Amazon Web Services ブログ
ironSource が多目的データレイクを Upsolver、Amazon S3、および Amazon Athena で構築する方法
ironSourceは、独自の言葉で言えば、アプリ内の収益化と動画広告の主要なプラットフォームで、世界中の 15 億人を超える人々が無料でプレイおよび使用できるようにしています。 ironSource は、業界最大のアプリ内動画ネットワークなどを含めて、アプリ開発者がアプリを次のレベルに引き上げることを支援します。80,000 を超えるアプリが ironSource テクノロジーを使用して、ビジネスを成長させています。
ironSource がさまざまな収益化プラットフォーム(アプリ、ビデオ、メディエーションを含む)にわたって動作する巨大な規模は、膨大な量のストリーミングデータを生成する数百万のエンドデバイスにつながります。インフラストラクチャとエンジニアリングのオーバーヘッドを最小限に抑える一方で、複数のユースケースをサポートするために、データを収集、保存、準備する必要があります。
この記事では以下について説明します。
- ironSource が Amazon S3 に基づくデータレイクアーキテクチャを選択した理由。
- ironSource が Upsolver を使用してデータレイクを構築する方法
- Amazon Athena、Amazon ES、および Tableau などのアナリティックサービスに対して出力を作成する方法。
- このソリューションの利点
データレイクアーキテクチャの利点
データベースに焦点をあてたアプローチで数年間仕事をした後で、ironSource のデータは以前のシステムをコストとメンテナンスの観点で、実行不可能にしました。代わりに、生イベントデータをオブジェクトストレージに保管し、複数のアプリケーションとアナリティックフローに対応してカスタマイズされた出力ストリームを作成するデータレイクアーキテクチャを採用しました。
ironSource が AWS データレイクを選択した理由
データレイクは以下の理由で ironSource の正しいソリューションでした。
- 規模 – ironSource は、1 秒あたり 50 万件のイベントと毎日 200 億件を超えるイベントを処理しています。S3 でほぼ無限の量のデータを、データの事前処理なしで保管する能力は重要です。
- 柔軟性 – ironSource は複数のビジネスプロセスをサポートするデータを使用します。同じデータを複数のサービスにフィードして、異なるユースケースを提供することが必要なため、会社はデータベースアプローチによりもたらされる堅牢姓とスキーマ―の制限をバイパスすることが必要でした。代わりに、元のデータを S3 に保管して、臨時の出力と変換を必要に応じて作成します。
- 弾力性 – すべての履歴データが S3 にあるため、障害からの回復が容易になり、パイプラインのさらに下のエラーが本番環境に影響を与える可能性が低くなります。
ironSource が Upsolver を選択した理由
Upsolver のストリーミングデータプラットフォームは、クラウドデータレイクの構築と管理に関連づけられたコーディング集約型プロセスを自動化します。Upsolver を使用すると、ironSource は、データを取り込み、分析のために準備し、構造化されたテーブルをさまざまなクエリサービスに出力するために、GUIベースのセルフサービスツールを提供することで、幅広いデータコンシューマーをサポートし、DevOps エンジニアがデータ配管に費やす時間を最小限に抑えることができます。
重要な利点には以下のものが含まれています。
- データコンシューマーの自給自足 – セルフサービスのプラットフォームとして、Upsolver は BI 開発者、Ops、およびソフトウェアチームにコードを書かせずに、データストリームを表形式のデータに変換させることを許可します。
- 改善されたパフォーマンス – Upsolver が S3 の最適な Parquet ストレージでファイルを保管するため、ironSource は手動のパフォーマンス調整なしで、クエリの高いパフォーマンスからの恩恵を受けます。
- 伸縮自在なスケーリング – ironSource は急成長しているため、1 週間のインバウンドデータ量とピークの増加、S3 からのイベントの再処理、およびデータを使用する異なるグループ間の隔離を処理するために伸縮自在なスケーリングを必要としています。
- データプライバシー – ironSource の VPC は Upsolver を外部からのアクセスなしでデプロイするため、機密データに関するリスクはありません。
この投稿では ironSource が Upsolver を使用して、最小限のコーディングとメンテナンスにより、そのデータを構築、管理、および調整する方法を示します。
ソリューションのアーキテクチャ
次の図は、ironSource が使用するアーキテクチャを示したものです。

Kafka から Upsolver へのストリーミングと S3 での保管
Apache Kafka はデータを ironSource のモバイル SDK から 1 秒あたり最大 50 万件のイベントの速度でストリーミングします。Upsolver はデータを Kafka から取り出し、データレイクアーキテクチャ内の S3 にそれを保管します。また、生イベントデータのコピーを維持する一方で、各イベントを正確に一度書き込み、同じデータを消費のために最適化された Parquet ファイルに保管します。
Upsolver での入力ストリームの構築
Upsolver GUI を使用して、ironSource は関連する Kafka トピックに直接接続し、それらを S3 に正確に一度書き込みます。次のスクリーンショットをご覧ください。
![[Data Source] タブを示す Upsolver UI の画像は、[Compute Cluster] セクションで [Mobile SDK Cluster] が強調表示された [Create a Kafka Data Source] ページに開いています。](https://d2908q01vomqb2.cloudfront.net/b6692ea5df920cad691c20319a6fffd7a4a766b8/2019/09/25/IronSourceUpsolver2.png)
S3 にデータが保管された後で、ironSource は多岐にわたるデータベースとアナリティックツールを使用して、データを運用を進めることができます。次のステップは、最も顕著なツールについて取り上げます。
Athena への出力
本番稼働の問題を理解するために、開発者と製品チームはデータにアクセスする必要があります。これらのチームはデータを直接操作し、Upsolver と Ahtena を使用して自分自身の質問に答えを出すことができます。
Upsolver は、コンパクト化、圧縮、パーティション化、AWS Glue データカタログ内のテーブルの作成と管理などを含む、Athenaで使用するデータの準備プロセスを簡素化し、また自動化します。ironSource の DevOps チームは、パイプラインエンジニアリングで何百時間も節約します。Upsolver の GUI は各テーブルを一度作成し、そのポイントから先は、データコンシューマーは完全に自給自足になります。Athena のクエリを高速に、また最小限のコストで実行するために、Upsolver はデータが S3 に取り込まれて保存される際のパフォーマンス調整のベストプラクティスも実施します。詳細については、Top 10 Performance Tuning Tips for Amazon Athena を参照してください。
Athena のサーバーレスアーキテクチャはさらにこの独立性を保管します。つまり、管理するインフラストラクチャがなく、アナリストが新しい質問ごとに Amazon Redshift またはクエリクラスターを使用するために DevOps を必要としないことを意味します。代わりに、アナリストは必要なデータを示して、回答を得ることができます。
Upsolver での Athena へのテーブルの送信
Upsolver では、SQL または組み込み GUI を使用して、関連付けられたスキーマでテーブルを宣言できます。これらのテーブルを AWS Glue データカタログを通じて、Athena に露出することができます。Upsolver は Parquet ファイルを S3 に保存し、Create DDL と Alter DDL ステートメントを使用して、AWS Glue データカタログに適切なテーブルとパーティション情報を作成します。Upsolver Output を使用して、これらのテーブルを編集し、列を追加、削除、または変更することもできます。Upsolver は S3 にテーブルデータを作成し直し、AWS GLUE データカタログのメタデータを変更するプロセスを自動化します。
テーブルの作成
![[Outputs] タブを示す Upsolver UI の画像は、[Mobile SDK Data] ページに開かれています。](https://d2908q01vomqb2.cloudfront.net/b6692ea5df920cad691c20319a6fffd7a4a766b8/2019/09/25/IronSourceUpsolver3.png)
Amazon Athena へのテーブルの送信
![[Run Parameters] ダイアログボックスを表示する Upsolver UI の画像が開いており、前の画像で説明した [Mobile SDK Data] ページからこのダイアログボックスに移動してきています。](https://d2908q01vomqb2.cloudfront.net/b6692ea5df920cad691c20319a6fffd7a4a766b8/2019/09/25/IronSourceUpsolver4.png)
出力のためのテーブルオプションの編集
![[Mobile SDK Data] ページの画像。左上の3つのドットからドロップダウンメニューを示し、[Edit] が強調表示されています。](https://d2908q01vomqb2.cloudfront.net/b6692ea5df920cad691c20319a6fffd7a4a766b8/2019/09/25/IronSourceUpsolver5.png)
Upsolver の出力での既存のテーブルの変更

BI プラットフォームへの出力
IronSource の BI アナリストは Tableau を使用して、SQL を使用するデータをクエリし、可視化します。ただし、ストリーミングデータでこのタイプの分析を実行するには、広範な ETL とデータ準備が必要になる場合があり、分析の範囲が制限され、レポートのボトルネックを作成します。
IronSource のクラウドデータレイクアーキテクチャは、BI チームがTableau のビッグデータを操作できるようにします。それらは Upsolver を使用して、データを強化して、フィルター処理し、Redshift に書き込んでレポートダッシュボードを構築するか、アドホック分析クエリのためにテーブルを Athena に送信します。Tableau は Redshift と Athena の両方にネイティブに接続するため、アナリストは、手動の ETL プロセスに頼るのではなく、通常の SQL と使い慣れたツールを使用してデータを照会できます。
Amazon ES の縮小ストリームの作成
IronSource のエンジニアリングチームは、Amazon ES を使用してアプリケーションログを監視および分析します。ただし、他のデータベースと同様に、Amazon ES に生データを保存することは高価であり、運用上の問題につながる可能性があります。
これらのログの大部分は重複しているため、Upsolver はデータを重複排除します。これにより、Amazon ES コストを減らし、パフォーマンスを改善します。Upsolver は同一のレコードを集積することにより、Amazon ES でストアされたデータのサイズを 70% 削減します。これにより、大量のログを生成するにもかかわらず、実行可能でコスト効率が良くなります。
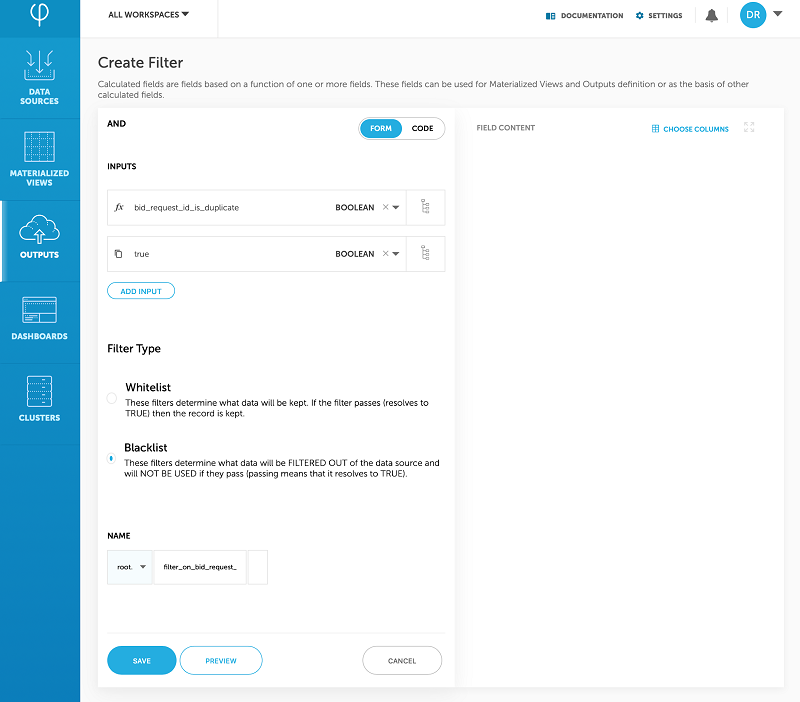
これを行うために、Upsolver は計算されたフィールドをイベントストリームに追加します。このことは、特定のログが重複しているかどうかを示します。重複している場合は、Amazon ES に送信されるストリームからのログをフィルタリングします。
計算されたフィールドの作成

計算されたフィールドを使用したフィルタリング
まとめ
自給自足は ironSource の開発理念の大きな部分を占めます。データインフラストラクチャの改良で、会社は開発者と BI チームがデータの操作をするために、DevOps とデータエンジニアリングに過度に依存することなく。セルフサービスの環境を作成することを模索してきました。データエンジニアは、コード指向の ETL フローを構築して維持する代わりに、機能に焦点を合わせることができるようになりました。
ironSource は、Upsolver および AWS データレイクツールを使用して、アジャイルで多用途のアーキテクチャを構築することに成功しました。このソリューションは、データのコンシューマーがデータを独立して操作できるようにする一方で、大幅にデータの新鮮さを向上させ、それにより社内意思決定と社外報告の両方に対応する上で役立ちます。
数字の結果の一部には、以下が含まれます。
- 何千時間ものエンジニアリング時間を節約 – ironSource の DevOps とデータエンジニアは、手動のコーディング集約型プロセスをセルフサービスツールと管理されたインフラストラクチャに置き換えることで、インフラストラクチャに費やすはずの数千時間を節約しています。
- 費用を節約 – インフラストラクチャ、労働力、およびライセンスコストを考慮して、Upsolver は ironSource のインフラストラクチャコスト全体を大幅に削減します。
- Kafka からエンドユーザーへの 15 分のレイテンシ – データコンシューマーはほぼりらるタイムのデータに対応し、アクションを行うことができます。
- スケール増大の速度が 9 倍 – 現在は、0.5 M の受信イベント/秒および 3.5 M の送信イベント/秒です。
ronSource Mobile の研究開発担当バイスプレジデントである Seva Feldman は、次のように述べています。「DevOps を含むエンジニアリングチームがインフラストラクチャに費やす時間を最小限に抑え、機能の開発に費やす時間を最大限に増やしたいと考えています。Upsolver は数千時間のエンジニアリング時間を節約し、総所有コストを大幅に削減しました。これにより、これらのリソースをデータパイプラインではなくハイパーグロースの継続に投資することができます。」
この記事の内容および意見は第三者の作者によるものであり、AWS はこの記事の内容または正確性について責任を負いません。
著者について
Seva Feldman は ironSource Mobile の R&D 担当のバイスプレジデントです。
20 年以上にわたるシニアアーキテクチャとしての経験により、Seva は運用上の課題を改善の機会に変換するエキスパートです。
 Eran Levy は、Upsolver のマーケティングディレクターです。
Eran Levy は、Upsolver のマーケティングディレクターです。
 Roy Hasson は、AWS の分析およびデータレイクのグローバルビジネス開発リーダーです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy は、マンチェスターユナイテッドの大ファンであり、家族とともにチームを応援しています。
Roy Hasson は、AWS の分析およびデータレイクのグローバルビジネス開発リーダーです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy は、マンチェスターユナイテッドの大ファンであり、家族とともにチームを応援しています。