Amazon Web Services ブログ
Amazon Forecast を使用して正確なエネルギー消費量を予測する
Amazon Forecast は、機械学習 (ML) により、それまでの機械学習経験を待つことなく、非常に正確な予測を生成できる完全マネージド型サービスです。Forecast は、エネルギー需要の予測、製品需要の見積り、人事計画、クラウドインフラストラクチャの使用状況の算定など、さまざまなユースケースに使用できます。
Forecast では、プロビジョニングするサーバーや手動で構築する機械学習モデルはありません。また、使用した分だけお支払いいただくようになっており、最低料金や前払い料金を求められることはありません。Forecast を使用するために必要なことは、予測対象の履歴データをご提供いただくことだけです。オプションとして、予測に影響を与えると思われる追加データもご提供ください。この関連データには、価格、行事、天候など、時により変化するデータと、色、ジャンル、リージョンなどカテゴリに関するデータの、両方が含まれます。このサービスでは、お手元のデータに基づいて機械学習モデルを自動的にトレーニングし、デプロイして、予測を取得するためのカスタム API を提供します。
電力会社と公益事業会社にはいくつかの予測ユースケースがありますが、中でも主なものは、顧客レベルと集計レベルの両方でエネルギー消費量を予測することです。エネルギー消費を正確に予測することにより、顧客がサービスを中断せず、低価格で安定したグリッドシステムを提供することができます。
この記事では、Forecast を使用して、過去の時系列データを気象などの重要な外生変数と組み合わせることにより、このユースケースに対処する方法について説明します。
ユースケースの背景
電力会社が日常業務を効率的に行うには、正確なエネルギー予測が不可欠です。需要は動的であり、季節による気象変化が影響を与える可能性があるため、エネルギー予測は特に困難です。最も一般的な 2 つのユースケースを次に示します。
- 消費者レベルでの電力消費量予測 – 多くの国では、電力は競争の激しい小売市場によって提供されています。消費者には電気を購入するという選択肢があり、高額の電気代を受け取るプロバイダーや、顧客体験が悪いプロバイダーを切り替えることができます。公益事業会社は、顧客サービスを改善し、将来の支出アラートを積極的に利用することで、顧客のチャーンを減らすことができます。これらのアラートは、個々の顧客レベルでの電力消費を正確に予測することに基づいています。
- 需要と供給をより適切に管理するための総消費電力予測 – 電力会社として、総需要と総需要のバランスをとる必要があります。ピーク需要を満たすためにエネルギーを購入したり、スポットマーケットで余剰容量を販売したりすることがよくあります。さらに、需要予測は次のような課題に直面しています。
- 風力や太陽光などの再生可能エネルギー資源の導入。これらは電力会社と最終消費者の両方が所有しており、天候の変化による影響を受けやすく、常に安定した電力を生成するわけではありません。
- 電気自動車の購入が増え、自動車の所有者が自宅で電気自動車を充電したいという未知の性質。予測の改善により、より費用対効果の高い先物契約を構築するための事前計画が可能になります。
この記事では、消費者レベルで、最初のユースケースのソリューションに焦点を当てています。
最初の手順では、データをセットアップして準備します。データレイクは、ユーティリティにとって革新的であることが証明されています。データウェアハウスは、既に特定の目的で処理された構造化およびフィルター済みデータのリポジトリです。対照的に、データレイクは、必要になるまでネイティブ形式で膨大な量の未加工データを保持するストレージリポジトリです。これは、何百万もの顧客からのメーターの読み取り値を収集、保存、処理する電力会社や公益事業会社にとって非常に価値があります。
ソリューションのアーキテクチャ
次の図は、顧客に請求アラートを表示するために実装できるソリューションのアーキテクチャを示しています。
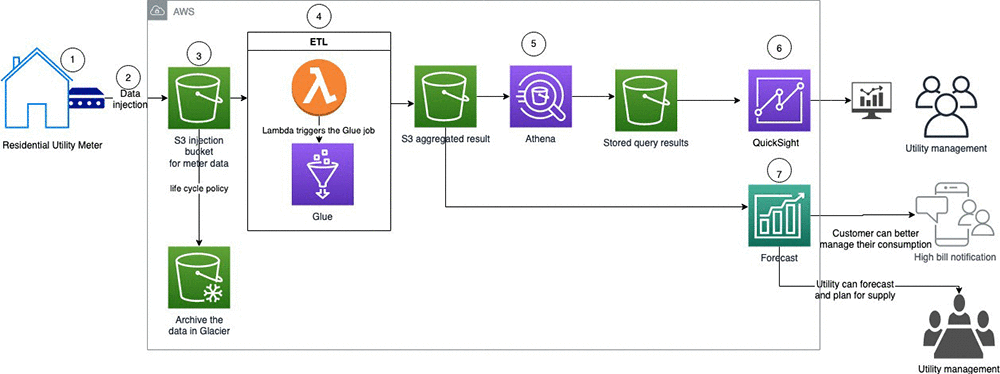
アーキテクチャには次の手順が含まれます。
- 住宅の公益事業メーターは、通常、エネルギーを 1 時間に 1 回以上記録し、少なくとも毎日、電力会社に報告します。
- さまざまなチャネルを介してデータの取り込みを実装できます。オンプレミスのデータセンターでデータを収集する場合、AWS Direct Connect を介して AWS にデータを送信できます。メーターに IoT 機能がある場合、MQTT トピックを介してデータを AWS IoT Core に送信できます。MQTT は、マシンツーマシン (M2M)/IoT 接続プロトコルです。軽量のパブリッシュおよびサブスクライブメッセージングトランスポートとして設計されました。これは、小さなコードフットプリントを必要とする、またはネットワーク帯域幅が貴重なリモートロケーションでの接続に役立ちます。
- Amazon S3 を使用して未加工のメーターデータを保存します。AmazonS3 ベースのデータレイクソリューションは、Amazon S3 をプライマリストレージプラットフォームとして使用します。Amazon S3 は、無制限のスケーラビリティにより、データレイクに最適な基盤を提供します。ストレージをギガバイトからペタバイトにシームレスに増やし、使用した分に対してのみお支払いいただきます。Amazon S3 は、99.999999999% の耐久性を提供するように設計されています。ライフサイクルポリシーを導入して、データを Amazon S3 Glacier にアーカイブすることができます。詳細については、最大限の柔軟性を実現するためのビッグデータストレージソリューション (データレイク) の構築を参照してください。
- 取り込まれたデータは、未加工ゾーンと呼ばれる S3 バケットに格納されます。データが使用可能になると、Amazon S3 トリガーが AWS Lambda 関数を呼び出し、データを処理して、処理済みゾーンと呼ばれる別の S3 バケットにデータを移動します。
- Amazon Athena を介して Amazon S3 のデータをクエリできます。Athena は、標準 SQL を使用して Amazon S3 で直接データを分析できるようにするインタラクティブなクエリサービスです。Athena は、Amazon S3 で指定できるクエリ結果の場所で実行される各クエリのクエリ結果とメタデータ情報を自動的に保存します。
- Amazon QuickSight でクエリ結果バケットにアクセスできます。Amazon QuickSight は、視覚化の構築、アドホック分析の実行、およびデータからのビジネスインサイトの取得に使用できるビジネス分析サービスです。AWS データソースを自動的に検出し、データソースを操作することもできます。
- Amazon S3 からの処理済みデータを使用して、Forecast で予測を行うことができます。住宅用顧客は、これらの結果を使用して将来のエネルギー消費量を確認できます。これにより、エネルギーコストを計算し、より効率的な料金プランに変えたり、必要に応じて将来の使用量を変更したりできます。クエリ API を使用してモバイルまたはウェブアプリケーションと統合し、顧客に将来の需要を可視化して、消費を促進することができます。Forecast 関連のワークフロー自動化については、Lambda、Step Functions、CloudWatch Events ルールで Amazon Forecast ワークフローを自動化するを参照してください。
予測の設定
この記事では、個別の顧客レベルでエネルギー消費量を予測する 2 つの異なるアプローチを評価しています。1 つは関連する時系列情報がなく、もう 1 つには関連する時系列データがあります。
問題を予測する場合、関連する時系列は変数 (天気や価格など) であり、目標値と相関し、統計的強度を目標値 (この記事ではエネルギー需要) の予測に使用します。正確に言うと、Forecast は関連する時系列を外生変数として扱います。これらの変数はモデル仕様の一部ではありませんが、それらを使用して、関連する時系列の現在の値とターゲットの時系列の対応する値の間の相関をキャプチャできます。
関連する時系列を組み込むことにより、常に精度が向上するわけではありません。したがって、関連する時系列の追加はすべて、バックテストに基づいて全体の精度が改善されているか、または追加によって精度が変更されていないかを確認する必要があります。予測には関連する時系列は必要ありませんが、目標時系列が必要です。関連する時系列に欠損値またはその他の品質の問題がある場合、モデルにノイズが混入しないように、その時系列を含めない方が良い場合があります。基本的に、どの関連する時系列が有用か、または時系列を効果的に使用する方法を決定することは、主要機能のエンジニアリングタスクです。
詳細については、関連する時系列データセットの使用を参照してください。
ARIMA を使用したエネルギー消費量予測モデルの作成
自己回帰和分移動平均 (ARIMA) は、時系列の古典的な統計モデルです。時系列値を、遅れた値と予測誤差の線形結合で表現することにより、過去の値を使用して未来を説明します。ARIMA は、説明変数付きの自己回帰和分移動平均 (ARIMAX) モデルで、または関連する時系列変数や回帰変数なしで使用できます。ARIMA モデルを適用する場合、適切なモデルの順序を選択する作業は主観的なプロセスを手動で行うため、難しい場合があります。予測では、auto.arima を使用して、データに最適な ARIMA モデルを自動的に見つけます。
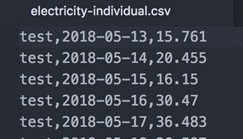
使用される入力データは、個々のエネルギー消費データです。これは、<CustomerID>、<日付>、および <エネルギー消費量> の 3 つの属性を持つ CSV ファイルです。エネルギー消費量の単位は kWh (キロワット時) です。この記事は 557 日間の履歴データを毎日使用しますが、業界ではより一般的な毎時のデータを簡単に使用できます。Forecast がサポートする周波数の詳細については、FeaturizationConfig を参照してください。選択した S3 バケットにデータファイルをアップロードします。
次のスクリーンショットは、顧客データのスナップショットの例を示しています。
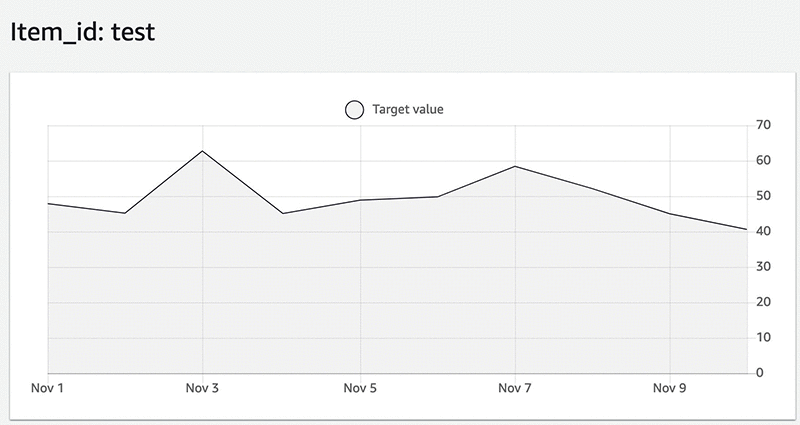
次のグラフは、そのサンプルデータを視覚化したものです。
リソース作成の詳細については、Amazon Forecast – 一般公開を参照してください。主な手順は次のとおりです。
- Amazon Forecast コンソールで、[データセットグループを作成] を選択します。
- 名前と予測ドメインを入力します。
- ターゲットの時系列データセットを指定します。
Item_idは、ユーティリティの<CustomerID>です。timestampは日付<YYYY-MM-DD>であり、これは毎日の消費量データです。Target_valueは、消費されるエネルギーです。
- 履歴データをインポートするインポートジョブを作成します。CSV ファイルがアップロードされている S3 バケットに IAM ロールがアクセスできることを確認します。
- データをインポートすると、ターゲットの時系列データのステータスがアクティブとして表示されます。
- ダッシュボードの [予測トレーニング] で、[開始] を選択します。
- この記事では ARIMA アルゴリズムを使用しています。
- 予測変数のトレーニングが完了すると、ダッシュボードのステータスがアクティブとして表示されます。
- 予測を作成します。
予測を正常に作成した後、特定のカスタマー ID についてクエリを実行するか、エクスポートジョブを実行してすべてのカスタマー ID の結果を生成できます。次のスクリーンショットは、ID テストの予測エネルギー消費量を示しています。
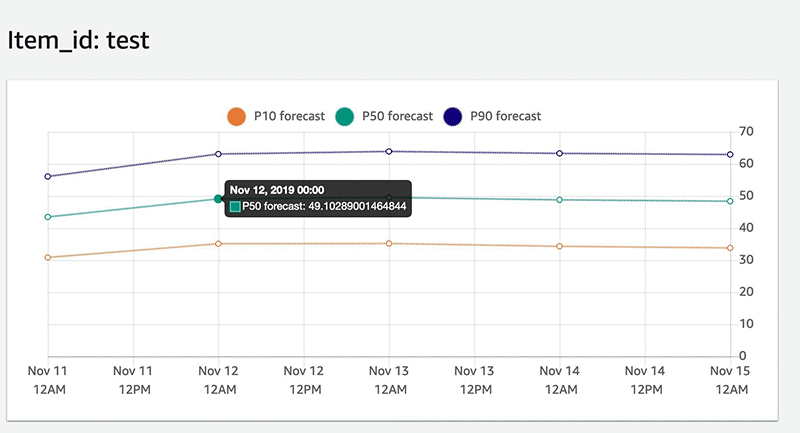
このチュートリアルには温度などの要素は含まれていませんでしたが、開始後にターゲットの時系列データを使用してベースラインモデルを確立するための優れた方法です。また、公益事業会社の総需要と総供給を満たすために、すべての顧客データを潜在的に集計し、将来の消費を予測して、それに応じて供給を計画することができます。
DeepAR+ を使用したエネルギー消費量予測モデルの作成
Forecast DeepAR+ アルゴリズムは、再帰型ニューラルネットワーク (RNN) を使用してスカラー (1 次元) 時系列を予測するための教師あり学習アルゴリズムです。ARIMA や指数平滑法 (ETS) などの従来の予測方法では、単一のモデルを個々の時系列に適合させます。対照的に、DeepAR+ は、時系列全体で学習する潜在的な利点を備えたグローバルモデル (すべての時系列に対して 1 つのモデル) を作成します。
DeepAR+ モデルは、特定の時系列の情報量が限られている、ターゲットの時系列の大規模なコレクション (数千以上) を操作する場合に特に役立ちます。たとえば、各世帯のエネルギー消費量を予測するために、DeepAR+ などのグローバルモデルは、さらに有益な統計的強みを使用して、新しい世帯をより良く予測できます。さらに、DeepAR+ は関連する時系列を考慮することができるため、予測を改善できます。
このユースケースは、エネルギー消費との相関関係を考慮して、気象データを追加します。主な手順は次のとおりです。
- 新しいデータセットインポートジョブを作成して、関連する時系列データでデータセットグループを更新します。このモデルでは、次のフィールド (
timestampとCustomerIDは除く) を考慮しました。dayofweekdailyaveragedrybulbtemperaturedailycoolingdegreedaysdailydeparturefromnormalaveragetemperaturedailyaveragenormaltempdailyheatingdegreedaysdailymaximumdrybulbtemperaturedailyminimumdrybulbtemperaturelength_of_day_hours
次の表は、シアトルの公共気象情報源からのデータ (このデータセットの顧客がその都市に居住している場合) をまとめたものです。
dayofweek dailyaveragedrybulbtemperature dailycoolingdegreedays dailydeparturefromnormalaveragetemperature dailyaveragenormaltemp dailyheatingdegreedays dailymaximumdrybulbtemperature dailyminimumdrybulbtemperature Length_of_Day_Hours 7 53 0 -3.1 56.1 12 60 46 15.03 1 55 0 -1.3 56.3 10 60 49 15.08 2 51 0 -5.5 56.5 14 55 47 15.12 3 50 0 -6.7 56.7 15 53 46 15.15 4 53 0 -3.9 56.9 12 60 46 15.2 5 57 0 -0.1 57.1 8 64 50 15.25 6 62 0 4.7 57.3 3 73 50 15.28 7 64 0 6.5 57.5 1 72 56 15.32 1 64 0 6.3 57.7 1 76 51 15.35 2 69 4 11.1 57.9 0 82 55 15.4 3 67 2 8.9 58.1 0 81 53 15.43 - 更新されたデータセットを使用して新しい予測を作成します。
- 新しいモデルを生成します。
- 新しい予測を作成します。
次のスクリーンショットは、新しいモデルを使用した同じテストカスタマー ID の予測エネルギー消費量を示しています。
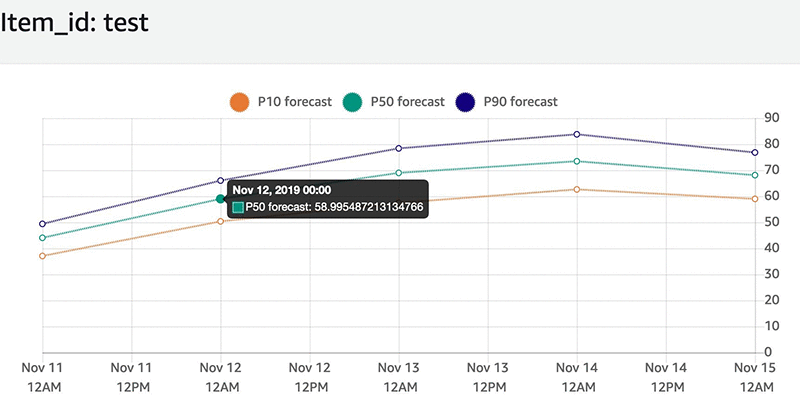
2 つのモデル (ARIMA および DeepAR+ と関連する時系列) の結果を、5 日間の予測範囲 (この記事では、2019 年 11 月 11 日から 2019 年 11 月 15 日) にわたる実際のエネルギー消費量で評価できます。
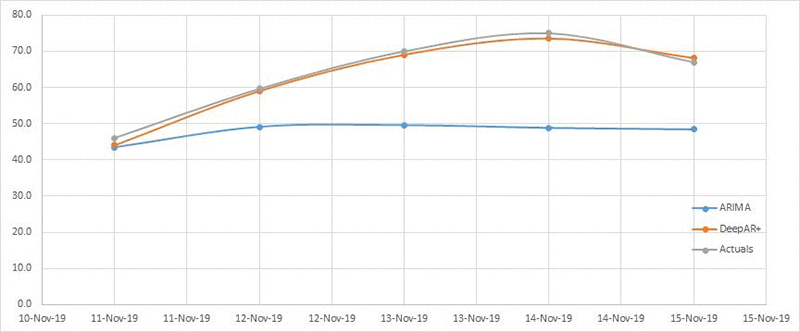
この評価を行うには、wQL[0.5]/MAPE メトリックを使用します。ARIMA で計算された MAPE メトリックは 0.25 ですが、気象データを含む DeepAR+ モデルの MAPE は 0.04 です。モデルの評価については、こちらをご覧ください。気象を含む DeepAR+ モデルで、モデルの精度を 84% 向上させました。次の表は、この比較内容を詳しくまとめたものです。
| 日付 | ARIMA (kWh 単位) | DeepAR+ (kWh 単位) | 実際のエネルギー消費量 (kWh 単位) |
| 2019 年 11 月 11 日 | 43.5 | 44.1 | 46 |
| 2019 年 11 月 12 日 | 49.1 | 59 | 59.6 |
| 2019 年 11 月 13 日 | 49.5 | 69 | 70 |
| 2019 年 11 月 14 日 | 48.8 | 73.5 | 75 |
| 2019 年 11 月 15 日 | 48.4 | 68.1 | 67 |
次のグラフは、比較したデータを視覚化したものです。
まとめ
この記事では、スマートメーターデータを使用して各顧客のエネルギー需要を予測するために、Forecast とその基盤となるシステムアーキテクチャを使用する方法について説明しました。DeepAR+ と気象データを使用してモデルの精度を高め、約 96% の予測精度を達成できます (MAPE により決定) 。
著者について
 Neelam Koshiya は AWS のエンタープライズソリューションアーキテクトです。現在、彼女は、戦略的ビジネス成果のためにクラウドを導入して企業顧客を支援することに焦点を当てています。余暇には、読書やアウトドアを楽しんでいます。
Neelam Koshiya は AWS のエンタープライズソリューションアーキテクトです。現在、彼女は、戦略的ビジネス成果のためにクラウドを導入して企業顧客を支援することに焦点を当てています。余暇には、読書やアウトドアを楽しんでいます。
 Rohit Menon はシニアプロダクトマネージャーで、現在は AWS で Amazon Forecast の製品の陣頭指揮をとっています。現在は、機械学習を使用して時系列予測を民主化することに取り組んでいます。余暇はドキュメンタリーを読んだり見たりしています。
Rohit Menon はシニアプロダクトマネージャーで、現在は AWS で Amazon Forecast の製品の陣頭指揮をとっています。現在は、機械学習を使用して時系列予測を民主化することに取り組んでいます。余暇はドキュメンタリーを読んだり見たりしています。
 Yuyang (Bernie) Wang は、Amazon AI ラボのシニア機械学習サイエンティストです。主に、大規模な確率的機械学習の予測アプリケーションについて研究しています。彼の研究対象は、統計的機械学習、数値線形代数学、ランダム行列理論におよびます。予測分野における Yuyang の研究は、実践的なアプリケーションから基礎理論までの、あらゆる側面をカバーしています。
Yuyang (Bernie) Wang は、Amazon AI ラボのシニア機械学習サイエンティストです。主に、大規模な確率的機械学習の予測アプリケーションについて研究しています。彼の研究対象は、統計的機械学習、数値線形代数学、ランダム行列理論におよびます。予測分野における Yuyang の研究は、実践的なアプリケーションから基礎理論までの、あらゆる側面をカバーしています。