ディープラーニング (DL) モデルのトレーニングおよびラーニングプロセスは、費用と時間がかかるものになりがちです。データサイエンティストは、トレーニング精度、トレーニング誤差、検証精度、検証誤差など、モデルのメトリックスを監視し、これらのメトリックスに基づいて、情報に基づく意思決定を行う必要があります。このブログポストでは、一定の時間内のモデルメトリックスの履歴を保存し、モデルパフォーマンスメトリックスをビジュアル化し、CloudWatch ダッシュボードを作成するために、Amazon SageMaker インテグレーションを Amazon CloudWatch にまで拡大する方法について説明します。私はこのデモでは MXNet フレームワークを使用しますが、このアプローチはすべての機械学習/深層学習 (ML/DL) フレームワークに適用することができます。 Amazon SageMaker には CloudWatch との既製のインテグレーションが付属しており、トレーニングジョブコンテナーの CPU、メモリ、GPU 使用率など、トレーニングジョブインスタンスの準リアルタイム使用率メトリックスについてデータを収集することができます。詳細については、『Amazon CloudWatch を使用して Amazon SageMaker を監視する』を参照してください。
ソリューションの概要
この例では、Amazon SageMaker を使用してノートブックインスタンスを作成した後、Apache MXNet 手書き数字認識モデルを構築して、トレーニングします。私は、簡素化するために、Gluon、MNIST データセット、および畳み込みニューラルネットワーク (CNN) アーキテクチャを使用します。また、トレーニングメトリックスを CloudWatch に送信して、それらのメトリックスのダッシュボードを作成するために、Amazon CloudWatch API 演算を使用します。最後に、モデルが過剰適合になった場合、私は Amazon Simple Notification Service (Amazon SNS) および AWS Lambda を使用して、通知を送信します。
アーキテクチャ
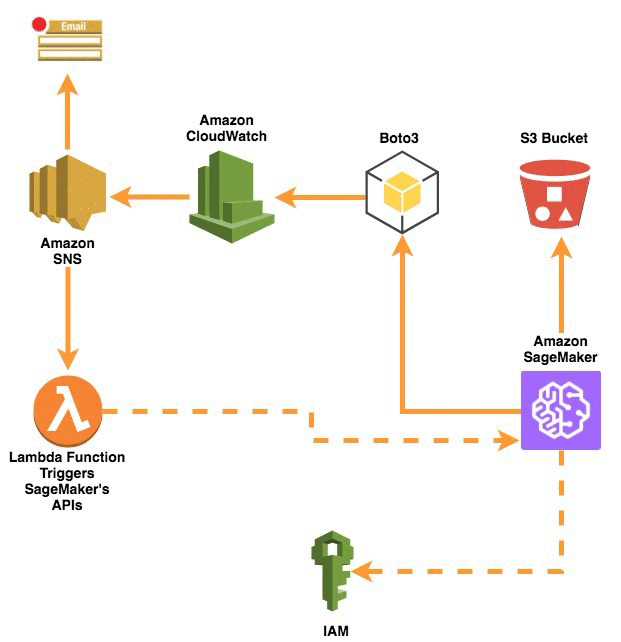
構成
Amazon SageMaker には、CloudWatch メトリックスを作成するための権限が必要です。これは必要な CloudWatch 権限を備えた IAM サービスロールを作成することで実現することができます。IAM マネージドポリシーの AmazonSageMakerFullAccess は、CloudWatch メトリックスを作成するための権限を既に持っています。AWS 管理コンソールを開いて、[IAM]、[Policies (ポリシー)] を選択してから、「AmazonSageMakerFullAccess」を検索します。CloudWatch ダッシュボードを作成する場合、ポリシーに cloudwatch:PutMetricData 権限を追加する必要があることに注意してください。IAM 権限の作成および管理についての詳細は、『ポリシーを使用するアクセス制御』を参照してください。
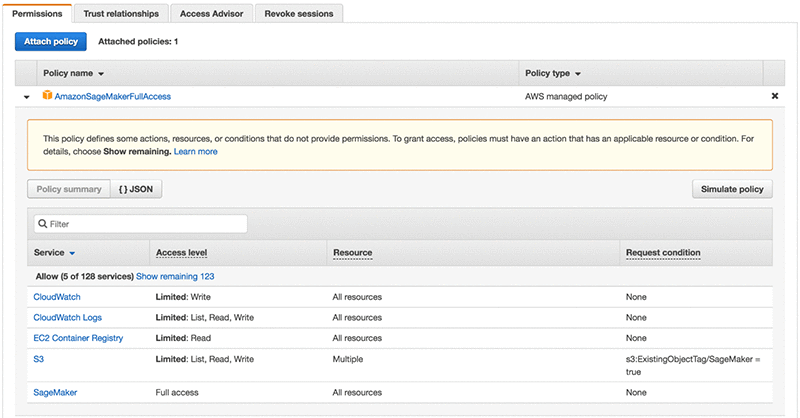
モデルトレーニング
コードを詳しく調べる前に、Amazon SageMaker を使用するトレーニングプロセスの重要ないくつかのコンセプトについて説明します。 Amazon SageMaker Python SDK には、エスティメーターと呼ばれるハイレベル構成体が含まれています。エスティメーターは、Amazon SageMaker 内蔵ディープラーニングフレームワークのラッパーです。エスティメーターを使用するトレーニング MXNet モデルは、2 つのステップで構成されるプロセスです。
- トレーニングロジックを含む、関数 train() が含まれるトレーニングスクリプトを用意します。Amazon SageMaker は、トレーニングスクリプト内のこの関数を呼び出すことによって、トレーニングを開始します。
- MXNet エスティメーターを使ってトレーニングスクリプトを起動するのと同時に、hyperparameters、num_gpus、channel_input_dir、など、トレーニング環境に関する情報をトレーニング関数に送信します。
トレーニングスクリプトのトレーニングおよびデプロイングを実行すると、Amazon SageMaker は Docker コンテナーで Python スクリプトを実行します。トレーニングで GPU と CPU のいずれを使うかは、MXNet コンストラクターに設定された train_instance_type で判断されます。train_instance_type パラメーターに GPU タイプのインスタンスがある場合、SageMaker は GPU バージョンの MXNet を使用します。 train_instance_type パラメーターに CPU タイプのインスタンスがある場合、SageMaker は CPU バージョンの MXNet を使用します。SageMaker エスティメーターについての詳細は、『AWS SageMaker エスティメーター』を参照してください。
私の SageMaker ノートブックから抜粋した以下のコードスニペットは、トレーニングプロセスの開始方法を示しています。
import sagemaker
from sagemaker.mxnet import MXNet
from mxnet import gluon
from sagemaker import get_execution_role
# Creates a SageMaker session to upload the training data
sagemaker_session = sagemaker.Session()
# Returns the IAM role that SageMaker uses to access Amazon S3 and other services.
role = get_execution_role()
# Download the training and testing data
gluon.data.vision.MNIST('./data/train', train=True)
gluon.data.vision.MNIST('./data/test', train=False)
# Upload the downloaded data to an S3 location
input_data = sagemaker_session.upload_data(path='data', key_prefix='data/mnist')
# Creating an MXNet Estimator that wraps the training environment parameters. P2.xlarge is a GPU type instance and will use GPU verion of MXNet
mxnet_estimator = MXNet("training_function.py", role=role, train_instance_count=1, train_instance_type="ml.p2.xlarge",
hyperparameters={'batch_size': 100, 'epochs': 20, 'learning_rate': 0.1,'momentum': 0.9,'log_interval': 100})
# start the training process.
mxnet_estimator.fit(input_data)
以下のコードスニペットは、最初の引数として MXNet エスティメーターに渡した training_function.py スクリプトからの抜粋です。この関数では、モデルの評価メトリックス (トレーニング精度、トレーニング誤差、および検証精度) を収集するために MXNet メトリックスクラスを使用しています。training_function.py スクリプトは、Jupyter ノートブックファイルと同じディレクトリに格納されます。
def train(channel_input_dirs, model_dir, hyperparameters, hosts, num_gpus, **kwargs):
# SageMaker passes num_cpus, num_gpus and other args we can use to tailor training to the current container environment.
# The training will use GPU if the instance type is a GPU instance otherwise, it will use CPU.
ctx = mx.gpu() if num_gpus > 0 else mx.cpu()
num_examples = 70000
best_accuracy = 0.0
# retrieve the hyperparameters we set in notebook (with some defaults)
batch_size = hyperparameters.get('batch_size', 100)
epochs = hyperparameters.get('epochs', 20)
learning_rate = hyperparameters.get('learning_rate', 0.1)
momentum = hyperparameters.get('momentum', 0.9)
log_interval = hyperparameters.get('log_interval', 100)
# load training and validation data
# we use the gluon.data.vision.MNIST class because of its built-in MNIST pre-processing logic,
# but point it at the location where SageMaker placed the data files, so it doesn't download them again.
training_dir = channel_input_dirs['training']
train_data = get_train_data(training_dir + '/train', batch_size)
val_data = get_val_data(training_dir + '/test', batch_size)
# define the network
net = nn.Sequential()
with net.name_scope():
net.add(nn.Dense(128, activation='relu'))
net.add(nn.Dense(64, activation='relu'))
net.add(nn.Dense(10))
# Collect all parameters from net and its children, then initialize them.
net.initialize(mx.init.Xavier(magnitude=2.24), ctx=ctx)
if len(hosts) == 1:
kvstore = 'device' if num_gpus > 0 else 'local'
else:
kvstore = 'dist_device_sync' if num_gpus > 0 else 'dist_sync'
trainer = gluon.Trainer(net.collect_params(), 'sgd',
{'learning_rate': learning_rate, 'momentum': momentum},
kvstore=kvstore)
# Instantiate the Accuracy and Cross Entropy Loss metric classes.
# The later Computes the softmax cross entropy loss.
metric = mx.metric.Accuracy()
loss = gluon.loss.SoftmaxCrossEntropyLoss()
# Instatiate the CloudWatch Class for Evaluation Metrics.
CWMetrics = CWEvalMetrics(region=region, model_name=model_name)
for epoch in range(epochs):
# reset data iterator and metric at begining of epoch.
metric.reset()
cumulative_loss = 0
btic = time.time()
for i, (data, label) in enumerate(train_data):
# Copy data to ctx if necessary
data = data.as_in_context(ctx)
label = label.as_in_context(ctx)
# Start recording computation graph with record() section.
# Recorded graphs can then be differentiated with backward.
with autograd.record():
output = net(data)
L = loss(output, label)
L.backward()
# Get the sum of the Loss for each Iteration
cumulative_loss += nd.sum(L).asscalar()
trainer.step(data.shape[0])
# update metric at last.
metric.update([label], [output])
if i % log_interval == 0 and i > 0:
name, acc = metric.get()
print('Training Loss: %f' % float(cumulative_loss / num_examples))
print('[Epoch %d Batch %d] Training: %s=%f, %f samples/s' %
(epoch, i, name, acc, batch_size / (time.time() - btic)))
# Send the collected training accuracy and loss to CloudWatch
CWMetrics.CW_eval(model_name, is_training=True, Accuracy=acc * 100, Loss=float(cumulative_loss / num_examples * 100), hyperparameters=hyperparameters)
btic = time.time()
name, acc = metric.get()
print('[Epoch %d] Training: %s=%f' % (epoch, name, acc))
name, val_acc = test(ctx, net, val_data)
print('[Epoch %d] Validation: %s=%f' % (epoch, name, val_acc))
#Saving the model if this is the best validation accuracy in the train loop
if val_acc > best_accuracy:
symbol = net(mx.sym.var('data'))
symbol.save('%s/model.json' % model_dir)
net.collect_params().save('{}/model-{:0>4}.params'.format(model_dir, epoch))
best_accuracy = val_ac
# Send the collected training accuracy and loss to CloudWatch
CWMetrics.CW_eval(model_name, is_training=False, Accuracy=val_acc * 100, hyperparameters=hyperparameters)
# Create Cloudwatch Dashboard with the generated metrics.
if epoch == 1:
CWMetrics.create_dashboard('MNIST_Dashboard')
return net
以前のコードでは、CWEvalMetrics と呼ばれたクラスが使われていました。以下のクラスでは、評価メトリックスを CloudWatch に送信するために Boto3 を使用する関数を実装しています。このクラスのコードは以下のとおりです。
class CWEvalMetrics():
# initialize the region and the model name with the class instantiation
def __init__(self, region='us-east-1', model_name='CW-example'):
self.region = region
self.model_name = model_name
# A function to send the training evaluation metrics
# the metric_type parameters will determine whether the data sent is for training or validation.
def CW_eval(self, model_name, is_training, **kwargs):
# collecting the loss and accuracy values
loss = kwargs.get('Loss', 0)
accuracy = kwargs.get('Accuracy')
# determine if the passed values are for training or validation
if is_training:
metric_type = 'Training'
else:
metric_type = 'Validation'
# Collecting the hyperparameters to be used as the metrics dimensions
hyperparameter = kwargs.get('hyperparameters')
optimizer = str(hyperparameter.get('optimizer'))
epochs = str(hyperparameter.get('epochs'))
learning_rate = str(hyperparameter.get('learning_rate'))
response = client.put_metric_data(
Namespace='/aws/sagemaker/' + model_name,
MetricData=[
{
'MetricName': metric_type + ' Accuracy',
'Dimensions': [
{ 'Name': 'Model Name', 'Value': model_name },
{ 'Name': 'Learning Rate', 'Value': learning_rate },
{ 'Name': 'Optimizer', 'Value': optimizer },
{ 'Name': 'Epochs', 'Value': epochs},
],
'Value': accuracy,
'Unit': "Percent",
'StorageResolution': 1
},
{
'MetricName': metric_type + ' Loss',
'Dimensions': [
{ 'Name': 'Model Name', 'Value': model_name },
{ 'Name': 'Learning Rate', 'Value': learning_rate },
{ 'Name': 'Optimizer', 'Value': optimizer },
{ 'Name': 'Epochs', 'Value': epochs},
],
'Value': loss,
'Unit': "Percent",
'StorageResolution': 1
},
]
)
return response
クラスは、モデル名と CloudWatch メトリックスをホストする AWS リージョンを用いて初期化されます。モデル名は CloudWatch 名前空間の一部です。初期化の後、metric_type パラメーターの値に基づいて、トレーニングあるいは検証のメトリックスを、CW _eval() 関数を使って送信します。また、複数のトレーニングジョブに関する各ハイパーパラメーターのパフォーマンスを比較しやすくするために、メイントレーニングハイパーパラメーターを各メトリックスの次元として追加してあります。
トレーニングが始まってしばらくたつと、CloudWatch には統計情報が現れ始めます。また、前のステップで作成したメトリックスを表示するカスタム CloudWatch ダッシュボードを作成することもできます。これは、CloudWatch を使用するか、Boto3 SDK で put_dashboard() API 演算を呼び出すかで、作成することができます。コードのサンプルは、以下のとおりです。
# A function to create a dashboard with the above training metrics.
def create_dashboard(self, db_name, **kwargs):
hyperparameter = kwargs.get('hyperparameters')
job_name = str(hyperparameter.get('sagemaker_job_name'))
optimizer = str(hyperparameter.get('optimizer'))
epochs = str(hyperparameter.get('epochs'))
lr = str(hyperparameter.get('learning_rate'))
# The dashboard body has the property of the dashboard in JSON format
dashboard_body = '{"widgets":[{"type":"metric","x":0,"y":3,"width":18,"height":9,"properties":{"view":"timeSeries","stacked":false,"metrics":[["/aws/sagemaker/' + self.model_name + '","Training Loss","Model Name","' + self.model_name + '","Epochs","' + epochs + '","Optimizer","' + optimizer + '","Learning Rate","' + lr + '"],[".","Training Accuracy",".",".",".",".",".",".",".","."],[".","Validation Accuracy",".",".",".",".",".",".",".","."]],"region":"' + self.region + '","period":30}},{"type":"metric","x":0,"y":0,"width":18,"height":3,"properties":{"view":"singleValue","metrics":[["/aws/sagemaker/' + self.model_name + '","Training Loss","Model Name","' + self.model_name + '","Epochs","' + epochs + '","Optimizer","' + optimizer + '","Learning Rate","' + lr + '"],[".","Training Accuracy",".",".",".",".",".",".",".","."],[".","Validation Accuracy",".",".",".",".",".",".",".","."]],"region":"' + self.region + '","period":30}}]}'
response = client.put_dashboard(DashboardName=db_name, DashboardBody=dashboard_body)
return response
CloudWatch コンソールを開いて、[Dashboards (ダッシュボード)] を選択してから、以前作成したダッシュボードの名前を入力すると、以前のステップで作成した 2 つのグラフを表示することができます。
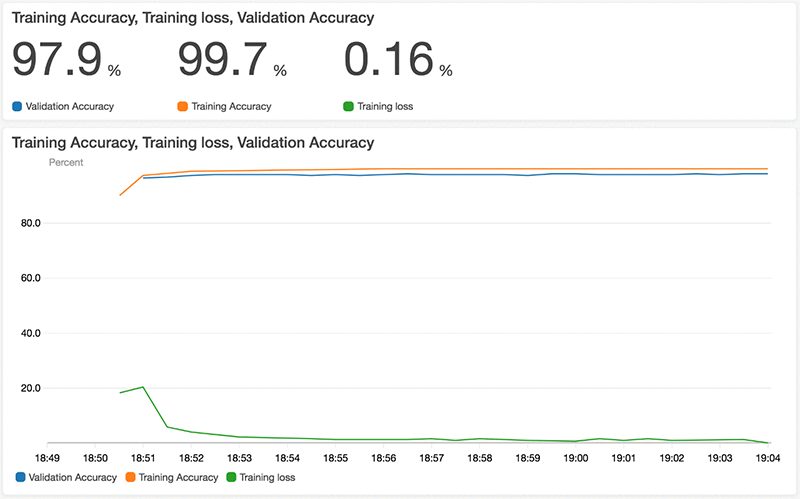
グラフ内の 3 つのメトリックスのいずれかの詳細を調べるには、グラフの下のメトリックス名をクリックします。特定のメトリックスについて、最小値、最大値、任意の時点の最後の値など、詳細が表示されます。
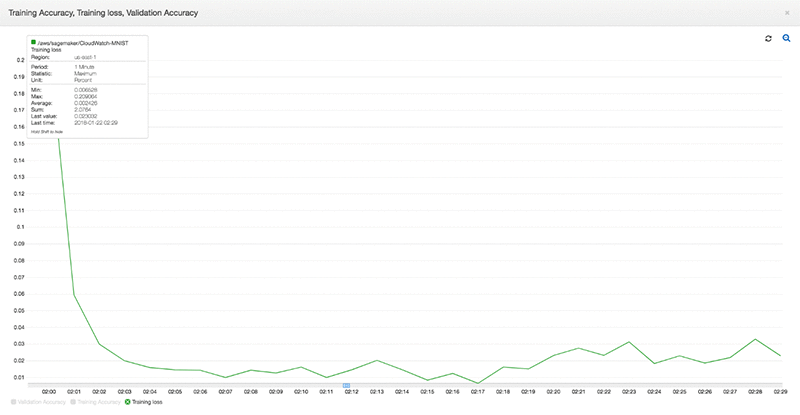
CloudWatch は、1 分データポイントであれば 15 日分、5 分データポイントであれば 63 日分、保持することができます。これにより、高解像度でモデルトレーニングの履歴にアクセスすることができます。また、コンソール内で [Metrics (メトリックス)] ビューを切り替えることによって、昔の評価メトリックスグラフをビジュアル化することもできます。そして CloudWatch にナビゲートして [Metrics (メトリックス)] を選択することによって、希望する時間枠の絶対値オプションを選択します。[custom Namespaces (カスタム名前空間)] セクションで、以前のステップで作成した名前空間を選択してから、希望するメトリックスを選択します。これにより、選択した時間枠の選択したメトリックスに関するすべてのデータが表示されます。
これは、トレーニング中の特定のイベントについて通知が欲しい場合、非常に役立ちます。プログラムによって、あるいは CloudWatch コンソールにナビゲートして、[Metrics (メトリックス)] を選択し、以前作成したカスタム名前空間を選択して、希望するメトリックスを選択することによって、アラームを作成することができます。そして、[Graphed metrics (グラフ化したメトリックス)] タブに切り替えて、  アイコンをクリックします。
アイコンをクリックします。

以下の例では、モデルで過剰適合が始まった場合、通知をメールで送信し、トレーニングジョブを停止するアラームを作成します。このデモでは、モデルの過剰適合をシミュレートするために、MNIST 検証データセットおよびトレーニングコードを操作しています。以下のダッシュボードコンソールのグラフは、トレーニングプロセスの最中にモデルが過剰適合になっていくために、検証精度が劣化していく様子を示しています。
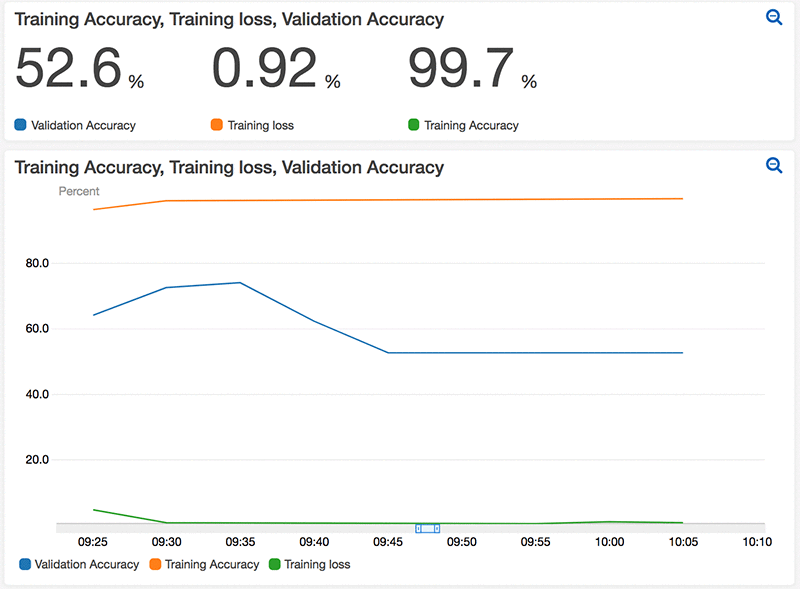
私は、training_function.py スクリプトでは以下の関数を使用して、SNS トピックに通知を送信するアラームを作成しました。このアラームは、5 分間の 10 個のデータポイントの検証精度が 90% 以下になったとき、トリガーされます。SNS トピックは、それに応じて、私のモデルが過剰適合になっていることを警告するメールを私に送信します。
# when creating an alarm that includes the 'Job Name' as one of the dimensions, then the CloudWatch
# metric created also needs to have 'Job Name' as one of the dimensions
def create_alarm(self, model_name, **kwargs):
hyperparameter = kwargs.get('hyperparameters')
job_name = str(hyperparameter.get('sagemaker_job_name'))
optimizer = str(hyperparameter.get('optimizer'))
epochs = str(hyperparameter.get('epochs'))
learning_rate = str(hyperparameter.get('learning_rate'))
namespace = '/aws/sagemaker/' + model_name
client.put_metric_alarm(
AlarmName='Overfitting Alarm',
ComparisonOperator='LessThanOrEqualToThreshold',
EvaluationPeriods=10,
DatapointsToAlarm=10,
MetricName='Validation Accuracy',
Namespace=namespace,
Period=30,
Statistic='Maximum',
Threshold=90.0,
ActionsEnabled=True,
AlarmActions=[
'arn:aws:sns:us-west-2:<account-id>:Sagemaker-Notification-Emails',
],
AlarmDescription='Alarm when the model is Overfitting',
Dimensions=[
{ 'Name': 'Model Name', 'Value': model_name },
{ 'Name': 'Job Name', 'Value': job_name },
{ 'Name': 'Learning Rate', 'Value': learning_rate },
{ 'Name': 'Optimizer', 'Value': optimizer },
{ 'Name': 'Epochs', 'Value': epochs},
],
Unit='Percent'
)
また、SNS トピックのパブリッシュイベントでトリガーされる Lambda 関数を作成することもできます。この Lambda 関数は、トリガーされると、SageMaker の stop_training_job API 演算を呼び出して、実行中のトレーニングを停止します。(Lambda 関数の作成方法については、『AWS Lambda – Lambda 関数の作成』を参照してください。)
import json
import boto3
def lambda_handler(event, context):
# Get the job name from the event
Trigger = event["Records"][0]["Sns"]["Message"]
Job = json.loads(Trigger)
# The index of the job name element will be the same as the one listed in the create_alarm() function
Job = Job["Trigger"]["Dimensions"][1]["value"]
# stop the training job if overfitting is detected
client = boto3.client('sagemaker')
response = client.stop_training_job(TrainingJobName=Job)
return response
Lambda 関数が SageMaker の stop_training_job API 演算を実行するには、適切な権限が付与されていること、および SNS トピックにイベントトリガーが設定されていることが必要であることに注意してください。
トレーニングを終了すると、私は数分後に、モデルが過剰適合になったことを知らせるメールを受信します。

Amazon SageMaker は、このモデル過剰適合アラームに応じて、トレーニングジョブを停止します。これは、AWS 管理コンソールに切り替えて、[Amazon SageMaker] を選択してから、[Jobs (ジョブ)] を選択することによって、表示することができます。training_function.py スクリプトは、検証精度が繰り返されるトレーニングを通じて最善の精度を保っている限り、各エポックでモデルのチェックポイントを作成することに注意してください。これにより、私はトレーニングジョブを停止する前に、必ずモデルの最新のチェックポイントが入手済みになっています。

トレーニングが十分に進行していない段階では、モデルのトレーニングを監視し続け、何かあれば、即座に対応できることが、非常に重要です。トレーニングのコストを下げるためにプロアクティブに行動し、モデルが遭遇する問題に対しては、いかなる問題であっても作成者に積極的に知らせる必要があります。
まとめ
Amazon SageMaker を使えば、ディープラーニングモデルのトレーニング、監視、およびデプロイを簡単に実行することができます。メトリックスの評価のために Amazon CloudWatch を集中化サービスとして使う利点は計り知れません。準リアルタイムでビジュアライゼーションを表示し、DL メトリックスの履歴レコードを保管し、メトリックスのイベントに対応するアラームおよび自動化アクションを作成し、すべての DL モデルのためのダッシュボードを構築して、カスタマイズすることができます。
今回のブログ投稿者について
 ワリード (ウィル) バドルは、オーストラリア・ニュージーランド (ANZ) 地域のシニアテクニカルアカウントマネージャーであり、AI および Machine Learning /深層学習に深い造詣を持っています。彼は、コミュニティに前向きな影響を与えるために、テクノロジを革新的な方法で使うことに情熱を持っています。彼は、時間が空けば、海に潜り、サッカーに興じ、太平洋の島々を探索しています。
ワリード (ウィル) バドルは、オーストラリア・ニュージーランド (ANZ) 地域のシニアテクニカルアカウントマネージャーであり、AI および Machine Learning /深層学習に深い造詣を持っています。彼は、コミュニティに前向きな影響を与えるために、テクノロジを革新的な方法で使うことに情熱を持っています。彼は、時間が空けば、海に潜り、サッカーに興じ、太平洋の島々を探索しています。