Amazon Web Services ブログ
DXC Technology が AWS の機械学習を使ってサポートチケットの選別を自動化
DXC Technology は、さまざまな企業や政府機関向けに、デジタルトランスフォーメーション上でエンドツーエンドのサービスを提供している IT サービスの世界的大手企業です。同社は、オンプレミスとクラウドで、クライアントのサービス管理も行っています。 プロセスの過程でインシデントチケットが発生した場合は、サービスレベルアグリーメント (SLA) に沿ってすばやく解決する必要があります。 DXC は、人的作業を減らし、インシデントの解決時間を短縮し、知識管理を強化して、インシデント解決の一貫性を向上させることを目標に掲げています。 そして、この目標を念頭に、知識管理 (KM) 記事の予測メカニズムを開発しました。
今回のブログでは、DXC が、KM 記事を自動的に特定するために AWS で機械学習をどのように使用しているか、またそれをチケット解決用のオーケストレーションランブックで自動化し、IT サポートの効率をいかに向上できるかについてご紹介します。
AWS を活用した DXC のソリューション
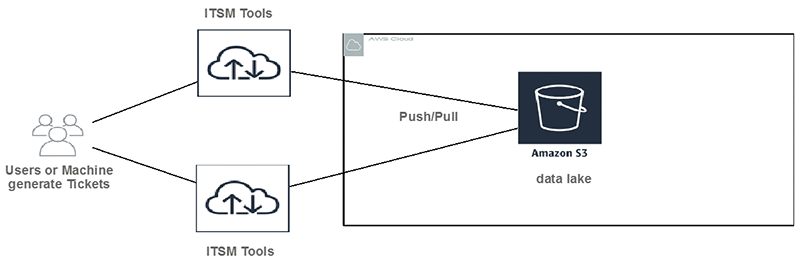
その 1: Amazon S3 にデータレイクを構築する
DXC の顧客が、インシデントチケットを IT サービスマネジメントツール (ITSM) へ送ります。チケットは、ユーザーまたはマシンにより生成できます。データは、Amazon S3 のバケットへプッシュまたはプルされます。Amazon S3 は、高い耐久性で低価格のオブジェクトストレージであり、形式やフォーマットを問わずあらゆるデータを保存できます。
その 2: 最適な機械学習ツールとアルゴリズムを選択する
一般に、問題は、テキストをいかに分類するかということです。AWS は、テキストを分類するためのさまざまな選択肢を顧客に提供しています。DXC は、次の AWS サービスの評価を行いました。
- BlazingText と呼ばれるアルゴリズム内蔵の Amazon SageMaker
- Amazon Comprehend のカスタム分類
最適な選択肢は、Amazon Comprehend のカスタム分類の API でした。テキスト分類向けに徹底した構築が行われているためです。Amazon Comprehend を使用すると、最高の精度を求めて自らアルゴリズムを選び、調整し、自社のモデルを再トレーニングする必要がなくなりました。それらはすべて API が自動で行ったからです。同期呼び出しのサポートが開始されるときは、再度評価を行う予定です(現在はバッチモードの分類を提供)。
Amazon SageMaker の BlazingText は、fastText アルゴリズムを実装し、スケーラビリティと正確性の最適なバランスを維持しています。
その 3: モデルをトレーニングする
データ準備のトレーング:
モデルをトレーニングすることは、ML プロセスの最も重要な工程です。 管理されたモデルをトレーニングするには、ラベル付きのデータが必要になります。そのために DXC のチームは、大量の履歴データにラベル付けを行う必要がありました。テキストデータは、プロセス前の段階で NLTK (Python ライブラリ) を使ってトークン化され、トレーニングのために CSV 形式で Amazon S3 に保存されました。 トレーニングは、その履歴データを使って月 1 回行われます。
トークン化されたトレーニングデータは、以下の通りです。これらはトレーニングジョブの入力データとして使用されます。

ハイパーパラメータの最適化 (HPO) を備えたトレーニングジョブ
BlazingText のアルゴリズムのハイパーパラメータの検索を自動化し迅速化するため、Amazon SageMaker の自動モデル調整機能を使用します。
まず、静的なハイパーパラメータを設定し、トレーニングジョブ全般で変更を行う必要性をなくします。また、最適化を必要とするハイパーパラメータの範囲を定義します。
注: 下記のコードで参照されているパラメータの値は、すべてサンプル値です。値は、各自の要件に基づき、独自の値をテストし使用する必要があります。
次に、推定子と HPO チューナーをインスタンス化しました。それから、Amazon S3 で提供されているトレーニングデータを使ってトレーニングジョブをトリガーしました。
その 4: AWS Step Functions を使用して Amazon SageMaker でのデータの準備、モデルのトレーニング、モデルのデプロイのオーケストレーションを行う
当社は AWS Step Functions を使用してこの ML ワークフローのオーケストレーションを行い、Amazon CloudWatch Events のルールを使用してスケジュールを設定しました。
AWS Step Functions では、次のステップが実行されます。
- トレーニングの入力データがある場所に Amazon S3 バケットが存在するかチェックします。
- モデルのトレーニング用のデータセットを前処理します。
- 必要なパラメータを使用して Amazon SageMaker でのトレーニングジョブを開始します。
- トレーニングジョブのステータスを継続的にチェックします。
- トレーニングが正常に完了した後に、モデルを検証します。
- モデル検証後、Amazon SageMaker エンドポイントとしてモデルをデプロイします。(モデルエンドポイントがある場合は、そのモデルエンドポイントを更新します。)
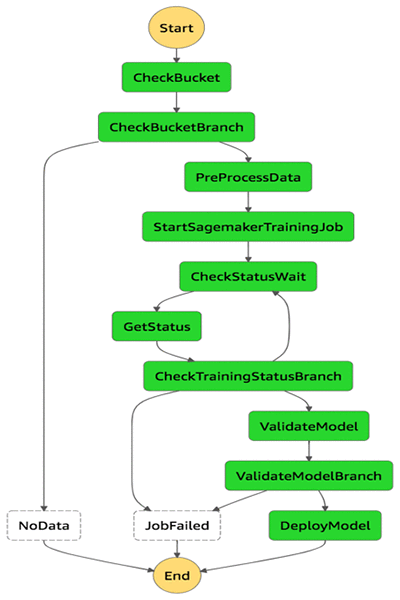
これらのステップはすべて AWS Lambda 関数として展開されます。
注意 : AWS re:Invent 2018 の期間中に、新しい機能がリリースされ、Step Functions を Amazon SageMaker と直接統合できるようになりました。この機能を使用して、先ほど説明したステップの一部を Lambda 関数を書き込まずに展開することができます。しかしながら、DXC がこのソリューションを開発した当時は、この機能が利用できませんでした。
その 5: 推論を呼び出す
新しい ITSM チケットが Amazon S3 バケットに取り込まれるとすぐに AWS Lambda 関数がトリガーされ、Amazon SageMaker エンドポイントを使用して推論を呼び出します。
Lambda 関数は受信するファイルからチケット番号および説明を読み取り、次のようなペイロードを作成します。

次に、ペイロードの情報を使用して Amazon SageMaker モデルエンドポイントを呼び出します。
CSV 出力が作成されて Amazon S3 に保存されます。出力は次の例の通りです。チケット番号、予測される KB ドキュメント、信頼レベルが保存されます。
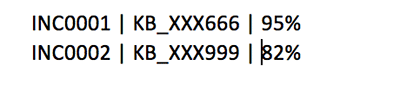
その 6: CI/CD パイプラインを構築して、ソリューションのデプロイを自動化する
DXC は、Ansible、Jenkins、および AWS CloudFormation のテンプレートを使用して CI/CD パイプラインを開発し、ソリューション全体のデプロイを自動化しました。
その 7: サポートチームが利用できるようにする
予測が生成されると、インシデントの識別子またはインシデントの説明に基づき、API エンドポイントを使用してアクセスすることができます。 インシデントの説明は問題をリアルタイムで解決するのにより適しています。チケットの作成も不要となる場合があります。Amazon SageMaker エンドポイントと照合された場合の問題の説明としてオフラインで参照可能な KM 記事識別子が出力されるため、問題が解決につながる可能性があります。このシナリオでは、チケットの作成は不要です。
チケット作成済みの場合、Service Desk Agent はチャットボットを使用して、API を呼び出すか、インシデント識別子を提供することにより直接 API を使用することができます。インシデント識別子の出力は、KM 記事識別子となります。これをオフラインですぐに参照してインシデントを解決することができるので、解決にかかる時間が低減します。
さらに、ランブックのオートメーションと統合することで、チケット解決がオートメーション化されて人の手がほとんどかからなくなります。
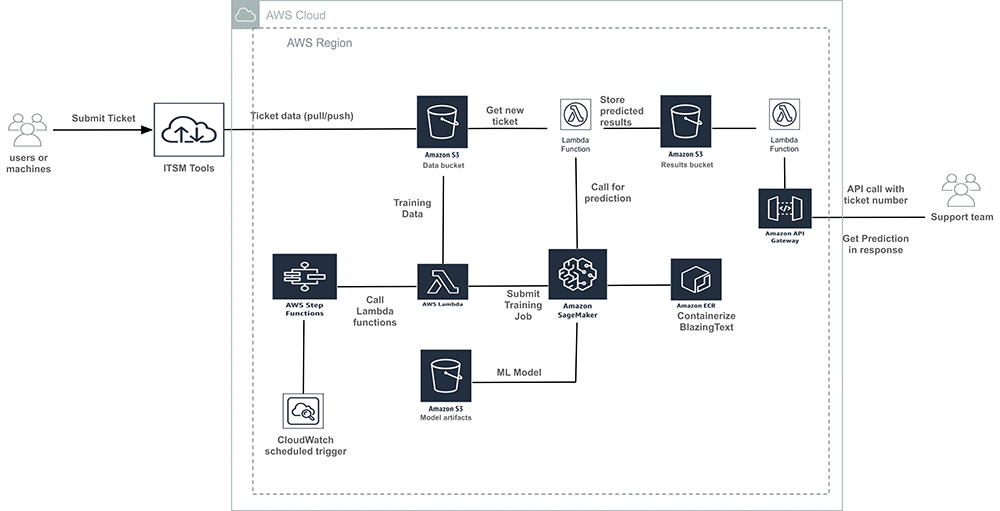
エンドツーエンドのソリューション
全体的なアーキテクチャは次の通りです。
結論 – DXC が達成したこと
要約すると、KM 記事予測メカニズムによって、次のような利点が実現しました。
- サポートチームの効率性が改善されました。サポートチームは、チケットの解決のためにどの KM 記事を確認するべきかをほぼ瞬時に知ることができます。
- ユーザーがチケットの説明を入力し、そこで KM の記事を取得して自分の問題を解決する場合に、この予測メカニズムをセルフサービスとして使用することもできます。これによって、チケットの数も低減します。
- このメカニズムをランブックのオートメーションと統合することで、チケットの解決も自動化することができます。
著者について

Sougata Biswas は AWS プロフェッショナルサービスのビッグデータアーキテクトです。AWS のお客様が AWS でソリューションのアーキテクチャを設計および実装し、データからビジネス価値を得るためのサポートをしています。
 Sofian Hamiti は Amazon ML Solutions Lab のデータサイエンティストです。さまざまな業界の AWS のお客様が AI およびクラウドの導入を加速するためのサポートをしています。
Sofian Hamiti は Amazon ML Solutions Lab のデータサイエンティストです。さまざまな業界の AWS のお客様が AI およびクラウドの導入を加速するためのサポートをしています。
プロジェクトに従事した DXC チームに感謝いたします。特に、このブログポストの作成を奨励しレビューしていただいた以下の DXC のリーダーにお礼申し上げます。
Niladri Chowdhury は、DXC Technology の Data Engineering and Analytics Mgr Operations Engineering and Excellence (OE&E) の担当マネージャーです。アナリスト、データエンジニア、データサイエンティストのチームを率いて、クラス最高のクラウドでのビジネスインテリジェンス配信ソリューションを設計、構築、デプロイします。
William Giotto, は、DXC Technology のグローバルプロダクトオーナーです。インテリジェントなオートメーションを目指して努力を重ねています。父親であり、データサイエンスに熱心に取り組む、アマチュア天文家です。(www.astrogiotto.com)