概要
Amazon SageMaker では、TensorFlow、MXNet、Chainer、PyTorch、scikit-learn といった機械学習フレームワークをサポートしています。これらのフレームワークを利用して機械学習による予測結果を得るためには、学習した機械学習モデルをエンドポイントにデプロイする必要があります。複数のモデルを利用したい場合、モデル一つ一つに対してエンドポイントを作成する方法が一般的ですが、推論リクエストが少ないモデルに対してエンドポイントを常時起動すると、推論処理に対するコストが高くなってしまいます。そこで、推論リクエストの少ないモデルを、他のモデルと同じエンドポイントにデプロイし、常時起動するインスタンス数を低減する方法があります。この手法はリアルタイム処理が必要な場合は特に有効です。なお、推論処理がリアルタイム性を要求しない場合はバッチ変換ジョブをご利用ください。
本記事では、複数のモデルを一つのエンドポイントにデプロイする方法について説明いたします。Amazon SageMaker がサポートする全ての機械学習フレームワークで、複数のモデルを一つのエンドポイントにデプロイすることができますが、ここでは Tensorflow Serving を利用して、複数のモデルをデプロイする方法について説明します。例として、軽量な物体検出モデル SSD MobileNet と、軽量な画像分類モデル MobileNet を1つのインスタンスにデプロイします。デプロイまでの手順の概要は以下のとおりです。
- 複数の TensorFlow モデルを TensorFlow Serving にデプロイ可能な SavedModel 形式で保存します。
- 保存したモデルを1つのアーカイブファイル (tar.gz 形式) にして、Amazon S3 (S3) にアップロードします。
- Amazon SageMaker の API を利用して、1 つのインスタンスにデプロイし、テストします。
それでは各手順について以下で説明します。
1. TensorFlow モデルの保存
Jupyter Notebook からコードを実行し、TensorFlow の学習済みモデルをダウンロードして、以下のような SavedModel 形式で保存します。model1 を SSD MobileNet、model2 を MobileNet とします。TensorFlow モデルには、SavedModel 形式以外の学習済みモデルが公開されている場合があるので、必要に応じて変換します。今回は SSD MobileNet と MobileNet の両モデルを変換します。
./multi
├── model1
│ └── 0
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
│
└── model2
└── 0
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
1-1. 物体検出用モデルの取得
TensorFlow detection model zoo から、SSD MobileNet の学習済みモデルをダウンロード・解凍し、SavedModel 形式に変換します。解凍したファイルの中から、学習済みモデルのファイル frozen_inference_graph.pb を TensorFlow のグラフとして読み込み、builder.save() を利用して保存することで SavedModel 形式のモデルを得ることができます。ルート(この場合は ./multi/model1/0/ )を指定すれば、上記の通りに保存されます。また、 デプロイした際に、bounding box や score なども返すように signature を定義します。
export_dir = 'multi/model1/0/'
graph_pb = 'ssd_mobilenet_v1_coco_2018_01_28/frozen_inference_graph.pb'
builder = tf.saved_model.builder.SavedModelBuilder(export_dir)
with tf.gfile.GFile(graph_pb, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
sigs = {}
with tf.Session(graph=tf.Graph()) as sess:
tf.import_graph_def(graph_def, name="")
g = tf.get_default_graph()
input_image = g.get_tensor_by_name("image_tensor:0")
detection_boxes = g.get_tensor_by_name('detection_boxes:0')
detection_scores = g.get_tensor_by_name('detection_scores:0')
detection_classes = g.get_tensor_by_name('detection_classes:0')
num_detections = g.get_tensor_by_name('num_detections:0')
sigs[signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY] = \
tf.saved_model.signature_def_utils.predict_signature_def(
{"input": input_image},
{"boxes": detection_boxes,
"scores": detection_scores,
"classes": detection_classes,
"n_detect": num_detections} )
builder.add_meta_graph_and_variables(sess,
[tag_constants.SERVING],
signature_def_map=sigs)
builder.save()
1.2. 画像分類用モデルの取得
画像認識用のモデル MobileNet の学習済みモデルはこちらからダウンロードできます。こちらは TF-Slim 用のモデル形式なので、モデルのファイルmobilenet_v1_0.25_128.ckptを読み込んで、SavedModel 形式に保存します。モデルを読み込むため、学習済みモデルとともに提供されている Python スクリプトをダウンロードし、 import mobilenet_v1 でインポートして利用します。先ほどと同様に、./multi 以下に model2/0 を作成して、モデルを保存します。variables 以下のファイルも保存する必要があります。
checkpoint_file = 'mobilenet_v1_0.25_128.ckpt'
# Initialize the network.
tf.reset_default_graph()
# Define the network and load checkpoint
input_tensor = tf.placeholder(tf.float32, shape=(None,128,128,3), name='input_image')
sess = tf.Session()
import mobilenet_v1
with tf.contrib.slim.arg_scope(mobilenet_v1.mobilenet_v1_arg_scope()):
logits, end_points = mobilenet_v1.mobilenet_v1(inputs=input_tensor, depth_multiplier=0.25, is_training=False, num_classes = 1001)
saver = tf.train.Saver()
saver.restore(sess, checkpoint_file)
export_path = "./multi"
tf.saved_model.simple_save(
sess,
os.path.join('multi/model2/0/'),
inputs={'input_image': input_tensor},
outputs={'output': end_points['Predictions']})
2. 二つのモデルを一つのファイルにまとめて、S3 にアップロード
フォルダ ./multi 以下に2種類のモデルが保存されました。これを一つのアーカイブファイル multi.tar.gz にして S3 にアップロードします。アップロード先は変数 models に格納され、デプロイするときに参照されます。
!tar -czvf multi.tar.gz ./multi
import sagemaker
from sagemaker import get_execution_role
sagemaker_session = sagemaker.Session()
models = sagemaker_session.upload_data(path='./multi.tar.gz', key_prefix='pretrained_model/multiple_models/')
3. 複数モデルをデプロイし、テストする
アップロードした multi.tar.gz を利用して複数のモデルをデプロイします。デフォルトでどちらのモデルを推論に使用するか、環境変数 env で設定しておきます。ここでは物体検出用モデルがデフォルトで使用されるようにしています。deploy() を呼び出す操作は、一つのモデルをデプロイする通常の場合と同じです。
from sagemaker.tensorflow.serving import Model, Predictor
role = get_execution_role()
env = {
'SAGEMAKER_TFS_DEFAULT_MODEL_NAME': 'model1'
}
model = Model(model_data=models, role=role, framework_version='1.12', env=env)
predictor = model.deploy(initial_instance_count=1, instance_type='ml.c5.xlarge')
推論のテストを行うために次の犬の画像を利用します。こちらの画像を Jupyter Notebook と同じディレクトリに dog.jpg というファイル名で保存してください。

あらかじめ物体検出と画像分類それぞれのラベルを1行ずつ記述した coco_labelmap.txt と mobilenet_labelmap.txt を用意します。これらも Jupyter Notebook や画像ファイルと同じディレクトリに保存してください。ここでは、これらのテキストファイルを読み込んで、ラベル ID に対応するラベルの名前がわかるようにします。
# Load labelmap for object detection
object_label_map = []
with open('coco_labelmap.txt', 'r') as f:
for line in f:
object_label_map.append(line.strip())
#Load labelmap for image classification
cls_label_map = []
with open('mobilenet_labelmap.txt', 'r') as f:
for line in f:
cls_label_map.append(line.strip())
それでは実際に SSD MobileNet を使って、物体検出の推論を行ってみます。
%matplotlib inline
from PIL import Image
import matplotlib.patches as patches
import matplotlib.pyplot as plt
import numpy as np
# Load image and resize it for inference.
pil_img = Image.open('dog.jpg')
height, width, _ = np.array(pil_img).shape
#Preprocess for base model
image = pil_img.resize((128,128)).convert('RGB')
image = np.array(image)
im = image.reshape(128,128, 3)
#Inference by base model
result = predictor.predict({"input":im})
# Extract results of which score is larger than 0.5
scores = result['predictions'][0]['scores']
good_scores = [score for score in scores if score > 0.5]
# Parse result data
rect = []
label = []
score = []
for i in range(len(good_scores)):
# Extract box data and generate rectangle objects to be draw on image later
box = result['predictions'][0]['boxes'][i]
y_min = box[0]*height
x_min = box[1]*width
y_max = box[2]*height
x_max = box[3]*width
im_width = x_max - x_min
im_height = y_max - y_min
rect.append(patches.Rectangle((x_min,y_min),im_width,im_height,linewidth=1,edgecolor='b',facecolor='none'))
# Store the label name
label_id = result['predictions'][0]['classes'][i]
label.append(object_label_map[int(label_id)])
# Store score
score.append(good_scores[i])
# Display the image with bounding boxes, labels and scores.
fig,ax = plt.subplots(1)
ax.imshow(np.array(pil_img))
for index in range(len(rect)):
ax.add_patch(rect[index])
caption = label[index] + ": " + str(score[index])
plt.text(x_min,y_min-10,caption,fontsize='12', color = 'b')
print(caption)
plt.show()
こちらのような出力が得られるはずです。
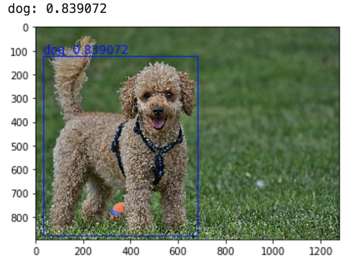
次に画像分類を試します。画像分類モデルはデフォルトに設定されたモデルではないため、画像分類モデル model2 を呼び出すPredictorを作成します。predictを利用することによって、画像分類の結果を取得することができます。
%matplotlib inline
# get the endpoint name from the default predictor
endpoint = predictor.endpoint
# Load image and resize it for inference.
pil_img = Image.open('dog.jpg')
height, width, _ = np.array(pil_img).shape
#Preprocess for base model
image = pil_img.resize((128,128)).convert('RGB')
# image = (np.array(image)/255 - 0.5 )*2
image = np.array(image)
im = np.array(image.reshape(-1, 128,128,3))
# get a predictor for 'model2'
model2_predictor = Predictor(endpoint, model_name='model2')
class_id=np.argmax(model2_predictor.predict(im)['predictions'][0]['probabilities'])
probability = model2_predictor.predict(im)['predictions'][0]['probabilities'][class_id]
print(cls_label_map[class_id] + ": " + str(probability))
fig,ax = plt.subplots(1)
ax.imshow(np.array(pil_img))
plt.show()
出力のサンプルは次のとおりです。

これで二つのモデルが一つのエンドポイントへとデプロイできることが確認できました。最後に、動作確認を完了し、必要のなくなったエンドポイントを、sagemaker.Session().delete_endpoint(predictor.endpoint) で削除しましょう。
まとめ
本稿では TensorFlow のデプロイ環境として TensorFlow Serving を利用し、複数モデルを Amazon SageMaker で作成した一つのエンドポイントへとデプロイする方法を示しました。複数モデルを一つのエンドポイントへとデプロイすることでコストを抑えながらリアルタイムに推論する環境を提供することができます。Amazon SageMaker では今回ご紹介した機械学習モデルのデプロイ以外にも、機械学習モデルの開発やトレーニング、データのラベル付け、ハイパーパラメータ最適化、トレーニング済モデルのコンパイルなどの機能がお使い頂けます。皆様が Amazon SageMaker を利用して機械学習を使ったサービスを構築する際は、このブログ記事がご参考になれば幸いです。
著者について

奥野 友哉 (Tomoya Okuno, Ph.D.) は AWS のソリューション アーキテクトで、反応流体計算・宇宙・機械学習の分野に興味があります。休日はコーヒーが美味しいカフェで過ごしています。

鮫島 正樹 (Masaki Samejima, Ph.D.) は AWS の機械学習スペシャリスト ソリューション アーキテクトで、コンピュータビジョンや時系列解析などを得意にしています。