Amazon Web Services ブログ
新しい Amazon Redshift コンソールでクエリをモニタリングおよび最適化する
数万人ものお客様が Amazon Redshift を使用してワークロードを強化し、ビジネスインテリジェンス、予測分析、リアルタイムストリーミング分析などの最新の分析ユースケースを実現しています。管理者やデータエンジニアにとって、データアナリストや BI プロフェッショナルなどのユーザーが最適なパフォーマンスを得ることは重要です。Amazon Redshift コンソールで、クエリのパフォーマンスに関する問題をモニタリングおよび診断できます。
Amazon Redshift マネジメントコンソールには、Amazon Redshift クラスターを作成、管理、モニタリングするためのダッシュボードや更新したフローをモニタリングする機能があります。詳細については、「Simplify management of Amazon Redshift clusters with the Redshift console」をご参照ください。
この投稿では、新しい Amazon Redshift コンソールを使用してユーザークエリをモニタリングし、低速クエリを特定し、暴走するクエリを終了する方法について説明します。クエリプラン、クエリの実行の詳細、低速クエリを最適化するためのインプレースでの推奨事項、Advisor による推奨事項を使用してクエリのパフォーマンスを向上させる方法などの詳細も解説します。
ユーザークエリと書き換えられたクエリ
ユーザーが Amazon Redshift に送信するクエリはすべてユーザークエリです。アナリストがユーザークエリを作成するか、Amazon QuickSight や Tableau などの BI ツールがクエリを生成するかのいずれかです。Amazon Redshift は通常、最適化のためにクエリを書き換えます。Amazon Redshift で、ユーザークエリを単一のクエリに書き換えたり、複数のクエリに分割したりできます。これらのクエリは書き換えられたクエリです。
次の手順は、Amazon Redshift が各クエリに対して実行します。
- リーダーノードがクエリを受信して解析します。
- パーサーは元のクエリの論理表現である最初のクエリツリーを生成します。Amazon Redshift はこのクエリツリーをクエリオプティマイザに入力します。
- オプティマイザはクエリを評価し、必要に応じてクエリを書き換えて効率を最大化します。このプロセスにより、単一のクエリを置き換える複数のクエリが作成されることがあります。
クエリの書き換えは自動的に行われるので、ユーザーが気づくことはありません。
元の Amazon Redshift コンソールとシステムテーブルを使用したクエリモニタリング
以前は、元の Amazon Redshift コンソールまたはシステムテーブルで書き換えられたクエリのパフォーマンスをモニタリングできました。しかし、ユーザーが送信した SQL を見つけるのは、たいてい大変な作業でした。
次のテーブルは、元の Amazon Redshift コンソール、システムテーブル、および新しいコンソールでのクエリモニタリングの違いを比較したものです。
| 元のコンソール | システムテーブル | 新しいコンソール |
|
• ユーザークエリのサポートなし • 書き換えられたクエリのみをモニタリング • 上位 100 件のクエリのみを表示 |
• ユーザークエリのサポートは使用不可 • 書き換えられたクエリ • すべてが書き換えられたクエリ |
• ユーザークエリのサポートあり • システムテーブルで使用可能なすべてのクエリを表示 • 書き換えられたクエリをユーザークエリと関連付けることが可能 |
新しいコンソールは、ユーザークエリのモニタリングを簡素化し、システムで利用可能なすべてのクエリモニタリング情報を表示します。
クエリのモニタリングと診断
Amazon Redshift コンソールは、クラスターで実行しているクエリのパフォーマンスに関する情報を提供します。この情報を使用すれば、処理に時間がかかったり、他のクエリの効率的な実行を妨げる障害を作成したりするクエリを識別および診断できます。
次のテーブルは、クエリのパフォーマンスに関する問題をモニタリング、分離、診断する際によくある質問の一部です。
| モニタリング | 分離と診断 | 最適化 |
| クエリのパフォーマンスとリソースの使用率に関して、クラスターはどのように動作しますか? | ユーザーが特定の時間でのパフォーマンスに満足しませんでした。SQL と診断に関する問題を特定するにはどうすればよいですか? | エンドユーザーが作成した SQL を最適化するにはどうすればよいですか? |
| クラスターのスループット、同時実行、レイテンシーをどう思いますか? |
クエリが遅いときに実行していた他のクエリはどれですか? すべてのクエリが低速でしたか?
|
スキーマの設計で必要な最適化はありますか? |
| クエリがクラスター内のキューに入っていますか? | 他のユーザーからのクエリで、データベースが過負荷になっていますか? キューの深さが増減していますか? | WLM キューに必要な調整はありますか? |
| 現在、どのクエリまたは読み込みを実行していますか? | 特定のユーザーが実行するクエリを特定するにはどうすればよいですか? | 並列スケーリングを有効にすると、何かメリットがありますか? |
| 通常のタイミングよりも時間がかかるクエリまたは読み込みはどれですか? | クラスターのリソースの使用量が非常に高くなっています。実行中のクエリを確認するにはどうすればよいですか? | |
| 過去 1 時間または過去 24 時間での、期間別の上位クエリはどれですか? | ||
| 失敗したクエリはどれですか? | ||
| クラスターの平均クエリレイテンシーは、時間の経過とともに増加または減少していますか? |
これらの質問に答えるには、Amazon Redshift コンソールを使用するか、システムカタログを使ってスクリプトを開発します。
クエリのモニタリング
Amazon Redshiftコンソールの「クエリと読み込み」ページ、または [クエリモニタリング] タブ (「クラスター」ページにある) でクエリをモニタリングできます。クエリモニタリングのオプションはどちらも同じようなもので、「クエリと読み込み」ページですべてのクラスターのクエリにすばやくアクセスできます。クエリを表示するには、クラスターと期間を選択する必要があります。

[ビューの一覧] ([クエリモニタリング] タブ、「クラスター」ページ) でクエリを表示できます。「クエリモニタリング」ページには、クエリがガントチャートで視覚的に表示されます。
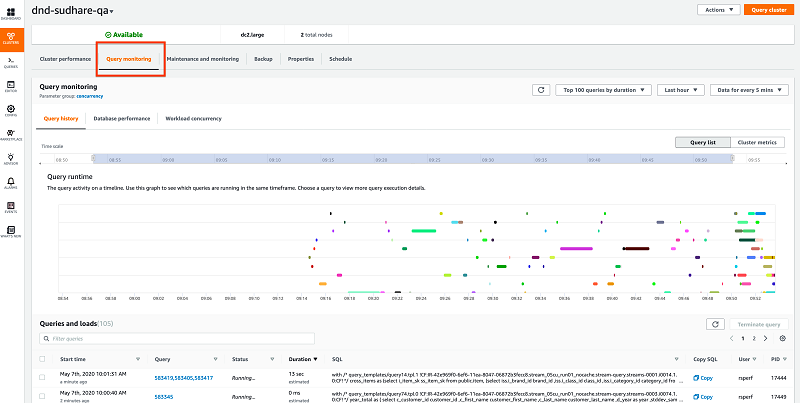
各バーはユーザークエリを表し、バーの長さはクエリのランタイムを表します。X 軸は選択した期間を示し、バーの位置はクエリの開始と終了を示します。クエリには、SELECT、INSERT、DELETE などの標準 SQL ステートメントと、COPY コマンドなどの読み込みの両方が含まれます。
上位クエリのモニタリング
デフォルトでは「クエリモニタリング」ページに、選択した時間ウィンドウのランタイムまたは期間ごとでの最長クエリの上位 100 個が表示されます。時間ウィンドウを変更すれば、その期間の上位クエリを表示できます。上位のクエリには、完了したクエリと実行中のクエリも含まれます。完了したクエリは、クエリのランタイムまたは期間の降順で並べ替えられます。
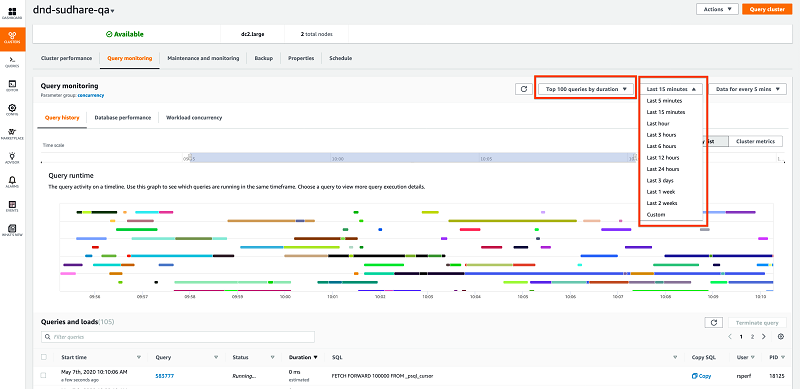
実行中のクエリの特定
ドロップダウンメニューから [実行中のクエリ] を選択すると、実行中のクエリを確認できます。

SQL テキスト、ランタイムの詳細、関連する書き換えられたクエリ、実行の詳細など、クエリの詳細を表示するには、クエリ ID を選択します。
期間列には、クエリの推定期間とランタイムが表示されます。クエリを選択して [クエリの終了] をクリックすると、クエリを終了できます。クエリをキャンセルするには、redshift:CancelQuerySession アクションを IAM ポリシーに追加する必要があります。
読み込みの表示
データエンジニアまたは Redshift 管理者にとって、読み込みジョブを正しく完了し、必要とされるパフォーマンス SLA を確実に満たすことは、重要な優先事項です。
[読み込み] を「クエリのモニタリング」ページのドロップダウンメニューから選択すると、すべての読み込みジョブを表示できます。その後、目的の時間ウィンドウにズームインできます。
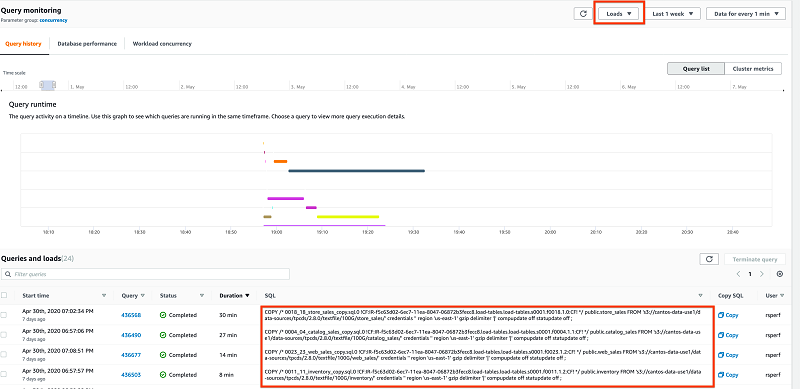
上記のガントチャートは、すべての読み込みが正常に完了したことを示しています。クエリのステータスは、読み込みが失敗したか、管理者が読み込みを終了したかを示しています。
失敗したクエリの特定
[失敗したまたは停止したクエリ] を「クエリモニタリング」ページのドロップダウンメニューから選択し、目的の時間にズームインすることで、失敗したクエリを特定できます。
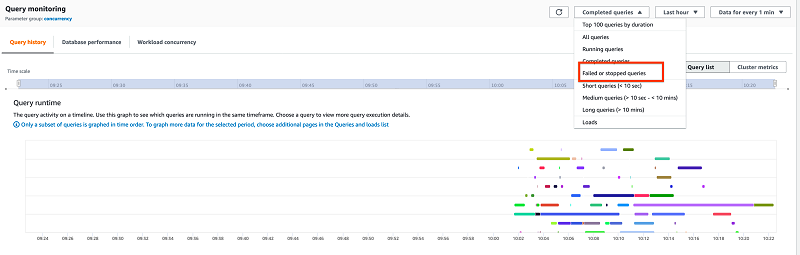
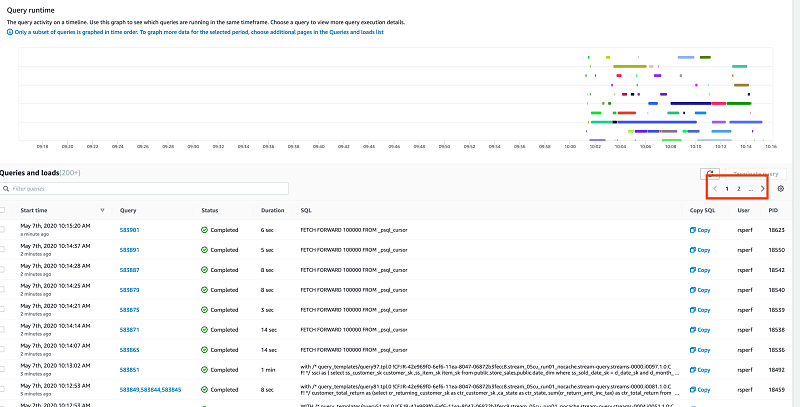
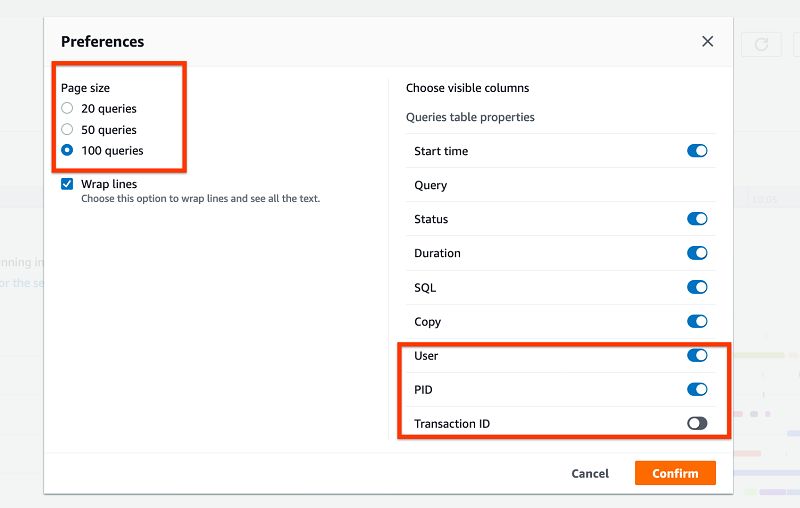
クエリページにはデフォルトで 50 個のクエリが表示されます。さらに結果を表示するには、ページ分割する必要があります。設定の歯車アイコンを選択すると、ページサイズを変更できます。

[設定] セクションで、[クエリと読み込み] リストに表示するフィールドをカスタマイズできます。たとえば、トランザクション ID ではなく PID を表示できます。これらの変更は、ブラウザーのセッション全体で保持されます。
長時間実行しているクエリのモニタリング
Amazon Redshift は、クエリまたは読み込みの実行時間が 10 分を超える場合、クエリを分類します。ドロップダウンメニューから [長時間クエリ] を選択すると、長時間実行しているクエリを確認できます。同様に、中程度の時間のクエリや短時間クエリをフィルタリングすることもできます。

問題のあるクエリの分離
次のセクションでは、コンソールを使用してクエリのパフォーマンスに関する問題を診断するいくつかのユースケースについて説明します。
クエリのパフォーマンスに関する問題
このユースケースでは、ダッシュボードの一部のクエリが低速なため、関連するクエリを特定したいとユーザーが言っている例を取り上げます。これらのクエリは、上位のクエリの一部ではない可能性があります。これらのクエリを分離するには、ドロップダウンメニューから [完了したクエリ] または [すべてのクエリ] を選択し、[カスタム] をクリックして時間ウィンドウを指定します。

ドリルダウンして特定の期間のクエリを表示したり、ユーザー名を検索して特定のユーザーからのクエリをフィルタリングしたりすることも可能です。

SQL クエリテキストを検索してクエリをフィルタリングすることもできます。

前出のガントチャートと同様、バーのサイズはクエリのランタイム期間を相対的に表しています。この例での期間では、強調表示されたクエリが最も遅くなっています。ガントチャートのバーの上にマウスを置くと、クエリ ID、クエリテキストの一部、ランタイムなど、クエリに関する役立つ情報が表示されます。特定のクエリの詳細を表示するには、[クエリ ID] をクリックします。

クエリパフォーマンスのシステム上の問題の特定
このユースケースでは、多くのユーザーが通常よりも長いクエリのランタイムについて不満を言っています。クラスターで何が起こっているのかを診断したいとします。時間をカスタマイズして、グラフビューに切り替えることができます。これで、通常より長いランタイムとクラスターで発生していることを関連付けることができます。次のガントチャートと CPU 使用率のグラフが示すように、その時点で多くのクエリを実行中に CPU 使用率がほぼ 100% に達しています。

Amazon Redshift の並列スケーリング機能は、ワークロードが急激に増加した場合でも安定したパフォーマンススループットを維持するのに役立ちました。
高い CPU 使用率
クエリのパフォーマンスをクラスターのパフォーマンスと関連付け、CPU 使用率などの特定のメトリクスを強調表示することで、そのときに実行していたクエリを確認できます。

ワークロードのパフォーマンスのモニタリング
ワークロード実行の内訳グラフを確認することで、ワークロードのパフォーマンスの詳細を確認できます。ワークロードの計画、待機、実行にかかった時間を見ることができます。INSERT、UPDATE、DELETE、COPY、UNLOAD、または CTAS などのオペレーションに費やした時間も表示できます。クエリ履歴で選択した時刻は、ページ間を移動したときに保存されます。

上のスクリーンショットのワークロードの内訳グラフで、いくつかの待機があることを確認できます。並列スケーリングを利用して、クエリのバーストを処理できます。
クエリのスループットとクエリ期間の関連付け
長、中、短時間クエリの期間や実行時間などのクエリのパフォーマンスの傾向を表示し、クエリのスループットと相関させることができます。

こうした情報から、クラスターが現在の設定で各クエリカテゴリをどの程度適切に処理しているかについての洞察を得ることができます。
WLM キューのワークロードのモニタリング
クエリのパフォーマンスをクラスターのパフォーマンスと関連付け、CPU 使用率などの特定のメトリクスを強調表示することで、そのときに実行していたクエリがどれかを確認できます。さまざまな WLM キューごとに、平均スループット、平均継続時間、平均キュー時間を表示できます。このグラフから得られる分析情報は、クエリの調整に役立つことがあります。たとえば、WLM キューに適切な優先順位を割り当てるか、WLM キューの並列スケーリングを有効にするか、などです。

クエリパフォーマンスの診断と最適化
低速クエリを特定したら、[クエリ ID] をクリックして、クエリの実行の詳細にドリルダウンできます。次のスクリーンショットは、複数のクエリに書き換えられたクエリの複数のクエリ ID を示しています。

「クエリの詳細」ページには、親クエリとすべての書き換えられたクエリが表示されます。

書き換えられたクエリが、並列スケーリングクラスターで実行されたかどうかも確認できます。
クエリの計画、計画の各手順のコストなどの実行統計、クエリ用にスキャンしたデータを表示できます。

クラスターでクエリを実行したときに、クラスターのメトリクスを表示することもできます。次のスクリーンショットは、クエリ計画での問題がある手順を示しています。問題のある手順を選択すると、このクエリを改善するためのインプレースでの推薦事項が表示されます。

Advisor の推奨事項の実装
Amazon Redshift Advisor は、ワークロードのパフォーマンスを向上させることができる推奨事項を提供します。Amazon Redshift は、機械学習を使用してワークロードを調べ、カスタマイズした推奨事項を提供します。Amazon Redshift は、次の重要な領域でのパフォーマンスを改善するガイダンスを提供します。
- 短時間クエリアクセラレーション (SQA) – クエリパターンをチェックし、SQA を有効化して SQA 対応のクエリのレイテンシーと 1 日のキュー時間を削減可能な最近のクエリの数を報告することで、クエリのパフォーマンスを向上する
- テーブルの並べ替えキー – データウェアハウスのワークロードを数日間分析し、テーブルに有効な並べ替えキーを特定し、並べ替えキーの推奨事項を作成する
- 分散キー (テーブル用) – ワークロードを分析して、キー分散スタイルから大きな利点を得ることができるテーブルでの最も適切な分散キーを特定する
次のスクリーンショットは、テーブルの分散キーを変更するための推奨事項を示しています。

並列スケーリングの有効化
ユーザーに最適なパフォーマンスを提供するために、ユーザーのワークロードをモニタリングしたり、問題を診断した場合にはアクションを実行したりできます。特定の時間のクエリ履歴にドリルダウンして、その時間に実行しているいくつかのクエリを確認できます。

並列スケーリングを使用していない場合、クエリがキューに入れられている可能性があります。[ワークロードの同時実行] タブでも確認できます。次のスクリーンショットでは、並列スケーリングを有効にしていないため、その間多くのクエリがキューにとどまっていることがわかります。

送信されたすべてのクエリをモニタリングし、キューに入れられたクエリが増加しているときに並列スケーリングを有効にすることができます。
この機能の詳細については、クエリモニタリングのデモをご覧ください。
まとめ
この投稿では、Amazon Redshift コンソールの新機能を紹介しました。この機能はユーザークエリをモニタリングし、ユーザーワークロードでのパフォーマンスの問題を診断するのに役立ちます。コンソールを使って、上位のクエリを期間ごとに表示したり、失敗したクエリや実行時間の長いクエリをフィルター処理したり、関連する書き換えられたクエリとその実行の詳細をドリルダウンしたりできます。つまり、コンソールでクエリの調整が可能です。新しい Amazon Redshift コンソールのクエリモニタリング機能の使用を開始して、今すぐユーザーのワークロードをモニタリングしましょう。
著者について
 Debu Panda は AWS のシニアプロダクトマネージャーで、分析、アプリケーションプラットフォーム、データベーステクノロジーの業界リーダーです。IT 業界で 20 年以上の経験があり、分析、エンタープライズ Java やデータベースに関する多数の記事を発表し、複数の会議でプレゼンテーションを行いました。「EJB 3 in Action (Manning Publications 2007, 2014)」と「Middleware Management (Packt)」の主任執筆者です。
Debu Panda は AWS のシニアプロダクトマネージャーで、分析、アプリケーションプラットフォーム、データベーステクノロジーの業界リーダーです。IT 業界で 20 年以上の経験があり、分析、エンタープライズ Java やデータベースに関する多数の記事を発表し、複数の会議でプレゼンテーションを行いました。「EJB 3 in Action (Manning Publications 2007, 2014)」と「Middleware Management (Packt)」の主任執筆者です。
 Apurva Gupta は AWS のユーザーエクスペリエンスデザイナーです。データベース、分析、AI ソリューションが専門です。以前は、エンドツーエンドを設計する大小さまざまなトップ企業と協力し、チームが設計優先の製品開発プロセス、設計システム、アクセシビリティプログラムをセットアップするのを支援していました。
Apurva Gupta は AWS のユーザーエクスペリエンスデザイナーです。データベース、分析、AI ソリューションが専門です。以前は、エンドツーエンドを設計する大小さまざまなトップ企業と協力し、チームが設計優先の製品開発プロセス、設計システム、アクセシビリティプログラムをセットアップするのを支援していました。
 Chao Duan は Amazon Redshift のソフトウェア開発マネージャーです。開発チームを率いて、Redshift の包括的なモニタリングによるセルフメンテナンスとセルフチューニングの実現に取り組んでいます。高い可用性とパフォーマンス、コスト効率のデータベースを構築し、データ主導の意思決定を利用して顧客を強力にサポートすることに情熱を傾けています。
Chao Duan は Amazon Redshift のソフトウェア開発マネージャーです。開発チームを率いて、Redshift の包括的なモニタリングによるセルフメンテナンスとセルフチューニングの実現に取り組んでいます。高い可用性とパフォーマンス、コスト効率のデータベースを構築し、データ主導の意思決定を利用して顧客を強力にサポートすることに情熱を傾けています。
 Sudhakar Reddy は Amazon Redshift を使用したフルスタックのソフトウェア開発エンジニアです。ビッグデータ、データベース、分析向けのクラウドサービスとアプリケーションの構築を専門としています。
Sudhakar Reddy は Amazon Redshift を使用したフルスタックのソフトウェア開発エンジニアです。ビッグデータ、データベース、分析向けのクラウドサービスとアプリケーションの構築を専門としています。
 Zayd Simjee は Amazon Redshift のソフトウェア開発エンジニアです。
Zayd Simjee は Amazon Redshift のソフトウェア開発エンジニアです。