Amazon Web Services ブログ
Cisco は、ハイブリッド機械学習ワークフローを作成するために Amazon SageMaker と Kubeflow を使用
この記事は、Cisco の AI/ML ベストプラクティスチームのメンバーによるゲスト投稿です。そのメンバーには、テクニカルプロダクトマネージャーの Elvira Dzhuraeva 氏、上級エンジニアの Debo Dutta 氏、プリンシパルエンジニアの Amit Saha 氏が含まれます。
Cisco は、多くのビジネスユニットに機械学習 (ML) と人工知能 (AI) を適用する大企業です。CTO オフィスにある Cisco AI チームは、AI と ML を使用するビジネスユニット全体の会社のオープンソース (OSS) AI/ML ベストプラクティスを担当しています。また、Kubeflow オープンソースプロジェクトと MLPerf/MLCommons の主要な貢献者でもあります。チームの使命は、Cisco のビジネスユニットとお客様の両方が使用できるアーティファクトとベストプラクティスを ML で作成することです。このソリューションはリファレンスアーキテクチャとして共有しています。
ローカライズされたデータ要件などのビジネスニーズに応えて、Cisco はハイブリッドクラウド環境を運用しています。モデルトレーニングは独自の Cisco UCS ハードウェアで行われますが、多くのチームはクラウドを活用して推論を行い、スケーラビリティ、地理的冗長性、復元力を活かしています。けれども、ハイブリッド統合では一貫した AI/ML ワークフローを構築してサポートするために深い専門知識と理解が必要になることが多いため、このような実装はお客様にとって困難な場合があります。
これに対処するために、Amazon SageMaker を使ってクラウド内のモデルにサービスを提供するハイブリッドクラウドを実装するために、Cisco Kubeflow スターターパックを使用する ML パイプラインを構築しました。このリファレンスアーキテクチャを提供することで、お客様が複雑なインフラストラクチャ全体でシームレスで一貫性のある ML ワークロードを構築して、直面する可能性のあるあらゆる制限を満たすことを支援することを目指しています。
Kubeflow は、Kubernetes 上の ML オーケストレーション用の人気のあるオープンソースライブラリです。ハイブリッドクラウド環境で運用している場合は、Cisco Kubeflow スターターパックをインストールして、オンプレミスで ML モデルを開発、構築、トレーニング、デプロイできます。スターターパックには、最新バージョンの Kubeflow とアプリケーションサンプルバンドルが含まれています。
Amazon SageMaker は、データの作成、データの処理、モデルのトレーニング、モデル実験の追跡、モデルのホスト、エンドポイントのモニタリングに役立つマネージド ML サービスです。SupMaker Components for Kubeflow Pipelines を使用すると、ハイブリッド ML プロジェクトで行った Kubeflow Pipelines からのジョブをオーケストレーションできます。このアプローチにより、オンプレミスの Kubeflow クラスターからのトレーニングと推論のために、Amazon SageMaker マネージドサービスをシームレスに使用できます。Amazon SageMaker を使用すると、ホストされたモデルに、Auto Scaling、マルチモデルエンドポイント、モデルモニタリング、高可用性、セキュリティコンプライアンスなどのエンタープライズ機能がもたらされます。
ユースケースのしくみを説明するために、Bluetooth Low Energy (BLE) Received Signal Strength Indication (RSSI) の測定値を含む、一般的に入手可能な BLE RSSI Dataset for Indoor Localization and Navigation データセットを使用してシナリオを再現します。パイプラインは、Bluetooth デバイスの場所を予測するモデルをトレーニングしてデプロイします。次の手順は、Kubernetes クラスターが Amazon SageMaker と対話してハイブリッドソリューションを実現する方法の概要を示しています。Apache MXNet で記述された ML モデルは、ローカライズされたデータ要件を満たすように Cisco UCS サーバーで実行されている Kubeflow を使用してトレーニングします。次に、Amazon SageMaker を使用して AWS にデプロイされます。
作成およびトレーニングされたモデルは、Amazon Simple Storage Service (Amazon S3) にアップロードされ、Amazon SageMaker エンドポイントを使用して提供されます。次の図は、エンドツーエンドのワークフローを示しています。
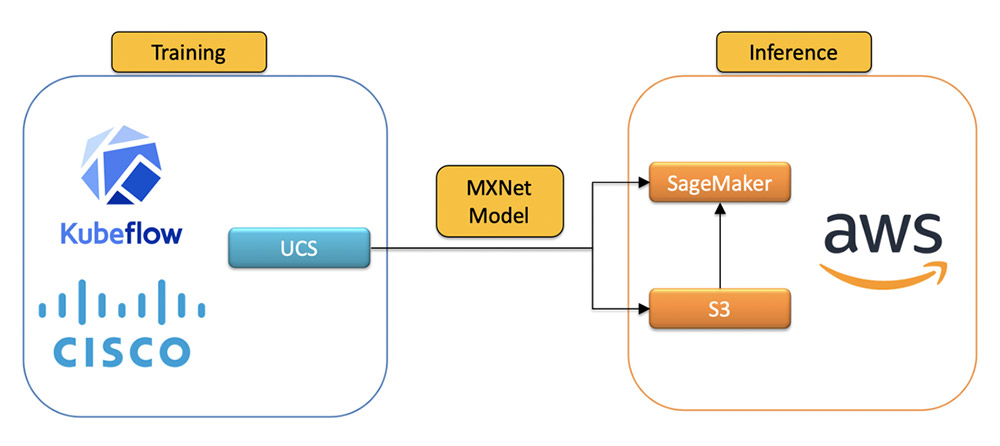
開発環境
現在 Cisco のハードウェアがない場合は、Kubeflow で実行する Amazon Elastic Kubernetes Service (Amazon EKS) をセットアップして使用開始できます。手順については、「Amazon EKS クラスターの作成」および「Kubeflow Pipelines のデプロイ」を参照してください。
既存の UCS マシンがある場合、Cisco Kubeflow スターターパックにより、Kubernetes クラスター (v15.x 以降) で Kubeflow をすばやくセットアップできます。Kubeflow をインストールするには、INGRESS_IP 変数にマシンの IP アドレスを設定し、kubeflowup.bash インストールスクリプトを実行します。次のコードを参照してください。
インストールの詳細については、GitHub リポジトリのインストール手順を参照してください。
ハイブリッドパイプラインの準備
Cisco UCS と AWS の間のシームレスな ML ワークフローのために、Kubeflow Pipelines コンポーネントと Amazon SageMaker Kubeflow コンポーネントを使用してハイブリッドパイプラインを作成しました。
コンポーネントの使用を開始するには、Kubeflow Pipeline パッケージと AWS パッケージをインポートする必要があります。
パイプラインを設定して実行するための完全なコードについては、GitHub リポジトリをご覧ください。
パイプラインは、ワークフローとコンポーネントがグラフの形で相互にどのように関係するかを記述します。パイプライン設定には、パイプラインを実行するために必要な入力 (パラメータ) と、各コンポーネントの入力と出力の定義が含まれます。次のスクリーンショットは、完成したパイプラインを Kubeflow UI で視覚的に表現したものです。
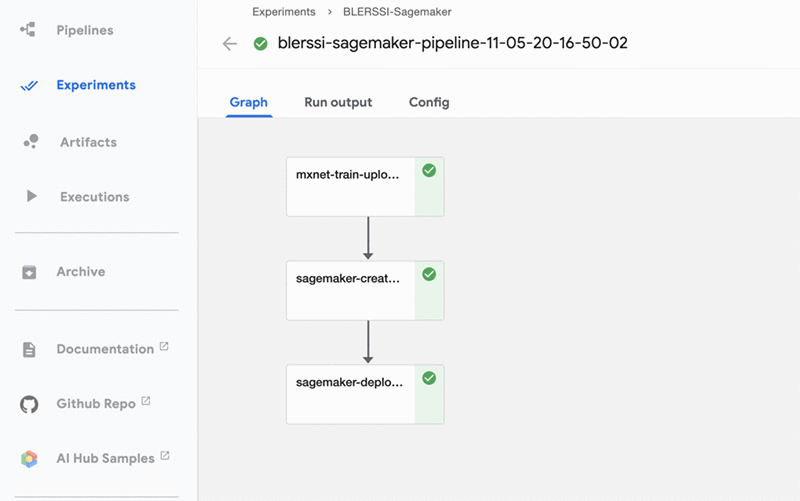
パイプラインは次の 3 つのステップを実行します。
- モデルのトレーニング
- モデルリソースの作成
- モデルのデプロイ
モデルのトレーニング
ローカルで BLE データを使用してモデルをトレーニングし、画像を作成して S3 バケットにアップロードします。次に、MXNet モデル設定 .yaml ファイルを適用して Amazon SageMaker にモデルを登録します。
トレーニング済みのモデルアーティファクトが Amazon S3 にアップロードされると、Amazon SageMaker は Amazon S3 に保存されているモデルを使用して、モデルをホスティングエンドポイントにデプロイします。Amazon SageMaker エンドポイントにより、ダウンストリームアプリケーションがモデルを使用しやすくなり、チームが Amazon CloudWatch を使用してモデルをモニタリングできるようになります。次のコードを参照してください。
モデルリソースの作成
MXNet モデルとアーティファクトが Amazon S3 にアップロードされたら、KF Pipeline CreateModel コンポーネントを使用して、Amazon SageMaker モデルリソースを作成します。
Amazon SageMaker エンドポイント API は柔軟で、トレーニング済みモデルをエンドポイントにデプロイするためのオプションをいくつか提供します。たとえば、デフォルトの Amazon SageMaker ランタイムにモデルのデプロイ、ヘルスチェック、モデルの呼び出しを管理させることができます。Amazon SageMaker では、カスタムコンテナとアルゴリズムを使用してランタイムをカスタマイズすることもできます。手順については、「Amazon SageMaker のコンテナの概要」を参照してください。
このユースケースでは、model health check API と model invocation API をある程度制御する必要がありました。Amazon SageMaker ランタイムのカスタムオーバーライドを選択して、トレーニング済みモデルをデプロイしました。カスタム予測子を使用すると、受信リクエストを処理し、モデルに渡して予測を行う方法を柔軟に設定できます。次のコードを参照してください。
モデルのデプロイ
KF Pipeline CreateEndpoint コンポーネントを使用して、モデルを Amazon SageMaker エンドポイントにデプロイします。
推論に使用されるカスタムコンテナは、チームに最大の柔軟性をもたらし、モデルへのカスタムヘルスチェックと呼び出しを定義します。ただし、カスタムコンテナは、Amazon SageMaker ランタイムによって規定された API のゴールデンパスに従う必要があります。次のコードを参照してください。
パイプラインの実行
パイプラインを実行するには、次の手順を実行します。
- 以下のように、Amazon SageMaker コンポーネントを使用してハイブリッドパイプラインを定義する Python コードを設定します。
設定の詳細については、「パイプラインのクイックスタート」を参照してください。完全なパイプラインコードについては、GitHub リポジトリをご覧ください。
- 次のパラメータをフィードしてパイプラインを実行します。
この時点で、BLERSSI Amazon SageMaker パイプラインが実行を開始します。すべてのコンポーネントが正常に実行されたら、sagemaker-deploy コンポーネントのログをチェックして、エンドポイントが作成されたことを確認します。次のスクリーンショットは、デプロイされたモデルへの URL を含む最後のステップのログを示しています。
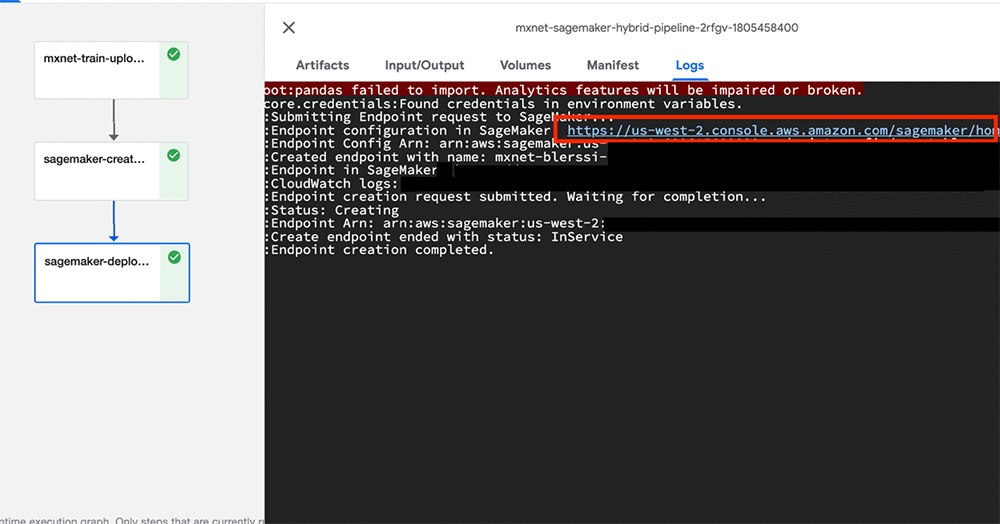
モデルの検証
モデルが AWS にデプロイされた後、AWS にデプロイされたモデルのエンドポイント名を使用して、HTTP リクエストを介してサンプルデータをモデルに送信することにより、モデルを検証します。次のスクリーンショットは、Python クライアントを含むサンプルの Jupyter ノートブックのスニペットと、場所の予測を含む対応する出力を示しています。
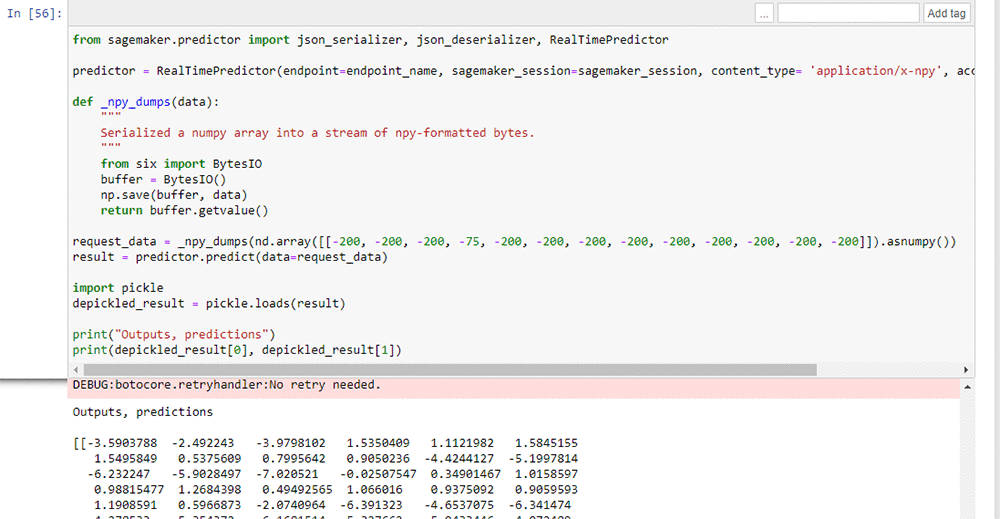
まとめ
Amazon SageMaker と Kubeflow Pipelines は、単一のハイブリッドパイプラインに簡単に統合できます。Amazon SageMaker のブログとチュートリアルの完璧な組み合わせにより、Kubeflow Pipelines 用の Amazon SageMaker コンポーネントを介してハイブリッドパイプラインを簡単に作成できます。API は網羅的で、使用に必要なすべての主要コンポーネントをカバーしています。また、カスタムアルゴリズムの開発と Cisco Kubeflow Starter Pack との統合を可能にしました。トレーニング済みの ML モデルを Amazon S3 にアップロードして、Amazon SageMaker を使用して AWS でサービスを提供することで、複雑な ML ライフサイクルを管理する複雑さと TCO をほぼ半減させました。当社は、データプライバシーに関する最高水準の企業ポリシーに準拠し、米国および世界中で AWS の冗長性を備えたスケーラブルな方法でモデルを提供しています。
著者について
Elvira Dzhuraeva 氏は、Cisco のテクニカルプロダクトマネージャーで、クラウドとオンプレミスの機械学習と人工知能戦略を担当しています。彼女は Kubeflow のコミュニティプロダクトマネージャーでもあり、さらに MLPerf コミュニティのメンバーでもあります。
Debo Dutta 氏は、Cisco の上級エンジニアで、アルゴリズム、システム、機械学習を横断的に扱うテクノロジーグループを率いています。Debo 氏 は Cisco に在籍する傍ら、現在スタンフォード大学の客員研究員を務めています。彼は南カリフォルニア大学でコンピューターサイエンスの博士号を取得し、インド工科大学ハラグプール校でコンピューターサイエンスの学士号を取得しました。
Amit Saha 氏は、Cisco のプリンシパルエンジニアで、システムと機械学習の取り組みを主導しています。彼はインド工科大学ハラグプール校の客員教授です。彼はヒューストンのライス大学でコンピューターサイエンスの博士号を取得し、インド工科大学ハラグプール校の学士号を取得しています。彼は、コンピュータサイエンスに関する最高峰のカンファレンスのプログラム委員会で奉仕したこともあります。