Amazon Web Services ブログ
Amazon Polly – スピーチマークとウィスパーを発表
私のように、あなたは好きな本を読んでもらうために図書館か書店に行くのが好きかもしれません。幼い頃、声の抑揚を変えて話に命を吹き込むことができる上手な物語作家が物語る本の話を聞くのが好きでした。物語作家がよく使うスライド付きの本のナレーションは、新しい本を読んだり、見つけたりする私の趣味を駆り立てました。
実際、私の読書に関する趣味が古典小説にいたるように、両親はテープレコーダー付きの小さなプロジェクターを姉妹と私に買ってくれました。このプロジェクターは話を物語り、次のスクリーンに進むべきタイミングをチャイム音で知らせ、本と映像の投影を同期しました。不運にも、私はその話に夢中になってしまったけれど、私たちが TTS のようなスピーチ技術を実現するのにどれくらいの位置にいるのかについて振り返り、考えることが私にとって重要でした。あらゆるスピーチ技術の進歩をもってしても、TTS を利用して、ゲームやビデオ、デジタル書籍の中でキャラクターのアニメーションやグラフィックスに同期した会話/音声を追加することはデベロッパーにとって今だチャレンジングなものでした。加えて、リアルな音声のピッチやテンポ、音圧の強さを模倣するために TTS を利用したソリューションの成功事例は非常に稀でした。
これを踏まえて、Amazon Polly がスピーチマークとウィスパーをサポート開始することを私は喜んで発表します。

Amazon Polly はテキストをリアルな音声に変換することを可能にする深層学習を利用したサービスです。サービスが提供する24の言語と47のリアルな音声から好きな音声を選択することが可能です。Polly を使って、音声に変換したいテキストを Polly の API に送信することができます。そして、API は再生、もしくは、MP3 のような共通オーディオファイルフォーマットに保存可能なオーディオストリームを返却します。
スピーチマークはデベロッパーが映像体験と会話の同期を可能とするメタデータです。この機能は、会話を顔のアニメーションと同期することや、カラオケスタイルの単語の強調表示を利用することで、リップシンクのようなシナリオを可能とします。スピーチマークメタデータは合成された音声を記述します。そして、スピーチマークメタデータを会話と一緒に使うことにより、音声ストリームが音、語句、文、そして SSML タグの始まりと終わりを決定することができます。新しいスピーチマークを利用することで、デベロッパーは今、リップシンクするアバターや視覚的に強調表示された読み下し体験を生み出すことができ、そして、キャラクターに声を与えるために Amazon Lumberyard のようなゲーミングエンジンに会話能力を統合することができます。
スピーチマークには4つの種類があります:
- 文: 入力テキストの1文要素を明示する
- 語句: 入力テキストの1単語要素を表す
- ビゼーム(Viseme): 話された音に対応する顔と口の位置を説明する
- Speech Synthesis Markup Language(SSML): SSML で表現された入力テキストから <mark> タグを記述する
ウィスパーはピッチやテンポ、音圧と似たスピーチエフェクトの1つで、デベロッパーに TTS 出力を装飾可能とするもう一つの音声表現機能を提供します。ウィスパー機能はデベロッパーが <amazon:effect name=”whispered”> SSML タグを使って、ささやき声で話される言葉を持つのを可能とします。
これら2つの新しい機能について、見てみることにしましょう。
スピーチマークの利用
AWS 管理コンソールで Amazon Polly を使ってスピーチマークを利用する例にさっそく入ります。まず最初に Amazon Polly のコンソールに移動し、Get Startedボタンを押下します。
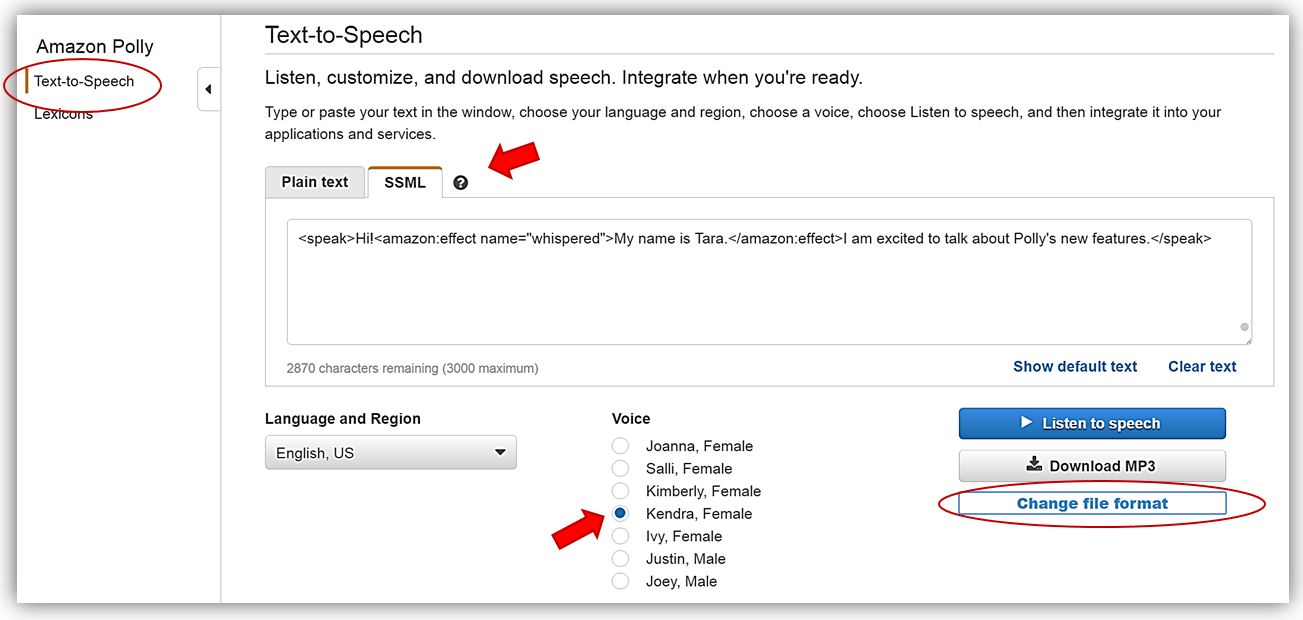
Text-to-Speech (テキスト読み上げ機能) メニューオプションに入り、Text-to-Speech (テキスト読み上げ機能)セクションの下の SSML を選択します。話してほしい2文を提供されたテキストフィールドに単純に追加し、音声を選択します。
Listen to Speech (音声を聴く) ボタンをクリックしてフォームに設定された文章を確かめます。聞いた内容が良かったので、スピーチマークメタデータを追加する手順に進みます。スピーチマークを利用するため、Change file format (ファイル形式を変更) リンクを選択します。
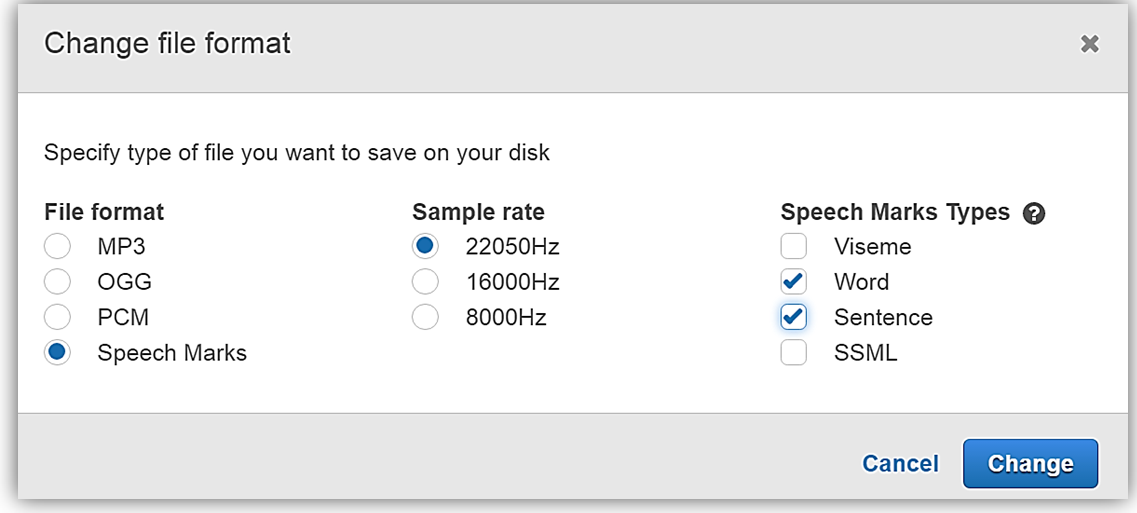
Change file format (ファイル形式を変更) 画面がポップアップするので、File Format (出力形式) からスピーチマークを選択し、スピーチマークのタイプセクションの下のチェックボックスをチェックして、Word(語句) と Sentence(文) を選択します。さあ、Change (変更) ボタンをクリックしましょう。
クリックすると、コンソールの Text-to-Speech (テキスト読み上げ機能) セクションに戻るので、生成されたスピーチマークを確かめるため、Download Speech Marks (Speech Marks のダウンロード) ボタンをクリックします。
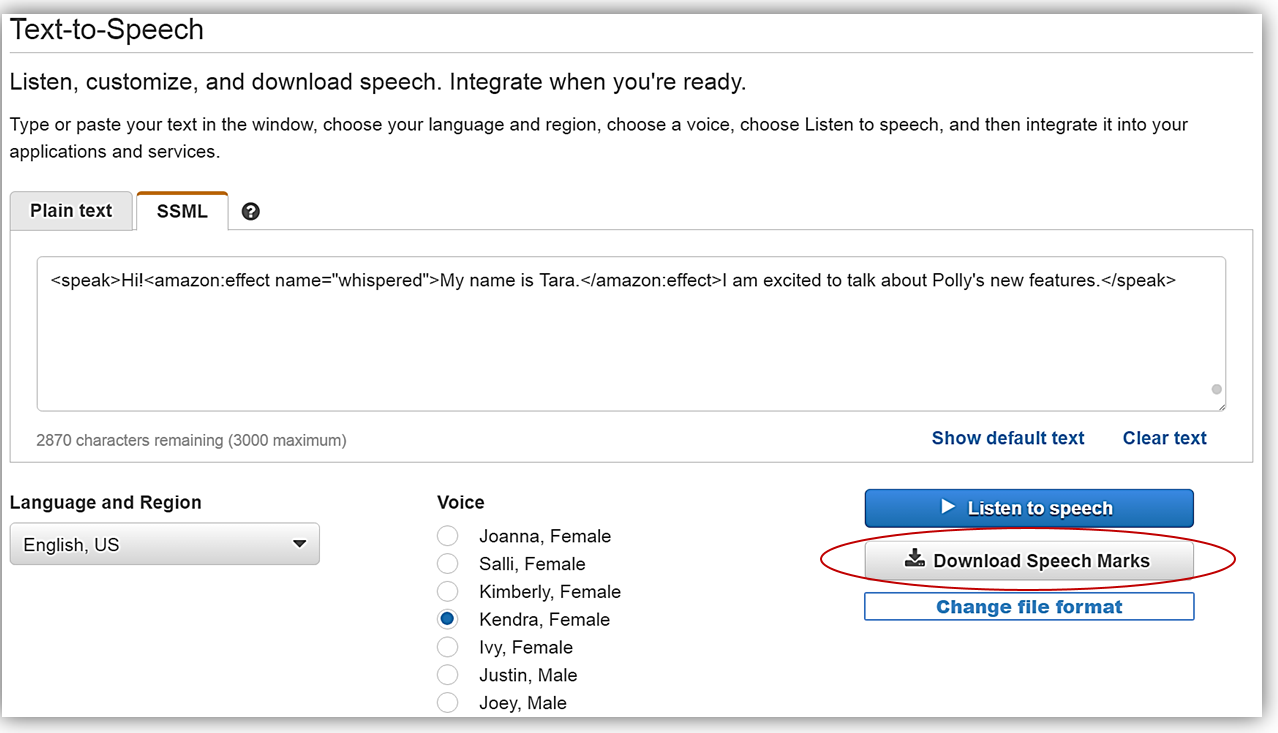
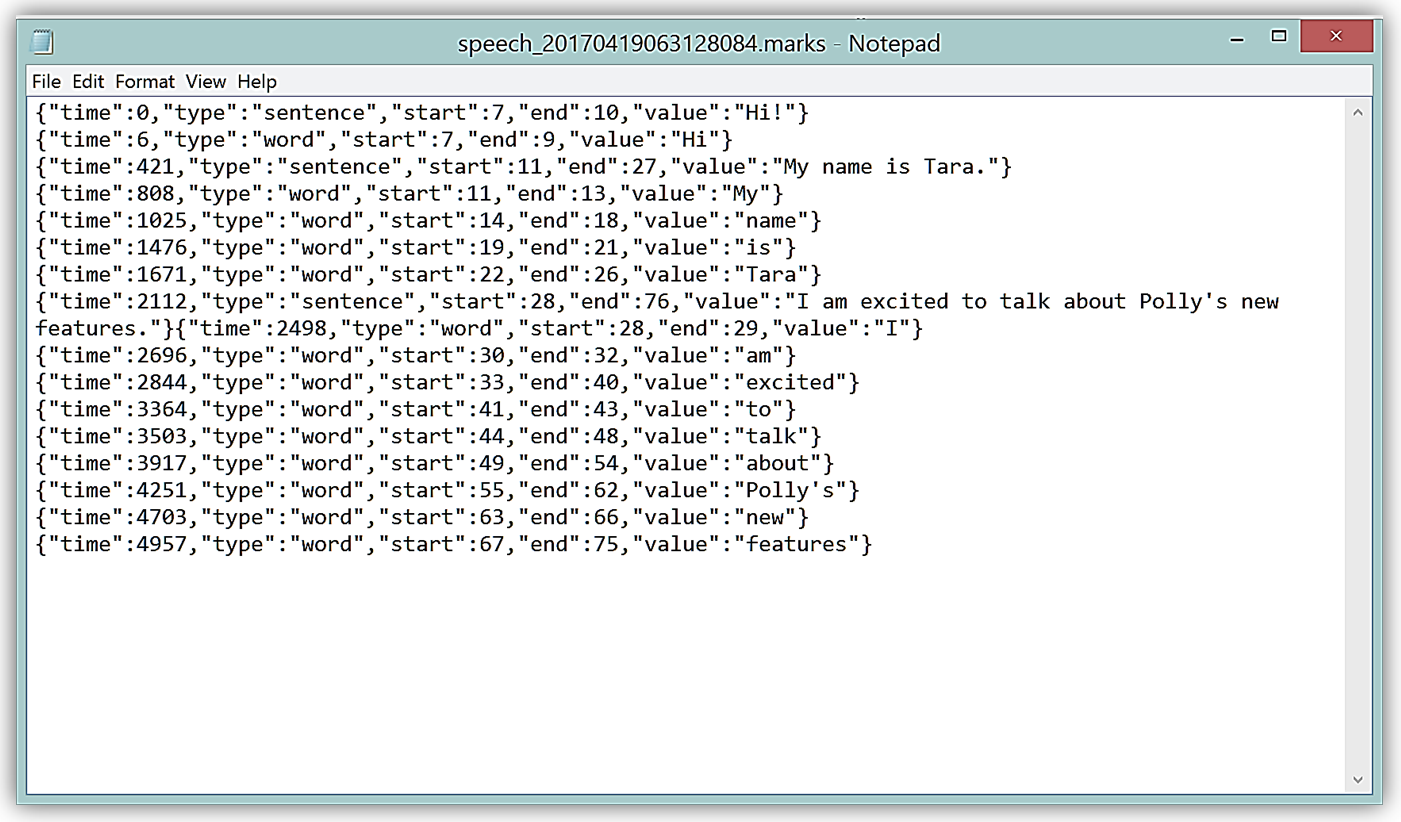
ダウンロードファイルは .marks 拡張子のファイルで、JSON 形式になっており、設定した文と語句それぞれについて最初と最後に関する情報が含まれています。JSON の変数は下記の通りです。
- Time: オーディオストリーム開始からのミリ秒単位経過時間
- Type: スピーチマークの種別(viseme, sentence, word, SSML)
- Start: 入力テキストにおける特定要素に関する先頭からのバイトオフセット(viseme は含まない)
- End: 入力テキストにおける特定要素の最後のバイトオフセット(viseme は含まない)
- Value: スピーチマーク種別に基づき様々な形式となるデータ(例: 文スピーチマークはテキスト中の文全体を含んでいる)
ウィスパーの利用
以前に指摘したように、ウィスパー機能を使うと whispered が値に設定された name 属性を持つ SSML amazon:effect タグを使ってささやき声で話される入力テキストを持つことが可能となります。上記の例を利用し、ささやき声を使って話されるように SSML タグを入力します。
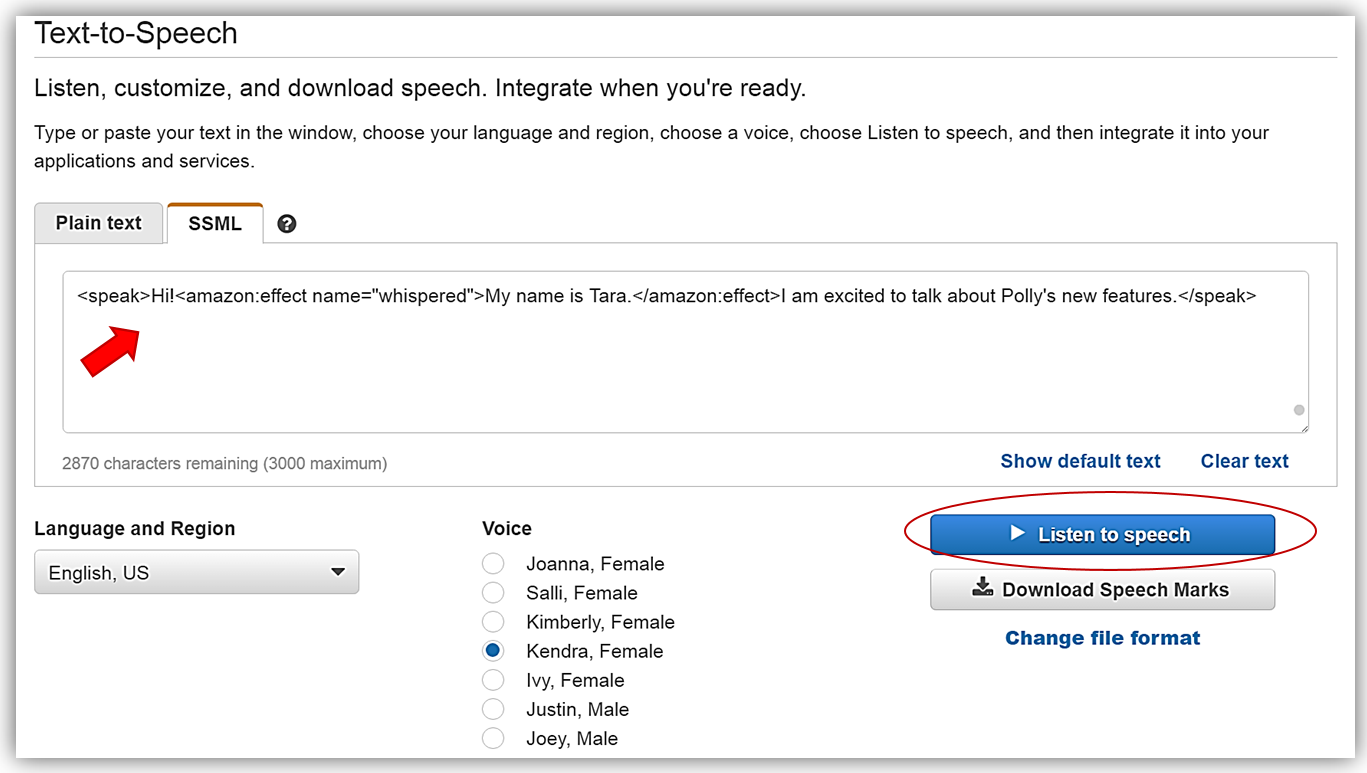
Amazon Polly のコンソールに戻り、文章(“My name is Tara“)に新しいささやき声機能を使うため、設定されている現在のテキストを修正します。これを達成するため、次のSSMLタグを使用します: <amazon:effect name=”whispered”>。故、テキストボックスに入力した文章に SSML タグを入れた最終的な文章は次のようになります:
<speak>Hi!<amazon:effect name="whispered">My name is Tara.</amazon:effect>I am excited to talk about Polly's new features.</speak>Listen to speech (音声を聴く) ボタンをクリックすると、文(“My name is Tara“)が本当にささやき声で話されているのが聴けます。
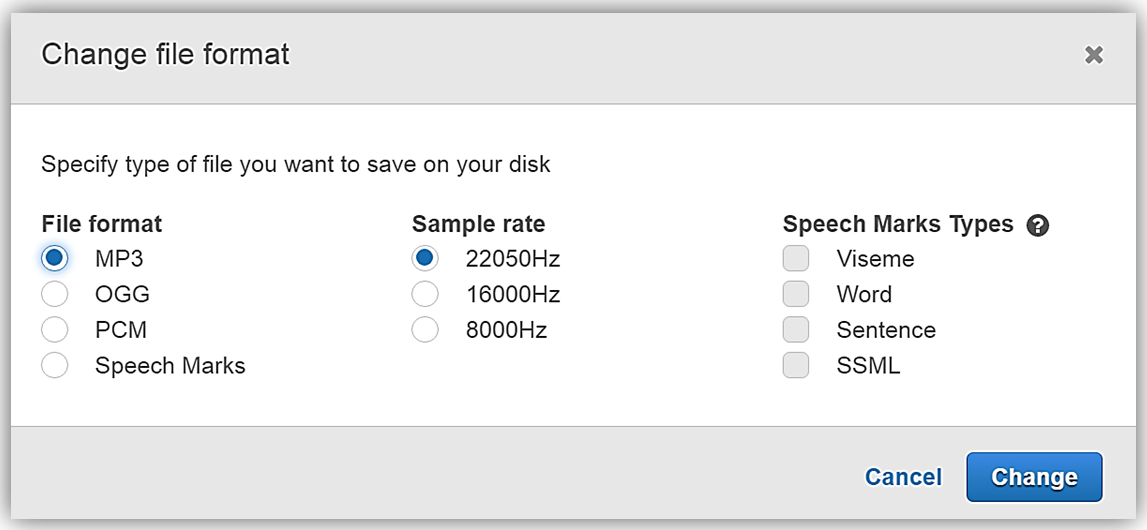
会話出力をダウンロードしたいので、Change file format (ファイル形式を変更) リンクをクリックします。Change file format (ファイル形式を変更) 画面がポップアップするので、File Format (出力形式) セクションの下から MP3 オプションを選択してから Change (変更) ボタンをクリックします。
今、私は Download MP3 (MP3 のダウンロード) ボタンをクリックしてファイルをダウンロードするオプションを持っています。
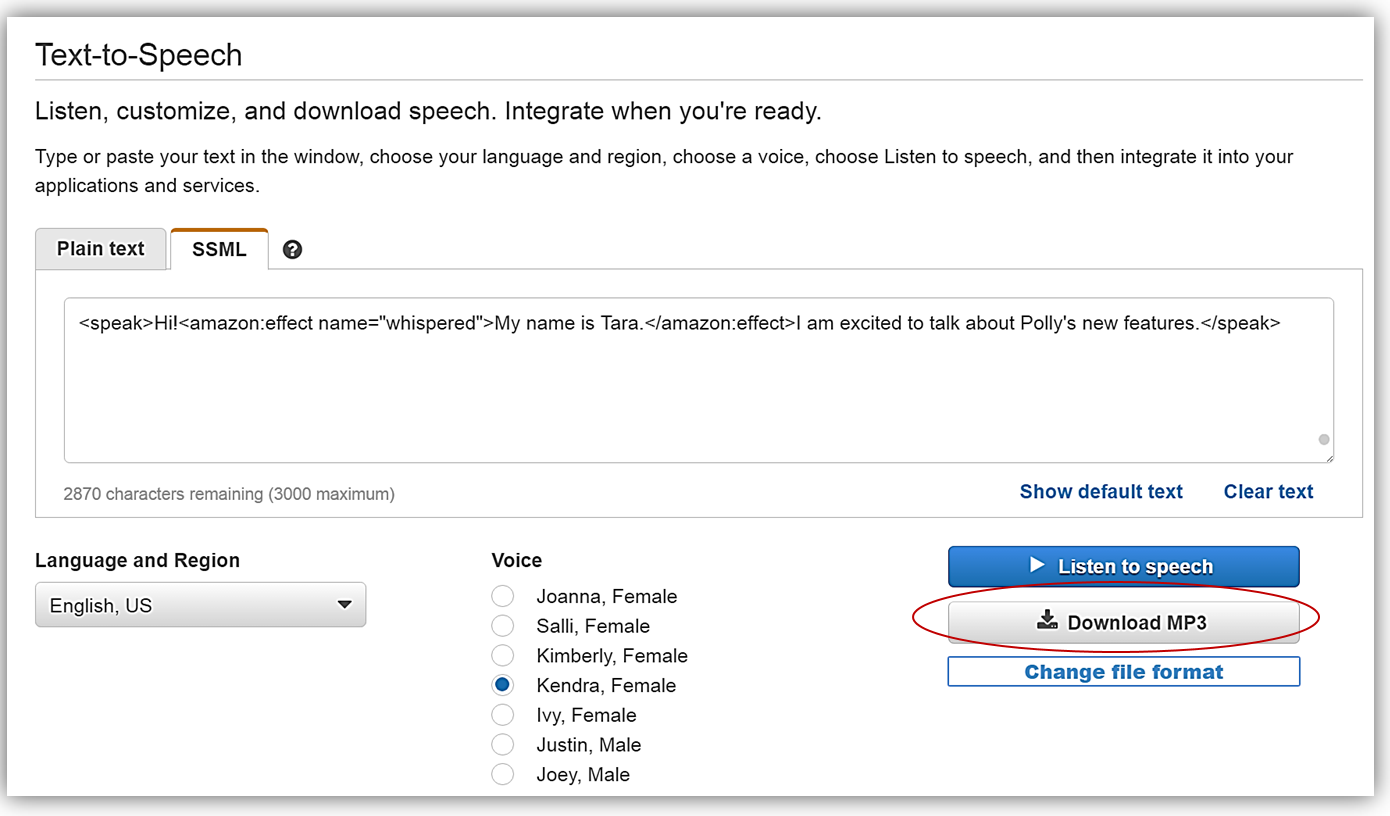
ここをクリックすることにより、新しいささやき声を使った会話出力を聞くことができます。
まとめ
スピーチマークとウィスパー機能は Amazon Polly で本日からご利用いただくことが可能です。これらの機能やその他の機能についてもっと学ぶには、以下のリンクにある Amazon Polly デベロッパーガイドをご確認ください。
http://docs.aws.amazon.com/polly/latest/dg/
Amazon Polly に関する詳細は Amazon Polly の製品ページを参照いただくか、もしくは、Amazon Polly のコンソールでテキストを音声に変換するところから始めてください。
今日、Amazon Polly を使って、あなたのテキストに声の贈り物を与えるべきです。
– Tara
(翻訳: SA川村,原文: Amazon Polly – Announcing Speech Marks and Whispering)