Amazon Web Services ブログ
Amazon SageMaker に独自のハイパーパラメータ最適化アルゴリズムを持ち込む
このブログ記事では、Amazon SageMaker でモデルをチューニングするためのカスタムの最先端のハイパーパラメータ最適化 (HPO) アルゴリズムを実装する方法について説明します。Amazon SageMaker には HPO アルゴリズムが組み込まれていますが、独自の HPO アルゴリズムを使用するための柔軟性があります。選択した HPO アルゴリズムを組み込むためのフレームワークを提供します。けれどもこれを実行する前に、いくつかの基本事項を確認しましょう。
フレームワークに関係なく、どのような機械学習 (ML) パイプラインでも、4 つの一般的な手順は、構築、トレーニング、チューニング (調整)、そしてデプロイです。構築段階では、データを収集し、マッサージし、そして ML トレーニングのために準備し、そしてアルゴリズムをゼロから記述するか、または一般的な ML フレームワークを使用して記述します。次に、準備されたデータをアルゴリズムで指し示し、何らかのパフォーマンス測定基準 (検証精度など) を段階的に改善することによってモデルをトレーニングします。モデルを望ましいレベルの精度にトレーニングしたら、より大きな ML アーキテクチャで使用するためにホストするか、デプロイする準備が整います。トレーニングを開始する前に、各アルゴリズムは、アルゴリズムのさまざまな側面を定義するハイパーパラメータと呼ばれる値のセットから開始します。たとえば、Amazon SageMaker の組み込みアルゴリズムとしても提供されている一般的な Xgboost (Extreme Gradient Boosted Trees の略) アルゴリズムは、モデルをトレーニングする前に以下のパラメータを設定する必要があり、そしてデータと共に、トレーニングの実行方法、およびモデルの最終的な精度を決定します。
| パラメータ名 | パラメータタイプ | 推奨範囲 |
| alpha | 連続 | MinValue: 0, MaxValue: 1000 |
| colsample_bylevel | 連続 | MinValue: 0.1, MaxValue: 1 |
| colsample_bytree | 連続 | MinValue: 0.5, MaxValue: 1 |
| eta | 連続 | MinValue: 0.1, MaxValue: 0.5 |
| gamma | 連続 | MinValue: 0, MaxValue: 5 |
| lambda | 連続 | MinValue: 0, MaxValue: 1000 |
| max_delta_step | 整数 | [0, 10] |
| max_depth | 整数 | [0, 10] |
| min_child_weight | 連続 | MinValue: 0, MaxValue: 120 |
| num_round | 整数 | [1, 4000] |
| subsample | 連続 | MinValue: 0.5, MaxValue: 1 |
この表の各パラメータは、浮動値 (パラメータタイプ「連続」(Continuous)) または整数値 (パラメータタイプ「整数」(Integer)) のいずれかを取り、トレーニングの前に設定できます。通常、ユーザーは経験に基づいて、または推奨範囲内の値をランダムに推測してこれらのパラメーターの値を選択します。自動化されたプロセスがあった場合に限り、これらの変数の値に最適な選択を教えてくれ、そして最高のパフォーマンスを発揮するトレーニングされたモデルを提供してくれます。ハイパーパラメータ最適化 (HPO) に進みましょう。
HPO は、トレーニングジョブを定義するパラメータの最適な選択を判断するために、さまざまなハイパーパラメータの選択を試みる一連の方法です。パラメータのこの最適な選択は、検証精度のようないくつかのメトリクスに応じて最良のモデルに対応します。機械学習に適用された HPO の優れたレビューについては、Claesen and De Moor, 2015 (https://arxiv.org/abs/1502.02127) を参照してください。HPO で使用される最も直感的な方法は、グリッド検索とランダム検索の 2 つです。「グリッド検索」では、探索する変数の下限と上限 (または範囲) を指定して、すべての変数のすべての値を調べて、パラメータ値の組み合わせごとにトレーニングジョブを実行します。浮動値の場合は、解像度 (0.5 など) も選択します。これにより、その浮動パラメータの次元内で評価する点の数が決まります。前述のようにチューニングする 11 のパラメータを持つ HPO の問題は、検証精度を最大化することを目的とした 11 次元の最適化問題です。想像できるように、グリッド検索は、特に探索するのに浮動パラメータと整数パラメータの選択の組み合わせがいくつかある場合には非常に高価になります。一方、「ランダム検索」では、パラメータ値の許容範囲内でこれらのパラメータのランダムな値を選択し、トレーニングジョブを実行します。トレーニングジョブの最大数を予算として考えた場合、複数のランダムな組み合わせを探索し、最高のパフォーマンスがあるトレーニングジョブを選択することができます。ランダム検索とグリッド検索はどちらもこの問題の設計スペースをうまく探索しますが、効率的ではありません。また、目的関数の値 (この例では検証精度) を継続的に向上させることはありません。幸いなことに、何十年もの最適化研究が助けてくれます。
最適化問題は、目的関数 f の値を最適化 (つまり最小化または最大化) する設計変数 x の値を見つけることと捉えることができます。この目的関数の f が (x-1)^2 であると仮定します。ここでの目的は、この目的関数の最小値を x のすべての実数値について求めることです。f の最小値は 0 であり、この最小値での x の値、すなわち x * は、(1-1)^2 = 0 であることから、1 であることが容易にわかります。多くの場合、関数 f は (x-1)^2 のような閉形式表現を持たないプロセスの後に返される値です。これらの関数は、f の値を計算する手順には盲目であるため、ブラックボックス関数と呼ばれますが、この関数に x の値を「送信する」メカニズムがあり、値が「戻る」のを待ちます。HPO では、ブラックボックス関数 f は ML トレーニングジョブの最後に返されるメトリクス (精度など) の値であり、x はトレーニングジョブを定義するハイパーパラメータのセットです。
最先端の HPO アルゴリズムの概要
生物学的に触発されたアルゴリズムやカーネル法からアンサンブルモデルに至るまで、文献には多数の HPO アルゴリズムが存在します。目的関数を瞬時に評価できる標準的な最適化問題には、いくつかのアルゴリズムが適しています。たとえば、x の値を指定して (x-1)^2 の値を計算するのは簡単で、評価には 1 秒もかかりません。けれども、HPO で最適化しようとしている「関数」は、ML 全体のトレーニングジョブです。 ML のトレーニングジョブは、完了までに数分から数時間かかることがあります。この種の問題は、高価なブラックボックス最適化問題のカテゴリーに入ります。各目的関数は、トレーニングジョブ全体の完了に依存しているため、評価するのにコストがかかり、時間がかかるため、それらは「高価」です。トレーニングジョブは閉形式や代数方程式として表現できないので、それらは「ブラックボックス」です。機械学習 HPO 問題は、次の点で一般的なブラックボックス最適化問題と異なります。
- わずかに異なるハイパーパラメータ値であっても、ML トレーニングジョブはさまざまな時間がかかる可能性があります。
- ML トレーニングジョブはそれ自体最適化の問題です。
ベイズ最適化技法は、関数を最適化するのに必要な関数評価の数に関して最も効率的なアプローチのうちの一つで、いくつかの困難な最適化ベンチマーク関数に対して他の最先端の汎用的な最適化アルゴリズムよりも優れていることが示されています。ベイズ最適化、およびその他のブラックボックス最適化アルゴリズムは、目的関数の評価にコストがかかる場合、導関数にアクセスできない場合、または当面の問題が 凸 でない場合に役立ちます。
Amazon SageMaker の組み込み自動モデルチューニングアルゴリズム
Amazon SageMaker の自動モデルチューニングでは、ベイズ最適化と呼ばれるアルゴリズムを使用して、選択したメトリクスで測定した結果、最もパフォーマンスの高いモデルになるハイパーパラメータ値を選択します (参考: https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-how-it-works.html)。
ベイズ最適化に関する詳細な説明については、Brochu 他が行っています (参考: https://arxiv.org/abs/1012.2599)。次のトレーニングジョブに最適なハイパーパラメータを選択するときに、Amazon SageMaker の HPO は、これまでにこの問題について知っていることすべてを考慮しています。これは、これまでに見つかった最良の結果をさらに改善する可能性が最も高いハイパーパラメータの値を選択します。これにより、ハイパーパラメータチューニングで設計スペースを探索したり、設計スペースのより良い領域に焦点を当てたり (または「利用」したり)することができます。それ以外の場合は、試していたものから遠く離れたハイパーパラメータのセットを選択します。これにより、よく理解されていない新しい分野を見つけることを試みるためにスペースを探索することを可能にします。ベイズ最適化は、カテゴリカル入力または条件付き入力を含む検索スペース、または複数のカテゴリカル入力を含む組み合わせ検索スペースにも適用でき、効率的に解くことができるため、HPO に最適です。この場合の目的関数の評価は、ハイパーパラメータのセット x を使用してトレーニングジョブを実行し、トレーニングジョブからの精度の値 (またはその他のメトリクス) を記録することを意味します。ベイズ最適化は目的関数 f の理解を更新するために x の連続する値を試します。ベイズ最適化では、これは確率的代理モデルと呼ばれます。
下の図は Shahriari などから引用したもので (https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7352306) 、「n=2」サブプロットの 2 つの初期観測値 (黒い点) を示しています。ここで、「n」は実際の関数評価の総数を示します。黒い点は、目的を直接評価することによって (この場合はトレーニングジョブを実行し、f の値を測定することによって) 目的メトリクスの実際の測定値を表します。青い点線の領域は、実際の測定点 (黒い点) 間の不確定領域を示しています。これは、これらの点で f を実際に評価していないためです。ベイズ最適化は、取得関数 (詳細については、先に引用した論文を参照) を使用して、次の実験を実施する場所、つまり次の関数評価を実行する場所を決定します。この新しい点は、下の図では赤い点として表示されています。新しい点を追加した後に、確率的代理モデル (青色) の形状がどのように変化したかに注目してください。このプロセスは、実際の目的関数の最小値に達し、最適値が見つかるまで続きます。
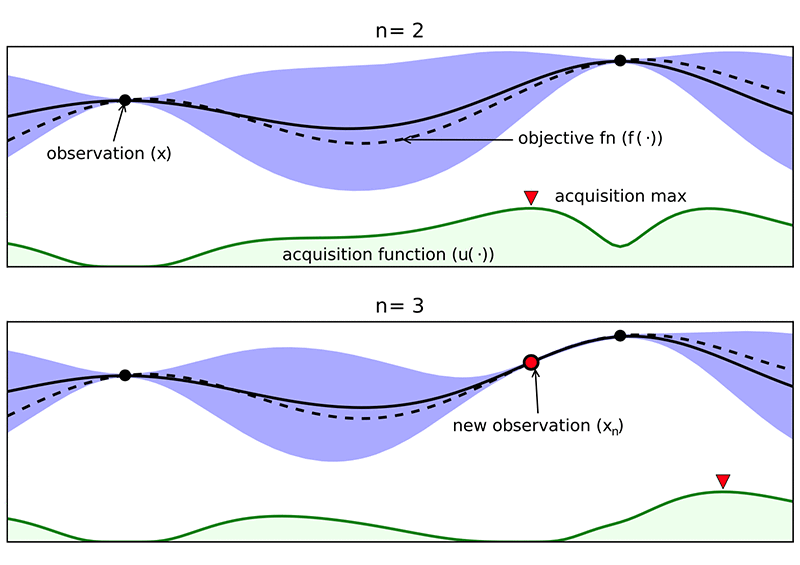
探索/利用のトレードオフは、多くの最適化アプローチ、特にブラックボックス最適化とグラジエントフリー最適化に優れた「進化的最適化」アルゴリズムと呼ばれる最適化アルゴリズムのクラスでよく見られます。
ではなぜ進化的最適化手法 (またはその他のベイズ最適化以外の最適化手法) を使用するのでしょうか?
進化的最適化は、さまざまな大規模なブラックボックスおよびグラジエントフリーのアプリケーション問題で使用されてきました。ベイズ最適化は、ユーザーが最適モデルを見つけるのに役立つ方法の 1 つですが、最適化プロセスで使用できる方法は他にもたくさんあります。進化的最適化手法は、適者生存のように、自然界で発生するプロセスに触発されているため、通常、高度に並列化可能で直感的です。毎年他の何百もの最適化アルゴリズムが査読誌に掲載されており、標準的なベンチマークアルゴリズムに対して厳格なテストを経ており、それらが既存の最先端のアルゴリズムよりも優れている場合にのみ公開されます。最適化コミュニティでのこのように研究スピードが速いことを考えると、HPO の観点から新しいアルゴリズムを試すための柔軟性を提供することが重要です。
前述したように、このブログの主な目的は、選択した HPO アルゴリズムを組み込むことができるようにするためのフレームワークを提供することです。例として、Amazon SageMaker の組み込み HPO アルゴリズム、ランダム検索やいくつかの一般的な進化的最適化アルゴリズムを使用します。
進化的最適化アプローチ
その名前が示すように、進化的最適化 (Evolutionary Optimization) は自然の進化の過程に触発されたアプローチです。自然淘汰による進化論は次のようにまとめることができます。
- 個人の連続世代は、前の世代とは異なる場合がある。子供は両親の特性を受け継ぐ。しかし、これらの特性を組み合わせて変更すると、世代ごとにばらつきが生じます。
- 人口の中の個人はしばしば彼らの DNA を表している。実際には、この個人の「DNA」(ここでは 1 回のトレーニングジョブ) をビット列としてエンコードし、必要に応じて再度デコードする必要があります。
- あまり適さない個人 (ここでは、トレーニングジョブ) は選択的に排除されます (「適者生存」)。
アルゴリズム自体は、連続した世代の人々が全体的に前のものよりもパフォーマンスが確実に良くなるようにします。このブログ記事の残りの部分では、MNIST データセットを例として使用して、さまざまなカスタム HPO 戦略について検討します。
問題の説明 (MNIST 画像分類)
修正国立標準技術研究所 (MNIST) データセットは 0 から 9 までの手書き数字の画像を含み、一般的な ML 問題です (https://en.wikipedia.org/wiki/MNIST_database)。MNIST データセットには、60000 のトレーニング画像と 10000 のテスト画像が含まれています。これらの画像のいくつかを以下に示します。
この例では、Amazon SageMaker に始めから用意されている例に従います (こちらで見つけることができます: https://github.com/awslabs/amazon-sagemaker-examples/tree/master/hyperparameter_tuning/mxnet_mnist)。
このノートブックでは、Amazon S3 でデータを設定し、Amazon SageMaker が提供する組み込み HPO アルゴリズムを使用する方法について説明します。各トレーニングジョブは、多層ニューラルネットワークを定義するカスタム MXNet スクリプトを使用します。トレーニングスクリプトは、HPO ジョブが各トレーニングジョブに対して定義したハイパーパラメータ値を使用します。
自分の HPO を持ち込む
このチュートリアルのノートブックと Python ファイルはここからダウンロードできます。
BYO HPO を希望する理由はいくつかあります。
- 「No Free Lunch Theorem (ノーフリーランチ定理)」(Wolpert and Macready, 1997) では、どのような検索/最適化アルゴリズムについても、あるクラスの問題に対する高いパフォーマンスは、他のクラスに対するパフォーマンスに代わって支払われると述べています。言い換えれば、「最善の」HPO アルゴリズムはなく、各アルゴリズムには当面の問題をよりよく解決するのに役立つ特定の特性があります。たとえば、ランダム検索は高度に並列化可能であり、パフォーマンスの点でいくつかの問題について他のアルゴリズムよりも優れたパフォーマンスを発揮する可能性があります。
- 最先端の ML と最適化は、非常に急速に動いている研究コミュニティです。今までに解決したことのない問題、特に極端にノイズの多い関数空間と 1 億もの設計変数を持つもののように解決するのが非常に難しい問題を解決するために、国際的に互いに競い合っているアルゴリズムがあります。そのようなさまざまな競争の詳細については、IEEE の進化論的計算に関する会議 (CEC) を参照してください (https://ieeexplore.ieee.org/document/7744241)。それと比べると、このブログの例でチューニングするものは 2 変数しかありません。
- 自社製または自家製のアルゴリズム – テストしたい独自の HPO アルゴリズムがあるかもしれません。
ランダム検索
まず、HPO 戦略としてランダム検索について詳しく見てみましょう。参考として、次の最近公開されたブログ記事を使用し、問題に合わせていくつか変更を加えます。 https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-automatic-model-tuning-produces-better-models-faster/
すべてのトレーニング用ノートブックと同様に、ここで提供されている例は、Amazon SageMaker ロールを取得することから始まります。次に、トレーニングとテストのデータを Amazon S3 にアップロードします。
Amazon SageMaker で単一の MXNet ジョブをトレーニングするのと同じように、MXNet スクリプト、IAM ロール、 (ジョブごとの) ハードウェア設定、および調整していないハイパーパラメータを渡して MXNet 推定子を定義します。
「mnist.py」は、S3 からデータをロードし、MXNet を使用してモデルニューラルネットワークを構築し、モデルをトレーニングする関数を定義するスクリプトです。このランダム検索セクションと以下の進化的アルゴリズムセクションに関する推定子は、メトリクス (検証精度) を使用して評価する「母集団」内の「個人」です。これらの個人の世代は連続的に改善され、最終的には最適なトレーニングジョブ定義にたどりつきます。各トレーニングジョブは、次の所定のハイパーパラメータ範囲内に入るハイパーパラメータのセットによって定義されます。
静的ハイパーパラメータ (バッチサイズ= 100) に加えて、チューニングしたい他の 2 つのハイパーパラメータ (0.01 から 0.2 までの間の任意の浮動値である学習率 (“ learning_rate”)、および 10 から 50 までの整数値であるエポック数 (“ num_epoch”)) があります。実際には、このリストの長さははるかに長くなりますが、この例では簡単にするためにこれら 3 つのパラメータを使用します。
ランダム検索機能を構築して、以下のような、SM の 組み込み HPO チューナー機能に似たものにします。
random_tuner.py ファイルを再利用し、 https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-automatic-model-tuning-produces-better-models-faster/ で使用されている関数を含めました
ファイル内のいくつかの重要なクラスと関数について、以下簡単に説明します。
- StaticParameter、ContinuousParamater、IntegerParameter、および CategoricalParameter の各クラスは、これらのクラスに属するハイパーパラメータを、指定されたハイパーパラメータ範囲の適切な値で初期化します。これらのクラスには get_value () というメソッドがあり、その特定のハイパーパラメータの乱数値を返しますが、それでもそのハイパーパラメータの許容範囲 (下限と上限) を順守します。
- _get_random_hyperparameter_values () はこれらのクラスを使用して、各トレーニングジョブのハイパーパラメータセットを生成します。
- random_search () は、「世代」ごとにいくつかの (「max_parallel_jobs」) ジョブを並行して実行します。
この生成パラメータは、ランダムチューナーのこの実装が前述のブログ投稿とは異なる点です。これは、他の進化的最適化アルゴリズムのパラメータ生成の意味について、シームレスに説明し続けることができるようにするためです。各セットが 3 つのジョブを並行して実行しながら、10 セットのジョブを実行するとします。各セットは世代であり、各トレーニングジョブはその世代の人口メンバー (個人) です。
max_parallel_jobs 個のトレーニングジョブをデプロイした後、これらのジョブが完了するのを待って (boto3 Amazon SageMaker の describe_training_job 関数を使用して)、次の世代に進みます。連続した世代の間には関係がないことに注意してください。つまり、ハイパーパラメータは完全にランダムに設定されているため、次世代の個人は向上しない可能性があるということです。これが進化的アルゴリズムと比較したときの主な違いです。
すべてのジョブが完了したら、ヘルパー関数 table_metrics () を使用します。内部的に、CloudWatch Logs は各ジョブの最終的な検証の正確性を見つけるために解析され、それから以下のソートされた表形式で提示されます。
これは SageMaker Search を使って行うこともできます。詳しくは、 https://docs.aws.amazon.com/sagemaker/latest/dg/API_Search.html を参照してください。
ランダム検索を使用したいくつかの実行のうち、利用可能な最善の実行では、次のような出力が得られました。
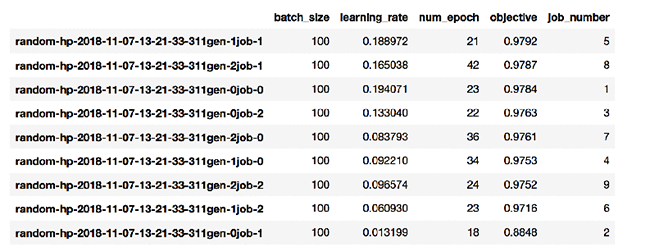
ご覧のとおり、ジョブ番号 5 (最も左側の行のジョブ名のうち、世代番号 1、ジョブ番号 1 に対応します) の検証精度が最高の 0.9792 です。より多くのジョブが実行されるにつれて、全体的なソリューションが向上するという保証はありません。
進化的検索 – 遺伝的アルゴリズム
遺伝的アルゴリズムは、その使いやすさから進化論的検索の世界では非常に一般的な選択ですが、それは最先端というわけではありません (ただし、ノーフリーランチ定理を忘れないでください)。次のブログ記事には遺伝的アルゴリズムの基本がわかりやすく紹介されています – https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3。一般的な遺伝的 (およびその他の進化論的) アルゴリズム用の簡略化された擬似コードは次のとおりです。
- 初期母集団を生成します (複数のハイパーパラメータセット。各ハイパーパラメータセットは母集団内の単一の個人を表します)
- 初期母集団を評価します (トレーニングジョブを実行し、各ジョブの検証精度などの目的関数を取得する)
- 母集団内の 2 人の「親」 (任意の 2 人の個々のメンバー) をランダムに選択してから、親の組み合わせを使用して 2 人の新しい「子」を生成します
- 遺伝的アルゴリズムでは、各母集団メンバーは元のハイパーパラメータを代表する染色体を持っています。2 変数の例では、検証精度を最大にするために最適化したいパラメータは num_epochs と learning_rate です。これらを 3 ビットのバイナリ表現で「エンコード」しましょう。 num_epochs = 5 は、3 ビットバイナリの「101」に対応します。浮動値の場合は、連続パラメータの範囲を離散化します。したがって、0.01 の学習率は 3 ビットバイナリの「 011 」に対応します。したがって、この個体を表す「染色体」は、これら 2 つのバイナリ「遺伝子」 – 「101 011」を連結することによって得られます。親として選択された場合、この個体はその遺伝子を別の親と組み合わせ (「交差」と呼ばれます)、新しい個体を作ります。ビットが破損しても多様性が生じる可能性があります。これは「突然変異」と呼ばれます。
- 微分進化などの他のアルゴリズムは、浮動値と整数値を直接使用して、交差と突然変異を実行します。
- 新しく生成された子供と一緒に新しい世代を評価します (この場合、各母集団メンバーに対応するすべてのトレーニングジョブを実行し、最終的な検証精度を測定します)。
- 最大世代数に達するまで、または他の何らかの停止条件が発生するまで (たとえば、目的関数が十分に改善されなかった)、手順 3 と 4 を繰り返します。
CPLEX、GUROBI、IPOPT、SciPy、SNOPT、Pyomo など、最適化アルゴリズムのいくつかの一般的な実装が実用化されています。ここでは、「inspyred」と呼ばれる Python パッケージを使用します (https://pythonhosted.org/inspyred/)。
以下のコマンドを使用してノートブックセルまたは端末にパッケージをインストールします。
ノートブックの例では、最初に toy 関数を使用した最適化に関する手引を提供します。ランダム検索の場合と同様に、まず提供された evolutionary_tuner.py ファイルからクラスと関数をインポートします。
このファイルには、さまざまなタイプのハイパーパラメータ、つまり静的、連続、整数、カテゴリカルパラメータタイプを定義する random_tuner.py ファイルに似たクラスが含まれています。通常、進化的最適化アルゴリズムでは、カテゴリカル変数を整数値にマッピングします。この例では、ハイパーパラメータのタイプに基づいて次のようにハイパーパラメータを設定します。
次に、ステートメントを使用してチューニングジョブを開始します。
最後に、table_metrics を呼び出して、すべてのジョブの結果を表にすることができます。
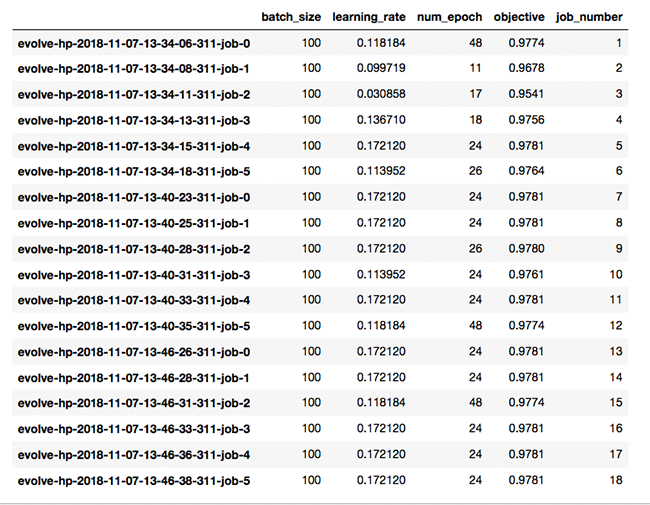
各世代が進むにつれて、結果が全般的に向上することが保証されているので、結果をソートする必要がないことに注意してください。それでは、実際に進化的最適化を実行する関数について詳しく見てみましょう。まず、inspyred で利用できる GA オプティマイザーを初期化します。
次に、generate_population と evaluate_population の 2 つの関数を作成します。generate_population 関数は、入力として提供されたハイパーパラメーター範囲を順守しながら、新しい世代の個人を生成します。evaluate_population 関数は、1 世代のトレーニングジョブ全体を実行し、完了を待ちます。すべてのジョブが完了すると、Amazon CloudWatch からトレーニングジョブメトリクスを取得し、適応値 (または目標値、ここでは検証精度) のリストをオプティマイザーに返します。
現在の世代のすべての候補者のハイパーパラメータの値、および各ジョブの対応する適応値に基づいて、新しい世代の子供たちが新しいトレーニングジョブのセットの新世代に生成されます。これと比較して、ベイズ最適化の構築は 49 エポックとわずかに異なる学習率の後に 0.9789 の最良の検証精度に達しました。
進化的検索 – 粒子群最適化
このフレームワークを使って他のオプティマイザーを試すのはとても簡単です。変更しなければならないのは、inspyred から特定のアルゴリズムを取得するコンストラクターだけです。粒子群最適化を用いるには、次を使用します。
各アルゴリズムには、設定が必要な場合がある追加のパラメータがある可能性があります。たとえば、ここでは neighborhood_size=5 と設定します。
次に、遺伝的アルゴリズムの場合と同じ引数で et.evolutionary_search(…) を呼び出します。得られた結果は以下の通りであり、達成された最も高い検証精度は 0.9795 でした。
進化的検索 – パレートアーカイブ進化戦略 (PAES)
PSO と同様に、最初に以下を使用して PAES オブジェクトを取得します。
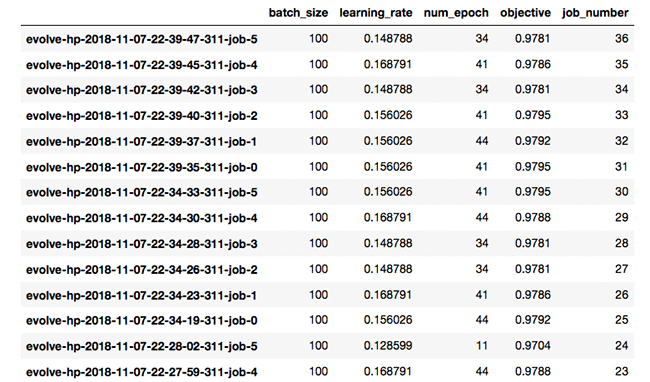
PSO では、0.9795 というわずかに高い検証精度が得られます。
PAES を実行するためにコンストラクターに必要な変更は次のとおりです。
次のアルゴリズム固有のパラメーターも設定します。
PAES を使用した HPO の結果は、次の抜粋にまとめられています。
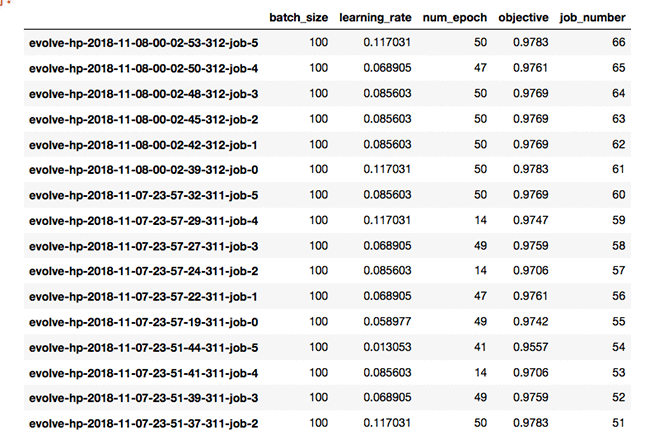
最終的な検証精度は 0.9783 でした。
このブログでは、HPO の基本と SageMaker の実装について概説し、SageMaker の柔軟性を利用して、独自の HPO アルゴリズムを実装してモデルを調整しました。このブログでは inspyred パッケージからいくつかのアルゴリズムを使用しましたが、inspyred 内で使用できる他のアルゴリズムには、進化戦略、シミュレーテッドアニーリング、微分進化、分布推定、非優勢ソーティングの遺伝的アルゴリズム、および蟻コロニー最適化があります。また、Python ライブラリに基づいた進化しないアルゴリズムについては、pyomo と、scipy の最適化ツールをで調べてみてください。
最後に、眠れなくなるトピックが必要な場合は、次の点を考えてみてください。最適なトレーニングジョブ (それ自体が最適化実行) を最適化する複数のオプティマイザーにちて詳しく見てきて、HPO アルゴリズム自体に最適なパラメータを選択する別のオプティマイザーが必要でしょうか?
著者について
 Shreyas Subramanian は AI/ML スペシャリストのソリューションアーキテクトであり、機械学習を使用して AWS プラットフォームでビジネス上の課題を解決することでお客様を支援しています。
Shreyas Subramanian は AI/ML スペシャリストのソリューションアーキテクトであり、機械学習を使用して AWS プラットフォームでビジネス上の課題を解決することでお客様を支援しています。