Amazon Web Services ブログ
Amazon SageMaker で PyTorch を使用するグローバル最適化のためのディープニューラルネットベースの代理関数の構築
最適化とは、設計変数と呼ばれる入力に依存する関数の最小値 (または最大値) を求めるプロセスです。お客様 X には次のような問題があります。このお客様は、最大の燃料効率のために設計される新しい自動車モデルをリリースしようとしています。実際の場合、エンジン、トランスミッション、サスペンションなどに関連するチューニングパラメータを示す何千ものパラメータがあり、それらの組み合わせは様々な燃料効率値を生じます。
しかし、この記事では、特定の速度で走行する場合に燃焼される 1 時間あたりの燃料量 (ガロン単位) としてこの効率性を測定し、その他すべてのパラメータは変化しないと仮定します。従って、最小化される「関数」は「1 時間ごとに燃焼される燃料量 (ガロン単位)」になり、設計変数は「速度」になります。 この一次元最適化問題は、「1 時間ごとに燃焼される燃料量を最小限化するには、どの速度で車を走行させるべきか」という問題を提起します。これは、考慮される何千もの実際のパラメータを大幅に簡素化したものです。
目的関数 (f) が以下の合成関数のようになると仮定します。
f(x) = x⋅sin(x)+x⋅cos(2x)
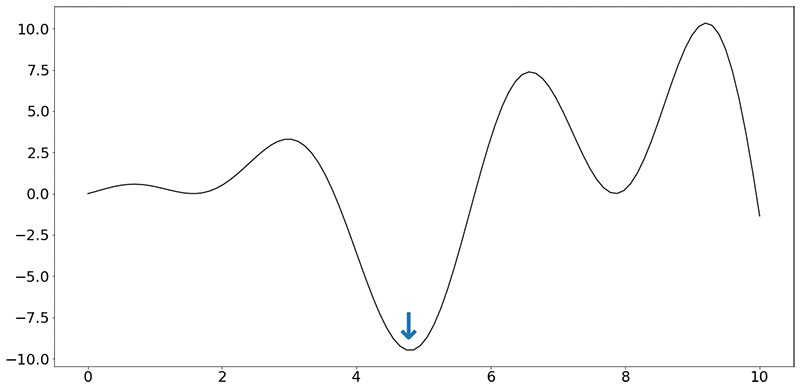
x および y 軸の単位を無視して、青矢印で示されているこの関数の最小値を探すのが今回のタスクになります。単一次元を扱っている場合でさえも、すべての速度値 (速度は実数) で車を走行させるのは非現実的です。
この記事では、実験を 30 回行う予算があるとします。各「実験」では、テスト装置上で車をその速度で走行させ、1 時間ごとに燃焼された燃料の平均値を測定し、収集します。こうすることで、速度の 30 の値に対応する燃焼された燃料の 30 の値だけが得られ、それ以外は得られません。また、最小値 (図の青矢印) で示されている速度の値で実施された実験が存在するという保証もありません。
各実験のセットアップには、実際に数時間かかる場合があります。このような実験を特定回数以上実施することは現実的ではないため、このタイプの関数は高コストなブラックボックス関数と呼ばれます。この関数が高コストなのは値を返すまでに時間がかかるためで、ブラックボックスと呼ばれるのは実施された実験を数式で記述できないからです。
最適化研究分野の全体が、これらのような問題を解決するアルゴリズムの作成を目的としています。この記事では、上記の関数 (f) を近似化するために、ニューラルネットワークを使用します。「代理モデル」としても知られる関数の訓練された近似化は、実際の実験の代わりに使用することができます! 訓練されたモデルが実際の関数の良好な近似化であるならば、任意の値の速度 (入力) に対して燃焼された燃料 (出力) を予測するためにこのモデルを使用できます。
技術的なアプローチ
これらすべてのステップを詳しく説明するサンプルの Jupyter ノートブックについては、Build a Deep Neural Global Optimizer を参照してください。
関数 (f) を設定し、様々な入力値を与えて出力の値を測定します。Scalable Bayesian Optimization Using Deep Neural Networks にある推奨事項に基づいて、シンプルな 4 層のネットワークを作成します。
- 入力層 (tanh activation)
- 隠れ層 1 (tanh activation)
- 隠れ層 2 (tanh activation)
- 出力総 (ReLU activation)
PyTorch では、これを以下のように記述することができます。
ここで、D_in、H、D、および D_out は、関数内にあるパラメータのマトリクスサイズを定義するために使用できます。
各ニューロンに活性化関数を指定し、入力がフォワードパスでどのように変換されるかを指定する必要もあります。
訓練関数では、損失関数として平均二乗誤差を使用し、ADAM 最適化法を使用します。
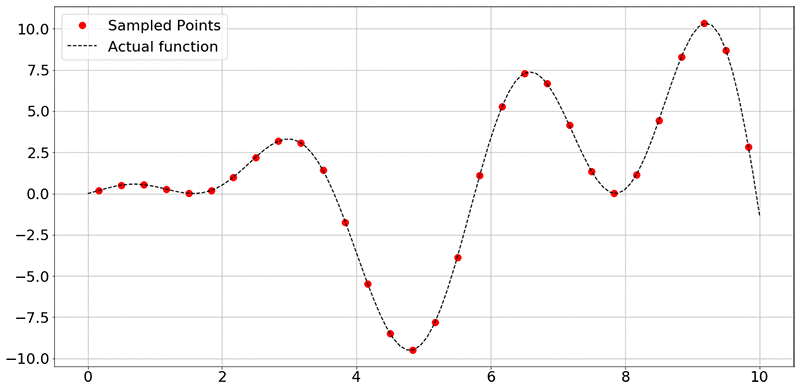
実験からのデータを収集するには、ランダムなポイントで関数 f(x) = x⋅sin(x)+x⋅cos(2x) のサンプリングを行います。以下の図では、黒い点線が x 範囲 (ここでは 0 から 10) 内における f(x) のすべての値を表し、赤い点がサンプリングされた 30 のポイントを示しています。
繰り返しますが、このネットワークの目標は、関数を近似化することを学ぶためにトレーニングデータ (サンプリングされたデータポイントに対応する x 軸と y 軸の値) を使用することです。ニューラルネットワークが元の関数 f(x) の良好な近似化を学んだとすると、高コスト、または時間のかかる実験を行うことなく、訓練されたモデルを使用して、入力を与え、出力の値を予測することができます。
技術面におけるより詳細な情報に関心がある場合は、Scalable Bayesian Optimization Using Deep Neural Networks を参照してください。簡単に説明すると、ディープニューラルネットワークの最後の隠れ層にベイズ線形回帰が追加されます。これは、観察回数と直線的にスケールする、定評のある統計的手法である適応基底回帰をもたらします。これらの「基底関数」は、ディープニューラルネットワークの重みとバイアスを使用してパラメータ化されます。最後に、「Scalable Bayesian Optimization」論文にある (4) および (5) の公式を使って予測の平均と分散を計算できます。このため、関数近似を得るだけでなく、予測されたポイントに関連付けられた不確実性も得ることになります。
サイズが小さい入力ベクターを前提として、conda36_pytorch カーネルを使ってノートブックでモデルを訓練します。適切な場合は、ローカルトレーニングではなく、Amazon SageMaker を使った分散型トレーニングを用いることを強くお勧めします。以下のコマンドがトレーニングプロセスを開始します。
PyTorch では、訓練ループが以下のように実装されます。
ネットワークが訓練されたことを示す以下の出力を取得します。
最後に、以下のようにテスト値 (xtest) 一式を使用して代理モデルを作成します。
以下の画像を取得します。
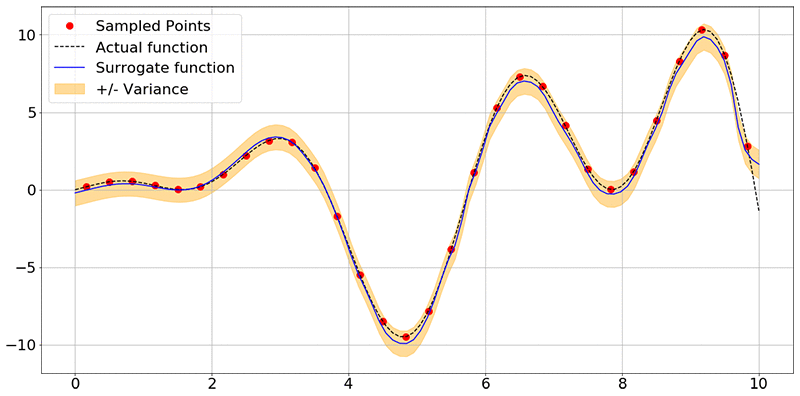
ご覧のとおり、ネットワークは関数 f(x) の形状を正確に学んでおり、ネットワークが予測に使用した各ポイントに不確実性も関連付けています。ここでは、青い線が予測平均で、オレンジ色の帯が各予測に関連付けられた不確実性です。
まとめ
この時点で、実験を実際に行うことなく、信頼区間内で任意の数の実験出力値を予測するためにこのモデルを使用できます。より有用なのは、最小 f(x) 値に対応する最適入力値を見つけるために最適化パッケージを使用することです。これを開始するには、scipy.optimize または inspyred パッケージを参照してください。
最後になりますが、これはノートブックインスタンス上でローカルに実行される Starter Example です。Amazon SageMaker コンソールを起動し、Amazon Sagemaker における分散型トレーニングを調べることによって、今すぐ始めましょう。大規模な最適化ジョブについては、Amazon SageMaker Pytorch Estimator に PyTorch スクリプトを送信することによって、Amazon SageMaker で分散型トレーニングを実行することを検討してください。
著者について
 Shreyas Subramanian は AI/ML スペシャリストソリューションアーキテクトで、AWS プラットフォームを使用してビジネス面での課題を解決するために機械学習を用いることによってお客様を支援しています。
Shreyas Subramanian は AI/ML スペシャリストソリューションアーキテクトで、AWS プラットフォームを使用してビジネス面での課題を解決するために機械学習を用いることによってお客様を支援しています。