Amazon Web Services ブログ
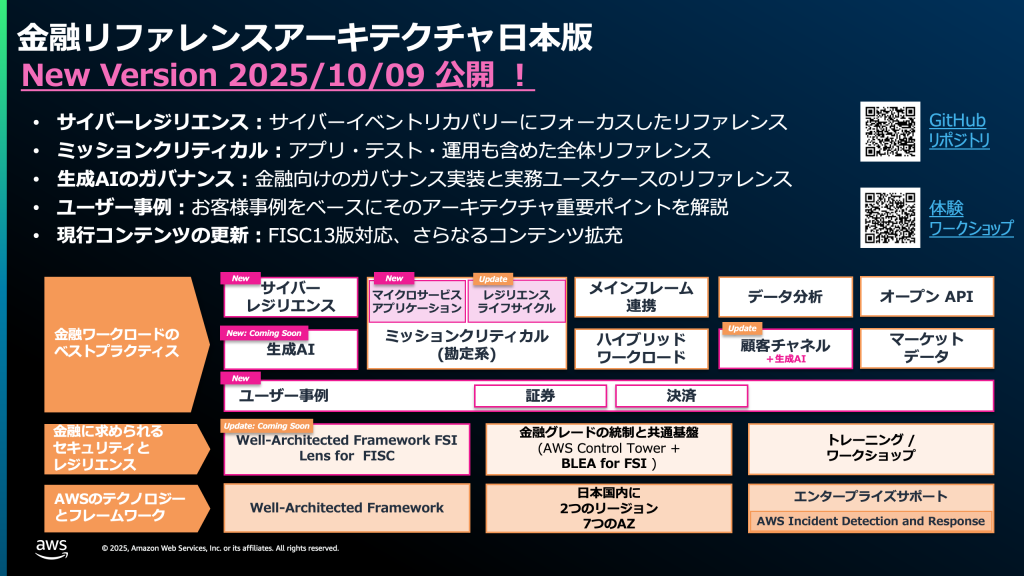
AWS 金融リファレンスアーキテクチャ日本版 2025 (v1.6) アップデート
(2025/11/14 : 新規公開した生成 AI ワークロードを追記しました。) 「金融リファレンスアーキテ […]
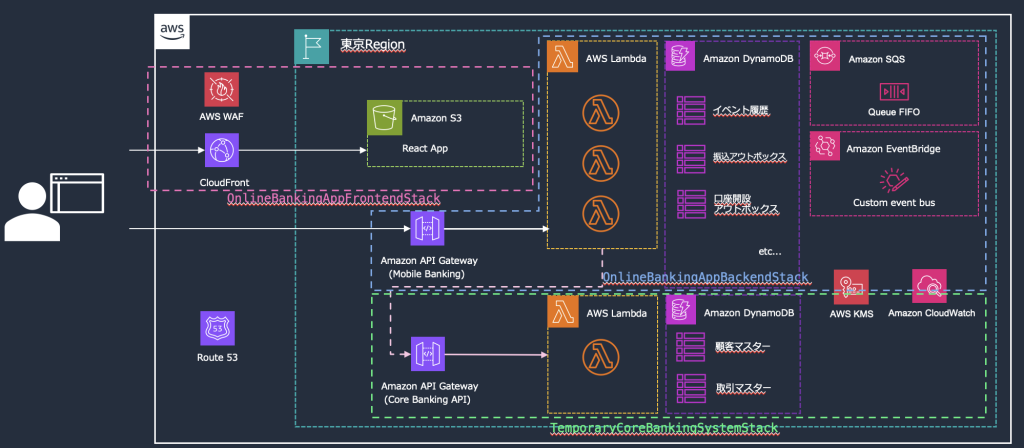
イベントドリブンな金融モダンアプリケーション実装を公開(金融リファレンスアーキテクチャ日本版 2025)
「金融リファレンスアーキテクチャ日本版」は、金融で求められるセキュリティと可用性に関するベストプラクティスを提供するフレームワークとして 2022 年 10 月に正式版として発表し、多くのお客様にご利用いただいております。この度、モダンアーキテクチャのサンプルとして、オンラインバンキングアプリケーションのユースケースを公開しました。本ブログ記事では、オンラインバンキングアプリケーションのユースケースを解説いたします。

Amazon Redshift DC2 ノードタイプから Amazon Redshift Serverless へのアップグレード
Amazon Redshift dense compute (DC2) インスタンスから Amazon Redshift Serverless へデータウェアハウスをアップグレードすることでこれらの利点が得られ、ユーザーエクスペリエンスの向上と運用の簡素化を実現し、より効率的でスケーラブルなデータ分析ソリューションを提供します。
この記事では、DC2 インスタンスから Amazon Redshift Serverless へのアップグレードプロセスをご紹介します。

エージェントステアリングと MCP を使って Kiro に新しいスキルを教える方法
この記事では、AI エージェントおよび開発環境である Kiro に、MathJSON というライブラリを理解させる方法を探ります。

AWS Weekly Roundup: AWS RTB Fabric、AWS Customer Carbon Footprint Tool、AWS Secret-West Region など (2025 年 10 月 27 日)
バージニア北部 (us-east-1) リージョンでサービスを使用している多くのユーザーにとって、10 月 2 […]

リアルタイム広告テクノロジーワークロードのための AWS RTB Fabric の紹介
10 月 23 日、リアルタイム入札 (RTB) 広告ワークロード専用に構築されたフルマネージドサービスである […]

Amazon GameLift Servers でローンチを成功させるためのステップ:ローンチフェーズ
ゲームが急激にヒットした場合に備え、最初から成功に向けた準備をしておくことが重要です。本記事では、Amazon GameLift Servers でマルチプレイヤーゲームを立ち上げる際に考慮すべき重要な点について説明します。ゲームのローンチの 2-3 ヶ月前に必要な作業に焦点を当てます。これは、ゲームの本番ローンチだけでなく、オープンベータ、アーリーアクセス、あるいは実際のプレイヤーが参加する他のマイルストーンも含まれます。

AWS DMS 拡張モニタリングを使用したリソース配分とパフォーマンス分析を理解する
本投稿は、Suchindranath Hegde と Mahesh Kansara と Balaji Bask […]

AWS DMS 実装ガイド:テスト、モニタリング、SOP による耐障害性のあるデータベース移行の構築
本投稿は、Sushant Deshmukh と Alex Anto Kizhakeyyepunnil Joyと […]

サイバーレジリエンス:サイバーイベントリカバリの実装 (金融リファレンスアーキテクチャ日本版 2025)
サイバーレジリエンスとは、サイバー攻撃を受けることを前提として、攻撃を予防し、検知し、対応し、復旧する能力を総合的に高めることです。従来の「攻撃を防ぐことに主眼を置く」という考え方に加えて、「攻撃を受けても事業を継続し、迅速に復旧する」という考え方も求められています。 特に可用性に影響を与えるランサムウェア攻撃やDDoS攻撃といったサイバーイベントに対する防御や復旧策は、実装が急務とされています。
昨今のこのような状況を踏まえ、この度、金融リファレンスアーキテクチャの新たなユースケースを提供いたします。金融機関におけるサイバーイベントからの迅速な復旧について、具体的なアーキテクチャと実装サンプルをセットでご紹介します。