Amazon Web Services ブログ
Amazon EC2 Windows と Amazon Linux 2 インスタンス間で Always On 可用性グループをデプロイする
Microsoft SQL Server 2017 は、Windows と Linux 間の Always On 可用性グループをサポートして、高可用性 (HA) なしで読み取りスケールのワークロードを作成します。残念ながら、そのクロスプラットフォーム設定を管理できるクラスター化されたソリューションがないため、Windows と Linux の間で HA を実現することはできません。
Always On 可用性グループで HA を使用するには、Windows Server Failover Cluster (WSFC) または Pacemaker on Linux の使用を検討してください。このソリューションは、SQL Server on Windows から Linux へ、そしてその逆への移行パス、または手動フェイルオーバーを使用した災害復旧に適しています。
前提条件
開始する前に、以下がインストールされていることを確認してください。
- Windows Server 2012 R2 または 2016 と SQL Server 2017 Enterprise Edition
- SQL Server 2017 Enterprise Edition を含む Amazon Linux 2
- SQL Server on Windows と SQL Server on Linux を管理する SQL Server Management Studio 17+ (SSMS)
以下はオプションです。
- AWS が管理する Microsoft Active Directory DNS サーバー
- AWS Simple AD DNS サーバー
- Amazon EC2 またはオンプレミスソリューションで実行されるカスタム DNS ソリューション
設定
2 つの異なるアベイラビリティーゾーンに、SQL Server 2017 Enterprise を持った EC2 Windows Server 2012 R2 または 2016 インスタンスと、SQL Server 2017 Enterprise を持った EC2 Amazon Linux 2 をデプロイします。EC2 のベストプラクティスの一部として、重要なアプリケーションをアベイラビリティーゾーンにかけてデプロイして、フォールトトレランスを改善します。次に、設定のために以下の手順を使用します。
ホストファイルを設定する
ホストファイルを設定するか、DNS サーバーの Windows および Linux インスタンスの A レコードを登録します。このデモでは、Windows および Linux のホストファイルを使用してホスト名を解決します。
- EC2 インスタンスを起動したら、リモートデスクトッププロトコル (RDP) を使用して Windows インスタンスに接続し、SSH で Linux インスタンスに接続してカスタムホスト名を設定します。Windows Server インスタンスで、
Windows-Hostという名前を付けます。Linux 側では、Linux-Hostという名前を付けます。OS ホスト名を変更した後、SQL ホスト名メタデータの更新を検討してください。 - Windows および Linux で hosts ファイルを設定します。
Windows で、管理者としてメモ帳を開きます。次のスクリーンショットに示すように、[ファイル]、[開く]、次に [C:\Windows\System32\drivers\etc\hosts] を選択します。Windows インスタンスに接続できない場合は、Windows ファイアウォールが ICMPv4-in を許可し、セキュリティグループ/ネットワーク ACL も ipv4 の ICMP を許可していることを確認してください。
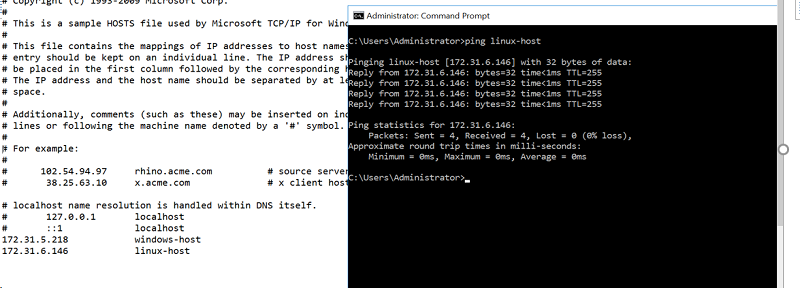
Linux で、次のコマンドを使用します。
sudo vi /etc/hosts
ファイアウォールを設定する
Windows インスタンスと Linux インスタンスの間で TCP ポート 1433 および 5022 を開きます。TCP 1433 (SQL Server のデフォルトポート) と 5022 (Always On のデフォルトポート) を許可するように、セキュリティグループとネットワーク ACL を設定します。
Windows ファイアウォールを設定する
既定では、Windows ファイアウォールは SQL Server および Always On ポートを許可しません。TCP 1433 および 5022 を許可するように Windows ファイアウォールを設定します。SQL サーバー名のインスタンスを使用している場合は、設定で SQL ブラウザーの UDP 1434 ポートも許可されていることを確認してください。
Windows/Linux のファイアウォール設定を支援するには、Windows ファイアウォールおよび Linux ファイアウォールを設定する次のコマンドを使用して、デフォルトの SQL Server TCP ポート 1433 および 5022 を開きます。既定では、SQL Server は TCP 1433 をリッスンするように設定されており、Always On レプリケーションポートは TCP 5022 です。
Windows コマンドプロンプトから、管理者として次を入力します。
(netsh advfirewall firewall add rule name= "SQL-Ports" dir=in action=allow protocol=TCP localport=1433,5022)
ルール名をユースケースに合った別の名前に変更することもできます。
Linux ファイアウォールを設定する
firewalld デーモンがインストールされている場合にのみ、Linux ファイアウォールにも同じことが当てはまります。次のコマンドを実行します。
- sudo firewall-cmd --zone=public --permanent --add-port=1433/tcp
- sudo firewall-cmd --zone=public --permanent --add-port=5022/tcp
- systemctl restart firewalld
SQL Server on Windows と SQL Server on Linux で Always On 可用性グループを有効にする
Windows と Linux 間で Always On HA を設定する前に、SQL Server on Windows と SQL Server on Linux で HA 機能を有効にする必要があります。Windows または Linux で本番 SQL Server を実行している場合、メンテナンスウィンドウをスケジュールする必要があります。Always On HA 機能を有効にした後、SQL Server を再起動する必要があります。
Windows で可用性グループを有効にする
Windows で、SQL Server 2017 Configuration Manager を開きます。
- SQL インスタンスの [プロパティ] を選択します。
- [AlwaysOn 高可用性] を選択してから、[AlwaysOn 高可用性グループ] をクリックします (次のスクリーンショットを参照) 。
- 有効にした後、必ず SQL Server サービスを再起動してください。

Linux で可用性グループを有効にする
Linux で、次のコマンドを実行します。
- sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
- sudo systemctl restart mssql-server
Amazon Linux 2 SQL Server AMI からデプロイした場合、次のコマンドを実行して (sa) のパスワードをリセットします。SQL 認証を使用して SQL Server on Linux に接続する必要があります。Windows では、SQL 認証または Windows 認証を使用して、SQL Server インスタンスを管理できます。
Linux 上のこれらのコマンドは、SQL Server を停止し、組み込み (sa) アカウントパスワードをパスワード設定にリセットします。本番 SQL Server on Linux を実行している場合は、メンテナンスウィンドウをスケジュールするまで SQL Server を停止しないでください。
Linux シェルから、次のコマンドを実行します。
- sudo systemctl stop mssql-server
- sudo /opt/mssql/bin/mssql-conf set-sa-password
強力なパスワードを使用してください。
- sudo systemctl start mssql-server
SQL ログインを作成する
Windows と Linux の間に可用性グループを確立する前に、HADR エンドポイントで使用する SQL ログインを作成する必要があります。これにより、SQL Server on Windows と SQL Server on Linux 間の接続が許可されます。
SSMS を使用して SQL Server on Windows と SQL Server on Linux インスタンス に接続し、次のコマンドを使用して新しいクエリを実行します。
CREATE LOGIN test
WITH PASSWORD = 'Password123'
CREATE USER test
FOR LOGIN test
いつものように、強力なパスワードを使用してください。“test” の代わりに、SQL ログインとユーザーに別の名前を使用できます。
マスター暗号化キーと HADR エンドポイントを作成する
次に、SQL Server on Windows と SQL Server on Linux でマスター暗号化キーを作成して、マシン上の証明書を保護します。SQL Server on Windows と SQL Server on Linux インスタンスを接続するために HADR エンドポイントが使用する証明書を作成します。
証明書オプションは、プラットフォーム間で SQL Server インスタンスを接続するための実用的なユースケースです。次に、WinSCP を使用して、証明書とそのプライベートキーを SQL Server on Linux にコピーします。また、次のクエリを実行する前に、C:\Cert-Backup などの Windows ディレクトリパスを作成します。
Windows でマスター暗号化キーを作成する
このユースケースでは、SQL Server on Windows がプライマリレプリカです。Windows SQL インスタンスで、次のクエリを実行して、マスター暗号化ファイルと証明書を作成します。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Password123';
CREATE CERTIFICATE AG_Cert WITH SUBJECT = 'AG_Cert';
BACKUP CERTIFICATE AG_Cert
TO FILE = 'C:\Cert-Backup\AG_Cert.cer'
WITH PRIVATE KEY (
FILE = 'C:\Cert-Backup\AG_Cert.pvk',
ENCRYPTION BY PASSWORD = 'Password123'
)
いつものように、強力なパスワードを使用してください。
Linux でマスター暗号化キーを作成する
WinSCP (またはお好みのツール) を使用して、証明書ファイルを /var/opt/mssql/data/ の Linux ホストにコピーします。
証明書キーとそのプライベートキーをコピーしたら、SSH を使用して Linux ホストに接続し、次のコマンドを実行します。
cd (/var/opt/mssql/data/)
次に、(ls) を実行して、ファイルが存在することを確認します。
ファイルが存在することを確認したら、次のコマンドを実行してファイルの所有権を設定します。
- sudo chown mssql:mssql /var/opt/mssql/data/ AG_Cert.cer
- sudo chown mssql:mssql /var/opt/mssql/data/ AG_Cert.pvk
この投稿では、SQL Server on Linux をセカンダリレプリカとして使用し、SQL Server on Linux に別のマスター暗号化キーを作成します。
マスター暗号化キーを作成するには、新しいクエリとして次のコマンドを実行します。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Password@1'
いつものように、強力なパスワードを使用してください。
証明書を復元する
SQL Server on Linux で、WinSCP を使用して /var/opt/mssql/data/ にコピーした証明書ファイルを復元します。
証明書を復元するには、新しいクエリとして次のコマンドを実行します。
CREATE CERTIFICATE AG_Cert
AUTHORIZATION test FROM
FILE = '/var/opt/mssql/data/AG_Cert.cer'
WITH PRIVATE KEY
(
FILE = '/var/opt/mssql/data/AG_Cert.pvk',
DECRYPTION BY PASSWORD = 'Password123'
)
復号化パスワードは、この投稿の前半で作成した証明書のプライベートキーの暗号化パスワードと一致する必要があります。
SQL Server on Linux で次のファイル階層が表示されるはずです。

HADR エンドポイントを作成する
Windows と Linux 間でデータベースをレプリケートする前に、以前に作成した証明書と SQL ログイン (Test) を使用する HADR エンドポイントを作成する必要があります。
HADR エンドポイントを作成するには、SQL Server on Windows と SQL Server on Linux で次のクエリを実行します。
CREATE ENDPOINT [AG_Endpoint]
AS TCP (LISTENER_IP = ALL, LISTENER_PORT = 5022)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE AG_Cert,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [AG_Endpoint] STATE = STARTED;
GRANT CONNECT ON ENDPOINT::[AG_Endpoint] TO [test]
エンドポイントが作成されると、次のスクリーンショットに示すように、両方のインスタンスの Database Mirroring の下に AG_Endpoint が表示されるはずです。

可用性グループを作成する
次に、SQL Server on Windows と SQL Server on Linux 間で読み取りスケールデータベースをレプリケートするために使用する可用性グループを作成します。SQL Server 2017 はプラットフォーム間で異なるファイルパスをサポートしているため、SQL Server 自動シードオプションを使用します。グループはプラットフォーム間で使用されるため、cluster type = “None” で可用性グループを作成します。
自動シードオプションを回避するには、自動ではなく手動に設定します。手動に設定した場合、SQL Server on Linux で手動でデータベースを復元する必要があります。また、すべての接続を許可するようにセカンダリレプリカを設定します。
次の SQL クエリは、プライマリレプリカに可用性グループを作成します。この場合のプライマリレプリカは、SQL Server on Windows で実行されています。"Windows-Host" と "Linux-Host" を適切なホスト名に置き換えます。
SQL 可用性グループを作成するには、プライマリレプリカを実行する SQL インスタンスで新しいクエリとして次のコマンドを実行します。
CREATE AVAILABILITY GROUP [AG-Test]
WITH (CLUSTER_TYPE = NONE)
FOR REPLICA ON
N'Windows-Host'
WITH (
ENDPOINT_URL = N'tcp://Windows-Host:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
FAILOVER_MODE = MANUAL,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'Linux-Host'
WITH (
ENDPOINT_URL = N'tcp://Linux-Host:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
FAILOVER_MODE = MANUAL,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
)
セカンダリレプリカへの参加
プライマリレプリカで可用性グループを作成したら、SQL Server on Linux をセカンダリレプリカとして参加させます。
SQL Server on Linux から、新しいクエリとして次のコマンドを実行します。
ALTER AVAILABILITY GROUP [AG-Test] JOIN WITH (CLUSTER_TYPE = NONE)
ALTER AVAILABILITY GROUP [AG-Test] GRANT CREATE ANY DATABASE
GO
クエリが正しく実行されない場合は、Linux インスタンスが TCP 5022 でリッスンしており、Linux ファイアウォールが TCP 5022 を許可していることを確認してください。設定が適切に設定されていることを確認したら、クエリを再実行します。
テストデータベースを作成する
次に、テストデータベースを作成して、Always On 可用性グループに追加できるようにします。データベースは完全復旧モードである必要があります。Always On はその設定の一部が必要なため、データベースの完全バックアップも行う必要があります。
Always On ウィザード設定の一部として、セカンダリレプリカに接続します。この場合、セカンダリレプリカは Linux 上で実行されています。SQL Server 認証を使用して、Linux 上の SQL インスタンスに接続します。
次のスクリーンショットに示すように、データベースの完全バックアップに「Noureddine」という名前を付けました。

[利用可能なデータベース] のコンテキスト (右クリック) メニューを開き、[データベースの追加…]、[データベースの選択] を選択し、作成した完全バックアップをクリックして、データベースを可用性グループに追加します。
次に、SQL Server 認証で接続します。[レプリカに接続] をクリックし、サーバーを選択します。サーバー名を入力し、認証方法を選択し、ログイン名とパスワードを入力して、[接続] をクリックします。
この記事と同様の環境をデプロイしている場合は、自動シードを使用してください。[データ同期の選択] を選択してから、[自動シーディング] を選択して [次へ] をクリックします。
[ウィザードが正常に完了しました] で、[概要] を選択します。データベースが [データベース] の下に表示されます。[完了] を選択します。[結果] を選択すると、[名前] の下に [可用性グループ ‘AG-Test’ へのデータベースの追加] が、そして [結果] の下に [成功] が表示されるはずです。
プライマリレプリカで、次のスクリーンショットに示すような結果が表示されるはずです。

セカンダリレプリカで、次のスクリーンショットに示すような結果が表示されるはずです。

[可用性グループプロパティ] で可用性モード (同期または非同期) を変更することもできます。

フェイルオーバーをテストする
SQL Server の設定が完了したら、フェイルオーバーをテストして、Always On が期待どおりに機能していることを確認します。SQL Server on Windows または SQL Server on Linux 間のフェイルオーバーは、Windows の従来の SQL Server Always On クラスタリングとは異なるプロセスです。
データを失うことなく手動フェイルオーバーをテストするには、次の手順を実行します。
- セカンダリが確実にキャッチアップされるようにするには、プライマリレプリカとセカンダリレプリカを同期コミットモードに設定します。
- 次のクエリを実行します。
ALTER AVAILABILITY GROUP [AG-Test]
SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1)
この設定により、プライマリレプリカが各トランザクションをコミットする前に、指定された数のセカンダリレプリカがトランザクションデータをログに書き込むことが保証されます。詳細については、「高可用性と、可用性グループ設定のデータ保護」を参照してください。
- 次のクエリを実行して、プライマリレプリカをセカンダリに降格させます。
ALTER AVAILABILITY GROUP [AG-Test] SET (ROLE = SECONDARY)
- 次のクエリを実行して、セカンダリレプリカをプライマリに昇格させます。
ALTER AVAILABILITY GROUP [AG-Test] FORCE_FAILOVER_ALLOW_DATA_LOSS
- 以前のプライマリレプリカはデータの移動を停止します。現在のセカンダリレプリカで、次のクエリを実行してデータの移動を手動で再開します。
ALTER DATABASE dbname SET HADR RESUME
(「dbname」を適切なデータベース名に置き換えてください)。
プライマリレプリカが利用できない場合は、データ損失を伴う手動フェイルオーバーを強制する必要があります。セカンダリレプリカで、次のクエリを実行します。
ALTER AVAILABILITY GROUP [AG-Test] FORCE_FAILOVER_ALLOW_DATA_LOSS
回復後にプライマリロールを引き継ぐ以前のプライマリレプリカで、次のクエリを実行します。
“ALTER AVAILABILITY GROUP [AG-Test] SET (ROLE = SECONDARY)”
次に、次のクエリを実行します。
“ALTER DATABASE noureddine SET HADR RESUME”
お疲れさまでした。 これで終了です。
著者について

Noureddine Ennacir は、アマゾン ウェブ サービスのクラウドサポートエンジニアです。