Amazon Web Services ブログ
ロールの連鎖を使用して、Amazon Redshift Spectrum 外部テーブルへのアクセスを Amazon Redshift IAM ユーザーとグループに制限する
Amazon Redshift Spectrum では、Amazon Redshift クラスターから中央 AWS Glue メタストアを使用して、Amazon Simple Storage Service (Amazon S3) データレイクのデータをクエリすることができます。この機能により、ご使用中の Amazon Redshift データウェアハウスにおけるペタバイト規模のデータ保存制限がなくなり、エクサバイトのデータへの拡張を低予算でできるようになります。Amazon EMR と同様に、オープンデータ形式と低料金のストレージによるメリットを享受しながら、Redshift Spectrum ノードを数千に拡張し、データのプル、フィルタリング、投影、集約、グループ化、ソートなどが行えます。Redshift Spectrum はサーバーレスであり、プロビジョニングや管理が不要な点で、Amazon Athena と同じです。お支払いは、1 TB のデータスキャンごとに 5 USD のみです。今回の記事では、ロールの連鎖を使用したきめの細いアクセス制御を有効化し、ユーザーの要求に忠実なアクセス管理を実現するための、Amazon Redshift でのセキュリティ設定方法をご説明していきます。
RedShift Spectrum を使用して Amazon Redshift と Amazon S3 のデータレイクを統合する、レイクハウスアプローチの使用を開始する際、クラスターにある異なる外部スキーマにアクセス権を付与するためには一定以上の柔軟性が必要です。たとえば、ここでは次のようなユースケースを考えます。2 つの Redshift Spectrum スキーマ(SA および SB)が、(それぞれに、A と B という)2 つのデータベースに対し AWS Glue データカタログにマッピングされて、Amazon Redshift からクエリが実行されたときに次のアクセスを許可します。
- IAM ユーザーグループ
Grp1だけに SA への select アクセスを許可 - IAM ユーザーグループ
Grp2だけにデータベース SB への select アクセスを許可 - データベース SA と SB への IAM ユーザーグループ
Grp3によるアクセスの禁止
デフォルトでは、Amazon Redshift クラスターに割り当てられた AWS Identity and Access Management (IAM) ロールにより定義されたポリシーが、クラスター内のすべてのユーザーおよびグループによって継承される Redshift Spectrum のテーブルアクセスを管理します。クラスターに割り当てられたこの IAM ロールでは、異なるユーザーやグループに対し、簡単に制限を加えることができません。この記事では、Amazon Redshift クラスター内の異なるユーザーに対し、きめ細やかな認証ポリシーを適用するのに必要となる設定手順を詳細に解説します。また、IAM ロールの連鎖を使用して、異なる Redshift Spectrum スキーマとテーブルに対するアクセスを制御する方法もご紹介します。ロールの連鎖を使用することで、クラスターの変更は必要なくなり、すべての修正を IAM 側でできるようになります。新規ロールを追加しても、Amazon Redshift は一切変更する必要がありません。本稿執筆時点では、たとえAWS Lake Formation を使用したとしても、Redshift Spectrum スキーマとテーブルに対し、このレベルの分離された、大まかなアクセス制御はできません。クロスアカウントのクエリの詳細については、「Amazon S3 で AWS KMS 暗号化データのクロスアカウント Amazon Redshift COPY および Redshift Spectrum クエリを有効にする方法」をご参照ください。
前提条件
この記事では、AWS Glue クローラにより AWS Glue 内でカタログ化され Amazon S3 に保存されている、TPC-DS 3 TB パブリックデータセット、および小売り部門に関するサンプルのデータセットを使用していきます。この作業を始めるには、次に挙げる前提条件を満たす必要があります。最初の 2 つの条件は、この記事の内容から外れていますが、Amazon S3 データレイク内の既存のクラスターとデータセットを使用することも可能です。
- Amazon Redshift クラスターを、IAM ロールの割り当てを行いながら(あるいは行わずに)作成します。
- Amazon S3 にあるデータレイクのデータを使用するデータベースを含む AWS Glue データカタログを、AWS Glue クローラ、Amazon EMR、AWS Glue、Athena のいずれかを使用して作成します。データベースには、異なる Amazon S3 パスを指している、1 つ以上のテーブルが必要です。今回は、業界の標準である TPC-DS 3 TB データセットを使用しましたが、ご自身のデータセットを使用することも可能です。
- 後に使用するため、Amazon Redshift 内に次のような IAM ユーザーとグループを作成します。
grpAとgrpBの名称で、ポリシーを定義しない新規の IAM グループを作成します。- ユーザー、
a1およびb1を作成し、対応するgrpAとgrpBにそれぞれ追加します。ユーザー名は小文字を使用してください。 - 作成したすべてのグループに次のポリシーを追加し、Amazon Redshift に対する認証が行われる際の一時的な承認を、IAM ユーザーに付与します。
さらにセキュリティを高める場合には、クラスター内で特定のユーザーとグループを許可する、より制限の強いアクセス制御をこのポリシーに適用する必要性もあります。
- Amazon Redshift クラスターにおいて、パスワードを使用しないローカルな IAM ユーザーおよびグループを作成します。
- 次のコードを入力し、
a1を作成します。 - 次のコードを入力し、
grpAを作成します。 - 前出の手順をユーザー
b1にも繰り返し、grpBにユーザーとして追加します。
- 次のコードを入力し、
- SqlWorkbenchJ などの JDBC SQL クエリクライアントを、クライアントマシンにインストールします。
ユースケース
ここからのユースケースでは、tpcds3tb と名前が付けられたデータベースを含む、AWS Glue データカタログを使用します。このデータベース内のテーブルは、単一のバケットにある Amazon S3 を指していますが、それぞれが、このバケットの下の異なるプレフィックスにマッピングされています。以下のスクリーンショットに、それぞれの異なるテーブルロケーションを示します。

データベースは tpcds3tb を使用し、また schemaA という名前で Redshift Spectrum の外部スキーマを作成します。異なる IAM ユーザーをマッピングしながら、それぞれ、grpA と grpB という名前のグループを作成します。ここでの目的は、grpA と grpB のそれぞれに、schemaA 内にある外部テーブルへの異なるアクセス権限を付与することです。
今回は、このソリューションとして、次のような 2 つのオプションを示しています。
- Amazon Redshift の
GRANT USAGEステートメントを使用し、grpAにschemaA内の外部テーブルに対するアクセス権を付与します。各グループからは、このスキーマで定義されたデータレイクにあるすべてのテーブルに対しアクセスが可能jです。そのテーブルが Amazon S3 内でマッピングされている場所には影響を受けません。 - Amazon S3 の外部スキーマに対しロールの連鎖を定義します。これにより、特定のデータレイクロケーションへのグループアクセスが分離され、スキーマ内で別の Amazon S3 ロケーションを指しているテーブルへのアクセスが拒否されます。
ユーザーとグループアクセスの GRANT USAGE(使用許可)権限を使用た分離
schemaA において、Amazon Redshift の GRANT USAGE 権限を使用すると、スキーマにあるすべてのオブジェクトへのアクセスを、grpA に許可することができます。grpB には、使用権限を一切付与しません。つまり、このグループ内にいるユーザーからのクエリは拒否されます。
- Amazon Redshift クラスターで
mySpectrumという名前の IAM ロールを作成し、次のようなポリシーを使用しながら、Redshift Spectrum による Amazon S3 オブジェクトの読み込みを許可します。 - Amazon Redshift 内のユーザーが、クラスターに割り当てられたロールを引き受けられるように、信頼関係を追加します。次にそのコードを示します。
- クラスター名を選択します。
- [Properties(プロパティ)] をクリックします。
- [Manage IAM roles(IAM ロールの管理)] をクリックします。
- [Available IAM roles(使用可能な IAM ロール)] から、新たに作成したロールを選択します。ロールが表示されていない場合は、[Enter ARN(ARN を入力)] をクリックしロールの ARN を入力します。
- [Done(完了)] をクリックします。スクリーンショットを次に示します。
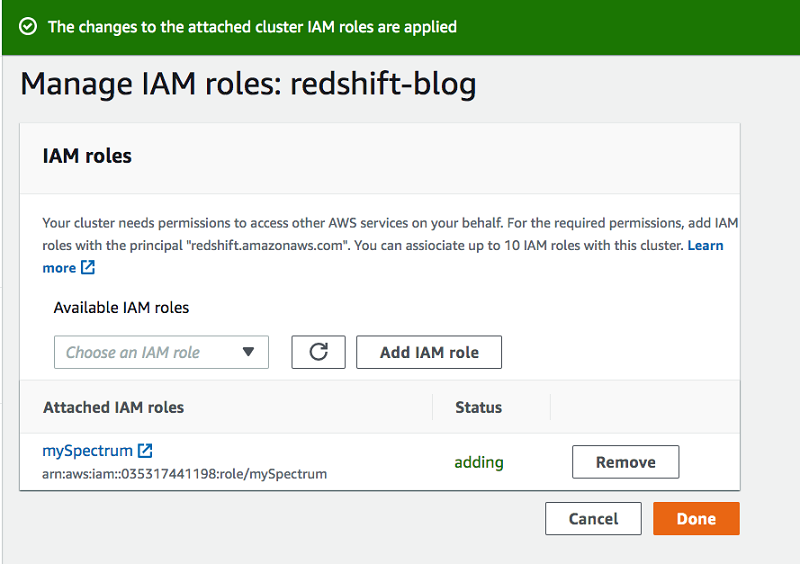
- AWS SDK が含まれている Amazon Redshift JDBC ドライバーを使用するために、Amazon Redshift コンソール(次のスクリーンショット参照)からダウンロードします。次に、SqlWorkbenchJ などの SQL クライアントから IAM 接続文字列を使用し、このドライバーをクラスターに接続します。次のスクリーンショットは、ここで選択できる jar ファイルを示しています。
 次のスクリーンショットに Workbenchj を使用しての接続設定を示します。
次のスクリーンショットに Workbenchj を使用しての接続設定を示します。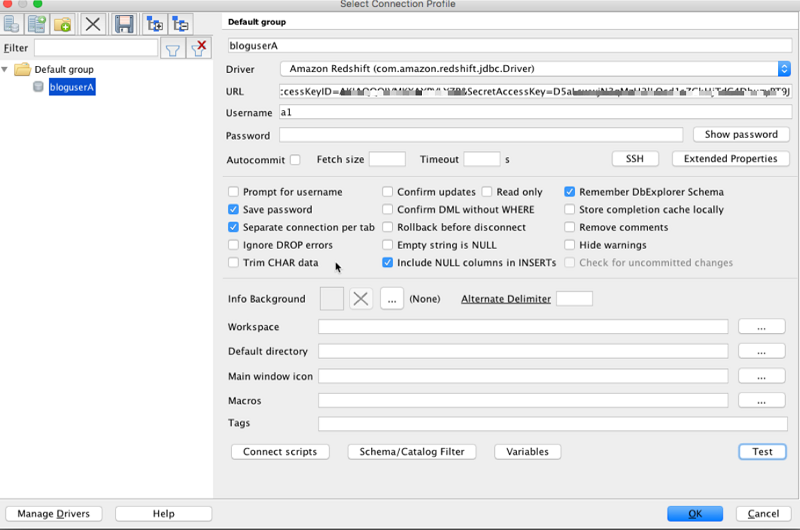
- Amazon Redshift の管理者として、AWS Glue のデータベース
tpcds3tbにマッピングされているschemaAを使用する外部スキーマを作成します(先に作成済みの IAM ロールを使用し、Redshift Spectrum による Amazon S3 へのアクセスを許可します)。次にそのコードを示します。 - 次のコードで、スキーマが Amazon Redshift カタログの中に存在することを確認します。
grpAに使用権限を付与します。次にそのコードを示します。- SQL クライアントを使用して、
grpAのユーザー a1 として、schemaA内のテーブルに対しクエリを送ります。次にそのコードを示します。クエリが成功した場合は、結果が次のスクリーンショットのように表示されます。

grpBのユーザーb1としてschemaA内のテーブルにクエリを送ると、次のスクリーンショットのようなエラーメッセージが表示されます。
このオプションを使用することで、Redshift Spectrum スキーマにおいてユーザーのアクセスを分離するための、大幅な柔軟性が提供されます。とは言え、ユーザー b1 に、このスキーマ内にある(すべてではないにせよ)複数のテーブルへのアクセス権が、付与されていたとしたらどうでしょうか? 2 つめのオプションにより、きめの粗いアクセス制御ポリシーが作成できます。
IAM ポリシーとロールの連鎖を使用してのユーザーおよびグループアクセスの分離
信頼関係を作成することで、アクセスしようとする Amazon S3 ロケーションに基づきながら、IAM ロールにマッピングされた IAM ポリシーを特定のユーザーとグループに適用することができ、アクセスをクラスターに割り当てることができます。今回のユースケースでは、grpB は s3://myworkspace009/tpcds3t/catalog_page/ に置かれたテーブルのcatalog_page にのみアクセス可能であり、一方 grpA は、s3://myworkspace009/tpcds3t/* に配置された、catalog_page を除く全テーブルへアクセスが可能です。次に示す手順により、このセキュリティ要件のための設定が行えます。
次の図で、ロールの連鎖の仕組みを説明します。

まず、grpA と grpB にそれぞれ専用のポリシーを含む IAM ロールを作成します。1 つめのロールは基本的なクラスターロールです。これは、ロールで定義した信頼関係を使用し、ユーザーがこのロールを引き受けられるように許可します。
- IAM コンソールから新規のロールを作成します。次にそのコードを示します。
- このロールに、次の 2 つのポリシーを追加します。
-
AWSAWS GlueConsoleFullAccessという名前のマネージドポリシーを追加します。セキュリティ要件からの制限がより厳しい場合には、このマネージドロールの代わりに、最小限の権限を与えるインラインポリシーを追加することも考えられます。- 次のようなルールを含む、
myblog-redshift-assumerole-inlineという名前のインラインポリシーを追加します。
- このクラスター内のユーザーが、このロールを引き受けられるようにするための、信頼関係を追加します。必要であれば、この対象を特定ユーザーに制限することも可能です。次にそのコードを示します。
- Redshift のカスタム化可能なロールを、
grpA専用に新規作成します。このポリシーでは、このグループにアクセスが許可される Amazon S3 ロケーションが定義されます。ただし、このグループにはcatalog_pageテーブルのデータ参照を許可しないので、これに関する Amazon S3 ロケーションはポリシーから除いておきます。
-
- このロールに
myblog-grpA-roleと名前を付けます。
- このロールに
- このロールに、次の 2 つのポリシーを追加します。
-
AWSAWS GlueConsoleFullAccessという名前のマネージドポリシーを、このロールに追加します。(注: セキュリティ要件からの制限がより厳しい場合には、このマネージドロールの代わりに、最小限の権限を与えるインラインポリシーを追加することも考えられます。)- 次のルールを使用するインラインポリシーを、
myblog-grpA-access-policyという名前で追加します(セキュリティ要件と最小限のアクセス許可に合わせるには、このポリシーを修正します)。
grpA内の全ユーザーを明示的にリストする信頼関係を追加し、各ユーザーがこのロールだけを引き受けられるようにします([Trust relationships(信頼関係)] タブを開き、次に示すポリシーを追加し、関係するアカウント詳細設定を更新します)。このロールに追加されるユーザーに対しては、毎回この信頼関係を更新する必要があります。もしくは、各ユーザーで新規ロールを作成します。個別の新規ユーザーに対し、この信頼関係を自動的に適用するスクリプトは、さほど難しくはありません。grpB専用に、Redshift のカスタム化可能なもう 1 つのロールを新規作成します。このポリシーでは、このグループにアクセスが許可される Amazon S3 ロケーションのみに、アクセスが制限されます。
-
- このロールに
myblog-grpB-roleと名前を付けます。
- このロールに
- このロールに、次の 2 つのポリシーを追加します。これらのマネージドポリシーを、各 DB グループごとのデータアクセス権限を反映させながら作成します。その上でこのポリシーを、クラスター上で引き受けられた各ロールにアタッチします。
-
AWSAWS GlueConsoleFullAccessという名前のマネージドポリシーを、このロールに追加します。セキュリティ要件からの制限がより厳しい場合には、このマネージドロールの代わりに、最小限の権限を与えるインラインポリシーを追加することも考えられます。- 次のルールを使用するインラインポリシーを、
myblog-grpB-access-policyという名前で追加します(セキュリティ要件と最小限のアクセス許可に合わせるには、このポリシーを修正します)。
grpB内の全ユーザーを明示的にリストしている信頼関係を追加し、各ユーザーがこのロールだけを引き受けられるようにします([Trust relationships(信頼関係)] タブを開き、次に示すポリシーを追加し、関係するアカウント詳細設定を更新します)。このロールを引き受けるユーザーに対しては、毎回この信頼関係を更新する必要があります。もしくは、各ユーザーで新規ロールを作成します。この信頼関係の自動更新は、スクリプトで比較的容易に実行できます。- これら 3 つのロールを Amazon Redshift クラスターにアタッチし、このクラスターにマッピングされている他のロールを削除します。ドロップダウンメニューにロールが 1 つも表示されていない場合は、ARN ロールを選択します。
- 管理ユーザーとして、
grpAとgrpBに、それぞれ新しい外部スキーマを作成します。これには、先に作成してある 2 つのロールによる、ロールの連鎖を使用します。
-
- [
grpA] に次のコードを入力します。 - [
grpB] に次のコードを入力します。
- [
grpAそしてgrpB内のユーザーとして、外部スキーマにクエリを送ります。
-
- 次のコードを入力し、
grpAのユーザーa1として、カスタマーテーブルとcatalog_pageテーブルにクエリを送ります。
- 次のコードを入力し、
次のクリーンショットで示すクエリ結果では、ユーザー a1 が、カスタマーテーブルへのアクセスに成功したことが確認できます。

次のスクリーンショットからは、a1 が catalog_page にアクセスできなかったことがわかります。

-
grpBのユーザーb1としても、カスタマーテーブルとcatalog_pageテーブルにクエリを送ります。
次のスクリーンショットで、ユーザー b1 が catalog_page に正常にアクセスできたことが確認できます。

また、次のスクリーンショットでは、ユーザー b1 がカスタマーテーブルにはアクセスできなかったことがわかります。

まとめ
今回の記事では、外部スキーマとテーブルに対するアクセスを、ユーザーおよびグループで分離するための、2 つの異なる手法についてご紹介しました。GRANT USAGE ステートメントを使用する 1 つめの手法では、テーブルが指している Amazon S3 データレイクのパスに関わらず、権限を与えられたグループはスキーマ内のすべてのテーブルにアクセスできます。このアプローチはアクセス権限付与が容易で非常に柔軟性がありますが、スキーマ内の特定のテーブルへのアクセスを受け入れたり拒否したりすることができません。
2 つめのオプションを使用すると、Amazon S3 オブジェクト単位でユーザーとグループによるアクセスを管理できます。これにより、データセキュリティをより詳細に制御できるようになり、不正なデータアクセスのリスクを低減できます。このアプローチでは、1 つめのケースに比べいくつか追加の設定作業が必要ですが、より良いデータセキュリティを実現できます。
どちらのアプローチにおいても、Amazon S3 パス、外部スキーマ、およびテーブルマッピングに関し、ユーザーのグループによるアクセス権を最も高くするように、適切なガバナンスモデルを事前に構築する必要があります。これにより、最良のセキュリティと低い運用オーバーヘッドを提供できます。
価値あるコメントと提案をいただいた AWS の同僚 Martin Grund 氏に対し、特別に謝意を表したいと思います。
著者について
 Harsha Tadiparthi は、AWS Analytics のシニアソリューションアーキテクトです。 彼は、データベースおよび分析の領域において、お客様の複雑な問題を解決し、成果を上げることに熱心に取り組んでいます。仕事以外では、時間が許す限り、家族と過ごしたり、映画鑑賞をしたり、旅行を楽しんでいます。
Harsha Tadiparthi は、AWS Analytics のシニアソリューションアーキテクトです。 彼は、データベースおよび分析の領域において、お客様の複雑な問題を解決し、成果を上げることに熱心に取り組んでいます。仕事以外では、時間が許す限り、家族と過ごしたり、映画鑑賞をしたり、旅行を楽しんでいます。
 Harshida Patel は、AWS のデータウェアハウススペシャリストソリューションアーキテクトです。
Harshida Patel は、AWS のデータウェアハウススペシャリストソリューションアーキテクトです。