Amazon Web Services ブログ
Amazon SageMaker Object2Vec の概要
このブログ記事では、高次元オブジェクトの低次元高密度埋め込みを学ぶことができる、高度にカスタマイズ可能な新しい多目的アルゴリズムである Amazon SageMaker Object2Vec アルゴリズムを紹介します。
埋め込みは、機械学習 (ML) における重要な特徴工学技術です。高次元のベクトルを低次元の空間に変換し、大きな疎ベクトル入力で機械学習を行いやすくします。また、埋め込みは、類似のアイテムを低次元空間の近くに配置することによって、基礎となるデータのセマンティクスも取得します。これにより、下流のモデルのトレーニングで特徴がより効果的になります。よく知られている埋め込みテクニックの 1 つに Word2Vec があり、これは単語の埋め込みを提供します。センチメント分析、ドキュメント分類、自然言語理解など、多くのユースケースで広く使用されています。特徴空間における単語の埋め込みの概念表現については、次の図を参照してください。

図 1: Word2Vec の埋め込み: 意味的に類似している単語は、埋込み空間内で互いに近くに位置しています。
単語の埋め込みに加えて、文章、顧客、製品など、より汎用的なオブジェクトの埋め込みを学びたいユースケースもあります。これは、情報検索、製品検索、商品照合、類似性に基づく顧客プロファイリングのため、または他の教師ありタスクの入力として実用的なアプリケーションを構築できるようにするためです。これが、Amazon SageMaker Object2Vec が導入された場所です。このブログ記事では、それが何であるか、それがどのように機能するか、いくつかの実用的なユースケースについて議論し、Object2Vec を使ってそうしたユースケースを解決する方法を紹介します。
仕組みの説明
埋め込みは、元の空間内のオブジェクトのペアの間の関係の意味が埋め込み空間内で保持されるように学習されます。したがって、学習された埋め込みを使用して、オブジェクトの最近傍を効率的に計算し、低次元空間内での関連オブジェクトの自然クラスターを視覚化することができます。さらに、埋め込みは、分類または回帰のような下流の教師ありタスクにおける対応するオブジェクトの特徴として使用することもできます。
Amazon SageMaker Object2Vec のアーキテクチャは、以下の主要コンポーネントで構成されています。
- 2 つの入力チャネル—2 つの入力チャネルが、同じタイプまたは異なるタイプのオブジェクトのペアを入力として受け取り、それらを独立したカスタマイズ可能なエンコーダーに渡します。 入力オブジェクトの例としては、シーケンスのペア、トークンのペア、シーケンスとトークンのペアがあります。
- 2 つのエンコーダー—エンコーダーは、それぞれのオブジェクトを固定長の埋め込みベクトルに変換します。 次に、ペア内のオブジェクトのエンコードされた埋め込みがコンパレータに渡されます。
- コンパレータ—コンパレータは埋め込みを異なる方法で比較し、ユーザーによって指定された各関係について、ペア内のオブジェクトの関係の強さに対応するスコアを出力します。出力スコアの例は、オブジェクトのペア間の強い関係を示す 1、または弱い関係を表す 0 などとなります。
トレーニング時に、トレーニング損失関数は、モデルによって予測された関係と、トレーニングデータでユーザーによって指定された関係との間の差異を最小にします。モデルをトレーニングした後、トレーニングされたエンコーダーを使用して、新しい入力オブジェクトを固定長の埋め込みに変換することができます。Object2Vec のアーキテクチャ図とアーキテクチャの各部の説明は次のとおりです。
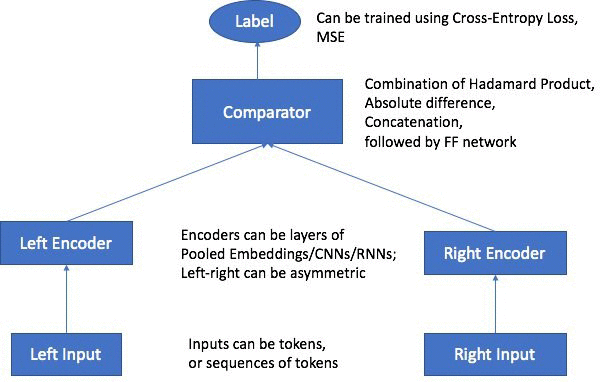
サポートされている入力タイプ、エンコーダー、損失関数
自然なこととして、Object2Vec は現在、integer-id として表されたシングルトン離散トークンと integer-id のリストとして表現された離散トークンのシーケンスを入力としてサポートしているため、入力データをサポートされている形式に変換するために前処理が必要です。それぞれのペアのオブジェクトは、互いに非対称であることもあります。たとえば、(トークン、シーケンス) ペア、(トークン、トークン) ペア、(シーケンス、シーケンス) ペアのいずれかです。トークンの場合、互換性のあるエンコーダーとして簡単な埋め込みをサポートしていますが、トークンのシーケンスの場合は、平均プール埋め込み、階層型畳み込みニューラルネットワーク (CNN)、多層双方向長時間短期記憶 ( BiLSTM) ベースのリカレントニューラルネットワークをエンコーダーをサポートします。それぞれのペアの入力ラベルは、ペア内のオブジェクト間の関係を表すカテゴリラベルであってもよいし、2 つのオブジェクト間の類似性の強さを表す評価またはスコアであってもかまいません。カテゴリラベルの場合はクロスエントロピー損失関数をサポートし、評価/スコアベースのラベルの場合は平均二乗誤差 (MSE) 損失関数をサポートしています。
Object2Vec でサポートされている現在の入力タイプは、離散トークンまたはシングルトントークンのいずれかのシーケンスですが、これらのオブジェクトを記述するデータは通常、離散シーケンスとして表現できるため、これらの入力タイプはすでに多くの実世界オブジェクトをカバーしています。以下にいくつかの例を示します。
- 顧客の埋め込み: 顧客の埋め込みを学ぶために、各顧客の最新のトランザクションのシーケンスからなる取引データを生成することができます。ここで、シーケンスは、肯定的な例として、顧客の ID とペアになる顧客によって購入された product-ID のリストとして表されます。否定的な例として、元の (したがって、不正確な) customer-ID とペアになった異なる顧客の取引を生成することができます。それぞれのペアについて、取引のシーケンスは、CNN または BiLSTM エンコーダーへの入力として渡され、customer-ID は埋め込みベースのエンコーダーへ渡されます。トレーニングを受けた後、顧客の埋め込みを埋め込みベースのエンコーダーから直接読み取ることができます。
- 製品の埋め込み: 製品の埋め込みをトレーニングするために、一連のテキストトークンとして表される製品のタイトルと product-ID を肯定的な例としてペアにすることができます。否定的な例として、別の (潜在的に関連する) 製品のタイトルと元の (そして間違っている) product-ID をペアにすることができます。
- ユーザーおよび動画の埋め込み: ユーザーおよび動画の埋め込みをトレーニングするには、ユーザーが動画に高い評価を割り当てたユーザーと動画のペアを肯定的な例として、ユーザーが低い評価を割り当てたペアを否定的な例として使用することができます。ユーザーとムービーの両方に対して埋め込みベースのエンコーダーを使用することができ、いずれかの埋め込みはトレーニング後に対応するエンコーダーから直接読み取ることができます。
- サッカー選手の埋め込み: サッカーの試合での選手の埋め込みを学習するには、試合中に各選手が追跡されたフィールドの離散化された場所の時系列を使用して、肯定的な例として player-ID とペアにします。異なる player-ID とペアになった選手の追跡された場所のシーケンスは、否定的な例として役立ちます。
- 英文の埋め込み: 英語の文章の埋め込みを学習するには、ドキュメント内の隣接する文章のペアを肯定的なペアとして扱い、異なるドキュメントからサンプリングした文章のペアを否定的なペアとして扱います。ペアの両方の文章に対して、CNN または BiLSTM ベースのエンコーダーを使用できます。いったんトレーニングされると、いずれかのエンコーダーを使用して新しい文章の埋め込みを生成することができます。
このブログ記事では、Jupyter ノートブックの例 (動画のリコメンデーションシ、マルチラベルドキュメント分類、文章類似性) を使って、これらのユースケースのいくつかを詳しく説明します。
Object2Vec は教師あり学習アルゴリズムか?
アルゴリズムはトレーニングのためにラベル付けされたデータを必要とするため、Object2Vec が教師あり学習者であることは確かです。ただし、人間による明示的な注釈を使用することなく、純粋にデータの自然なクラスタリングから関係ラベルを得ることができるシナリオが多いことを強調したいと思います。前にいくつかの例を挙げましたが、分かりやすくするために以下のように繰り返します。
- 単語の埋め込みを学習するには、所定のドキュメント内の文脈ウィンドウに出現する単語のペアを肯定的なラベルを有する例とみなし、コーパス内のユニグラム分布からのサンプルとして得られる単語のペアは否定的なラベルを有する例とみなすことができます。
- 同様に、文章の埋め込みを学習するには、ドキュメント内で互いに隣接する文章のペアは「肯定的なラベル」を有する例と考えることができ、同じドキュメント内で共起しない文章のペアは「否定的なラベル」を有する例と考えることができます。
- 顧客の埋め込みを学習するには、所与の時間枠内で同じ顧客からの取引記録のペアを肯定的な例と考えることができ、2 つの異なる顧客からの取引のペアは否定的な例と考えることができます。
繰り返しになりますが、Object2Vec のアーキテクチャでは、トレーニング時に各ペアのオブジェクト間の関係を明示する必要がありますが、関係自体はデータの自然なグループ化から得ることができ、明示的な人間によるラベル付けは必要ありません。
ハイパーパラメータ
Object2Vec は、さまざまな要件を満たすトレーニングを微調整するための一連のハイパーパラメータをサポートしています。以下は、主なハイパーパラメータの一部です:
- Encoder network (network)– 「階層型 CNN」、「BiLSTM」、「プールされた埋め込み」を選択できます。 並列化によりトレーニングのスピードを速くしたい場合は、階層型 CNN を使用します。BiLSTM は、シーケンス内のトークン間の長距離依存関係をキャプチャする必要があるセンテンスなど、シーケンシャル入力でより良い結果を与えます。 プールされた埋め込みは、ある程度の精度低下を犠牲にした超高速トレーニング用に設計されています。
- Optimizer– 「adam」 、「adagrad」、 「rmsprop」、 「sgd」、「adadelta」の中から選択できます。
- Token embedding dimension (token_embedding_dim) – 入力レイヤーの次元。 これは、事前にトレーニングされた埋め込みを適用できるレイヤーです。
- Encoding dimension (enc_dim) – 入力の最終エンコーディングの次元であり、対応するエンコーダーの出力です。
- Early stopping tolerance and patience – これらのハイパーパラメータを使用して、いくつかのエポックでパフォーマンスの向上を測定することで、トレーニングの早期停止をコントロールします。
サポートされているハイパーパラメータの完全なリストについては、こちらを参照してください。
データ入力チャネル
他の Amazon SageMaker の組み込みアルゴリズムと同様に、Object2Vec はトレーニングデータチャネル、検証データチャネル、テストデータチャネルをサポートしています。また、事前にトレーニングされた埋め込みファイルとボキャブラリファイルを提供するための補助データチャネルも用意されています。事前にトレーニングされた埋め込みファイル (例えば、GloVe埋め込みファイル) を使用して、それぞれの token-id に対して事前にトレーニングされた埋め込みベクトルを持つ入力で、それぞれの integer-id を置き換えます。事前にトレーニングされた埋め込みを使用することで、入力レイヤーの情報に基づいた初期点から開始するので、アルゴリズムのトレーニングのウォームスタートになります。自然言語処理アプリケーションでは、(word2vec や GloVe などの) 事前にトレーニングされた埋め込みを複数の場所からダウンロードすることができます。それぞれの入力トークンに正しい埋め込みを確実に使用するために、入力の integer-id を単語にマップし、対応する事前にトレーニングされた埋め込みを検索するために使用される語彙辞書も提供する必要があります。語彙辞書は、単語と JSON 形式の対応する整数表現のマッピングです。次の例は、語彙ファイルの外観を示しています。
推論
モデルをトレーニングした後、トレーニングされたエンコーダーを使用して次の 2 つのモードで推論を実行することができます。
- シングルトン入力オブジェクトを、対応するエンコーダーを使用して固定長の埋め込みに変換する。
- 入力オブジェクトのペアの間での関係ラベルまたはスコアを予測する。
推論サーバーは、入力データに基づいて、これら 2 つのモードのどちらが要求されているかを自動的に判別します。埋め込みを出力として取得するには、関係のラベルやスコアを予測するためにはペアの両方の入力を提供するのに対し、それぞれのインスタンスに 1 つの入力だけを提供します。
コンピューティングについての推奨
現在、Object2Vec は単一のマシンでのみトレーニングを行うように設定されています。ただし、複数の GPU でのトレーニングをサポートしています。トレーニングについて、GPU は高いスループットを提供するので、モデルトレーニングのために GPU を使用することをお勧めします。推論では、CPU と GPU の間での通信にレイテンシーオーバーヘッドがないため、CPU をお勧めします。
パフォーマンス
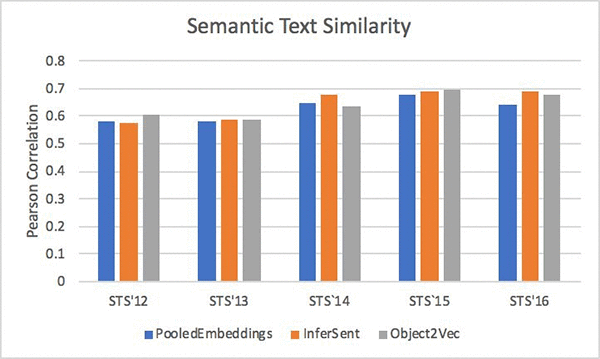
広範な種類の入力タイプに対する汎用の埋め込みアルゴリズムであるにもかかわらず、Amazon SageMaker Object2Vec は、何らかの目的向け専用の埋め込みアルゴリズムと同等のパフォーマンス結果をもたらします。さまざまなバージョンの Semantic Text Similarity (STS) データセットを使用したピアソン相関の比較については、Object2Vec を InferSent と呼ばれる最先端のモデルと比較している、以下を参照してください。
Object2Vec のユースケース
現在は、トークンのペア、シーケンスのペア、トークンとシーケンスのペアの埋め込みの学習をサポートしています。こうした表現の 1 つにマップできるユースケースはたくさんあります。次に、3 つの具体的なユースケースを見てみましょう。
- 協調リコメンデーションシステム
- マルチラベルドキュメント分類
- 文章埋め込み
トークンのペアによるトレーニング: 協調リコメンデーションシステム
協調フィルタリングは、リコメンデーションシステムを構築するための一般的な手法です。協調フィルタリングの背後にある主なコンセプトは、嗜好が類似しているユーザ (観察したユーザ – アイテム相互作用に基づく) は新しいアイテムに対して同様の相互作用を行う可能性が高いという考えです。Object2Vec は、ユーザーおよびアイテムの低次元表現を使用して、観察したユーザー – アイテムの相互作用を近似することによってリコメンデーションを行うことができます。
次の図は、ユーザーとアイテムの埋め込みを学習するためにユーザーとアイテムの相互作用のデータを使用する方法を示しています。結果として得られたモデルを使用して、新しいアイテムに関するユーザー評価を予測することができます。
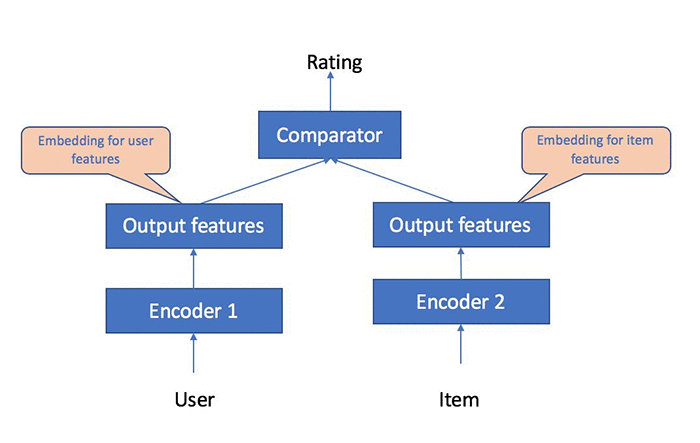
SageMaker Object2Vec を使用して協調リコメンデーションモデルを構築する方法については、このノートブックをご覧ください。 より具体的には、MovieLens データセットを使用して、以下の 2 種類の機械学習タスクを解決する方法を示します。
- タスク 1: 回帰問題としての評価の予測
- タスク 2: 分類問題としての動画のリコメンデーション
MovieLens データセットには、(ユーザー、動画) のペアデータとそれに対応する評価が含まれています。ユーザーに対応する integer-id が Object2Vec の 1 つのアームにフィードされ、動画に対応する integer-id が他のアームにフィードされます。ユーザと動画に別々の埋め込みベースのエンコーダーを使用してそれらを密な埋め込みに変換し、与えられた (ユーザー、動画) ペアの評価を予測するコンパレータに渡します。 最初に、ラベル付きトレーニングデータに基づいてユーザーと動画の埋め込みを学習する方法を示します。次に、学習した埋め込みを使用して、提供したテストセットで評価を予測する方法を示し、このモデルがオープンソースドメインで利用できる最良のツールのいくつかに匹敵する精度を達成していることを示します。 データ処理およびトレーニングのパイプラインの高レベルのロジックフローについては、次の図を参照してください。

データ処理および準備のステップでは、トレーニングデータファイル、検証データファイル、テストデータファイルを作成し、ファイルを Amazon S3 バケットにコピーします。 Amazon SageMaker Object2Vec は JSON ライン形式で入力を取るので、未加工の MovieLens データは後続のサンプルに似た形式に変換されます。 このサンプルでは、in0 はユーザー id を表し、in1 は動画 id を表し、ラベルは動画のユーザーによる動画の評価を表します。未加工のデータセットを使用してトレーニングデータセット、検証データセット、テストデータセットを作成します。トレーニング中、in0 の値は Object2Vec アルゴリズムの 1 つのアームにフィードされ、in1 は別のアームにフィードされます。
トレーニングのステップでは、タスク 1 とタスク 2 に必要なハイパーパラメータを設定します。回帰ジョブであるタスク 1 の場合、“output_layer” ハイパーパラメータを “mean_squared_error“ に設定し、タスク 2 では “output_layer” に “softmax” を使用します。 入力は個々のトークンであるため、両方のエンコーダーのネットワークを “pooled_embedding” に設定します。
Amazon SageMaker には、トレーニングやデプロイメントなどの SageMaker バックエンド操作との統合を容易にする Python SDK が用意されています。ここでは、Amazon SageMaker エスティメーターを使用してトレーニングを開始します。 評価予測 (回帰) ジョブを開始するための Amazon SageMaker Python SDK の構文については、次のコードサンプルを参照してください。
リコメンデーション (分類) ジョブを開始するためのコードサンプルについては、次を参照してください。
トレーニングジョブが実行されると、Amazon CloudWatch Logs および Jupyter ノートブックコンソールで、次のトレーニングおよび検証メトリクスが出力されます。
詳細な手順については、ノートブック全体を参照してください。
(one-hot ベクトルおよび one-hot ベクトルのシーケンス) のペアによるトレーニング: マルチラベルドキュメント分類
ドキュメントの分類とタグ付けは、特にビッグデータの時代には、多くの組織に共通のビジネス上の課題です。トピックのモデリングなどの教師なし機械学習アプローチや、マルチラベル分類などの教師あり機械学習アプローチがあります。トークンとシーケンスのペア入力をサポートできる Object2Vec の機能は、マルチラベルドキュメント分類問題に適しています。マルチラベル分類のトレーニングのために、ドキュメントとラベルのデータを Object2Vec にどのようにフィードすることができるかについては、次の図を参照してください。
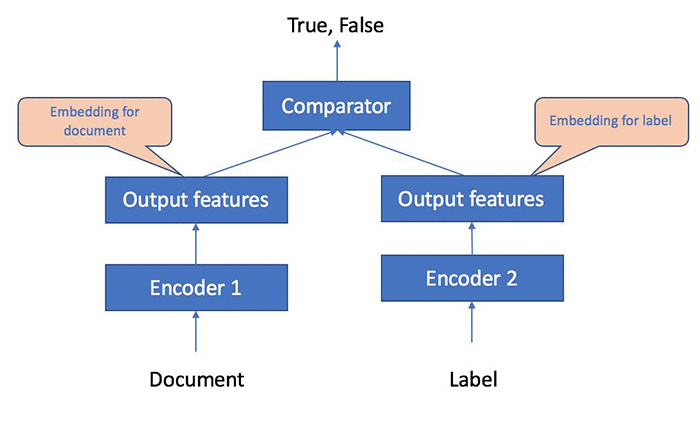
このノートブックの例では、トークン、シーケンスのペアで Object2Vec をトレーニングする方法を示します。検討する具体的なユースケースは、マルチラベルドキュメント分類です。この問題をモデル化するために、私たちのアーキテクチャの 1 つのアームは、word-id のシーケンスとして表現されたドキュメントを入力として受け入れます。他方のアームは、integer-id として表現されたドキュメントのカテゴリラベルを入力として受け入れます。マルチラベルドキュメントをドキュメント、ラベルのペアに変換し、それぞれのドキュメントはコーパス内のすべてのラベルと繰り返しペアリングされます。ドキュメントがグラウンドトゥルースデータの特定のラベルでタグ付けされている場合、(ドキュメント、ラベル) ペアに「肯定的」関係を適用します。それ以外の場合、ドキュメントとラベルのペアの関係は「否定的」とマークされます。 ドキュメントアームのエンコーダーは、可変長シーケンスを固定長の埋め込みに変換する CNN または BiLSTM です。ラベルアーム用のエンコーダーは、label-id を高密度の埋め込みに変換する簡単な埋め込みエンコーダーです。これら 2 つがコンパレータに渡され、コンパレータはドキュメントとラベルの間の 2 つの関係タイプに対するモデルの信頼に対応するスコアを出力します。
トレーニング時には、トレーニングデータに存在するすべての (ドキュメント、ラベル) ペアを「肯定的」な関係タイプに関連付け、ドキュメントがトレーニングデータ内にあるが、(ドキュメント、ラベル) ペアはドキュメントデータ内に出現しないような (ドキュメント、ラベル) のクロス積から「否定的」な関係タイプを有するペアをサンプリングします。同じドキュメントにマルチラベルがある場合、そのドキュメントに適用されるラベルごとに「肯定的」な関係を持つ一意な (ドキュメント、ラベル) ペアが生成されます。このような前処理は、マルチラベル付けされたドキュメント分類が複数の一対他分類器を使用して処理される方法と類似しています。
テスト時に、ドキュメント D が与えられると、このドキュメントを複数回 Object2Vec に渡します。そこで毎回、入力としてトレーニングセットの 1 つの一意のラベル L とペアになります。ペア (D,L) の「肯定的」な関係タイプのスコアが閾値より高ければ、ドキュメントに適用されるラベル L を受け入れます。
Object2Vec でマルチラベルドキュメント分類を実行する方法の詳細については、ノートブック全体を参照してください。
(トークンのシーケンス、トークンのシーケンス) のペアによるトレーニング: 文章類似性
文章類似性には多くの実用的なユースケースがあります。 たとえば、カスタマーサポートのワークフローでは、チケットに含まれるテキストの類似性に基づいて、重複したサポートチケットを識別したり、適切なサポートキューにチケットをルーティングする必要があります。文章/テキストの類似性が使用される別の例は、与えられた入力テキストについて、システムが類似しているテキストのリストを返す情報検索です。
埋め込みとしてのトークンのモデリングシーケンスは、自然言語以外の文脈でも関連します。たとえば、顧客の嗜好は、その顧客が最近に購入した product-id のシーケンスによってモデル化することができます。顧客が購入した product-id のシーケンスを肯定的なペアとし、異なる顧客が購入した product-id のシーケンスを否定的なサンプルとすることで、顧客の埋め込みを学習することができます。このようにして学習された埋め込みは、類似の顧客を見つけるために使用することができ、下流の教師ありタスクの特徴として使用することができます。
このノートブックでは、Object2Vec を使用して文章の埋め込みを生成し、文章の類似性の比較に使用する方法を示します。次の図は、埋め込みを学習するために文章のペアがどのようにして Object2Vec にフィードされるかを示しています。
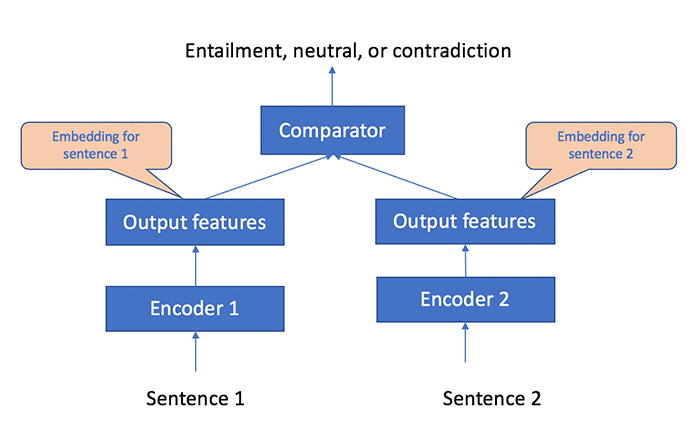
データ処理およびトレーニングのパイプラインの高レベルのロジックフローを次の図に示します。
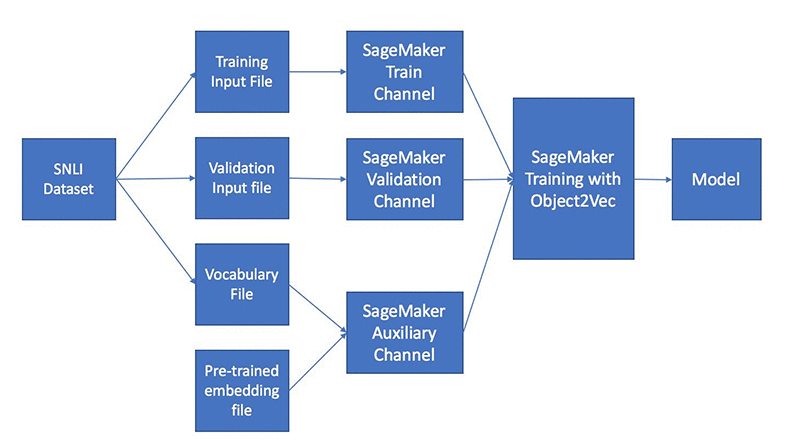
トレーニングデータについては、「entailment」、「neutral」、「contradiction」というラベルが付いた文章のペアからなるスタンフォード自然言語推論 (SNLI) データセットを使用します。 モデルをトレーニングした後、トレーニングされたモデルを使用して、英語の文章を固定長の埋め込みに変換することができます。SNLI データセットのホールドアウトテストデータセットを使用して、モデルの品質を測定します。ノートブックでは、Semantic Text Similarity (STS) データセットからの埋め込みスペースにおける文章ペアの類似性を比較し、それを人間がラベル付けしたグラウンドトゥルースと比較することによって、新しい文章での埋め込みの質も測定します。
SNLI データは、次のサンプルデータで示される JSON ライン構造に事前処理されるため、Object2Vec アルゴリズムで使用することができます。 このサンプルでは、in0 と in1 は、それぞれ文章の中の単語を表す整数と、2 つの文章の間の関係 (含意、中立、矛盾) を表すラベルがある 2 つの文章を表します。
この文章の類似性モデルをトレーニングすることは、Amazon SageMaker の組み込みアルゴリズムを使用して他のモデルをトレーニングする場合と同じです。 最初に、トレーニングデータ、検証データ、および語彙ファイル用の補助データと事前にトレーニングされた埋め込みファイル用のチャネルを含むデータチャネルを定義します。 次に、必要なトレーニングハイパーパラメータを設定し、Amazon SageMaker エスティメーターを使用してトレーニングジョブを開始します。 Amazon SageMaker エスティメーターを使用してトレーニングジョブを開始する場合の構文については、次のサンプルコードスニペットを参照してください。
トレーニングジョブが実行されると、各エポックが実行されるたびに次のパフォーマンスメトリクスが Amazon CloudWatch Logs に、および Jupyter ノートブックコンソールに直接表示されます。
埋め込みパイプラインの実行に関する詳細な手順についてはノートブック全体を確認し、STS データセットを使用して文章の類似性を測定する方法については、追加のコードサンプルを参照してください。
結論
このブログ記事では、新しい Amazon SageMaker Object2Vec アルゴリズムを紹介しました。この記事と付属のノートブックでは、Object2Vec の仕組みや、さまざまな実用的なビジネスユースケースにどのように適用できるかを紹介しています。
著者について
 David Ping は、AWS ソリューションアーキテクト部の、プリンシパルソリューションアーキテクトです。AWS を使ったクラウドと機械学習ソリューションを構築し、お客様をサポートしています。ニューヨークの中心部に暮らしながら、最新の機械学習テクノロジーを楽しく学んでいます。
David Ping は、AWS ソリューションアーキテクト部の、プリンシパルソリューションアーキテクトです。AWS を使ったクラウドと機械学習ソリューションを構築し、お客様をサポートしています。ニューヨークの中心部に暮らしながら、最新の機械学習テクノロジーを楽しく学んでいます。
 Patrick Ng は、AWS AI の業種およびアプリケーショングループのソフトウェア開発エンジニアです。ディープニューラルネットワークと自然言語処理の分野を中心に、スケーラブルな分散機会学習アルゴリズムの構築に取り組んでいます。 Amazon に来る前は、コーネル大学でコンピュータサイエンスの博士号を取得し、機械学習システムを構築するスタートアップ企業にいました。
Patrick Ng は、AWS AI の業種およびアプリケーショングループのソフトウェア開発エンジニアです。ディープニューラルネットワークと自然言語処理の分野を中心に、スケーラブルな分散機会学習アルゴリズムの構築に取り組んでいます。 Amazon に来る前は、コーネル大学でコンピュータサイエンスの博士号を取得し、機械学習システムを構築するスタートアップ企業にいました。
 Cheng Tang は、AWS AI の業種およびアプリケーショングループのアプライドサイエンティストです。機械学習の研究とその自然言語処理分野への応用に幅広く興味を持っている、Cheng は機械学習/深層学習アルゴリズムの研究と産業化の両方に貢献することに大きな魅力を感じており、それらが顧客に届くのを見て非常に喜んでいます。
Cheng Tang は、AWS AI の業種およびアプリケーショングループのアプライドサイエンティストです。機械学習の研究とその自然言語処理分野への応用に幅広く興味を持っている、Cheng は機械学習/深層学習アルゴリズムの研究と産業化の両方に貢献することに大きな魅力を感じており、それらが顧客に届くのを見て非常に喜んでいます。
 Saswata Chakravarty は、AWS アルゴリズムチームのソフトウェアエンジニアです。彼は迅速かつスケーラブルなアルゴリズムを Amazon SageMaker に導入し、顧客にとって使い易くすることに取り組んでいます。
Saswata Chakravarty は、AWS アルゴリズムチームのソフトウェアエンジニアです。彼は迅速かつスケーラブルなアルゴリズムを Amazon SageMaker に導入し、顧客にとって使い易くすることに取り組んでいます。
 Ramesh Nallapati は、AWS AI の業種およびアプリケーショングループの上級アプライドサイエンティストです。主に自然言語処理の分野で、大規模な新しいディープニューラルネットワークの構築に取り組んでいます。深層学習に情熱を注いでおり、AI の最新動向を楽しく学んでいます。また、この分野で貢献できることに興奮しています。
Ramesh Nallapati は、AWS AI の業種およびアプリケーショングループの上級アプライドサイエンティストです。主に自然言語処理の分野で、大規模な新しいディープニューラルネットワークの構築に取り組んでいます。深層学習に情熱を注いでおり、AI の最新動向を楽しく学んでいます。また、この分野で貢献できることに興奮しています。
 Bing Xiang は、AWS AI の業種およびアプリケーショングループのプリンシパルサイエンティスト兼責任者です。彼は、さまざまな AWS のサービスのために深層学習、機械学習、自然言語処理に取り組んでいるサイエンティストおよびエンジニアのチームを率いています。
Bing Xiang は、AWS AI の業種およびアプリケーショングループのプリンシパルサイエンティスト兼責任者です。彼は、さまざまな AWS のサービスのために深層学習、機械学習、自然言語処理に取り組んでいるサイエンティストおよびエンジニアのチームを率いています。
謝辞
AI プラットフォームチームのソフトウェア開発エンジニアである Orchid Majumder によるこのプロジェクトの初期での貢献、ならびに Amazon AI ラボの Algorithms&Platforms グループのグループマネージャーである Laurence Rouesnel と AI プラットフォームチームの上級プリンシパルエンジニアである Leo Dirac から専門的な助言と指導を受けたことに感謝の意を表します。