Amazon Web Services ブログ
AWS クラウドの GPU を使用した、スケーラブルなマルチノードの深層学習トレーニング
産業規模のデータセットでディープニューラルネットワークを幅広く採用する際、大きな障壁となるのは、それらをトレーニングするのに必要な時間とリソースです。AlexNet は、2012 年の ImageNet Large Scale Visual Recognition Competition (ILSVRC) を受賞し、現在のディープニューラルネットワークのブームを打ち立てましたが、120 万個の画像、1000 カテゴリのデータセット全体をトレーニングするのに約 1 週間かかっていました。機械学習モデルの開発と最適化は、反復的なプロセスです。新しいデータでモデルを頻繁に再トレーニングし、モデルとトレーニングのパラメータを最適化することで、予測精度を向上します。2012 年以降 GPU のパフォーマンスが大幅に向上し、トレーニング時間は数週間から数時間に短縮しましたが、機械学習 (ML) の専門家は、モデルトレーニング時間をさらに短縮しようと努力しています。 同時に、予測精度を向上させるために、モデルはますます大きくなり複雑化し、よって、計算リソースの需要も増加しています。
クラウドがディープニューラルネットワークをトレーニングするためのデフォルトオプションとなったのは、オンデマンドでの拡張が可能で、俊敏性が向上しているためです。さらに、クラウドを使用することで簡単に始めることができ、プリペイド使用モデルもあるからです。
このブログ記事では、分散 / マルチノード同期トレーニングを使用して、深層学習トレーニング時間をさらに最小限に抑えるため、AWS インフラストラクチャを最適化する方法をご紹介します。ImageNet データセットでは ResNet-50 を、NVIDIA Tesla V100 GPU では Amazon EC2 P3 インスタンスを使用して、トレーニング時間をベンチマークします。90 エポックの標準的なトレーニングスケジュールを使ったモデルを、わずか 8 つの P3.16xlarge インスタンス (64 V100 GPU) を使用して、約 50 分で 75.5% を超える最上位の検証精度になるようトレーニングします。
ML 専門家はモデルの構築とトレーニングに様々な機械学習フレームワークを使用するため、Apache MXNet と Horovod を装備した TensorFlow を使ったパフォーマンス結果を示すことで、AWS クラウドの多様性を実証します。Amazon EC2 P3 インスタンスでは、いろんなモデルタイプ (CNN、RNN、および GAN) を柔軟にトレーニングすることも可能です。ですので、ここで概要を述べている高性能コンピューティングアーキテクチャは、様々なフレームワークやモデルタイプにわたって効率的に拡張することが期待できます。
達成したパフォーマンスと結果
まず、8 つの P3.16xlarge インスタンスを使用して達成できたパフォーマンスと検証精度を確認します。
| フレームワーク | トレーニングする時間 | トレーニングスループット | 達成した最上位の検証精度 | スケーリング効率 |
| Apache MXNet | 47 分 | ~44,000 画像 / 秒 | 75.75% | 92% |
| TensorFlow + Horovod | 50 分 | ~41,000 画像 / 秒 | 75.54% | 90% |
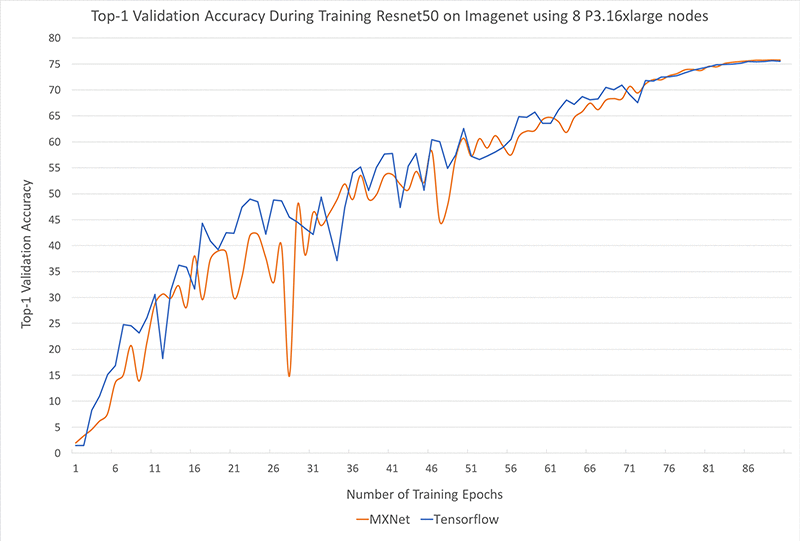
トレーニングまでの時間 – 8 つの P3.16xlarge インスタンスでは、MXNet を使用する場合はエポックあたり平均時間 31 秒、TensorFlow を使用した場合は平均 33 秒の時間を観測しました。これは、ImageNet データセット上で、MXNet で 47 分、TensorFlow で 50 分のトレーニング実測時間が 90 エポックを超えるほど変動し、最上位の検証精度がそれぞれ 75.75% と 75.54% になったことになります。 両フレームワークにおいて、ここで示している時間は、各エポックでのトレーニングとチェックポイントの時間を含んでいます。MXNet のトレーニングジョブを TensorFlow の標準的ワークフローと矛盾なく維持するため、各エポックの終わりではなく、トレーニングの最後にのみ検証を行います。
マルチノードトレーニングスループット – GPU あたり 256 個のバッチサイズ (~16,000 の総バッチサイズ) を持つ 8 つの P3.16xlarge インスタンス (64 V100 GPU) 上での混合精度を使ってトレーニングし、TensorFlow で約 41,000 画像/秒、MXNet で約 44,000 画像 / 秒となり、ほぼ直線的なスケーリングになりました。 TensorFlow では、スケーリング効率を向上させるために、ネイティブのパラメータサーバーアプローチの代わりに、分散トレーニングフレームワークの Horovod を使用しました [6]。MXNet には、ネイティブのパラメータサーバーアプローチを使用しました。MXNet のスケーリング効率は、単一ノードの kvstore タイプ ‘device’ と、複数ノードの ‘dist_device_sync’ を使って計算しました。今後の作業では、MXNet を介した分散型トレーニング用のオールリダクションベースのアプローチを使用するため、パフォーマンスをさらに向上させることが可能です。
検証精度 – 次のグラフは、8 つの P3.16xlarge インスタンスを使用した、ImageNet 上の Resnet50 のトレーニング中での最上位の検証精度を示しています。MXNet と TensorFlow の両方に同様のトレーニング設定をしたところ、両方のフレームワークの収束動作が非常に似ていることが分かりました。
クラスターアーキテクチャ:
使用した高性能コンピューティングクラスターの図を、次に示します。Horovod と TensorFlow を併用する場合、パラメータサーバー用の M4 インスタンスは必要ありません。
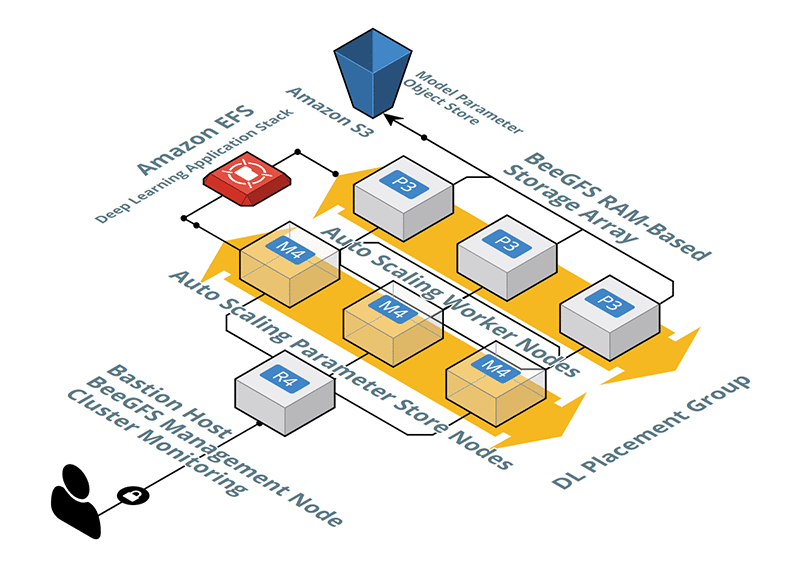
コンピューティングクラスターの RAM をストレージターゲットとして使用し、共有ストレージを作成しました。並列ファイルシステム (BeeGFS) を使用して、RAM ターゲットを各ノードのグローバル名前空間として公開します。このアプローチか、代わりに Amazon EBS、Amazon S3、または Amazon EFS ストレージサービスを使用して、トレーニングデータを入手できます。
コンピューティングクラスターは、グローバル名前空間からデータをロードし、それを (切り取り、反転、またはぼかしを使用して) 増強し、次に、順方向パス、誤差逆伝搬、勾配同期、および重み更新を実行します。8 つの p3.16xlarge インスタンスを使用します。各インスタンスは、8 つの NVIDIA Tesla V100 GPU、64 の仮想 CPU、488 GB のメモリ、25 Gb/s のネットワーク帯域幅を持ちます。
MXNet はパラメーターサーバーアプローチを使用します。ここでは、別々のプロセスがパラメーターサーバーとして機能し、各ワーカーノードからの勾配を集計し、重み更新を実行します。開発時には、パラメーターサーバーとしてのみ機能する追加ノードを持つ方が、パフォーマンスに優れていることが分かりました。このロールを P3 インスタンスに対して 2:1 の比率で実行するために、M4.16xl インスタンスを選択します。この組み合わせにより、トレーニングスループットのほぼ直線的なスケーリングが可能となります。TensorFlow では、Horovod を使用して多くのノードでトレーニングをスケールアップする方が、TensorFlow [6] のネイティブのパラメーターサーバーアプローチを使用するよりも大きく優れていることが分かりました。
トレーニングアプローチ
ニューラルネットワークを迅速にトレーニングするには、多くのノードにわたる大きなバッチサイズを使用しなければならないことがよくあります。実際には、大きなバッチサイズを使用すると、一般化能力がいくらか失われることが観察されています [4]。よって、大きなバッチサイズを使用するには、モデルが低いバッチサイズでも同じ精度を確実に達成できるよう、特別な注意が必要です。次に、これらのモデルをこのスケールでトレーニングするアプローチについて説明します。
モデル
MXNet と TensorFlow の両方で、Resnet50 v1 モデルを使用しました。障害ブロックが 1×1 レイヤーの代わりに、3×3 畳み込みレイヤーで特徴マップサイズをダウンサンプリングするバージョンを使用しました。これにより、より多くの情報が保持され、わずかながら高い精度でトレーニングが可能となります。このバージョンについて詳細を述べている正式な文献はありませんが、いくつかの論文 ([1][2]) で述べられており、また、TensorFlow や PyTorch のようなフレームワークの例では標準で使用されています。
データの前処理と拡張
データ並列処理でトレーニングを行い、各 GPU がデータセットの独自の部分でフルモデルをトレーニングするようにしました。これを可能にするために、各ミニバッチは 64 個の部分に分割し、各 GPU に 1 つずつ含めます。次に、各ワーカーはデータのシャードをロードし、データの拡張を実行します。データ拡張はトレーニングデータセットを増加させ、ネットワークをトレーニングする際に正則化効果を生み出します。この正則化は、大規模なバッチサイズでトレーニングする際に起こりがちな過学習に対処できます [4]。トレーニング中に、アスペクト比を特定の範囲に維持しながら、元の画像を 224×224 のサイズにランダムに切り取りました。[3/4. , 4./3.]. 次に、画像を水平方向にランダムに反転しました。MXNet では、ジッタリング彩度、色相と明度、および主成分分析 (PCA) 分布からサンプリングしたノイズを追加する形で、追加の拡張機能をいくつか実行しました。この結果、MXNet のトレーニングジョブは、同様のトレーニングスケジュールでも、より高い検証精度に達することができたと思います。両方の場合の検証画像は、中央だけが切り取られ、ランダム化した拡張は受けませんでした。トレーニングおよび検証画像の両方を正規化して、データセット全体の画像平均を減算しました。
最適化
これまでの研究 [3] が示唆していることと同様、学習率はミニバッチサイズに基づくチューニングをするための重要な最適化パラメーターであることが分かりました。 256 個の画像のミニバッチサイズを含む Volta V100 GPU 1 つの場合、最適化ツールとしての Nesterov Accelerated Gradient Descent を使用して、0.1 の学習率、0.9 の運動量、および 0.0001 の荷重減衰となりました。1 つの GPU から 64 個の GPU (8 つの P3.16xlarge インスタンス) に拡張した時、GPU あたりの画像数を 256 (1 つの GPU で 256 のミニバッチサイズから 64 個の GPU で 16,384 まで) に一定に保ちながら、使用した GPU の数 (1 つの GPU では 0.1、64 個の GPUでは 6.4) で学習率を直線的に拡大しました。GPU の数が増えても、荷重減衰と運動量パラメータは変わりませんでした。
大きな学習率での最適化に対する不安定性に対抗するため、学習率が 10 エポックにわたって 0.001 から 6.4 へと徐々に直線的に拡大していくウォームアップスキーム [3] を使用しました。10 エポック後、学習率は多項式 (次数 =2) の減衰スキームによって、次の 80 エポックにわたり低下しました。全てのモデルは、使用したノード数にかかわらず、合計で 90 エポックのトレーニングを受けました。これは、各残差ブロックにある最後のバッチノルムレイヤーのガンマパラメーターを 0 に初期化すれば、大きなバッチサイズで収束できることを示しています [3]。これが精度の向上に役立っていることが分かりました。他のシナリオでも使用可能な標準的なアプローチを提供したいので、ハイパーパラメータにさらなる変更を加えることはしませんでした。
混合精度
P3 インスタンスの Nvidia Volta GPU をサポートする高速な float16 での計算を活用するために、両方のフレームワークで混合精度を使用してトレーニングを行いました。これで、トレーニング時間を約 50% 短縮できました。 興味深いことに、TensorFlow では、範囲の外れや発散を防ぐために勾配を計算しながら、損失を 1024 倍で拡大する必要がありました。しかし、MXNet はロススケーリングを必要としませんでした。ロススケーリングとそれがどのように機能するかの詳細については、こちらの論文 [5] をご参照ください。
再現する手順
P3 インスタンスは広範で大規模な利用が可能なため、世界中の開発者やデータサイエンティストがこの作業を活用し、トレーニング時間を短縮できることを期待しています。これらのモデルのトレーニングに使用するスクリプトと、ここで説明したクラスタをセットアップするためのスクリプトを、次の GitHub リポジトリ https://github.com/aws-samples/deep-learning-models で共有しています。ぜひこれらをチェックして、深層学習作業にクラウドの力を活用してください。
前述のパフォーマンス数値には、次の主要コンポーネントを含むスタックを使用しています。
Ubuntu 16.04、NVIDIA Driver 396、CUDA 9.2、cuDNN 7.1、NCCL 2.2、OpenMPI 3.1.1、Intel MKL、および MKLDNN、TensorFlow 1.9、および Horovod 0.13、MXNet 1.3b (現在のマスター、v1.3 としてもうすぐリリース予定)。
手順
- 前述の Hpc-cluster のところで述べたリポジトリの AWS CloudFormation を使用して、P3 クラスタをセットアップするスクリプトを、その使用方法についての説明とともに、提供しています。このスクリプトで CloudFormation テンプレートを使用すると、クラスタを簡単に起動および実行できます。
- ImageNet データセットは、http://www.image-net.org/ にあります。元のデータセットから次のファイル (ILSVRC2012_img_train.tar.gz および ILSVRC2012_img_val.tar.gz) を登録し、ダウンロードする必要があります。これには、1,000 クラスの中の 128 万個の元のイメージが含まれています。utils ディレクトリで提供するスクリプトを使用して、ImageNet 画像を処理し、MXNet 用の RecordIO ファイル、または Tensorflow 用の TF Records を作成します。
- これで、リポジトリのモデルとスクリプトを使用して、AWS でトレーニングジョブを開始できます。
この後の作業
この作業の結果は、AWS が高性能かつ柔軟でスケーラブルなアーキテクチャを使用して、深層学習ネットワークを迅速にトレーニングするのに利用できることを示しています。 このブログ記事で説明している実装は、さらに最適化することが可能です。 8 つの NVIDIA V100 GPU を搭載する単一の Amazon EC2 P3 インスタンスは、SuperConvergence やその他の高度な最適化技術とともに、ImageNet データを使用すれば、約 3 時間で ResNet50 をトレーニングすることできます (NVIDIA、Fast.AI)。 同様の技術を適用すれば、分散構成にわたって、トレーニング時間をさらに短縮できると考えています。
さらなるパフォーマンスを引き出すことが可能な領域は、スケーリング効率の向上です。 最後になりますが、一般的なフレームワークを全て均等にサポートしたいと思っていますので、今後は、PyTorch や Chainer などの他のフレームワークで同様の結果を複製することに重点的に取り組む予定です。
参考文献
[1] Xie、Saining、Ross Girshick、Piotr Dollár、Zhuowen Tu、および Kaiming He。「ディープニューラルネットワークのための集合的残差変換」Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference, pp. 5987-5995. IEEE, 2017.
[2] Hu、Jie、Li Shen、および Gang Sun。「詰め込み & 励起ネットワーク」arXiv preprint arXiv:1709.01507 7 (2017)
[3] Goyal、Priya、Piotr Dollár、Ross Girshick、Pieter Noordhuis、Lukasz Wesolowski、Aapo Kyrola、Andrew Tulloch、Yangqing Jia、および Kaiming He。「正確で大規模なミニバッチ SGD: 1 時間で ImageNet をトレーニングする」 arXiv preprint arXiv:1706.02677 (2017)
[4] Keskar、Nishish Shirish、Dheevatsa Mudigere、Jorge Nocedal、Mikhail Smelyanskiy、および Ping Tak Peter Tang。「深層学習のための大規模バッチトレーニング: ジェネレーションギャップと sharp minima」 arXiv preprint arXiv:1609.04836 (2016)
[5] Micikevicius、Paulius、Sharan Narang、Jonah Alben、Gregory Diamos、Erich Elsen、David Garcia、Boris Ginsburg 等。「混合精度トレーニング」 arXiv preprint arXiv:1710.03740 (2017)
[6] Sergeev、Alexander、および Mike Del Balso。「Horovod: TensorFlow での迅速で簡単な深層学習」 arXiv preprint arXiv:1802.05799 (2018)
ブログ投稿者について
 Amr Ragab は、AWS の ML および HPC (ハイパフォーマンスコンピューティング) プロフェッショナルサービスコンサルタントで、大規模な計算ワークロードを実行するお客様をサポートしています。旅行が趣味で、技術を日常生活に取り入れる方法を考えるのが好きです。
Amr Ragab は、AWS の ML および HPC (ハイパフォーマンスコンピューティング) プロフェッショナルサービスコンサルタントで、大規模な計算ワークロードを実行するお客様をサポートしています。旅行が趣味で、技術を日常生活に取り入れる方法を考えるのが好きです。
 Rahul Huilgol は、AWS Artificial Intelligence グループのソフトウェア開発エンジニアで、深層学習フレームワークに取り組んでいます。仕事以外では、特に仕事で役に立つサイエンスフィクションの研究に勤しんでいます。
Rahul Huilgol は、AWS Artificial Intelligence グループのソフトウェア開発エンジニアで、深層学習フレームワークに取り組んでいます。仕事以外では、特に仕事で役に立つサイエンスフィクションの研究に勤しんでいます。
 Yong Wu は、AWS Artificial Intelligence グループのソフトウェア開発エンジニアで、深層学習フレームワークに取り組んでいます。自由な時間には、ハイキングや卓球を楽しみます。
Yong Wu は、AWS Artificial Intelligence グループのソフトウェア開発エンジニアで、深層学習フレームワークに取り組んでいます。自由な時間には、ハイキングや卓球を楽しみます。
 Chetan Kapoor は、Amazon EC2 チームのシニアプロダクトマネージャであり、GPU Compute インスタンスを管理しています。自由な時間には、アウトドアやランニングを楽しんだり、2 人の息子たちと過ごします。
Chetan Kapoor は、Amazon EC2 チームのシニアプロダクトマネージャであり、GPU Compute インスタンスを管理しています。自由な時間には、アウトドアやランニングを楽しんだり、2 人の息子たちと過ごします。
 Tyler Mullenbach は、AWS プロフェッショナルサービスのデータサイエンティストで、機械学習を使ってお客様のサポートを行っています。コーディング以外にも、木工細工や車のチューニングが趣味です。
Tyler Mullenbach は、AWS プロフェッショナルサービスのデータサイエンティストで、機械学習を使ってお客様のサポートを行っています。コーディング以外にも、木工細工や車のチューニングが趣味です。
 Jarvis Lee は、AWS プロフェッショナルサービスのデータサイエンティストで、ML Solutions Labs に所属しています。仕事以外では、ロードサイクリングやトレイルライディングが趣味です。
Jarvis Lee は、AWS プロフェッショナルサービスのデータサイエンティストで、ML Solutions Labs に所属しています。仕事以外では、ロードサイクリングやトレイルライディングが趣味です。