Amazon Web Services ブログ
Amazon EMR での Spark にバックアップされた Amazon SageMaker ノートブックの構築
2017年の AWS re:Invent で発表された Amazon SageMaker は、データサイエンスと機械学習ワークフローのためのフルマネージド型サービスを提供します。Amazon SageMaker の重要な部分のひとつは、モデルの構築に使用できる強力な Jupyter ノートブックインターフェイスです。Amazon SageMaker 機能は、ノートブックインスタンスを Amazon EMR で実行されている Apache Spark クラスターに接続することによって強化することができます。Amazon EMR は、大量のデータを処理するためのマネージドフレームワークです。この組み合わせにより、大量のデータに基づいてモデルを構築することが可能になります。
Spark はビッグデータの迅速な処理を可能にするオープンソースのクラスターコンピューティングフレームワークで、機械学習ワークロードのための MLlib が含まれています。Amazon SageMaker ノートブックと Spark EMR クラスターとの接続を容易にするには、Livy の使用が必要になります。Livy は、Spark クライアントを必要とすることなく、どこからでも Spark クラスタとやり取りするためのオープンソース REST インターフェイスです。
このブログ記事では、Spark EMR クラスターをスピンアップする、Amazon SageMaker と EMR 間のコミュニケーションを許可にするために必要なセキュリティグループを設定する、Amazon SageMaker ノートブックを開く、そして最後に Livy を使用してそのノートブックを EMR 上の Spark に接続する方法を説明します。このセットアップは、PySpark、PySpark3、Spark、および SparkR ノートブックで利用できます。
EMR Spark と Livy をセットアップする
AWS マネジメントコンソールを開いて、画面上部の [サービス] メニューから分析セクション下の EMR を選択します。[クラスターの作成] を選択します。[詳細オプションに移動する] (上部にある「クラスターの作成 – クイックオプション」の横) に進み、すべてのチェックを外します。次に、Livy と Spark だけにチェックを入れます。[次へ] を選択します。
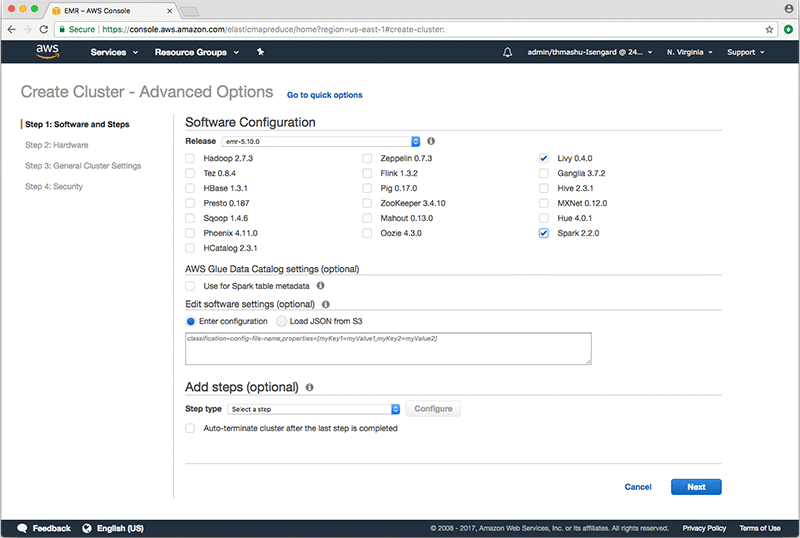
[ネットワーク] でお使いの VPC を選択します。このブログ記事の例にあるネットワークは sagemaker-spark という名前です。後で必要になるため、EC2 サブネットをメモしておくようにしてください。

[次へ] を選択してから、[クラスターを作成] を選択します。希望に応じて、ノードへのリモートアクセスのためのキーペアの追加、またはクラスターのカスタム名など、適切だと思われるその他のオプションをクラスターに含めてください。
ここで、Spark クラスターのマスターノードのプライベート IP アドレスを取得する必要があります。
[サービス] を選択してから [EMR] を選択します。お使いのクラスターに開始中 (緑色) と表示されるまで待ってから、作成したクラスターを選択します。[ハードウェア] タブを選択します。

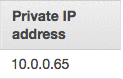
マスターの ID を選択し、右にスクロールしてプライベート IP アドレスを見つけます。後で使用するために、この ID を保存しておきます。このブログ記事の例の ID は 10.0.0.65 になっていますが、実際の ID はこれとは異なります。
セキュリティグループをセットアップしてポートを開く
次に、Amazon SageMaker ノートブックがポート 8998 の Livy を通じて Spark クラスターと通信できるようにセキュリティグループをセットアップして関連するポートを開く必要があります。
コンソールで [サービス]、[EC2] と選択します。左側のナビゲーションペインで、[セキュリティグループ] を選択します。[セキュリティグループの作成] ボタンを選択します。
セキュリティグループ名 (この例でのグループ名は sagemaker-notebook) 、説明、および EMR クラスター (この例でのクラスターは sagemaker-spark) に使用した VPC を設定します。
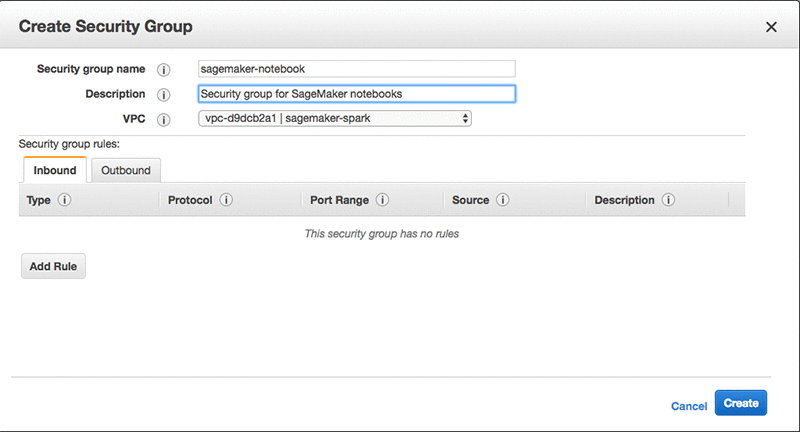
[作成] を選択します。
これによってセキュリティグループが作成され、このグループ内のインスタンスのみにポートを開くことが可能になります。この後、ElasticMapReduce-master グループでもポートを開かなければなりません。
セキュリティグループが開かれている間に、SageMaker ノートブックセキュリティグループのグループ ID を取得しておきます。この例では sg-35610640 となっていますが、実際の ID はこれとは異なります。後ほど使用するために、この値を保存しておきます。

EMR クラスターを作成したときに自動的に作成された EMR マスターセキュリティグループを変更する必要があります。ElasticMapReduce-master グループを選択してから、[インバウンド] タブを選択します。[編集] ボタンを選択し、次に [ルールの追加] ボタンを選択します。
カスタム TCP ルールを作成します。ポートは 8998、セキュリティグループ ID は先ほど保存した SageMaker ノートブックセキュリティグループからのグループ ID に設定します。この例で保存した ID は sg-35610640 でした。以下は、入力完了時のフィールドの表示例です。

[保存] ボタンを選択します。これで重要なポートが開かれたため、SageMaker ノートブックインスタンスが Livy 経由で EMR クラスターと対話することができるようになりました。
SageMaker ノートブックをセットアップする
Livy を使って実行される EMR Spark クラスターが作成され、関連ポートが使用できるようになりました。それでは、Amazon SageMaker ノートブックインスタンスを稼働させましょう。
[サービス] を選択してから、Amazon SageMaker を選択します。[ノートブックインスタンスの作成] ボタンを選択します。
ノートブックインスタンス名を設定して、ノートブックインスタンスのタイプを選択する必要があります。ノートブックインスタンス名にはいくつかの命名制約があることに注意してください (英数字最大 63 文字、ハイフンは使用可能でスペースは使用不可、AWS リージョンでお使いのアカウント内で固有である必要あり)。また、IAM ロールを AmazonSageMakerFullAccess でセットアップし、必要な Amazon Simple Storage Service (Amazon S3) バケットへのアクセスもセットアップしなければなりません。ロールがアクセスできるバケットを指定する必要がありますが、Amazon SageMaker にロールを生成させることもできます。
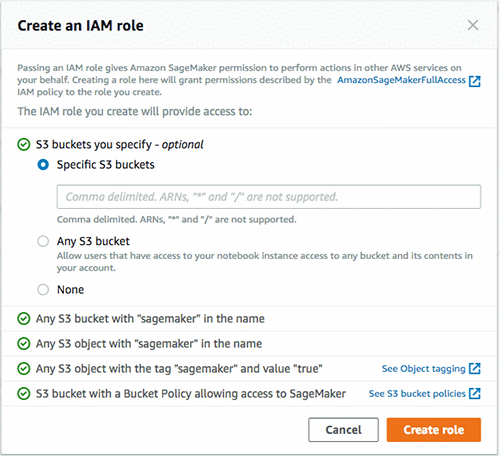
次に、ノートブックインスタンスを EMR クラスターと同じ VPC (この例では sagemaker-spark でした) にセットアップしたことを確認しなければなりません。また、EMR クラスターと同じサブネット (EMR クラスター作成時にメモしているはずです) も選択してください。最後に、先ほどノートブックインスタンス用に作成したグループにセキュリティグループを設定します (この例では sagemaker-notebook でした)。
[ノートブックインスタンスの作成] を選択します。
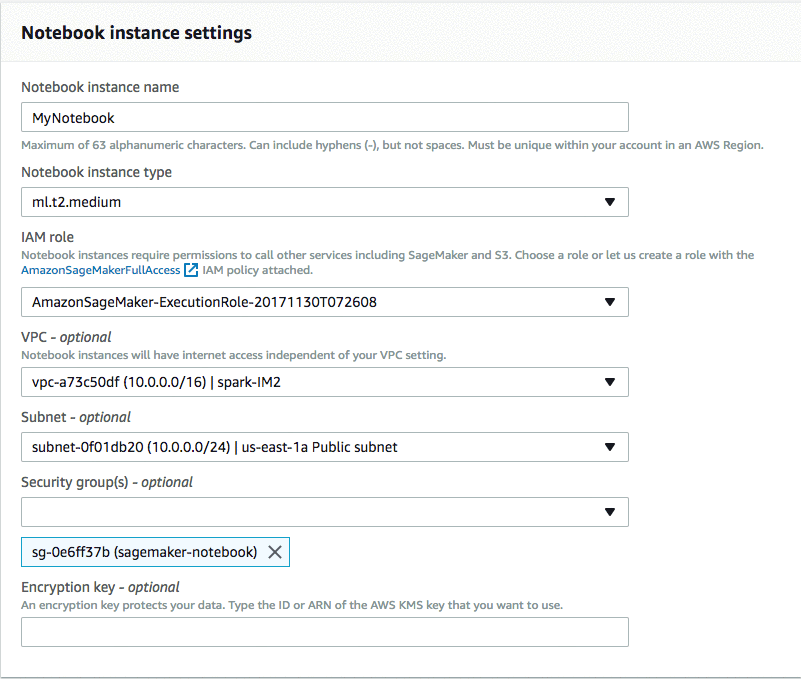
EMR がクラスターのプロビジョニングを終了し、SageMaker ノートブックステータスが InService になるまで待ちます。
ノートブックを Amazon EMR に接続する
これで EMR Spark クラスターと Amazon SageMaker ノートブックが実行されるようになりましたが、お互いに対話することはできません。次のステップは、SageMaker で Sparkmagic をセットアップし、SageMaker が EMR クラスターの見つけ方を認識するようにします。
今の Amazon SageMaker コンソールからお使いのノートブックインスタンスにアクセスし、プロビジョニングされたインスタンスで [オープン] を選択します。
Jupyter コンソールで、[New] 、[Terminal] と選択します。

以下のコマンドを入力します。
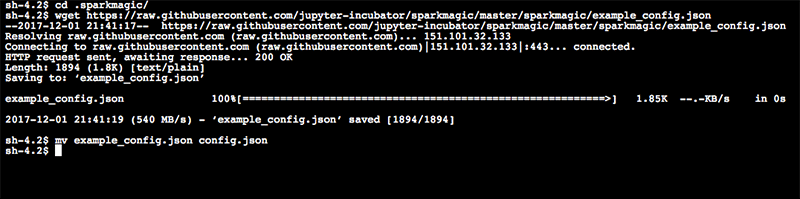
- cd .sparkmagic
- wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json
- mv example_config.json config.json
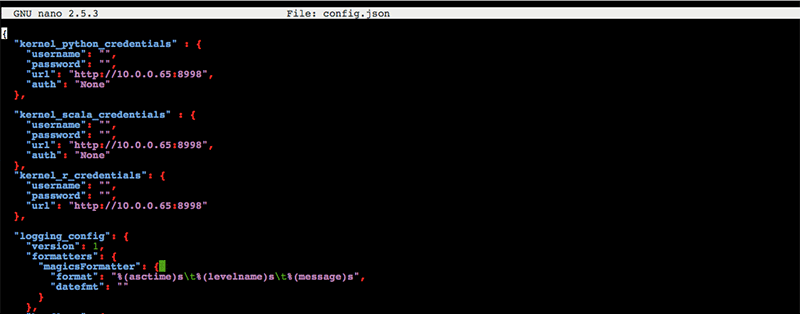
次に、config.json を編集して、すべての「localhost」インスタンスを、前に使用した EMR マスターのプライベート IP に置き換える必要があります。前に見たこの例の IP は 10.0.0.65 でしたが、実際の IP はこれとは異なります。
置き換えには以下のコマンドを使用しました。
- nano config.json
- ctrl+\
- localhost
- <お使いの EMR マスタープライベート IP>
- a
- ctrl+x
- y
- enter
これで 3 つのカーネルクレデンシャルの「url」フィールドにある localhost の 3 つのインスタンスが置き換えられたはずです。変更の保存には、使いやすいエディタを自由に使用してください。
先に進む前に、Livy 経由での EMR への接続をテストするようにしてください。これは、以下のコマンドを実行して行うことができます (EMR マスタープライベート IP をお使いのインスタンスの IP アドレスに置き換えてください)。
- curl <EMR マスタープライベート IP>:8998/sessions
出力は次のようになります。

エラーが生じた場合は、セキュリティグループでお使いのポートが開かれていない可能性が高いため、前に戻ってこれらの設定をチェックすることをお勧めします。
ターミナルを閉じましょう。exit と入力してから、ターミナルが表示されているブラウザを閉じます。Jupyter が表示されているタブを開き、[New]、[Sparkmagic (PySpark)] と選択して PySpark ノートブックを開きます。念のために、[Kernel]、[Restart] と選択してカーネルを再起動します。
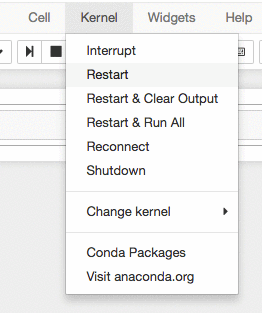
最初のセルに以下のコマンドを入力して、接続をテストしてください。
- %%info
shift と enter を同時に入力してセルを実行すると、以下のような出力が表示されます。

おめでとうございます! これで Sparkmagic カーネルが Jupyter ノートブックで実行され、Livy を使用して EMR Spark クラスターと対話するようになりました。
今回のブログの投稿者について
 Thomas Hughes は AWS プロフェッショナルサービスのデータサイエンティストです。カリフォルニア大学サンタバーバラ校で博士号を取得した Hughes は、社会科学、教育、および宣伝広告における問題に取り組んできました。Hughes は現在、機械学習がビッグデータに遭遇するときに生じる最も困難な問題の幾つかを解決すべく尽力しています。
Thomas Hughes は AWS プロフェッショナルサービスのデータサイエンティストです。カリフォルニア大学サンタバーバラ校で博士号を取得した Hughes は、社会科学、教育、および宣伝広告における問題に取り組んできました。Hughes は現在、機械学習がビッグデータに遭遇するときに生じる最も困難な問題の幾つかを解決すべく尽力しています。
 Stefano Stefani は AWS のシニアプリンシパルエンジニアで、Amazon SimpleDB、Amazon DynamoDB、Amazon Redshift、および Amazon Aurora といった複数の AWS のサービスでチーフテクノロジストとしての役割を担ってきました。Stefani は現在、Amazon AI: Amazon Lex、Amazon Rekognition、Amazon SageMaker、Amazon Transcribe、およびその他で同じ職務に携わっています。
Stefano Stefani は AWS のシニアプリンシパルエンジニアで、Amazon SimpleDB、Amazon DynamoDB、Amazon Redshift、および Amazon Aurora といった複数の AWS のサービスでチーフテクノロジストとしての役割を担ってきました。Stefani は現在、Amazon AI: Amazon Lex、Amazon Rekognition、Amazon SageMaker、Amazon Transcribe、およびその他で同じ職務に携わっています。