Amazon Web Services ブログ
Amazon SageMaker を使用して、より迅速に大規模な主成分分析法を実行できます
このブログ記事では、Amazon SageMaker、Spark ML、Scikit-Learn を使用した、高ディメンジョンセットでの PCA に関するパフォーマンス比較を実施します。SageMaker は一貫してより高速な計算性能を示しました。速度改善内容を確認するために、下図 (1) および (2) を参照してください。
主成分分析法
主成分分析 (PCA) とは、依然として、可能な限りより多くの情報を保持しながら、データセット内部のディメンジョナリティ (例: 機能の個数など) の低減を目的とした監督機能解除済み学習アルゴリズムです。PCA は、各列は、それ以降はお互いが独立性を有する状況となるような、1 組のデータ行列を 1 個の直交空間に線形変換するものであり、個別のカラムが対象データ内で 1 個の既知の割合を占めることができるものです。換言すれば、個別のコンポーネントが互いに無相関性のような、元の特徴の複合体である、コンポーネントと呼ばれる 1 つの新しいセットの機能を発現します。更に、これらは制限が付加されることで、第 1 コンポーネントが対象データ内で可能な限り巨大な可変率を占め、第 2 コンポーネントが第 2 番目に最大であり、そして以下も同様となることとなります。
より包括的な説明については、「https://docs.aws.amazon.com/sagemaker/latest/dg/how-pca-works.html」を参照してください。
PCA は、Exploratory Data Analysis (EDA) 用の 1 個のツールおよび 1 個の機械学習用アルゴリズム (ML) の両面でも強力です。EDA に関して、PCA はディメンジョナリティ低減および 1 件のデータ問題についての多重共線性 (マルチコ) 低減に最適です。ML 方法論の 1 つとして、異常検出 (例: ネットワーク内の疑わしいトラフィックの特定)、堅牢な予測 (数理ファイナンス)、分類 (例: 与信格付け) などを改善するために、PCA はその他の ML 方法論と組み合わせることができます。
技術の進歩により向上されたデータ収集能力が実現されているため、より大きなサイズおよびより細分化されたデータセットが実現されています。PCA は、ビッグデータ分析向けに非常に有用な ML ツールの 1 つです。しかしながら、PCA は容易には並列化できず、Amazon SageMaker 以前は、ビッグデータアプリケーションでも実用に関してはスケーラブルには対応はできませんでした。
このブログ記事では、Amazon SageMaker PCA 機能の速度およびスケーラビリティを実演することになります。サイズが増大しつつある行列に関して、Spark ML および Scikit-Learn のそれぞれの PCA 関数に対して、Amazon SageMaker PCA ランタイムが測定されることとなります。
Amazon SageMaker
Amazon SageMaker は、開発者やデータサイエンティストが、機械学習モデルをあらゆる規模で、迅速かつ簡単に構築、トレーニング、デプロイできるようにする AWS が提供する完全マネージド型プラットフォームのサービスです。Amazon SageMaker は、通常、機械学習を使用したい開発者の邪魔になるような障壁を排除することができます。Amazon SageMaker には、線形学習機能、K-means、DeepAR、PCA などのいくつかの組み込み型アルゴリズムを実装しています。
データセット
Amazon SageMaker PCA のスケーラビリティを実証するには、当社は実在するビッグデータセットの 1 個を選択しており、実在データセットの 4 倍の規模の観測標本数のデータおよび最大で 2 倍の機能項目数で、シミュレーションを実施しています。
実在のデータセット: NIPS Bag of Words (ニューラル情報処理システムズ会議の実在データセット)
このデータセットは、1987 年から 2015 年にわたって発行された NIPS 会議論文、「11,463-by-5,812 matrix of word counts [Perrone et al., 2016]」(11,463×5,812 規模の行列の形態での単語数の考察) の本文に掲載の単語数について配布物です。個別の列は、1 件の NIPS 論文をしており、当該論文に掲載された 11,463 個の単語の個別の引用回数が記載されています。各列の名称は、合計で 5,812 件の論文に関して、対応する NIPS 論文を「PublicationYear_PaperID」(発行年_論文ID) の形式により識別しています。このデータセットは、https://archive.ics.uci.edu/ml/datasets/NIPS+Conference+Papers+1987-2015# にて公開されています。
そのような 1 個のデータセットでの分析は、例えば、どのキーワードが 1 回の出版の可能性を高めるのか、またはより多数の引用件数につながるか可能性があるか、についての正しい情報を提供することができます。
シミュレートされたデータセット
当社のシミュレートされたデータセットは、20k 回の観測から構成され、個別に 5k、10k、15k、20k 個の特徴から構成されています。
コード: Amazon SageMaker を使用する PCA 実装
当社は、1 個の Conda MXNet カーネルを実装した ml.m4.xlarge SageMaker ノートブック・インスタンスを作成しました。実装の再現性に関する個別のステップに対応させるためにコードには行番号が含まれています。当社のコードは、ここからダウンロードできる自己完結型の機能する Sage-Maker ノートブックです。
NIPS データセットをダウンロードしてみましょう。対象行列の構成要素は転置されるため、各列は単語を表し、各行は論文の名称を表することになります。これは、5,812 x 11,463 の構成要素の行列が得られます。インデックス、即ち、各論文 ID の文字列が 1 個の冗長な列として含まれていないことを確認してください。当社の行列をバイナリストリームファイルオブジェクトとして取り込みます。
これで、当社 Amazon S3 バケットにファイルオブジェクトをアップロードする準備が整いました。次の 2 か所のパスを指定します: 1 個は、アップロードされた行列が存在する場所であり、もう 1 個は、Amazon SageMaker がその出力を書き込むことなる場所です。Amazon SageMaker は、既に存在しないパス内部に任意のフォルダーを作成します。
Amazon SageMaker の PCA セッションをインスタンス化するには、6 個の引数が必要です。第 1 の引数は、当社の SageMaker ノートブックが存在する [Region] (リージョン) に対応するコンテナアドレスです。例えば、us-east-1 はコンテナ 382416733822.dkr.ecr.us-east-1.amazonaws.com/pca:latest を保有。第 2 の引数は、このノートブックの作成に関連した、Amazon SageMaker IAM の役割です。 第 3 及び第 4 の引数については、当社 PCA を実行するための仮想環境として、train_instance_count of train_instance_type ml.c4.8xlarge の 1 個を指定しています。実際には、例えば、ml.p2.xlarge は ml.c4.8xlarge よりも安価であり、より短時間ででジョブを終了できるため、当社は、ml.p2.xlarge または ml.p3.xlarge などの GPU 搭載コンピューターを推奨します。ここでは、多数のコア数及び高容量メモリ向けに ml.c4.8xlarge インスタンスを選択しており、公平性のために、当実験にわたってこの同一のコンピュータータイプを使用します。第 5 の引数は、出力が書き込まれるために前述で定義したパスです。最後に、Amazon SageMaker セッション自体にも合格します。
ここまでで、Amazon SageMaker のトレーニングインスタンスパラメーターを指定しています。依然として、PCA アルゴリズムに関するハイパーパラメーターを指定する必要があります。ハイパーパラメーターとは、特徴の個数、返される主成分の期待される個数、行列分解に先立ち個別の列の平均値を減算するための 1 個のブール値、「通常」もしくは「ランダム化」PCA の実行の有無、最後に、ミニバッチのサイズです。
ここでは、対象入力として渡された当社の Amazon S3 データパスにより、PCA フィッティングを開始するだけです。Amazon SageMaker は、以下の対象形式について、S3 がある場所にある 1 個のログファイルに書き込みます:
https://console.aws.amazon.com/cloudwatch/home?region=<region> #logEventViewer:group=/aws/sagemaker/TrainingJobs;stream=<algo-YYYY-MM-DD-hh-mm-ss-SSS>/algo-<int>-<timestamp>
ログファイルの内容により、インスタンスのスピンアップまでの所要時間および PCA フィッティングの所要時間を比較勘案することができます。 オンプレミスのコンピューターを使用する場合と異なり、プロビジョニング時間は除外され、消費された分にのみ課金されます。当社はプロビジョニング対象の指定されたインスタンスの所要時間が約7分であること確認しております。対象の各インスタンスが準備完了すると、PCA がフィッティングされ、出力が 1 個の tar 形式ファイルとして指定済みの S3 の場所に書き込まれます。
そのコンテンツが MXNet ndarray 形式の一種として読み取ることができる、TAR 形式の出力をダウンロードしてみましょう。ndarray は次の 3 個の属性を有します: 各列の平均値を有する 1 個の配列、mean (平均値)、各特異値を有する 1 個の ndarray、s (配列)、及び各主成分ベクトルを有する 1 個の ndarray、v (配列) を有します。
その他のツールに対するパフォーマンス評価: SparkML および Scikit-Learn
当社は、Spark ML および とScikit-Learn が現在、大規模 PCA に対処しようとしているトップ 2 のオープンソースライブラリであると認識しています。
Spark は、一般的な統計アルゴリズムを実装したた分散機械学習ライブラリを有するクラスタコンピューティングフレームワークであり、ディスクベースの実装よりも 9 倍高速のベンチマークが確認されています [Rocha et al., 2017]。Scikit-Learn は、Python プログラミング言語用に開発された機械学習ライブラリです。当初は単一のコンピューター用に設計されたものでありましたが、その PCA の特定の実装は並列化されています [Pedregosa et al., 2011]。
当社は、実際の NIPS データとシミュレートされたデータの両方で、個別の環境ごとに関して同一の c4.8xlarge インスタンスをスピンアップさせて、ディメンジョナリティを増加させるための PCA ランタイムを記録しました。
結果
図 1 は、最大 1,000 個の特徴項目の行列の場合、Spark ML が Amazon SageMaker よりも PCA を約 90 倍低速で実行することを示しています。5,000 個を超過する特徴で、Spark ML は、所要時間が法外なものとなるため、このブログ記事の高ディメンジョンの比較から除外されています。
表 1: PCA テストケースごとの行列のディメンジョナリティ
| NIPSデータ: 5,811 件の観測 | シミュレートされるデータ: 20k 回の観測 |
| 最初の 50 個の特徴 | 5k 個の特徴 |
| 最初の 100 個の特徴 | 10k 個の特徴 |
| 最初の 500 個の特徴 | 15k 個の特徴 |
| 最初の 1k 個の特徴 | 20k 個の特徴 |
| 最初の 5k 個の特徴 | |
| 最初の 10k 個の特徴 | |
| 全ての 11,463 個の特徴 |
低ディメンジョンの行列の場合、Scikit-Learn の PCA のパフォーマンスは Amazon SageMaker のそれと同等です。図 1 は、5,000 個に接近する特徴を持つ場合にのみ、SageMaker が Scikit-Learn に比べて 5 倍の優位性を持つことを示しています。しかしながら、ここで、Scikit-Learn は非正方行列では完全な PCA を実行しないことに注意することが非常に重要です。Scikit-Learn が返すことになるコンポーネントの最大数は、min(num_observations; num_features) と等しくなります。換言すれば、Scikit-Learn は、num_observations の回数が num_features の個数を超過する場合、残存する観測回数を破棄します。そのため、ここで確認できる各ランタイムは、より小型サイズの行列を切り捨てたものです。
分析アプリケーションでの Scikit-Learn の有用性を制限することに加えて、更に、それは同時に並列化時試行回数に関して当社提供サービスも制限することになります。当社は、特徴のディメンジョナリティが対象サンプルサイズを決して超過しない状況で、シミュレート対象の各データセットを注視しました。図2は、Amazon SageMaker PCA が Scikit-Learn よりも約 5 倍高速であることを示しています。
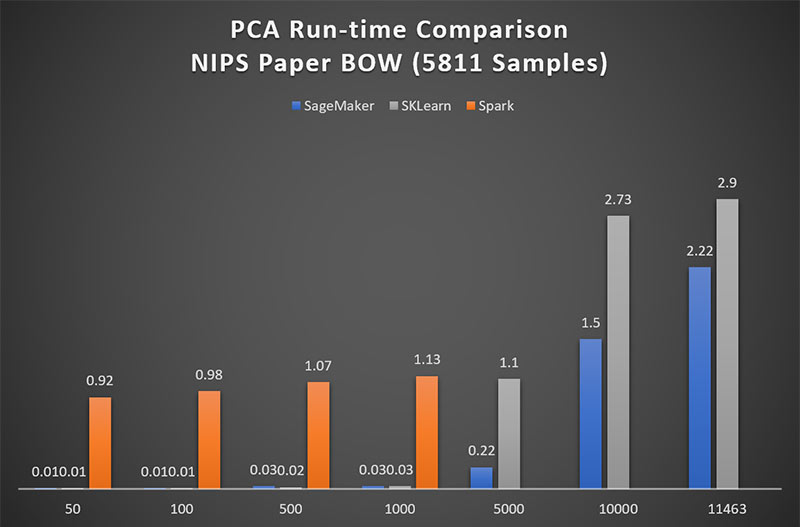
図1: Amazon SageMaker は Spark よりも 90 倍のパフォーマンスを達成
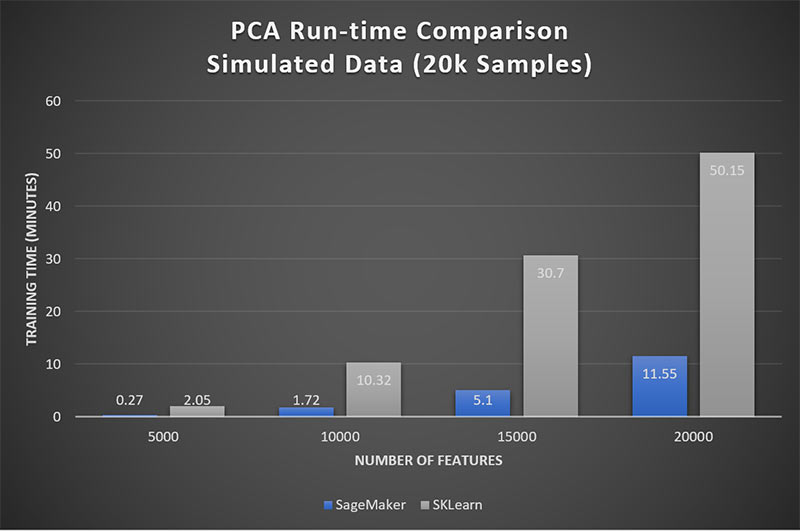
図2: Amazon SageMaker は Scikit-Learn よりも 5 倍のパフォーマンスを達成
まとめ
PCA は、データの可視化およびデータの無相関化に関して低ディメンジョンでの諸問題で常に重要性を示しています。しかしながら、現実世界の問題は益々巨大となるデータセットを取り扱っているため、高ディメンジョンの問題に関するスケーラブルな PCA がこれまで以上に重要性を増しています。このブログ記事では、Amazon SageMaker が PCA に関して最もスケーラブルなフレームワークを実現する上での優位性を示しました。
ここに記載されたコードは完全に自己完結型です。最初に、SageMaker ノートブックを開き、記載されているコードの数ブロックをコピーアンドペーストし、ここに表示されている NIPS 結果を複製します。または、これらのコードブロックが事前入力済みのこのノートブックをダウンロードするかします。このサーバーレスツールは、基盤となるプラットフォームおよびコンピューティングフレームワークを処理することになります。要求された個数のコンポーネント試行してみて、Amazon SageMaker がスケーリングする方法を確認してください。 更に、異なる観測および特徴の個数を有する自身のデータセットで当コードを試行することもできます。
参考文献
[Pedregosa et al., 2011] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. (2011).「Scikit-learn: Python での機械学習。Journal of Machine Learning Research, 12:2825{2830.4
(機械学習研究ジャーナル)」[Perrone et al., 2016] Perrone, V., Jenkins, P. A., Spano, D., and Teh, Y. W. (2016).「動的特徴モデルに関するポアソンランダム分布フィールド。arXiv preprint arXiv:1611.07460」。2
[Rocha et al., 2017] Rocha, A., Correia, A. M., Adeli, H., Reis, L. P., and Costanzo, S. (2017).「Recent Advances in Information Systems and Technologies (情報システムおよびテクノロジーでの最近の進歩)」, volume 3Springer.4
今回のブログ投稿者について
 Elena Ehrlich は、AWS プロフェッショナルサービス所属のデータサイエンティストです。彼女は、Imperial College London から数学博士号を授与され、防衛、金融、および広告テクノロジーを含む、様々な業界で活躍しています。現在、AWS の機械学習と AI ソリューションの開発および統合に向けて顧客と協業しています。
Elena Ehrlich は、AWS プロフェッショナルサービス所属のデータサイエンティストです。彼女は、Imperial College London から数学博士号を授与され、防衛、金融、および広告テクノロジーを含む、様々な業界で活躍しています。現在、AWS の機械学習と AI ソリューションの開発および統合に向けて顧客と協業しています。
 Hanif Mahboobi は、AWS プロフェッショナルサービス所属のデータサイエンティストです。彼は、2009 年に Sharif University of Technology から博士号を授与され、科学計算、複雑なシステムのモデリングおよびデータサイエンスの研究者として数年の経験を持っています。現在、様々な業界の AWS 顧客が機械学習および人工知能ソリューションを開発することを支援しています。
Hanif Mahboobi は、AWS プロフェッショナルサービス所属のデータサイエンティストです。彼は、2009 年に Sharif University of Technology から博士号を授与され、科学計算、複雑なシステムのモデリングおよびデータサイエンスの研究者として数年の経験を持っています。現在、様々な業界の AWS 顧客が機械学習および人工知能ソリューションを開発することを支援しています。