Amazon Web Services ブログ
Amazon EC2 スポットインスタンスを使って GPU で深層学習モデルをトレーニング
ディープニューラルネットワークのアーキテクチャ向けに設計されたデータセットの収集と、トレーニングルーティンのコード化はすでに済んでいます。いつでも、最強の GPU インスタンスにある複数のエポックに、大規模なデータセットでのトレーニングを実行することが可能です。NVIDIA Tesla V100 GPU を搭載した Amazon EC2 P3 インスタンスが、計算集約型の深層学習トレーニングジョブに最適であることはわかりました。ただし、予算は限られており、トレーニングの費用を減らしたいと考えます。
スポットインスタンスの料金は、数時間から数日を要するトレーニングジョブを実行している深層学習の研究者や開発者のために、高性能 GPU を手頃で利用しやすいものにしています。スポットインスタンスを利用すると、オンデマンドレートよりも大幅に値引きされた価格で、予備の Amazon EC2 コンピューティング性能を利用できます。インスタンスおよびリージョンごとの最新の価格一覧については、スポットインスタンスアドバイザーをご覧ください。スポットインスタンスとオンデマンドインスタンスの主要な相違点の詳細については、Amazon EC2 ユーザーガイドをお読みいただくことをお勧めします。
スポットインスタンスは深層学習のワークフローに最適ですが、オンデマンドインスタンスと比べ、使用上の課題がいくつか存在します。まず、スポットインスタンスはプリエンプションが可能で、2 分前に通知すれば終了できます。これは、トレーニングジョブを実行し完了する際にインスタンスを当てにできない、ということを意味します。したがって、時間的制約のあるワークロードにはお勧めしません。第二に、トレーニングの進行状況が正常に保存されていなかった場合、インスタンスを終了したときにデータが紛失する可能性があります。第三に、スポットインスタンスを作成した後はアプリケーションを中断させないことを決定した場合、スポットインスタンスを停止し、オンデマンドインスタンスまたはリザーブドインスタンスとして再作成する以外に選択肢がなくなります。
これらの課題に対処するために、深層学習のトレーニングワークフロー向けにスポットインスタンスをセットアップし、同時に、スポットの中断が発生した場合にはトレーニングの進行状況の紛失を最小限に抑えることが可能な、ステップバイステップのガイドを用意しました。次の特徴を維持しながらセットアップを実装することが、ここでの目標です。
- コンピューティング、ストレージ、コードのアーティファクトを分離し、コンピューティングインスタンスをステートレスに維持する。これにより、インスタンスが終了したときに、復旧とトレーニング状態の復元を簡単に行えるようになります。
- データセット、トレーニングの進行状況 (チェックポイント)、ロゴのために、専用のボリュームを使用する。このボリュームは永続的で、インスタンスの終了の影響を受けるようなことがあってはなりません。
- バージョン管理システム (例: Git) を使用する。このリポジトリは、トレーニングを開始/再開するためのクローンを作成する必要があります。これにより、トレーサビリティが有効になり、インスタンスが終了したときに変更されたコードが紛失することを防げます。
- トレーニングスクリプトのコードの変更を最小限に抑える。これにより、トレーニングスクリプトを個別に開発することが可能になり、バックアップとスナップショットのオペレーションをトレーニングコードの外部で実行できます。
- さまざまな自動化終了後の交換用インスタンスの作成、起動時のデータセットとチェックポイントのEBS ボリュームの添付、 アベイラビリティーゾーンを横断したボリュームの移動、インスタンスの状態の復元実行、トレーニングの再開、トレーニング完了後のインスタンスの終了、これらを自動化します。
TensorFlow と AWS 深層学習 AMI を使用したスポットインスタンスの深層学習
この例では、スポットインスタンスと AWS 深層学習 AMI を使って、CIFAR10 データセットで ResNet50 モデルをトレーニングします。 ここでは、AWS 深層学習 AMI バージョン 21 で入手可能な CUDA 9 を使って構成された、TensorFlow 1.12 を使用します。AWS 深層学習 AMI は頻繁に更新されるので、先に AWS Marketplace をチェックし、自分のトレーニングコードと互換性のある最新バージョンが使用されていることを確認してください。TensorFlow 1.13 と CUDA 10 を使用する場合は、代わりにこの AWS 深層学習 AMI を使用します。
続いて、深層学習のトレーニングジョブ向けにスポットフリートリクエストとをセットアップする方法を紹介します。これは、特定のデータセットとモデルの開始点として使用します。
読者が以下の前提条件が満たしているものと仮定して、話を進めます。
- AWS アカウントを持ち、自分のホストに AWS CLI ツールをインストールしている
- Python と少なくとも 1 つの深層学習のフレームワークについての知識がある
その他すべての必要事項は、実装の詳細を読み進めながら学習していきます。コード、設定ファイル、AWS CLI は、すべて GitHub から入手できます。
ここでは、次の AWS とオープンソースのサービスおよびコンセプトを使用します。図 1 は、これらが例の中でどのように組み合わさっているのかを示しています。
- AWS CLI: ここでは AWS サービスとのやり取りに CLI を使用します。CLI を使ってできることは、すべて AWS コンソールからでも実行できます。CLI を使うと自動化が可能になります。自動化はこの例の目標の 1 つです。
- Amazon EC2 スポットインスタンスとスポットインスタンスリクエスト: スポットリクエストは、指定された数のスポットインスタンスが実行中であることを確認します。スポットフリートは、目的の容量を満たすようにスポットリクエストを配置し、中断されたインスタンスがあれば自動的に補充します。
- AWS 深層学習 AMI: 深層学習のフレームワークをプリインストールした Amazon マシンイメージです。この例では、GPU によって高速化した TensorFlow フレームワークをトレーニングに使用します。
- Amazon Elastic Block Storage (EBS): データセット、チェックポイント、ログを保存する 永続ボリューム で、実行中のインスタンスに添付することが可能です。
- Amazon EBS スナップショット: スナップショットを使うと、Amazon EBS ボリュームにあるデータを Amazon S3 へバックアップできます。スナップショットには、データを新しい EBS ボリュームに復元する際に必要となるすべての情報が含まれ、ボリュームを新しい アベイラビリティーゾーンへ移行させるときに使用します。
- Amazon EC2 インスタンスメタデータとユーザーデータ: インスタンスの起動時に、ユーザーデータのシェルスクリプトを実行し、ボリュームの添付、トレーニングの起動、クリーンアップといったアクションを実行します。インスタンスメタデータを使うと、ユーザーデータのシェルスクリプトで使用するインスタンス ID など、インスタンスにそれ自身の情報をクエリさせることができます。
- Amazon IAM ロールとポリシー: EC 2 インスタンスに、ユーザーの代わりに AWS サービスを使用するアクセス許可を与えます。すべての自動化に必須です。
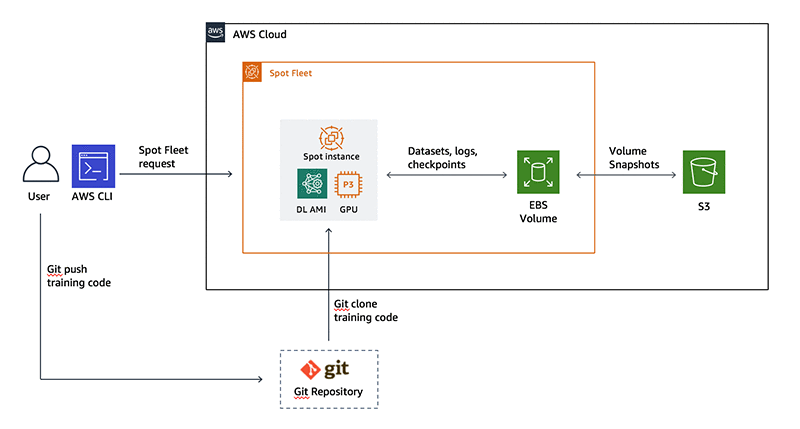
図 1: 深層学習のワークフローでスポットインスタンスを使用する場合のリファレンスアーキテクチャ
ステップ 1: 汎用インスタンスを使ってデータセットとチェックポイントのための専用 EBS ボリュームをセットアップする
最初のステップでは、データセット、チェックポイント、およびその他、ログや他のメタデータを永続化するために必要な情報を保存するための、専用の EBS ボリュームをセットアップします。ここではオンデマンドの m4.xlarge インスタンスを作成して開始するため、このステップは 1 回しか実行しません。データセットが小さく、準備段階で前処理のステップを行う予定がない場合は、メモリと処理能力の低い、費用の安いインスタンスを作成しても構いません。画像のコード変換や、その他マルチスレッドの前処理ルーティンの実行を予定している場合は、GPU でサポートされているかコンピューティングで最適化された CPU インスタンスを選んでください。
AWS CLI を使って自分の端末から次のコマンドを実行します。このページに記載しているすべてのコマンドは、MacOS でテスト済みです。
image-id は、深層学習 AMI Ubuntu インスタンスのことを指します。インスタンスへの SSH 接続を可能にするセキュリティグループ、キー ID、サブネット ID が更新されていることを確認します。詳細は、こちらのドキュメントを参照してください。
重要: サブネットは特定の アベイラビリティーゾーンで作成します。自分が選択した アベイラビリティーゾーンを覚えておいてください。EBS ボリュームを添付できるのは、同じサブネットにあるインスタンスのみです。図 1 の例をご覧ください。この例では、セットアップ用の アベイラビリティーゾーンとして us-west-2b を使用します。EBS スナップショットを使って アベイラビリティーゾーン間で EBS ボリュームの移行を自動化する方法については、ステップ 3 で説明します。
この例では、イタリック体で書かれた文字はすべて、自分のセットアップに固有の値に置き換える必要があります。それ以外はコピーするだけで結構です。
次に、データセットとチェックポイントの EBS ボリュームを作成します。ここでは 100 GiB をリクエストします。値は、自分のデータセットのニーズに合った値を選択します。EBS ボリュームは、インスタンスと同じ アベイラビリティーゾーンにある必要があります。 ボリュームを作成したら、インスタンスへ添付します。run-instances と create-volume の各コマンドの出力から、ID の詳細を指定します。
ドキュメントのステップに従って、SSH を使ってインスタンスに接続し、添付したボリュームをフォーマットしマウントします。この例では、/dltraining という名前のルートで、マウントポイントディレクトリを使用します。
このステップは 1 回のみ行います。後ほどステップ 3 の中で、新しいスポットインスタンスが起動時に自動的にボリュームをセルフマウントし、データセットとチェックポイントをトレーニングに使用できるようにする方法について説明します。
この例では、次のパスを使用します。
- データセット:
/dltraining/datasets - トレーニングの進行状況のチェックポイント:
/dltraining/checkpoints
この例に沿って進むと、ディレクトリを作成した後、これらを空にすることができます。トレーニングスクリプト ec2_spot_keras_training.py が Keras を使用して CIFAR10 データセットをダウンロードし、最初のトレーニングが開始されます。
次のコマンドを使うと、このインスタンスを終了できます。これでボリュームのセットアップは完了し、作成された アベイラビリティーゾーンで永続化されます。
ステップ 2: IAM ロールとポリシーを作成しインスタンスにアクセス許可を付与する
クラウドを使うのが初めての方は、AWS Identity and Access Management (IAM) のコンセプトをあまりご存じないかもしれません。IAM ロールとポリシーは、ユーザーの代わりに他の AWS サービスにアクセスすることを可能にする特定のアクセス許可を、インスタンスに付与するために使用します。
トレーニング中は、スポットインスタンスが、EBS ボリューム内にあるステップ 1 で作成したデータセットとチェックポイントにアクセスできるようにしたいと考えています。しかし、そこに添付できるのは、インスタンスと同じ アベイラビリティーゾーンにあるボリュームだけです。ボリュームとインスタンスが異なる アベイラビリティーゾーンにある場合は、Amazon S3 に保存されているボリュームのスナップショットを使って、新しいボリュームを作成する必要があります。
これらのステップはすべて、インスタンスの作成時に AWS CLI とユーザーデータの bash スクリプトを使って実行します。その方法はステップ 3 で説明します。以下は、インスタンスの作成時に実行する必要のあるすべての AWS CLI コマンドです。
- 次の名前タグを持つボリュームのクエリ: DL-datasets-checkpoints (1 つのみ)
- 次のタグでこのボリュームのスナップショットを作成する: DL-datasets-checkpoints-snapshot
- インスタンスとボリュームが同じ アベイラビリティーゾーンにある場合、ボリュームをインスタンスに添付する
- インスタンスとボリュームが異なる アベイラビリティーゾーンにある場合、インスタンスの アベイラビリティーゾーンにあるスナップショットから新しいボリュームを次の名前: DL-datasets-checkpoints で作成し、インスタンスに添付する。異なる アベイラビリティーゾーンにあるボリュームを削除し、コピーが 1 つのみであることを確認する。
- トレーニングが完了したら、スポットフリートリクエストをキャンセルし、すべてのトレーニングインスタンスを終了する。
インスタンスでこれらのアクションを実行できるようにするには、インスタンスに、自分の代わりにアクションを行うためのアクセス許可を付与する必要があります。 自分がユーザーとして持つものとまったく同じアクセス許可はインスタンスに付与しないことで、潜在的な不正使用の危険を冒さないようにします。
ここでは、IAM ロールと呼ばれる Amazon EC2 インスタンスのロールを作成することから始めます。その後、ポリシーと呼ばれるものを作成し、このロールに特定のアクセス許可を付与します。 次のコマンドを実行し、新しい IAM ロールを作成します。私はロールの名前を DL-Training にしましたが、名前は自由に選んでください。
次に、インスタンスに以下のアクセス許可を付与するポリシーを作成し、添付します。
- ボリュームの記述、作成、添付、削除
- ボリュームからのスナップショットの作成
- スポットインスタンスの記述
- スポットフリートリクエストのキャンセルとインスタンスの終了
自分のアプリケーションで他の AWS サービスを使用することを予定している場合は、それにアクセスするためのアクセス許可を付与することもできます。通常、アクションの内容を詳細にすればするほどインスタンスはより良く理解できます。アクセス許可は、例にある GitHub レポジトリの ec2-permissions-dl-training.json と呼ばれるファイルの中にあります。
以下を実行してポリシーを作成し、IAM ロールへ添付します。
attach-role-policy コマンドで <account_id> を自分の AWS アカウント ID に置き換えることを忘れないようにします。
ステップ 3: EC2 ユーザーデータの bash スクリプトを作成する
次に、トレーニング中に実行したいインスタンスの詳細を記した launch specification ファイルを作成します。この例では、p3.2xlarge を使用します。マルチ GPU のトレーニングジョブを実行している場合は、より多くの GPU を持つインスタンスをリクエストできます。ちなみに、マルチ GPU のジョブとは、同じインスタンスに複数の GPU があることを意味します。現在、単一のインスタンスで取得可能な GPU の最大数は p3.16xlarge または p3dn.24xlarge で 8GPU です。分散ノード、マルチノードトレーニングのユースケースについては、今後別のブログ記事で説明します。
ステップ 2 で説明したように、Amazon EC2 では起動時に実行されるインスタンスにユーザーデータシェルスクリプトを渡すことができます。ユーザーデータシェルスクリプトを確認してみましょう。フルスクリプト (user_data_script.sh) は GitHub で入手できます。
ファイルには 4 つの重要なセクションがあります :
インスタンス ID とクエリボリュームを入手する
このセクションでは、スクリプトはインスタンスメタデータ API にクエリを行ない、このスクリプトが実行されている ID インスタンスにアクセスします。次にこの情報を使用して、データセットとチェックポイントボリュームをタグで検索します : DL-datasets-checkpoints
ボリュームとインスタンスが同じアベイラビリティーゾーンにあるかを確認する
このセクションでは、スクリプトはボリュームとインスタンスが同じアベイラビリティーゾーンにあるかを確認します。異なるアベイラビリティーゾーンにある場合、まずはボリュームのポイントインタイムスナップショットを Amazon S3 に作成します。スナップショットが作成されると、そのボリュームは削除され、そのインスタンスがあるアベイラビリティーゾーン内にスナップショットから新しいボリュームが作成されます。図 2 には 2 つのパターンを示しています。
aws ec2 wait コマンドは、次のコマンドに進む前に、スナップショットとボリュームの作成が完了していることを確認します。
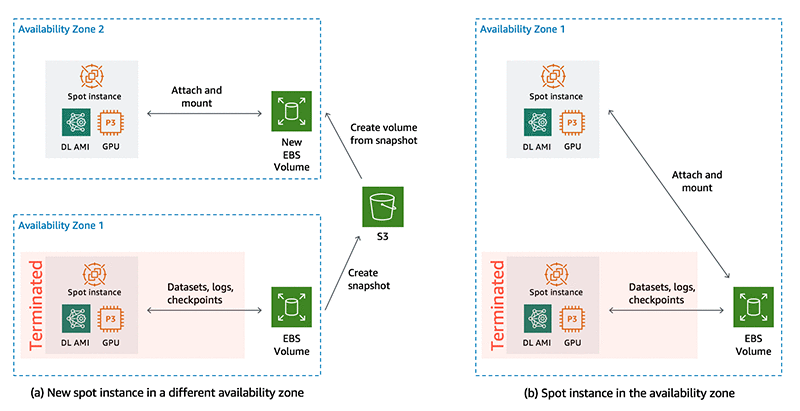
図 2 : スポットインスタンスの終了時に、新しいスポットインスタンスが異なるアベイラビリティーゾーン (a) で起動された場合、EBS ボリュームスナップショットは S3 に保存され、そのインスタンスがあるアベイラビリティーゾーンのスナップショットから新しいボリュームが作成されます。新しいスポットインスタンスがボリューム (b) と同じアベイラビリティーゾーンで起動された場合、同じ EBS ボリュームが新しいインスタンスにアタッチされます。
ボリュームのアタッチとマウント : このセクションでは、スクリプトは最初にインスタンスと同じアベイラビリティーゾーンにあるボリュームをアタッチします。次に、アタッチされたボリュームを /dltraining にあるマウントポイントディレクトリにマウントします。ユーザーデータスクリプトが root として実行された後で、所有権を Ubuntu ユーザーにアップデートします。
トレーニングスクリプトを入手する : このセクションでは、スクリプトはトレーニングコードの git リポジトリをコピーします。
トレーニングの開始/再開: スクリプトは tensorflow_p36 Conda 環境をアクティブにし、Ubuntu ユーザーとしてトレーニングスクリプトを実行します。トレーニングスクリプトは、Amazon EBS ボリュームからデータセットをロード、およびチェックポイントからトレーニングを再開する処理をします。ステップ 4 ではトレーニングスクリプトに必要になる修正について説明します。
クリーンアップ : トレーニングが完了すると、 スクリプトは現在のインスタンスに関連するスポットフリートリクエストをキャンセルしてクリーンアップします。cancel-spot-fleet-requests はフリートが管理していたインスタンスを削除することもできます。
ステップ 4 : スポットフリートリクエスト設定ファイルを作成する
次に、目標とする容量 (この例では 1 インスタンス)、インスタンスの起動仕様、および支払える上限価格が含まれるスポットフリート設定ファイルを作成します。 スポットフリートは、目標とする容量を満たし、中断されたインスタンスを自動的に補充するリクエストをします。
LaunchSpecifications セクションには、異なる仕様が 2 つあります。
- p3.2xlarge インスタンスタイプ (us-west-2 リージョン内のどのアベイラビリティーゾーンにも配置できます)
- p2.xlarge インスタンスタイプ (us-west-2 リージョン内のどのアベイラビリティーゾーンにも配置できます)
スポットフリート設定は、例えば GitHub のリポジトリであれば spot_fleet_config.json というファイルにあります。スポットフリート設定ファイルを使用すると、インスタンスタイプとアベイラビリティーゾーンを柔軟に組み合わせることができます。トレーニングスクリプトで NVIDIA Tesla V100 の混合精度 Tensor コアを利用する場合は、インスタンスタイプを p3.2xlarge のみに制限することをお勧めします。NVIDIA Tesla K80 を備えた p2.xlarge がサポートするのは単精度 (FP32) および倍精度 (FP64) のみで、深層学習トレーニング用としては V100 よりも安価ですが低速です。ニーズに合った組み合わせを選択してください。
インスタンスへの SSH 接続を許可するセキュリティグループを使用してデバッグおよび手動での進行状況確認を行い、キーペア名を使用して認証を行うようにしてください。IAM インスタンスプロファイルの箇所で、ステップ 2 で作成した IAM ロールを更新します。これにより、インスタンスに必要なアクセス許可が付与されます。
スポットフリートリクエストを使用するには、次のコマンドを実行して IAM フリートロールを作成します。
上記の設定のスニペット内、ユーザーデータの部分の base64_encoded_bash_script というテキストは、base64-encoded user data シェルスクリプトに置換します。これの実行には、Mac ベースおよび Linux ベースの OS で利用可能な base64 ユーティリティを使用できます。次のコマンドは Mac で機能します。Linux フレーバーでは、-b を -w に置換して改行を削除します。sed コマンドを実行すると、base64_encoded_bash_script という文字列すべてが base64 でエンコードされた Bash スクリプトに置換されます。
ステップ 5: 深層学習トレーニングスクリプトの更新
最後のステップは、深層学習トレーニングスクリプトの更新です。データセットの読み込み元とチェックポイントの保存先を、アタッチされた Amazon EBS ボリュームにします。この例では、CIFAR10 データセットで ResNet50 モデル をトレーニングします。 一般的な深層学習トレーニングスクリプトでは、次の手順を踏む場合があります。下記の疑似コードには、このセットアップで使用するトレーニングスクリプトに加えなければならない変更が含まれています。
要約すると以下の通りです。
- マウントされた Amazon EBS ボリュームからデータを読み込みます。この例では
/dltrainingです。 - チェックポイントの存在を確認してから、チェックポイントを読み込み、エポック数を更新してトレーニングを再開します。または、モデルアーキテクチャを定義して最初からトレーニングを開始します。
- トレーニングループにおいて、終了通知が発行されているかどうかを確認します。発行されていたら、トレーニングを一時停止してチェックポインティング中の終了を回避します。こうすることでチェックポイントの破損や未完成を防止できます。
- 終了通知が発行されていなかったら、モデルチェックポイントを
/dltraining/checkpoints/に保存します。
この例のトレーニングスクリプトは ec2_spot_keras_training.py と呼ばれるもので、サンプルリポジトリで入手可能です。下記のコードスニペットはトレーニングスクリプトからの抜粋です。load_checkpoint_model() という関数により最新のチェックポイントが読み込まれ、トレーニングが再開されます。
Keras と TensorFlow バックエンドを併用しているため、明示的にトレーニングループを記述する必要はありませんでした。Keras では、各エポック後のチェックポイントの保存と進行状況のログ記録に便利なコールバック関数が提供されます。
注意: TensorFlow の低レベル API、PyTorch、またはその他のフレームワークを使用して独自のトレーニングループを実装している場合、進行状況のチェックポインティングに関しては自己責任になります。これはきちんと理解できていないと極めて厄介な作業になるでしょう。適切にトレーニングを再開するには、(1) モデルを再定義するためのモデルアーキテクチャ、(2) 完了したエポック数および現在のエポック終了時のモデルの重み、(3) 損失関数、オプティマイザ、学習レートスケジュールといったトレーニングハイパーパラメータ、(4) エポック終了時のオプティマイザの状態を、必ず保存するようにする必要があります。
以下に示すのは、進行状況のチェックポインティングと終了状態の確認に使用する Keras のコールバック関数です。
ステップ 6: スポットリクエストを開始してトレーニングを開始する
ステップ 4 で作成した spot_fleet_config.json 設定ファイルを使用してスポットフリートリクエストを送信する準備ができました。
連携の仕組み
ここまで多数のコード、設定ファイル、AWS CLI コマンドを紹介してきました。図 3 は、それらすべてのコードおよび設定アーティファクトの連携の仕組みを示しています。どのようにこれらすべてが接続されているのかを理解してもらえるよう、プロセスを解説していきます。
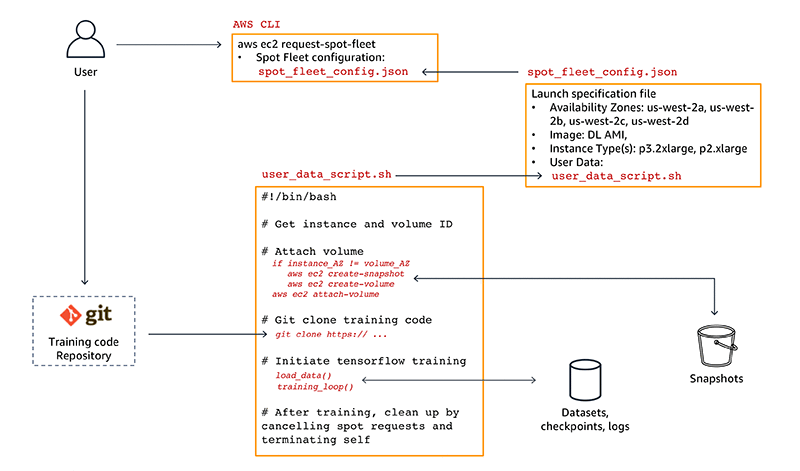
図 3: データ、コード、設定アーティファクトの依存関係図
まずはユーザーがいます。
深層学習の研究者または開発者として、まずはローカルで、または安価な CPU のみの Amazon EC2 オンデマンドインスタンス上で、AWS 深層学習 AMI を使用してモデルのプロトタイプの作成およびモデルの開発を行います。GPU でトレーニングジョブを実行する準備ができたら、トレーニングスクリプトを Git リポジトリにプッシュします。
次に、ステップ 6 で紹介した aws ec2 request-spot-fleet コマンドを使用してスポットリクエストを送信します。これですべてが動き出します。
スポットリクエストはスポットフリート設定ファイルである spot_fleet_config.json を使用して、希望するスポットインスタンスタイプを起動します。この例では、us-west-2 リージョンの任意のアベイラビリティーゾーンにある p3.2xlarge インスタンス上でトレーニングジョブを実行します。トレーニングスクリプトは、AWS 深層学習 AMI を使用して作成されたインスタンス上で実行します。これには、GPU 最適化 TensorFlow フレームワークが含まれています。
また、スポットフリート設定ファイルには、user_data_script.sh Bash スクリプトファイルが含まれています。ユーザーデータ Bash スクリプトは起動時にスポットインスタンス上で実行されます。このスクリプトは、ステップ 3 で見てきたように、データセットおよびチェックポイント用ボリュームのモニタリング、トレーニングスクリプトのクローン作成、トレーニングの開始を担います。
スポットインスタンス料金の上昇または容量不足に起因するスポットインスタンスの中断に際しては、インスタンスは終了され、データセットおよびチェックポイント用 Amazon EBS ボリュームはデタッチされます。その後スポットフリートは別のリクエストを実行し、中断されたインスタンスを自動的に補充します。
リクエストが再び受理されると、新しいスポットインスタンスが起動され、起動時に user_data_script.sh を実行します。スクリプトはデータセットおよびチェックポイント用ボリュームのクエリを実行します。ボリュームとインスタンスが異なるアベイラビリティーゾーンに存在する場合、スクリプトはまずボリュームのスナップショットを作成してから、スナップショットに基づく新しいボリュームを現在のインスタンスのアベイラビリティーゾーンに作成します。以前のアベイラビリティーゾーンに存在するボリュームは削除され、単一のソースのみが残ります。
その後スクリプトによりインスタンスにボリュームがアタッチされ、最後のチェックポイントからトレーニングが再開されます。トレーニングが完了すると、スポットフリートリクエストはキャンセルされ、現在実行中のインスタンスは終了します。
スポットインスタンスの上限料金を高く設定する場合や、インスタンスタイプまたはアベイラビリティーゾーンを変更する場合は、aws ec2 cancel-spot-fleet-requests を発行して実行中のスポットフリートリクエストをキャンセルし、更新したスポットフリート設定ファイルである spot_fleet_config.json を使用して新しいリクエストを開始します。
まとめ
以上が、スポットインスタンスを使用してオンデマンドインスタンスよりはるかに低いコストで GPU インスタンスにおける深層学習トレーニング実験を行う方法の概要です。
このブログ記事で紹介したセットアップは、拡張すればより高度な深層学習ワークフローをカバーできる可能性があります。いくつかのアイディアを以下に示します。
- マルチ GPU トレーニング。トレーニングスクリプトを更新してマルチ GPU トレーニングを可能にします。
- エポックより高い詳細度でのチェックポインティングおよび再開。この例では、チェックポイントは各エポックの終了時にのみ保存されます。エポックの終了までに時間がかかる大規模なデータセットおよび複雑なモデルの使用時に高頻度のチェックポインティングを行えば、中断中の進行状況の損失を最小化できます。
- 複数の並列実験。スポットフリートの容量ターゲットを増加させると、異なるハイパーパラメータで複数の独立したトレーニングジョブを実行できます。
この記事を読んでいただきありがとうございました。ご質問、コメント、フィードバックは、以下のコメント欄にお寄せください。スポットトレーニングの成功を祈ります。
著者について
 Shashank Prasanna は、アマゾン ウェブ サービス (AWS) の AI および機械学習テクニカルエバンジェリストです。機械学習に関する難題を解決するエンジニア、開発者、データサイエンティストのサポートに注力しています。AWS に入社する前は、NVIDIA、MathWorks (MATLAB および Simulink のメーカー)、Oracle で、プロダクトマーケティング、プロダクトマネジメント、ソフトウェア開発に携わっていました。
Shashank Prasanna は、アマゾン ウェブ サービス (AWS) の AI および機械学習テクニカルエバンジェリストです。機械学習に関する難題を解決するエンジニア、開発者、データサイエンティストのサポートに注力しています。AWS に入社する前は、NVIDIA、MathWorks (MATLAB および Simulink のメーカー)、Oracle で、プロダクトマーケティング、プロダクトマネジメント、ソフトウェア開発に携わっていました。