Amazon Web Services ブログ
CloudEndure Disaster Recovery を使ったアプリケーションの復旧力強化
IT 災害の発生時には、ビジネスの継続性を確保するために、ワークロードのバックアップを行った上で、それを素早く再実行させる必要があります。ビジネスクリティカルなアプリケーションでは、復旧時間とデータ損失を最小限に留めることが最優先ですが、全体的な予算を抑える必要もあります。
CloudEndure Disaster Recovery は、いかなるソースインフラストラクチャからでも、AWS への迅速なフェイルオーバーを実現するので、災害時にも通常通りのビジネスを維持するのに役立ちます。CloudEndure Disaster Recovery では、AWS の低コストなステージング領域にワークロードをレプリケーションすることで、コンピューティングコストを 95% カットでき、OS やサードパーティーのアプリケーションライセンスを重複配備することもなくなります。今回の記事では、CloudEndure Disaster Recovery をオンプレミスマシン用にセットアップするための、一連の基本的な手順をご紹介します。
CloudEndure Disaster Recovery の動作
CloudEndure Disaster Recovery はエージェントベースのソリューションで、 AWS アカウントにあるステージング領域へのソースマシンの継続的なレプリケーションを、パフォーマンスに影響を与えることなく実行します。この機能には、継続的データ複製技術を使用しています。これにより、サポートされたオペレーティングシステムで実行しているすべてのワークロードの、継続的で同期した、ブロックレベルでのレプリケーションが提供されます。この技術により、1 秒以内の復旧ポイント目標 (RPO) を達成しています。レプリケーションは (ハイパーバイザーや SAN レベルではなく) OS レベルで実行されるので、物理マシン、仮想マシン、そしてクラウドベースのマシンをサポートすることが可能です。災害発生時には、CloudEndure Disaster Recovery に命令を伝えるだけでフェイルオーバーが起動し、自動的なマシンの切り替えとオーケストレーションが実行されます。お使いの各マシンは、数分の内に AWS 上で再起動されるので、積極的な復旧時間目標 (RTO) に対応します。
レプリケーションには、次のように 2 段階の主要なステップがあります。
- 初期同期: インストールされた後の CloudEndure エージェントは、最初のブロックレベルレプリケーションを開始します。ここでは、お客様のマシンにあるすべてのデータを、ターゲットの AWS リージョンにあるステージング領域に複製します。この処理にかかる時間は、レプリケーションが行われるデータの量、および、お使いのソースインフラストラクチャとターゲット AWS リージョン間で使用できる通信の帯域幅によって変わります。
- 継続的データ保護: 初期同期が完了した CloudEndure Disaster Recovery は、ソースマシンの状態を継続的にモニタリングし、直前の 1 秒の内容まで絶え間なく正確な同期を行います。ソースマシンに対し行ったあらゆる変更は、ターゲット AWS リージョンにあるステージング領域にレプリケートされます。

CloudEndure Disaster Recovery のアーキテクチャ
さらに詳しい情報については CloudEndure Disaster Recovery のドキュメントをご参照ください。
ご使用の環境での CloudEndure Disaster Recovery のセットアップ
1. 必要なもの
- AWS アカウント
- AWS Marketplace 内での CloudEndure Disaster Recovery サブスクリプション
- CloudEndure エージェントをソースマシンにインストールするための要件は次の通りです。
- ルートディレクトリ上に最低 2 GB のデスク領域が必要です。エージェントを実行するマシンでは、最低でも 300 MB の RAM が常に解放されていることも確認してください。
- Linux ソースマシンには、Python 2 (2.4 以降) もしくは Python 3 (3.0 以降) が必要です。
2. 接続設定 (完全なネットワーク要件についてはテクニカルドキュメントをご参照ください)
- TCP Port 443 通信:
- ソースマシンと CloudEndure サービスマネージャー間
- ステージング領域と CloudEndure サービスマネージャー間
- TCP Port 1500 通信:
- ソースマシンとステージング領域間
3. 災害復旧プロジェクトの作成と設定
CloudEndure ユーザーコンソールにログインしたら、はじめに新規プロジェクトを作成します。これには、[Project type] リストから [Disaster Recovery] を選択します。

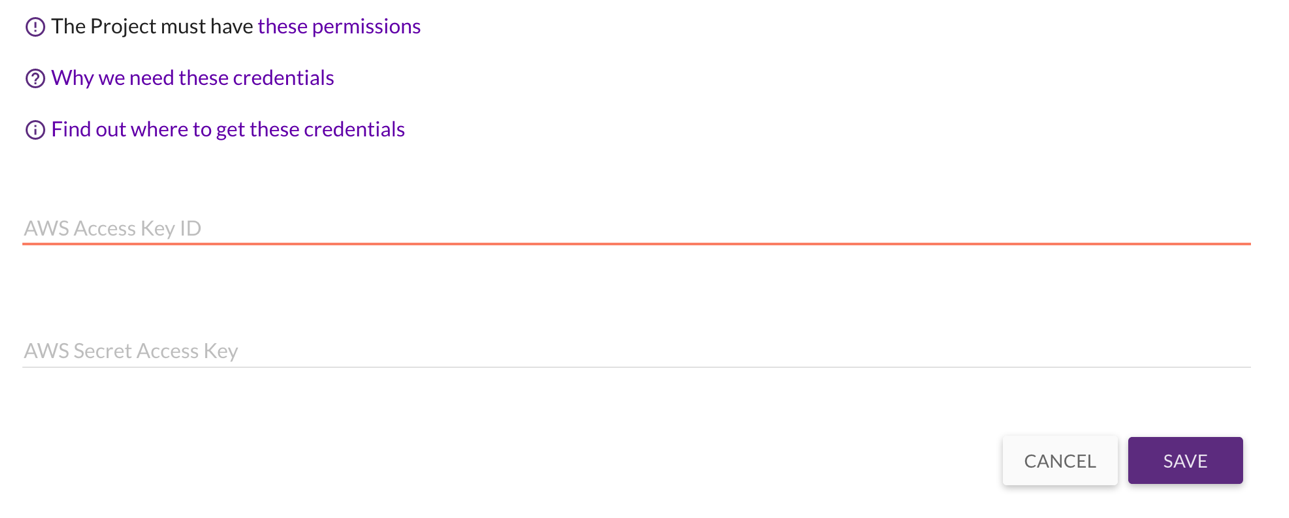
4. AWS 認証情報のセットアップ
AWS 上でリソースを起動するには、ご自身の AWS 認証情報を指定する必要があります。CloudEndure ユーザーコンソールの [Setup & Info] にある [AWS Credentials] に、AWS アクセスキー ID と AWS シークレットアクセスキーの認証情報を追加します。このページには、次のように必要なアクセス許可が表示されています。
5. レプリケーション設定の構成
次に、ご自身のソースマシンのロケーションを指定し、ターゲットのインフラストラクチャを選択します。今回の例では、ソースはオンプレミス (別のインフラストラクチャ) に、ターゲットマシンは AWS 欧州 (フランクフルト) に置かれています。

6.新たなマシンの追加と初期同期の開始
作成した災害復旧プロジェクトにマシンを追加するには、 CloudEndure エージェントのインストーラーをダウンロードし、そのインストール手順に従います。次に示すような、生成されたエージェントインストレーショントークンを使用します。


数秒経過すると、CloudEndure ユーザーコンソールにソースサーバーが表示され、データレプリケーションの進行状況が確認できるようになります。

初期同期の完了後、各マシンが起動可能になります。また、対象マシンのページにある [Data Replication Progress] 列では、継続的データ保護の状況が表示されます。

7. ターゲットマシンのブループリント設定を構成する
準備段階の最終ステップでは、ターゲットマシンのブループリントを使い、各ソースマシンに対するターゲットマシンの設定を定義します。希望のターゲットインフラストラクチャを選択し、その他のレプリケーション設定 (サブネット、セキュリティグループ、タグなど) を定義します。ブループリントの設定は、[Blueprint] メニューにある [Machines] タブから、レプリケーション中のどのタイミングでも行えます。これは、マシンが初期同期を完了していなくても有効です。

災害復旧のテスト
各マシンが継続的データ保護のモードになり、ターゲットのブループリント定義が完了したら、テストモード でそれらのマシンを起動できます。これは、テストしたいマシンを選択してから、画面右上部のメニューで [Test Mode] をクリックするだけで行えます。災害復旧プランが想定通り機能することや、ビジネスクリティカルなワークロードが所望の復旧目標の範囲内で復旧していることを確認するために、この復旧テストを定期的に実施するようにします。

ご使用の環境に、複数のサーバーで実行しているアプリケーションがあるときなど、これらのサーバーの起動をオーケストレーションしたい場合があります。こういったケースでは、復旧プラン機能を使い、起動の順序や起動までの待機時間などの手順を、各マシンに対し定義できます。

1 つのマシンの場合と同様に、復旧プランを適用した複数のマシンに対しても、画面右上のメニューから [Test Mode] を起動することができます。これにより、復旧プランで指定した順番で各マシンが起動します。
![復旧プランを適用したマシンに対しても、画面右上のメニューから [Test Mode] が起動できます](https://d2908q01vomqb2.cloudfront.net/e1822db470e60d090affd0956d743cb0e7cdf113/2020/02/03/You-can-use-the-top-right-menu-to-initiate-Test-Mode-for-machines-in-your-Recovery-Plan.png)
また、復旧ポイントダイアログでは、復旧プランが起動するポイントを指定するためのオプションが使用できます。これには、復旧ポイントを選択した上で、[Continue with Launch] をクリックします。
![復旧ポイントを選択した上で、[Continue with Launch] をクリックします](https://d2908q01vomqb2.cloudfront.net/e1822db470e60d090affd0956d743cb0e7cdf113/2020/02/03/Choose-a-Recovery-Point-and-click-Continue-with-Launch..png)
起動処理中は、次のように、各マシンに対するテストの状況が [Job Progress ] メニューで確認できます。
![起動処理中は、次のように、各マシンに対するテストの状況が [Job Progress ] メニューで確認できます](https://d2908q01vomqb2.cloudfront.net/e1822db470e60d090affd0956d743cb0e7cdf113/2020/02/03/During-the-launch-you-can-follow-the-status-of-your-machines-being-tested-in-the-Job-Progress-Menu.jpg)
立ち上がったターゲットマシンが実行を開始しブートも完了したら、アプリケーションでテストを実行し、すべての動作が適切に行われることを確認します。

フェイルオーバーの実施
これで、各アプリケーションは継続的に同期されています。災害が発生したときは、[Recovery Mode] を選んで復旧プランを起動します。CloudEndure Disaster Recovery は、マシンを Recovery Mode で起動した場合も、Test Mode で起動した場合でも、同じ機能を提供します。異なるのは、Test Mode がテスト用に選択されるのに対し、Recovery Mode は災害発生時に選択されるということです。

Test Mode での設定と同様に、ここでも復旧ポイントを指定する必要があります。処理の進行を [Job Progress] メニューで監視することもできます。
![Test Mode での設定と同様に、ここでも復旧ポイントを指定する必要があります。処理の進行を [Job Progress] メニューで監視することもできます](https://d2908q01vomqb2.cloudfront.net/e1822db470e60d090affd0956d743cb0e7cdf113/2020/02/03/As-described-for-the-Test-Mode-you-must-specify-the-recovery-point-and-you-can-monitor-the-updates-in-the-Job-Progress-menu.png)
Recovery Mode で各サーバーを起動したら、新たなターゲットサーバーにネットワークのトラフィックをリダイレクトして、フェイルオーバーを完了します。
災害後: フェイルバック
CloudEndure Disaster Recovery では、フェイルバックに対する準備も行えます。災害が去った後は、データレプリケーションの方向が、AWS 上のターゲットサーバーからお客様のソースサーバーに向かうよう反転されます。CloudEndure ユーザーコンソールでは、その時点で起動されているターゲットマシンをソースマシンとして扱うようになり、選択している AWS リージョンからオリジナルのソースインフラストラクチャに向け、データが移動されます。
まとめ
この記事では、オンプレミスのマシン用に CloudEndure Disaster Recovery をセットアップする方法をご紹介しました。これが提供する強固な復旧ソリューションにより、お客様のワークロードは AWS にレプリケートされます。お客様は、AWS で稼働中のアプリケーションを容易にテストできるようになり、AWS クラウドに対する習熟もスピードアップされます。災害発生時においてもご使用の環境を保護できるのと同時に、AWS への完全な移行の準備も進められます。
値下げした新たな料金プランで使用を開始する
AWS では最近、CloudEndure Disaster Recovery の使用料金を 80% 削減しました。料金は時間制なので長期契約の必要がなく、多数のサーバーを設定する必要もなしで、簡単にこのソリューションをご利用いただけます。使用開始は、AWS Marketplace 内のCloudEndure Disaster Recovery で行ってください。詳細については CloudEndure Disaster Recovery の製品ページをご参照ください。