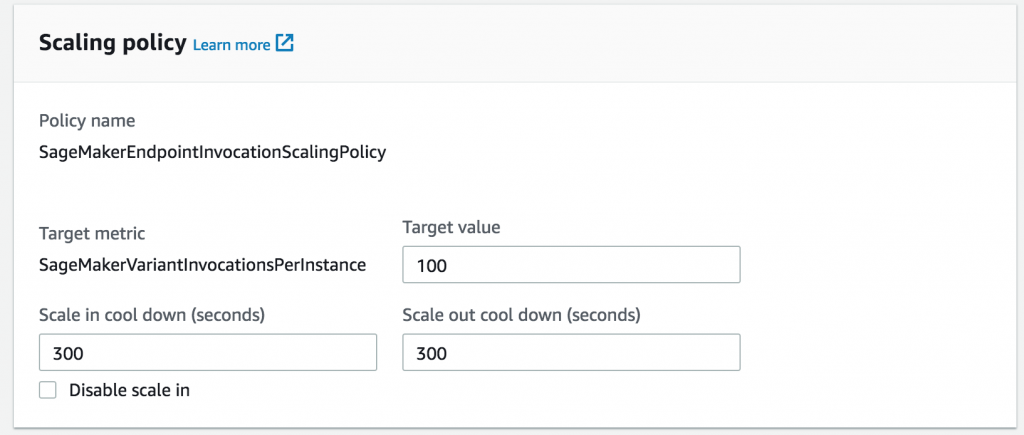
ワークロードの変動が大きい期間に振動しないように、オプションでスケーリングの開始または終了の冷却期間を設定できます。そうしないと、SageMaker はデフォルト値を想定します。
それで完了です。これで、推量が大きくなると、自動的にスケールするエンドポイントが設定されます。
通常の SageMaker の従量制の価格で使用した容量について支払うため、相対的な待期期間中の未使用の容量に対して支払う必要がなくなります。
本日、Amazon SageMaker の Auto Scaling は米国東部 (バージニア北部およびオハイオ)、欧州 (アイルランド)、米国西部 (オレゴン) の各 AWS リージョンで利用可能です。詳細については、Amazon SageMaker Auto Scaling ドキュメント を参照してください。

Kumar Venkateswar は AWS ML プラットフォームチームの製品マネージャーです。AWS ML プラットフォームは Amazon SageMaker、Amazon Machine Learning、AWS 深層学習 AMI から構成されます。趣味はバイオリンとマジック:ザ・ギャザリングです。