Amazon Web Services ブログ
NNPACK ライブラリを使用した Apache MXNet の高速化
Apache MXNet は、ディープラーニングネットワークをビルドし、トレーニングし、再利用するために開発者が利用できるオープンソースライブラリです。このブログ投稿では、NNPACK ライブラリを使用して推論を高速化する方法を説明します。確かに、GPU 推論が利用できない場合、NNPACK を Apache MXNet に追加することは、インスタンスからより大きなパフォーマンスを引き出すための簡単なオプションかもしれません。常にそうですが、「かかる労力は異なる場合があり」、常に自分自身でテストを実行する必要があります。
開始する前に、トレーニングと推論の基礎の一部を確認していきましょう。
トレーニング
トレーニングとは、ニューラルネットワークがデータセット内の各サンプルに対して正しいラベルを正しく予測する方法を学習するステップです。1 回に 1 個のバッチ (通常 32〜256 サンプル) ずつ、データセットがネットワークに送出され、バックプロパゲーションアルゴリズムを利用して、重みづけを調整することにより、エラー数の合計が最小限に抑えられます。
完全なデータセットを調べることをエポックと呼びます。大規模ネットワークは、可能な限り高い精度を達成するために、何百ものエポックに対してトレーニングする場合があります。これには数日から数週間かかることもあります。強力な並列処理能力を備えた GPU を使用することで、最も強力な CPU に比べてさえも、トレーニング時間を大幅に短縮することができます。
推論
推論とは、実際にトレーニングされたネットワークを使用して新しいデータサンプルを予測するステップです。Amazon Rekognition のように単一の画像内のオブジェクトを識別しようとする場合など、一度に 1 つのサンプルを予測することや複数のユーザーからの要求を処理するときに、複数のサンプルを同時に予測することなどが可能です。
もちろん、GPU は推論でも同様に効率的です。しかし、多くのシステムは、コスト、消費電力、またはフォームファクタの制約のために GPU に対応できません。したがって、CPU ベースの推論では、高速で実行できることが依然として重要なトピックになっています。ここでは NNPACK ライブラリが Apache MXNet で CPU 推論を高速化するのに役立つため、NNPACK ライブラリが、が採用されます。
NNPACK ライブラリ
NNPACK は、GitHub で利用できるオープンソースライブラリです。どのように役立つのでしょうか?コンボリューションニュートラルネットワークについてお読みいただいていることでしょう。これらのネットワークは、コンボリューションとプーリングを適用して入力画像内の機能を検出する複数のレイヤーからビルドされています。
この投稿では実際の理論には触れませんが、NNPACK が高度に最適化される方法でこれらのオペレーション (および行列の乗算のような他のオペレーション) を実施しているとだけ申しておきましょう。基礎理論にご興味があるようでしたら、この Reddit の投稿で著者が述べた研究論文を参照してください。
NNPACK は、Linux および MacOS X プラットフォームで使用できます。AVX2 の命令セットを搭載した Intel x86-64 プロセッサ、および NEON 命令セットと ARM v8 を搭載した ARMv7 プロセッサに対して最適化されています。
この投稿では、Deep Learning AMI を実行する c5.9xlarge インスタンスを使用します。ここでは次のようにします。
- ソースから NNPACK ライブラリをビルドします。
- ソースから NNPACK を使って Apache MXNet をビルドします
- さまざまなネットワークを使用して、いくつかの画像分類ベンチマークを実行します
では始めましょう。
NNPACK をビルドします
NNPACK は Ninja ビルドツールを使用します。残念ながら、Ubuntu リポジトリは最新バージョンをホストしていないので、ソースからもビルドする必要があります。
では、指示に従って、NNPACK ビルドの準備をしましょう。
実際にビルドする前に、設定ファイルを微調整する必要があります。この理由は、NNPACK は静的ライブラリとしてのみビルドされ、MXNET は動的ライブラリとしてビルドされるからです。これは、それらが適切にリンクされていないことを意味します。MXNet のドキュメントでは古いバージョンの NNPACK の使用を提案していますが、別の方法があります。
C と C++ ファイルを位置に依存しないコードとしてビルドするには、build.ninja ファイルと「-fPIC」フラグを編集する必要があります。これは実際に MXNet 共有ライブラリにリンクさせる必要があります。
それでは、NNPACK をビルドし、基本的なテストを実行してください。
NNPACK が終了しました。 ~/NNPACK/lib にライブラリが表示されているはずです。
NNPACK を使用した Apache MXNet のビルド
まず、最新の MXNet ソース (執筆時点で 0.11.0-rc3) と同様に、依存関係をインストールしてみましょう。詳しいビルドの手順は、MXNet の Web サイトで入手できます。
これで、MXNet ビルドを設定する必要があります。make/config.mk ファイルを編集し、ビルドに NNPACK を含めるために後続の変数を設定すると同時に、以前にインストールした依存関係を設定する必要があります。ファイルの末尾にすべてをコピーしてください。
MXNet をビルドする準備ができました。インスタンスには 36 個の vCPU がありますので、それらをうまく使いましょう。
約 4 分後、ビルドが完了します。新しい MXNet ライブラリとその Python バインディングをインストールしましょう。
Python で MXNet をインポートすれば、適切なバージョンがあることをすぐに確認できます。
準備ができました。ベンチマークを実行しましょう。
ベンチマーク
数枚の画像を使用したベンチマークでは、NNPACK で違いが生じるかどうかについて信頼できる見解を与えるものではありません。幸いにして、MXNet ソースには、ベンチマークスクリプトが含まれており、これは、次の各モデルを使用して、ランダムに生成された画像をさまざまなバッチサイズで送出するものです。AlexNet、VGG16、Inception-BN、Inception v3、ResNet-50、および ResNet-152。もちろん、ここでの重要点は推論時間を測定するためだけに予測を実施することではありません。
開始する前に、スクリプト内でコードの行を修正する必要があります。インスタンスには GPU がインストールされておらず (ここでの重要点です)、スクリプトはその事実を正しく検出できません。~/incubator-mxnet/example/image-classification/benchmark_score.py において修正する必要のあるものです。その間、さらにバッチサイズを追加しましょう。
ベンチマークを実行しましょう。NNPACK には最大の推奨値である 8 つのスレッドを使用しましょう。
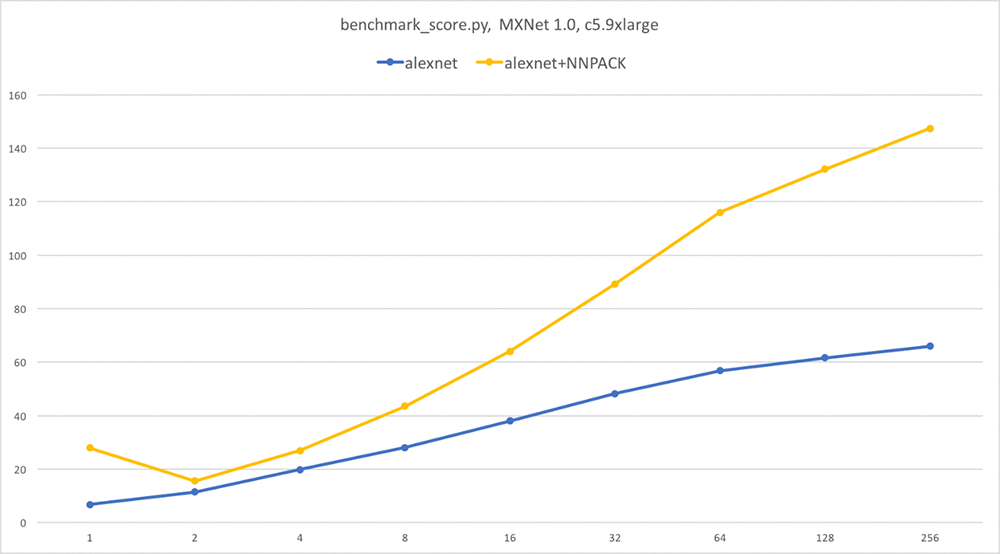
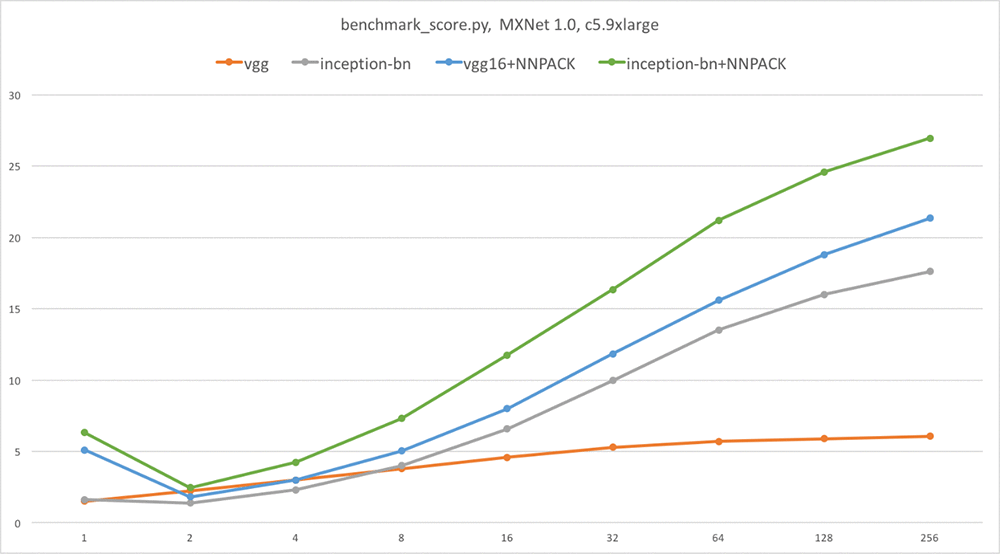
参考までに、vanilla MXNet 1.0 を実行している同じインスタンスでも同じスクリプトを実行しました。 続くグラフは、1 秒あたりの画像数 対 バッチサイズをプロットしたものです。推測できるとおり、1 秒あたりの画像数が多いほうが良いです。
ご覧のように、NNPACK は、AlexNet、VGG、Inception-BN、特に単一画像の推論 (最大 4 倍速) のための非常に重要なスピードアップを提供しています。
注意: この記事の範囲を超える理由から、Inception v3 と ResNet の高速化はありません。そのため、これらのネットワークのグラフは提供しませんでした。
まとめ
この記事を楽しんでいただければ幸いです。ご意見をお待ちしています。もっと深く学び、Apache MXNet のコンテンツを入手するには、Medium と Twitter で私をフォローしてください。
今回のブログの投稿者について
 Julien は EMEA の人工知能およびMachine Learning のエバンジェリストです。彼は、開発者や企業のアイデアを実現させるための支援を中心として活動しています。彼は余暇時間に、JRR Tolkien の作品を何度も読んでいます。
Julien は EMEA の人工知能およびMachine Learning のエバンジェリストです。彼は、開発者や企業のアイデアを実現させるための支援を中心として活動しています。彼は余暇時間に、JRR Tolkien の作品を何度も読んでいます。