Amazon Web Services ブログ
Amazon EMR で Spark ストリーミングアプリケーションをモニタリングする
アプリケーションをエンタープライズ対応にするには、本番環境に移行する前にアプリケーションの多くの側面を考慮し、アプリケーションの運用を可視化する必要があります。その可視性は、アプリケーションの正常性とパフォーマンスを測定し、アプリケーションダッシュボードとアラームをフィードするメトリクスを通じて得ることができます。
ストリーミングアプリケーションでは、さまざまなステージと各ステージ中のタスクをベンチマークする必要があります。Spark は、プローブをプラグインするためのインターフェイスを提供し、アプリケーションをリアルタイムでモニタリングおよび観察できるようにしています。SparkListeners は、スチーミングアプリケーションとバッチアプリケーションの両方に対応する柔軟で強力なツールです。これを Amazon CloudWatch メトリクス、ダッシュボード、およびアラームと組み合わせて、可視性を高め、問題が発生したときに通知を生成したり、クラスターやサービスを自動的にスケーリングしたりできます。
この記事では、シンプルな SparkListener を実装し、Spark ストリーミングアプリケーションをモニタリングおよび観察し、アラートを設定する方法を説明します。また、CloudWatch カスタムメトリクスに基づいて、アラートを使って Amazon EMR クラスターで Auto Scaling を設定する方法も示します。
Spark ストリーミングアプリケーションのモニタリング
本番環境のユースケースでは、Spark アプリケーションに必要なリソースの量を決定するために事前に計画する必要があります。多くの場合、リアルタイムアプリケーションには、各バッチの実行を安全に実行できる時間や各マイクロバッチの許容遅延時間など、満たす必要のある SLA があります。多くの場合、アプリケーションのライフサイクルの中で、入力ストリームのデータが突然増加することにより、流入するデータを処理して追いつくために、より多くのアプリケーションリソースが必要になります。
このようなユースケースでは、各マイクロバッチのレコード数、スケジュールされたマイクロバッチの実行の遅延、各バッチの実行にかかる時間などの一般的なメトリクスに興味を持たれるかもしれません。たとえば、Amazon Kinesis Data Streams では、IteratorAge メトリクスをモニタリングできます。Apache Kafka をストリーミングソースとして使用すると、最新のオフセットとコンシューマーオフセットの間のデルタなど、コンシューマーラグをモニタリングできます。Kafka には、この目的のためのさまざまなオープンソースツールがあります。
より多くのリソースをプロビジョニングするか、未使用のリソースを減らしてコストを最適化することにより、リアルタイムで対応したり、環境の変化に基づいてアラートを生成したりできます。
Spark ストリーミングアプリケーションをモニタリングするさまざまな方法が既にご利用いただけます。Spark の非常に効率的ですぐに使える機能は、Spark メトリクスシステムです。さらに、Spark は HTTP、JMX、CSV ファイルなど、さまざまなシンクにメトリクスを報告できます。
ログを出力することにより、アプリケーション内からアプリケーションメトリクスをモニタリングおよび記録することもできます。これには、count().print() の実行、マップ内のメトリクスの印刷、遅延の原因となる可能性のあるデータの読み取り、アプリケーションステージへの追加、または不要なシャッフルの実行が必要です。これは、テストには役立つ可能性はありますが、長期的なソリューションとしては高価であることがしばしば証明されています。
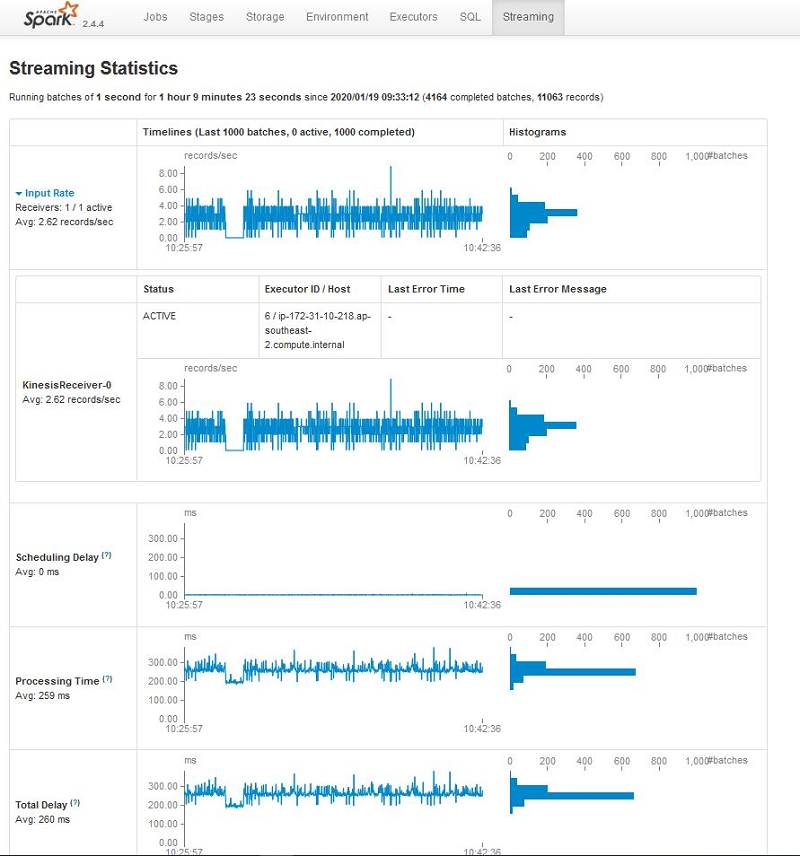
この記事では、別の方法について説明します。それは、SparkStreaming インターフェイスを使用する方法です。次のスクリーンショットは、Spark UI の [Streaming] タブで利用できるメトリクスを示しています。
Apache Spark リスナー
Spark は内部的に、イベントベースの方法で行う内部コンポーネント間の通信を SparkListeners に依存しています。また、Spark スケジューラは、各タスクのステージが変更されるたびに、SparkListeners のイベントを発行します。SparkListeners は、Spark 実行エンジンの中心部である DAGScheduler から発生するイベントをリッスンします。カスタム Spark リスナーを使用して SparkScheduler イベントをインターセプトできるため、タスクまたはステージがいつ開始および終了するかがわかります。
Spark Developer API は、主に開始時と停止時、失敗時、完了時、それにレシーバーやバッチの送信時、出力操作時に、さまざまな SparkEvents で呼び出される SparkListener トレイトの 8 つのメソッドを提供しています。これらのメソッドを実装することにより、各イベントでアプリケーションロジックを実行できます。詳細については、GitHub の StreamingListener.scala を参照してください。
カスタム Spark リスナーを登録するには、アプリケーションの起動時に spark.extraListeners を設定するか、アプリケーションで SparkContext を設定するときに addSparkListener を呼び出してプログラムで設定します。
SparkStreaming マイクロバッチ
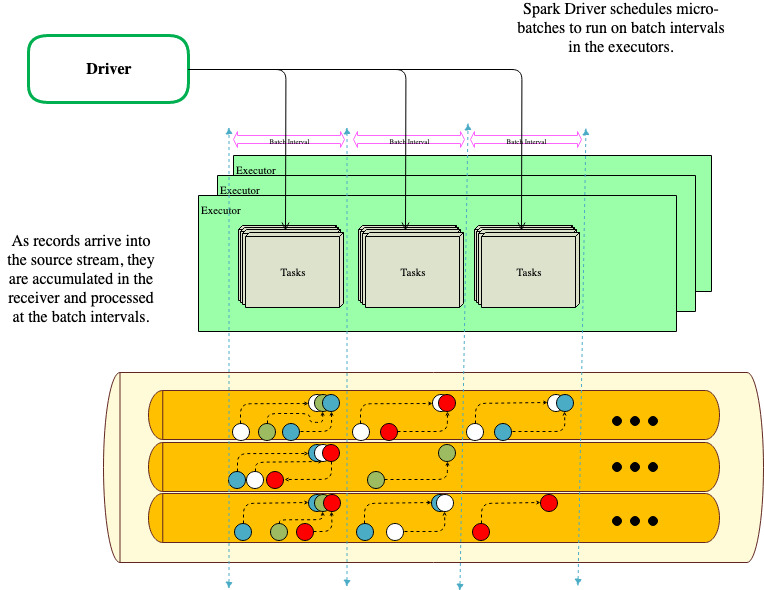
デフォルトでは、SparkStreaming にはマイクロバッチ実行モデルがあります。Spark は、継続的なストリームで間隔を置いてジョブを開始します。各マイクロバッチにはステージが含まれており、ステージにはタスクがあります。ステージは、DAG とアプリケーションコードが定義する操作に基づいており、各ステージのタスクの数は、DStream パーティションの数に基づいています。
ストリーミングアプリケーションの開始時に、レシーバーは実行時間の長いタスクとしてラウンドロビン方式でエグゼキューターに割り当てられます。
レシーバーは、blockInterval に基づいてデータのブロックを作成します。受信したブロックは、エグゼキューターの BlockManager によって配布され、ドライバーで実行されているネットワーク入力トラッカーにブロックの場所が通知されて、さらに処理されます。
ドライバーでは、各 batchInterval のブロックに対して RDD が作成されます。各ブロックは RDD のパーティションに変換され、タスクは各パーティションを処理するようにスケジュールされます。
次の図は、このアーキテクチャを示しています。
カスタム SparkListener を作成し、メトリクスを CloudWatch に送信する
CloudWatch カスタムメトリクスを利用して、カスタム Spark リスナーから収集したカスタム Spark メトリクスに基づいてアラームを反応または発生させることができます。
Scala で記述している場合は SparkListener trait を直接実装するか、同等の Java インターフェイスまたは PySpark Python ラッパー pyspark.streaming.listener を実装することで、カスタムストリーミングリスナーを実装できます。
この記事では、マイクロバッチに関するメトリクスのみを収集しているため、onBatchCompleted と onReceiverError のみをオーバーライドします。
OnBatchCompleted から、次のメトリクスを送信します。
- ハートビート – バッチが完了したときに得られる 1 の数値。これにより、期間を合計または平均して、実行されたマイクロバッチの数を確認できます
- レコード – バッチあたりのレコード数
- スケジュールの遅延 – バッチの実行がスケジュールされてから実際に実行されるまでの間の遅延
- 処理の遅延 – バッチの実行にかかった時間
- 合計遅延 – 処理遅延とスケジューリング遅延の合計
OnRecieverError から、レシーバーに障害が発生した場合は常に、数値 1 を送信します。次のコードを参照してください。
この例の Scala 実装の完全なソースコードとサンプルの Spark Kinesis ストリーミングアプリケーションについては、AWSLabs GitHub リポジトリをご覧ください。
カスタムリスナーを登録するには、カスタムリスナーオブジェクトのインスタンスを作成し、addStreamingListener メソッドを使用して、ドライバーコードでストリーミングコンテキストにオブジェクトを渡します。次のコードを参照してください。
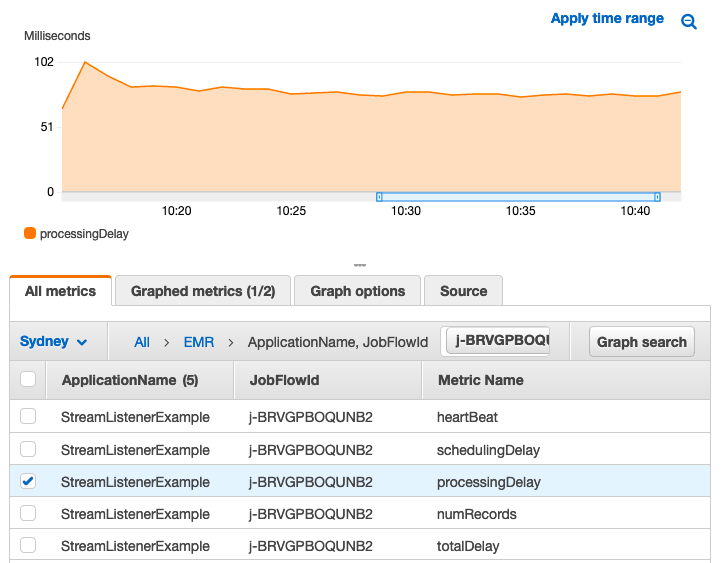
アプリケーションを実行すると、EMR クラスターが実行されているアカウントと同じアカウントで CloudWatch のメトリクスを見つけることができます。次のスクリーンショットを参照してください。
サンプルコードを使用する
この記事では、コードを示す AWS CloudFormation テンプレートを提供しています。GitHub リポジトリから emrtemplate.json ファイルをダウンロードします。テンプレートは、パブリックサブネットで EMR クラスターを起動し、必要なデフォルトの AWS Identity and Access Management (IAM) ロールにより 3 つのシャードを持つ Kinesis データストリームを起動します。サンプルの Spark Kinesis ストリーミングアプリケーションは、Amazon EMR ステップスクリプトがサンプルカスタム StreamListener を使用してコンパイルおよびパッケージ化する単純な単語数です。
CloudWatch でのアプリケーションアラームの使用
設定する必要があるアラートは、主にアプリケーションの SLA によって異なります。原則として、スケジュールされたバッチがキューに入れられ、入力ストリームに遅れが生じるため、バッチがマイクロバッチ間隔より長くかかることは望ましくありません。また、ストリームから読み取りを行うレシーバーのレートが、急増のためにバッチで処理できる速度を超えている場合、読み取られたレコードがディスクに流出し、他のエグゼキューターへのシャッフルがさらに遅延する可能性があります。処理の遅延がアプリケーションの batchInterval に近づいたときに通知するように CloudWatch アラームを設定できます。アラームを設定する手順については、「Amazon CloudWatch アラームの使用」を参照してください。
この記事の CloudFormation テンプレートには、モニタリング対象のサンプルアラームが 2 つあります。1 つ目は、processingDelays メトリクスの異常検出帯域に基づいています。 2 つ目は、schedulingDelay ratio to totalDelay の計算式または (schedulingDelay / totalDelay) * 100 のしきい値に基づいています。
ストリーミングアプリケーションのスケーリング
スケーリングに関しては、データの量が増えるにつれて、ストリーミングアプリケーションの blockIntervals に基づいて、DStream パーティションが増加します。受信したレコードに追いつき、バッチ間隔内で終了する必要があるバッチに加えて、レシーバーはレコードの流入に追いつく必要もあります。ソースストリームは、レシーバーがストリームから十分に速く読み取るのに十分な帯域幅を提供し、ソースからのレコードを消費するために適切なレートで読み取る十分なレシーバーが必要です。
DStream がレシーバーと WAL によってサポートされている場合は、レシーバーの数を事前に考慮する必要があります。アプリケーションを起動しても、アプリケーションを再起動しないと、レシーバーの数が変化しない場合があります。
SparkStreaming アプリケーションが起動すると、デフォルトで、レシーバーに優先ロケーションが定義されていない限り、ドライバーは使用可能なエグゼキューターでラウンドロビン方式でレシーバーをスケジュールします。すべてのエグゼキューターにレシーバーが割り当てられると、残りの必要なレシーバーがエグゼキューターでスケジュールされ、各エグゼキューターのレシーバー数のバランスが取られ、レシーバーは実行時間の長いタスクとしてエグゼキューターにとどまります。エグゼキューター上のレシーバーのスケジュールの詳細については、GitHub の ReceiverSchedulingPolicy.scala および Spark の問題のウェブサイトの SPARK-8882 を参照してください。
マイクロバッチ内のデータを減らし、マイクロバッチ間隔を超えたくないため、レシーバーを遅くしたい場合があります。レシーバーの速度を落とすには、バッチがレコードの急増に追いつくのに十分な速度で実行できないときにレコードを保持できるストリーミングソースがある場合、BackPressure 機能を有効にしてレシーバーからの入力レートに適応させることができます。そのためには、spark.streaming.backpressure.enabled を true に設定します。
考慮できるもう 1 つの要素は、ストリーミングアプリケーションの動的割り当てです。デフォルトでは、spark.dynamicAllocation は Amazon EMR で有効になっており、spark.streaming.dynamicAllocation と相互に排他的です。ドライバーに DStream タスクの追加のエグゼキューターをリクエストする場合は、spark.dynamicAllocation.enabled を false に設定し、spark.streaming.dynamicAllocation.enabled を true に設定する必要があります。Spark は定期的に平均バッチ期間を調べます。スケールアップ率を超える場合は、より多くのエグゼキューターをリクエストします。スケールダウン率を下回っている場合は、アイドル状態のエグゼキューターを解放します (できればレシーバーを実行していないエグゼキュータ―を解放します)。詳細については、GitHub の ExecutorAllocationManager.scala および Spark ストリーミングプログラミングガイドを参照してください。
ExecutorAllocationManager はすでにバッチ実行の平均時間を調べており、スケールアップとスケールダウンの比率に基づいてより多くのエグゼキューターをリクエストしています。このため、Amazon EMR で、できればタスクインスタンスグループで Auto Scaling をセットアップして、ContainerPendingRatio に基づいてノードを追加および削除し、コアノードにレシーバーに対して PreferredLocation を割り当てることができます。この記事のサンプルコードは、カスタムの KinesisInputDStream を提供します。これにより、リクエストするすべてのレシーバーに適切な場所を割り当てることができます。それは基本的にホスト名を返す関数で、できればレシーバーを配置します。GitHub リポジトリには、customKinesisInputDStream と customKinesisReciever を使用するサンプルアプリケーションもあり、これによりレシーバーのために preferredLocation をリクエストできます。
スケールダウン時に、Amazon EMR は、タスクインスタンスグループの廃止処理のために実行されているコンテナが最も少ないノードを指定します。
Auto Scaling の設定の詳細については、「インスタンスグループのカスタムポリシーで Auto Scaling を使用する」を参照してください。サンプルコードには、schedulingDelay のしきい値が含まれています。一般的なルールとして、しきい値は batchIntervals と processingDelay に基づいて設定する必要があります。schedulingDelay の増加は通常、タスクをスケジュールするためのリソースが不足していることを意味します。
次の表は、Spark ストリーミングジョブを起動するときに調整する設定属性をまとめたものです。
| 設定属性 | デフォルト |
spark.streaming.backpressure.enabled |
False |
spark.streaming.backpressure.pid.proportional |
1.0 |
spark.streaming.backpressure.pid.integral |
0.2 |
spark.streaming.backpressure.pid.derived |
0.0 |
spark.streaming.backpressure.pid.minRate |
100 |
spark.dynamicAllocation.enabled |
True |
spark.streaming.dynamicAllocation.enabled |
False |
spark.streaming.dynamicAllocation.scalingInterval |
60 Seconds |
spark.streaming.dynamicAllocation.minExecutors |
max(1,numReceivers) |
spark.streaming.dynamicAllocation.maxExecutors |
Integer.MAX_VALUE |
リスナーによる構造化ストリーミングのモニタリング
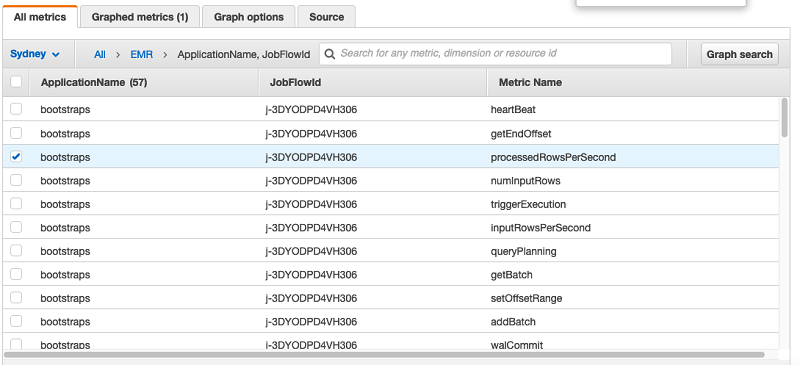
構造化されたストリーミングは、まだマイクロバッチでレコードを処理し、レシーバーからのデータがあるときにクエリをトリガーします。これらのクエリは、別のリスナーインターフェイス StreamingQueryListener を使用してモニタリングできます。この記事では、Kafka での構造化ストリーミングのサンプルリスナーと、実行用のサンプルアプリケーションを示します。詳細については、CloudWatchQueryListener.scala GitHub をご覧ください。次の画像は、カスタム StreamingQueryListerer が収集する CloudWatch カスタムメトリクスのスナップショットです。
EMR クラスターのスケールダウン
Spark ストリーミングアプリケーションを起動すると、Spark はアプリケーションの開始時に、利用可能なすべてのエグゼキューター上のレシーバーを均等にスケジュールします。EMR クラスターがスケールダウンに設定されている場合、Amazon EMR は、Auto Scaling ルールを使用して、インスタンスグループでより少ないタスクを実行しているノードを指定します。Spark レシーバーは長時間実行されるタスクですが、Amazon EMR は yarn.resourcemanager.decommissioning.timeout を待機するか、NodeManagers が廃止されると、ノードを正常に終了して縮小します。お客様は常に、レシーバーで実行中のエグゼキューターを失うリスクがあります。DStreams に対して十分な Spark ブロックレプリケーションと CheckPointing を常に検討し、理想的には PreferedLocation を定義して、レシーバーを失うリスクを回避する必要があります。
メトリクスの料金
一般に、Amazon EMR メトリクスでは CloudWatch のコストは発生しません。ただし、カスタムメトリクスには CloudWatch メトリクスの料金に基づく料金が発生します。詳細については、Amazon CloudWatch 料金表を参照してください。さらに、Spark Kinesis Streaming は Kinesis Client Library に依存しており、CloudWatch メトリクスの料金に基づいて料金が発生するカスタム CloudWatch メトリクスを公開しています。詳細については、「Amazon CloudWatch で Kinesis クライアントライブラリをモニタリングする」を参照してください。
まとめ
Spark ストリーミングおよびリアルタイムアプリケーションのモニタリングと調整は困難で、環境の変化にリアルタイムで対応する必要があります。また、全体像を把握するには、ソースストリームとジョブ出力をモニタリングする必要があります。Spark は、モニタリングジョブに複数のオプションを提供する非常に柔軟で豊かなフレームワークです。この記事では、SparkListeners を使用して Spark ストリーミングマイクロバッチのパフォーマンスをモニタリングし、抽出されたメトリクスを CloudWatch メトリクスと統合する効率的な方法を検討しました。
著者について
 Amir Shenavandeh は、AWS の Hadoop システムエンジニアです。彼は、オープンソースアプリケーションを使用してアーキテクチャガイダンスとテクニカルサポートでお客様を支援し、Hadoop エコシステムのアプリケーションを開発および進歩させ、オープンソースコミュニティと協力しています。
Amir Shenavandeh は、AWS の Hadoop システムエンジニアです。彼は、オープンソースアプリケーションを使用してアーキテクチャガイダンスとテクニカルサポートでお客様を支援し、Hadoop エコシステムのアプリケーションを開発および進歩させ、オープンソースコミュニティと協力しています。