本日、Amazon SageMaker は、内蔵の線形学習者アルゴリズムに対して、いくつかの機能追加を実施しました。Amazon SageMaker アルゴリズムは、労力を必要とせずに巨大なデータセットにスケールし、比類のない速度を達成できる、最新のハードウェア最適化の利点を活用できるように設計されています。Amazon SageMaker の線形学習者アルゴリズムは、線形回帰および二項分類アルゴリズムの両方を包含しています。 これらのアルゴリズムは金融、不正/リスク管理、保健、ヘルスケアにおいて広く使われています。学習者アルゴリズムの新しい機能は、トレーニングの速度を向上させ、異なるユースケースに合わせてモデルをカスタマイズしやすくするものです。例としては、不均衡クラスによる分類が含まれます。これは、ある結果が別のものよりずっとまれにしか生じないような分類です。また、回帰に特化した損失関数もあります。特定のモデルエラーに対して、他のものよりも大きなペナルティを科すことが重要な場合に対応します。
このブログでは、次の 3 つの点を扱います。
- 最適なモデルに対しては早期に終了して保存すること。
- 線形学習者モデルをカスタマイズする新しい方法。次のものが含まれます。
- ヒンジ損失 (サポートベクターマシン)
- 分位点損失
- Huber 損失
- イプシロン不感応損失
- クラス重み付けオプション
- それから、二項分類におけるパフォーマンスを向上させるためにクラス重み付けを用いる例を実際に試してみます。
早期終了
線形学習者は、確率的勾配降下法 (SGD) または Adam のような SGD の変種を用いて、モデルをトレーニングします。トレーニングでは複数回にわたってデータを処理することが求められます。これはエポックと呼ばれています。データはバッチ、ときにはミニバッチと呼ばれる塊として、メモリに読み込まれます。エポックは何回実行するべきでしょうか。理想的には、収束するまでトレーニングを行いたいところです。つまり、これ以上繰り返しても利点が増えなくなるところまでです。モデルが収束してからもエポックを実行するのは時間とメモリの無駄ですが、適切なエポック数を推測するのは、実際にトレーニングジョブを実行するまでは困難です。トレーニングのエポック数が少なすぎると、モデルの精度は本来可能な精度よりも落ちてしまいます。しかし、エポック数が多すぎると、リソースが無駄になりますし、過剰適合によってモデルの精度が悪化する可能性もあります。当て推量を避け、モデルトレーニングを最適化するために、線形学習者には 2 つの新しい機能が追加されました。自動的な早期終了と、最適なモデルの保存です。
早期終了は 2 つの基本的様式で動作します。検証セット付きと検証セットなしです。多くの場合、データはトレーニング、検証、および試験データセットに分割されます。トレーニングは損失の最適化のため、検証はハイパーパラメーターのチューニングのため、試験はモデルがまだ得ていない将来のデータに対しどの程度のパフォーマンスを出せるかを、公平に見積もるために行われます。検証データセット付きの線形学習者アルゴリズムを提供した場合、検証損失について向上が見られなくなると、モデルのトレーニングは早期に終了します。検証セットが利用できない場合、トレーニング損失について向上が見られなくなると、モデルのトレーニングは早期に終了します。
検証データセット付きの早期終了
検証データセットを利用することの大きな利点としては、トレーニングデータに対する過剰適合が起きたかどうか、そしていつ起きたかについて判断できることが挙げられます。過剰適合は、トレーニングデータへの適合性が緊密すぎる予測をモデルが与えるようになって、汎化されたパフォーマンス (まだ得ていない将来のデータに対するパフォーマンス) が低下することを指しています。下のグラフの右側は、検証データセット付きのトレーニングの典型的な進行状況を示しています。エポック 5 までは、モデルはトレーニングセットからの学習を続けており、検証セットでの成績が次第に良くなっています。しかしエポック 7~10 では、モデルがトレーニングセットへの過剰適合を起こし始めていて、検証セットでの成績が悪くなっていきます。モデルがトレーニングデータでの向上 (過剰適合) を続けていたとしても、モデルが過剰適合を始めたら、トレーニングを終了しなければなりません。そして、過剰適合が始まる直前の、最善のモデルを復元する必要もあります。これらの 2 つの機能は、線形学習者ではデフォルトでオンになっています。
早期終了のためのデフォルトのパラメーター値を下のコードに示します。早期終了の動作をさらに調整するため、値の変更を試してみてください。早期終了を完全にオフにするには、early_stopping_patience の値を実行するエポック数より大きくしてください。
early_stopping_patience=3,
early_stopping_tolerance=0.001,
パラメーター early_stopping_patience は、改善が見られない場合にも、トレーニングを終了するまで何回のエポックを待つかを定義します。早期に終了することにした場合でも、このパラメーターをある程度の大きさにするのは有用です。学習曲線には凹凸ができることがあるからです。改善がまだ続く場合でも、パフォーマンスが 1 ないし 2 エポックの間、悪化することもあり得ます。デフォルトでは、パフォーマンスが連続して 3 エポックの間悪化した場合、線形学習者は早期終了するようになっています。
パラメーター early_stopping_tolerance は、十分であると見なされる改善の大きさを定義します。損失における改善を、以前の最良の損失で割った比率がこの値よりも小さければ、早期終了機能は改善が 0 に達したものと見なします。
検証データセットなしの早期終了
トレーニングセットだけでトレーニングを行う場合には、過剰適合を検出する手段がありません。それでも、モデルが収束して、改善が見られなくなったら、トレーニングを終了する必要があります。下の図の左側で、エポック 25 付近で生じていることに注目してください。
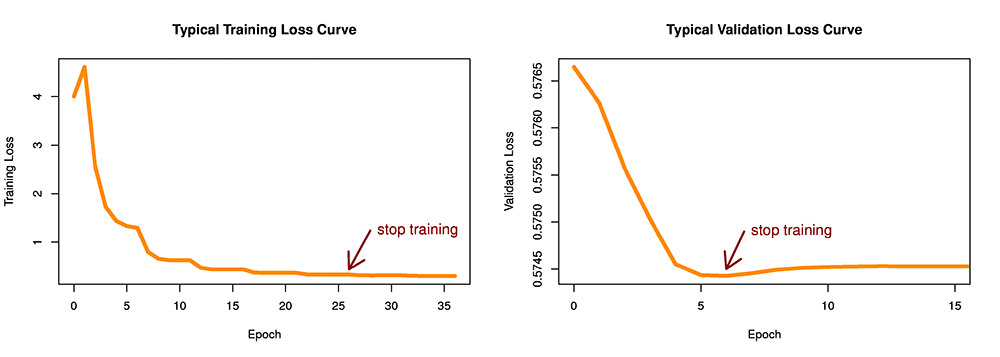
図 1: 検証データセットがある場合都内場合の早期終了
早期終了と校正
二項分類モデルでの、線形学習者自動しきい値チューニングについては、すでにご存じでしょう。デフォルトの線形学習者では、しきい値のチューニングと早期終了はシームレスに協調して機能します。
二項分類モデルが確率 (つまりロジスティック回帰) またはロースコア (SVM) を出力する場合、たとえば次のようにしきい値を適用して、二項予測に変換します。
predicted_label = 1 if raw_prediction > 0.5 else 0
精度やリコール数など、最も重要なメトリックスに基づいてしきい値 (たとえば 0.5) をチューニングしたい場合もあるでしょう。線形学習者は、このチューニングを binary_classifier_model_selection_criteria パラメーターを使用して予測を出力する長さを設定したりできます。閾値のチューニングと早期終了を両方ともオンにした場合 (デフォルト)、リクエストしたメトリックスに基づいて、トレーニングは早期終了します。たとえば、検証データセットを用意し、ロジスティック回帰モデルをリクエストし、精度に基づいてしきい値チューニングを行うことにした場合、自動しきい値を設定したモデルが検証データ上で最適なパフォーマンスに達すると、トレーニングは終了します。検証セットがなく、自動しきい値をオフにしていた場合、トレーニングデータ上で損失関数の最良の値に達すると、トレーニングは終了します。
新しい損失関数
損失関数とは、間違った予測をした場合のコストと定義されています。モデルのトレーニングを行う際には、トレーニングセット内に既知のラベルが存在するとして、モデルの重み付けを、損失が最小になる方向へ向けて動かします。最も一般的でよく知られている損失関数は二乗損失です。標準的な線形回帰モデルをトレーニングする場合には、これを最小化します。別の一般的な損失関数はロジスティック回帰で使用されるもので、ロジスティック損失、交差エントロピー損失、または二項尤度といったいくつかの名前で呼ばれています。理想的に言って、トレーニングで使用する損失関数は、解決したいビジネス上の問題と密接に適合しているべきです。トレーニング時に様々な損失関数から選択できる柔軟性があれば、モデルを異なるユースケースに合わせてカスタマイズすることができます。このセクションでは、どのような場合にどの損失関数を使用するべきかについて説明し、線形学習者に追加されたいくつかの新しい損失関数を紹介します。これらの損失関数に関する技術的な詳細については、このブログと関連付けられたノートブックを参照してください。
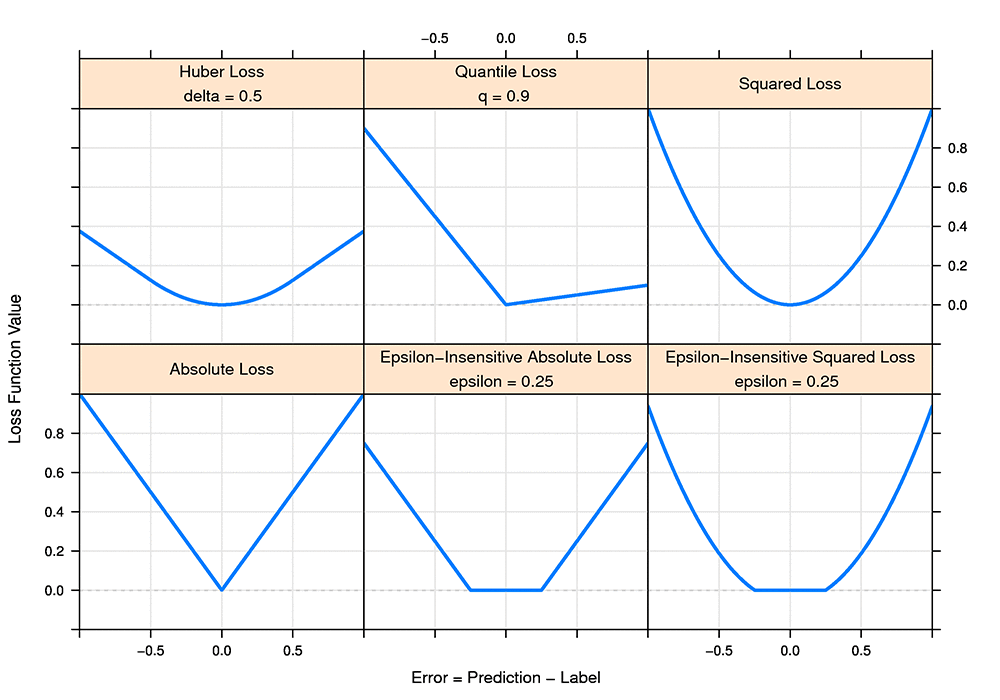
二乗損失
二乗損失は、ほとんどの回帰問題について、最初に考慮すべき選択肢です。ラベル付けされた特徴に対し、平均値の見積もりを生成することができる、優れたプロパティです。上のプロットで見てわかるとおり、二乗損失は、非常に悪い予測に対しては非常に高いコストを払うことになることを意味しています。このことは、トレーニングデータにいくつかの非常に大きく外れた値がある場合には問題の原因となり得ます。二乗損失に基づいてトレーニングされたモデルは、外れ値に対して非常に敏感になります。
絶対損失
絶対損失は二乗損失ほど一般的ではありませんが、非常に役立つものとなる場合があります。これら 2 つの間の違いは、絶対損失に基づいてトレーニングされたモデルは、ラベル付けされた特徴に対して中央値の見積もりを生成するという点です。二乗損失は平均を見積もり、絶対損失は中央値を見積もります。平均と中央値のどちらを見積もるべきかということは、ユースケースに基づいて決まります。たとえば、トレーニングデータ内の外れ値がモデルに影響を及ぼしすぎている場合には、二乗損失から絶対損失に切り替えてみてください。
分位点損失
分位点損失を使えば、ラベルの与えられた特徴に対し、上限と下限を予測することができます。時間の 90% 以上で真となる予測を行うためには、0.9 分位点の分位点損失でトレーニングを行います。例としては、ピーク需要に近い設備を建設する必要のある、電力需要予測があります。仮に平均に基づいて建設したとすると、電力制限を行わなくてはならない事態が生じ、顧客の怒りを買うことになるからです。
Huber 損失
Huber 損失は、二乗損失でトレーニングを行いたいものの、外れ値に対する過敏性を避ける必要がある場合に役立ちます。たとえば、配達時間を予測する際、トレーニング用データの中に、冬嵐のせいで通常よりはるかに長い時間がかかった例がいくつかある場合、またはキャンセルが生じたために非常に短い配達時間の例がある場合などです。
イプシロン不感応損失
イプシロン不感応損失は、エラーがあるしきい値を下回っている限りは、そのエラーの大きさが問題とならない場合に役立ちます。たとえば、機械部品の故障発生までの時間を予測しようとしているものの、その時間が 1 時間単位で記録されているような場合です。このような例では、損失不感応の値を 0.5 時間にすることによって、30 分未満のエラーを無視することができるでしょう。
ロジスティック回帰
ここまでで説明した損失はどれも回帰問題のためのもので、ラベルは浮動小数点数になります。ロジスティック回帰は、二項分類の問題で最もよく使われる損失関数です。
ヒンジ損失 (サポートベクターマシン)
二項分類の問題で最もよく使われる別のオプションはヒンジ損失です。これは線形カーネルを伴うサポートベクターマシン (SVM) またはサポートベクター分類 (SVC) とも呼ばれます。ロジスティック回帰と SVM のどちらが二項分類問題のための適切なモデルであるかを前もって判断するのは困難ですが、両方を試してみる価値はあります。
クラス重み付け
一部の二項分類問題では、トレーニングデータが非常に不均等であることがわかる場合もあります。たとえば、クレジットカード詐欺の検出では、ほとんどの取引の例は詐欺とは関係なく、詐欺よりずっと多く存在するはずです。このような例では、クラス重み付けにより、モデルのパフォーマンスを改善することができるかもしれません。
98% が陰性、2% が陽性であるような例を考えましょう。各クラスの重み合計のバランスを取るために、陽性のクラスの重みを 49 にすることができます。これで、陰性クラスの平均重みは 0.98 × 1 = 0.98、陽性クラスの平均重みは 0.02 × 49 = 0.98 となります。陰性クラスの重みの倍数は常に 1 です。
実地例: クレジットカード詐欺の検出
このセクションでは、クレジットカード詐欺の検出用データセットを調べてみます。データセット (Dal Pozzolo et al. 2015) は Kaggle からダウンロードできます。 25 万件以上のクレジットカード取引に対する特徴とラベルがあり、そのそれぞれに詐欺であるか、詐欺でないかのラベルが付けられています。将来、リスクが高い、または詐欺に関連した取引であるかを予測したいので、モデルをこれらの取引の特徴に基づいてトレーニングします。これは二項分類問題です。
様々な状況で線形学習者をトレーニングする方法と、推論エンドポイントをデプロイする方法を調べます。モデルの質は、そのエンドポイントに試験セットからの観察を与えることによって評価します。エンドポイントによって返されたリアルタイムの予測結果を取得して、試験セット内の実際のラベルと照合することにより評価できます。
次に、リコール数を犠牲にせずにより良い精度を達成するため、線形学習者自動しきい値チューニング機能を適用します。そして、クラス重み付け機能を持つ新しい線形学習者を使用し、精度をさらに高めます。詐欺の被害は非常に高いコストとなるため、偽陽性が増えるとしても、リコール数を高くするのが適切です。このことは、防御の最前線を構築する際に特に真実です。そのような場合には、顧客に影響を及ぼす行動を取る前にさらにレビューができるよう、詐欺の疑いのある取引に目印を付けることが目標となります。
このデータセットには、すでにいくらかの前処理が行われています。データ内の例はシャッフルされて、トレーニングセットと試験セットに分けられています。データの調査によれば、陽性のラベルはデータ内の 0.17% だけに付けられています。そのためこれは困難な分類問題となっています。それでは、Amazon S3 に書き込まれた前処理済みデータを使って、出発することにしましょう。後処理の詳細については、このブログと関連付けられている、詳細なノートブックを参照してください。
import boto3
import io
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import sagemaker
import sagemaker.amazon.common as smac
from sagemaker import get_execution_role
from sagemaker.predictor import csv_serializer, json_deserializer
# Set data locations
s3_train_data = 's3://linear-learner-mead-example/blog-2018-03-29/train/recordio-pb-data'
bucket = 'linear-learner-mead-example'
s3_test_features = 'blog-2018-03-29/test/features.csv'
s3_test_labels = 'blog-2018-03-29/test/labels.csv'
local_test_features = '/tmp/test-features.csv'
local_test_labels = '/tmp/test-labels.csv'
# Download test set from S3 to local /tmp directory on notebook instance
s3 = boto3.resource('s3')
s3.Bucket(bucket).download_file(s3_test_features, local_test_features)
s3.Bucket(bucket).download_file(s3_test_labels, local_test_labels)
# Load test set into memory as Numpy array
test_features = np.loadtxt(local_test_features)
test_labels = np.loadtxt(local_test_labels)
モデルトレーニングのセットアップは使いやすい関数にまとめてあります。この関数は、Amazon S3 内のトレーニングデータの保存場所、トレーニングジョブを定義するモデルのハイパーパラメーター、モデルの結果を配置する Amazon S3 の出力パスを引数として取ります。関数の内部では、アルゴリズムコンテナ、トレーニングが行われる Amazon EC2 インスタンスのタイプ、および入力と出力データ形式をハードコードします。
def predictor_from_hyperparams(s3_train_data, hyperparams, output_path):
"""
Create an Estimator from the given hyperparams, fit to training data, and return a deployed predictor
"""
# specify algorithm containers and instantiate an Estimator with given hyperparams
containers = {
'us-west-2': '174872318107.dkr.ecr.us-west-2.amazonaws.com/linear-learner:latest',
'us-east-1': '382416733822.dkr.ecr.us-east-1.amazonaws.com/linear-learner:latest',
'us-east-2': '404615174143.dkr.ecr.us-east-2.amazonaws.com/linear-learner:latest',
'eu-west-1': '438346466558.dkr.ecr.eu-west-1.amazonaws.com/linear-learner:latest'}
linear = sagemaker.estimator.Estimator(containers[boto3.Session().region_name],
get_execution_role(),
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path=output_path,
sagemaker_session=sagemaker.Session())
linear.set_hyperparameters(**hyperparams)
# train model
linear.fit({'train': s3_train_data})
# deploy a predictor
linear_predictor = linear.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
linear_predictor.content_type = 'text/csv'
linear_predictor.serializer = csv_serializer
linear_predictor.deserializer = json_deserializer
return linear_predictor
そして、ホスティングエンドポイントのセットアップ、予測、およびモデルの評価のための別の関数も追加します。予測を行うには、モデルのホスティングエンドポイントをセットアップする必要があります。それから、エンドポイントに対して試験からの特徴を供給し、予測された試験ラベルを受け取ります。この例で作成するモデルを評価するために、予測された試験ラベルを取り込み、何らかの一般的な二項分類メトリックスを用いて、それらを実際の結果と比較します。
def evaluate(linear_predictor, test_features, test_labels, model_name, verbose=True):
"""
試験セットを与えた予測エンドポイント上のモデルを評価します。 二項分類メトリックスを返します。
"""
# split the test data set into 100 batches and evaluate using prediction endpoint
prediction_batches = [linear_predictor.predict(batch)['predictions'] for batch in np.array_split(test_features, 100)]
# parse raw predictions json to exctract predicted label
test_preds = np.concatenate([np.array([x['predicted_label'] for x in batch]) for batch in prediction_batches])
# calculate true positives, false positives, true negatives, false negatives
tp = np.logical_and(test_labels, test_preds).sum()
fp = np.logical_and(1-test_labels, test_preds).sum()
tn = np.logical_and(1-test_labels, 1-test_preds).sum()
fn = np.logical_and(test_labels, 1-test_preds).sum()
# calculate binary classification metrics
recall = tp / (tp + fn)
precision = tp / (tp + fp)
accuracy = (tp + tn) / (tp + fp + tn + fn)
f1 = 2 * precision * recall / (precision + recall)
if verbose:
print(pd.crosstab(test_labels, test_preds, rownames=['actuals'], colnames=['predictions']))
print("\n{:<11} {:.3f}".format('Recall:', recall))
print("{:<11} {:.3f}".format('Precision:', precision))
print("{:<11} {:.3f}".format('Accuracy:', accuracy))
print("{:<11} {:.3f}".format('F1:', f1))
return {'TP': tp, 'FP': fp, 'FN': fn, 'TN': tn, 'Precision': precision, 'Recall': recall, 'Accuracy': accuracy,
'F1': f1, 'Model': model_name}
そして最後に、使用した後に予測エンドポイントを削除する関数を追加します。
def delete_endpoint(predictor):
try:
boto3.client('sagemaker').delete_endpoint(EndpointName=predictor.endpoint)
print('Deleted {}'.format(predictor.endpoint))
except:
print('Already deleted: {}'.format(predictor.endpoint))
線形学習者のデフォルト設定で二項分類モデルのトレーニングを始めましょう。エポック数を 40 に設定していることに注目してください。これはデフォルトの 10 エポックよりもかなり大きな値です。早期終了を行い場合には、エポック数の設定が大きすぎることを心配する必要はありません。モデルが収束すると、線形学習者はトレーニングを自動的に終了します。
# Training a binary classifier with default settings: logistic regression
defaults_hyperparams = {
'feature_dim': 30,
'predictor_type': 'binary_classifier',
'epochs': 40
}
defaults_output_path = 's3://linear-learner-mead-example/blog-2018-03-29/defaults/output'
defaults_predictor = predictor_from_hyperparams(s3_train_data, defaults_hyperparams, defaults_output_path)
今度は、90% に固定されたリコール値で最良の精度が得られるよう、しきい値がチューニングされたモデルを作成します。
# Training a binary classifier with automated threshold tuning
autothresh_hyperparams = {
'feature_dim': 30,
'predictor_type': 'binary_classifier',
'binary_classifier_model_selection_criteria': 'precision_at_target_recall',
'target_recall': 0.9,
'epochs': 40
}
autothresh_output_path = 's3://linear-learner-mead-example/blog-2018-03-29/autothresh/output'
autothresh_predictor = predictor_from_hyperparams(s3_train_data, autothresh_hyperparams, autothresh_output_path)
クラス重み付けでリコールを改善する
今度は、これらの結果を、線形学習者に追加された新しい機能、二項分類向けのクラス重み付けを使って改善しましょう。この機能は、「クラス重み付け」のセクションで紹介しました。ここでは、均等化されたクラス重み付けで新しいモデルをトレーニングすることにより、クレジットカード詐欺のデータセットへの適用方法を調べましょう。
# Training a binary classifier with class weights and automated threshold tuning
class_weights_hyperparams = {
'feature_dim': 30,
'predictor_type': 'binary_classifier',
'binary_classifier_model_selection_criteria': 'precision_at_target_recall',
'target_recall': 0.9,
'positive_example_weight_mult': 'balanced',
'epochs': 40
}
class_weights_output_path = 's3://linear-learner-mead-example/blog-2018-03-29/class_weights/output'
class_weights_predictor = predictor_from_hyperparams(s3_train_data, class_weights_hyperparams, class_weights_output_path)
最初のトレーニング例では、二項分類のためのデフォルトの損失関数である、ロジスティック損失を使いました。今度はヒンジ損失でモデルをトレーニングします。これはまた、線形カーネルを持つ、サポートベクターマシン (SVM) 分類モデルとも呼ばれます。しきい値のチューニングは、線形学習者のすべての二項分類モデルでサポートされています。
# Training a SVM binary classifier with hinge loss and automated threshold tuning
svm_hyperparams = {
'feature_dim': 30,
'predictor_type': 'binary_classifier',
'loss': 'hinge_loss',
'binary_classifier_model_selection_criteria': 'precision_at_target_recall',
'target_recall': 0.9,
'epochs': 40
}
svm_output_path = 's3://linear-learner-mead-example/blog-2018-03-29/svm/output'
svm_predictor = predictor_from_hyperparams(s3_train_data, svm_hyperparams, svm_output_path)
そして最後に、SVM モデルで均等化のためのクラス重み付けを使用した場合に何が生じるかを見てみます。
# Training a binary classifier with hinge loss, balanced class weights, and automated threshold tuning
svm_balanced_hyperparams = {
'feature_dim': 30,
'predictor_type': 'binary_classifier',
'loss': 'hinge_loss',
'binary_classifier_model_selection_criteria': 'precision_at_target_recall',
'target_recall': 0.9,
'positive_example_weight_mult': 'balanced',
'epochs': 40
}
svm_balanced_output_path = 's3://linear-learner-mead-example/blog-2018-03-29/svm_balanced/output'
svm_balanced_predictor = predictor_from_hyperparams(s3_train_data, svm_balanced_hyperparams, svm_balanced_output_path)
さて、モデルごとにセットアップした予測エンドポイントを、試験セットからの特徴を送信することによって利用し、それらの予測を、標準的な二項分類メトリックスを基準に評価します。
# Evaluate the trained models
predictors = {'Logistic': defaults_predictor, 'Logistic with auto threshold': autothresh_predictor,
'Logistic with class weights': class_weights_predictor, 'Hinge with auto threshold': svm_predictor,
'Hinge with class weights': svm_balanced_predictor}
metrics = {key: evaluate(predictor, test_features, test_labels, key, False) for key, predictor in predictors.items()}
pd.set_option('display.float_format', lambda x: '%.3f' % x)
display(pd.DataFrame(list(metrics.values())).loc[:, ['Model', 'Recall', 'Precision', 'Accuracy', 'F1']])
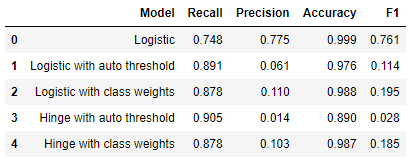
結果が出ました! しきい値チューニングにより、試験セット内の詐欺的取引の 89% を正確に予測することができました (リコール = 0.89)。しかし、これら真の陽性に加えて、多数の偽陽性も発生しました。詐欺的であると予測された取引の 94% は、実際には詐欺と関係ありませんでした (精度 = 0.06)。このモデルは、防御の最前線としては役に立つでしょう。詐欺の可能性のある取引に対し、さらなるレビューを行うように目印を付けることができます。その代わりに、詐欺的な取引を捕らえることがずっと少なくなるというコストを支払ってでも、偽陽性のアラームを非常に小さくするモデルが必要であれば、精度を高くするように最適化するべきです。
binary_classifier_model_selection_criteria='recall_at_target_precision',
target_precision=0.9,
それでは、新しい機能、二項分類用のクラス重み付けを使用した場合の結果はどうだったでしょうか。クラス重み付けでトレーニングを行うと、このモデルのパフォーマンスに大幅な改善が見られました! リコールはほぼ同じで 88% ですが、精度はほぼ 2 倍の 11%になりました。
均等化のためのクラス重み付けは SVM 予測モデルのパフォーマンスを改善しましたが、まだこのデータセット向けの対応するロジスティック回帰には達していません。今までのところのすべてのモデルを比較すると、クラス重み付けとしきい値のチューニングを行ったロジスティック回帰がベストの結果を出しています。
目標のリコールと確認されたリコールの比較について
これらの結果には、いくらかの時間を取って、さらによく調べる価値があります。モデルに対する線形学習者を、目標のリコールである 0.9 を基準に校正するよう求められていたとします。試験セットで 89% のリコールにしかならなかったのはなぜでしょうか。その理由は、トレーニング、検証、および試験の間の相違にあります。線形学習者は、検証データセットが提供されていればそれに基づき、提供されていなければトレーニングセットに基づいて、二項分類用のしきい値の校正を行います。今回、検証データセットを提供してはいなかったので、しきい値はトレーニングデータに基づいて計算されました。トレーニング、検証、および試験データセットは正確にマッチするわけではないので、目標とするリコール値をリクエストしても、計算されるしきい値は近似に過ぎません。この場合、トレーニングデータで 90% のリコール値を達成したしきい値は、テストデータではたまたま 89% のリコール値しか達成できなかったことになります。テストセットでのリコール値とトレーニングセットでのリコール値を比較した結果は、陽性となるポイント数に応じて変動します。この例では、データセット全体では 280,000 件の例があったにもかかわらず、陽性の例は 337 件に過ぎなかったので、違いは大きくなりました。近似の精度は、大きな検証データセットを提供してしきい値を正確にし、それから大きな試験セットを評価してモデルとそのしきい値の正確なベンチマークを取れば、改善することができます。さらに細かくコントロールするためには、校正サンプルの数を大きく設定することができます。そのデフォルト値は、1,000 万のサンプルとして、すでに非常に大きく設定されています。
num_calibration_samples=10000000,
クリーンアップ
最後に、設定した推測エンドポイントを削除して、クリーンアップを行います。
for predictor in [defaults_predictor, autothresh_predictor, class_weights_predictor,
svm_predictor, svm_balanced_predictor]:
delete_endpoint(predictor)

まとめ
今回は、クレジットカード詐欺の予測を改善するために、線形学習者の新しい早期終了機能、新しい損失関数、および新しいクラス重み付け機能を使う方法について説明しました。クラス重み付けは、あらゆるタイプの詐欺検出において、また広告クリック数の予測や、機械的故障の予測など、まれなイベントが含まれる他の場合の分類の問題において、リコール値または精度を最適化するのに役立つ可能性があります。二項分類の問題でクラス重み付けを使ってみてください。あるいは、回帰の問題で新しい損失関数のいずれかを使ってみてください。5% と 95% の分位点学習を行うことにより、予測の両側に信頼区間を設けてください。新しい損失関数とクラス重み付けの詳細については、線形学習者についてのドキュメンテーションを参照してください。
参照
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson and Gianluca Bontempi. Calibrating Probability with Undersampling for Unbalanced Classification. In Symposium on Computational Intelligence and Data Mining (CIDM), IEEE, 2015. Kaggle のフルライセンステキストへのリンクを参照してください。
今回のブログ投稿者について
 Philip Gautier は Amazon AI アルゴリズムグループの応用科学者です。このグループは、Amazon SageMaker での機械学習アルゴリズムに対して責任を負っています。統計的モデルのスケーラブルな最適化とデータ可視化に関連する背景を持っています。
Philip Gautier は Amazon AI アルゴリズムグループの応用科学者です。このグループは、Amazon SageMaker での機械学習アルゴリズムに対して責任を負っています。統計的モデルのスケーラブルな最適化とデータ可視化に関連する背景を持っています。
 Cyrus Vahid は、AWS ディープラーニングでのプリンシパルソリューションアーキテクトです。Cyrus は AI のスペシャリストで、人工ニューラルネットワークと Apache MXNet のようなプラットフォームに熟達しています。エンジニアリングからリーダーシップまで、ソフトウェア開発の様々なステージで働いた経験があります。現在の関心事には、自然言語処理、レコメンダーシステム、教科学習が含まれています。
Cyrus Vahid は、AWS ディープラーニングでのプリンシパルソリューションアーキテクトです。Cyrus は AI のスペシャリストで、人工ニューラルネットワークと Apache MXNet のようなプラットフォームに熟達しています。エンジニアリングからリーダーシップまで、ソフトウェア開発の様々なステージで働いた経験があります。現在の関心事には、自然言語処理、レコメンダーシステム、教科学習が含まれています。
 Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野としては、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
Zohar Karnin は、Amazon AI のプリンシパルサイエンティストです。研究分野としては、大規模およびオンライン機械学習アルゴリズムに関心を持っています。彼は、Amazon SageMaker のために、スケールの限界のない機械学習アルゴリズムを開発しました。
 Saswata Chakravarty は、AWS アルゴリズムチームのソフトウェアエンジニアです。SageMaker に高速でスケーラブルなアルゴリズムを持ち込み、顧客の使いやすいものとするために働いています。余暇には多くの政治風刺番組を視聴しており、John Oliver の熱烈なファンです。
Saswata Chakravarty は、AWS アルゴリズムチームのソフトウェアエンジニアです。SageMaker に高速でスケーラブルなアルゴリズムを持ち込み、顧客の使いやすいものとするために働いています。余暇には多くの政治風刺番組を視聴しており、John Oliver の熱烈なファンです。