Amazon Web Services ブログ
集合知と Amazon SageMaker Ground Truth を併用したアノテーション精度の向上
Amazon SageMaker Ground Truthは、Machine Learning (ML) 用の高精度なトレーニングデータセットをすばやく構築するお手伝いをします。ご自身のワークフォース、データラベリングに特化したベンダー管理ワークフォースの選択、または Amazon Mechanical Turk が提供するパブリックワークフォースを使用して、データにラベルを生成することができます。
パブリックワークフォースは大規模で経済的ですが、多様なワーカーと同様で、ミスも生まれやすくなります。このような低品質のアノテーションから高品質のラベルを作成する 1 つの方法は、同じ項目の異なるワーカーからの応答を 1 つのラベルに体系的に結合することです。Amazon SageMaker Ground Truth には、この集計を実行する組み込みのアノテーション統合アルゴリズムが含まれているため、ラベリング作業の結果として精度の高いラベルを取得できます。
このブログ記事では、分類を行う場合 (例: “owl”、“falcon”、“parrot” などの画像にラベル付けする) に焦点を当て、単一の回答と多数決の 2 つの競合するベースラインアプローチに対するメリットを示します。
背景
ラベル付きデータセットを生成する最も簡単な方法は、各画像をシングルワーカーに送信することです。ただし、各画像がシングルワーカーによってのみラベル付けされているデータセットでは、品質が低下する可能性が高くなります。スキルの低さや無関心などの要因によって、低品質のラベルを提供するワーカーからエラーが入り込むことがあります。回答を複数のワーカーから引き出し、一定の原則に沿って集計すれば、品質を向上させることができます。複数のアノテーターの回答を簡単に集計するには、多数決 (MV) を使用します。多数決では、最も多くの票を獲得したラベルを単純に出力し、任意の結びつきをランダムに解消します。そのため、3 人のワーカーがそれぞれ、“owl”、“owl”、“falcon” と画像にラベル付けした場合、MV は最終ラベルとして、“owl” を出力します。また、3 人のワーカーのうち 2 人から “owl” という回答が得られたため、この出力に 0.67(= 2/3)の信頼度を割り当てることもできます。
単純で直感的なことですが、原則として MV は ワーカーのスキルが異なると、多くのマークを見逃します。たとえば、最初の 2 人のワーカー (両方とも “owl” というラベルを指定している) は 60% の確率で正しい傾向があり、最後のワーカー (“falcon” というラベルを指定している) は 80% の確率で正しい傾向があることがわかっているとします。ベイズの規則を使用した確率計算では、ラベル “owl” が 0.36 の正解率 (= 0.6*0.6*0.2*0.5/(0.6*0.6*0.2*0.5 + 0.4*0.4*0.8*0.5)) しかないことを示し、その結果、ラベル “falcon” の正解率は 0.64 (= 1 – 0.36) となります。このように、ワーカーのスキルを把握することで、より高いスキルを持つワーカーからの回答を支持し、最終的な出力を大幅に変えることができます。
当社の集計モデルは、Dawid と Skene [1] によって提案された古典的な期待値最大化の手法からヒントを得たもので、ワーカーのスキルを考慮しています。ただし、前述の例とは異なり、このアルゴリズムではワーカーの正確性を事前に把握しているわけではないため、最終的なラベルを推測しながらそれらを学習する必要があります。もしワーカーのスキルを知っていれば、(前述のように) 最終的なラベルを計算でき、もし真の最終的なラベルを知っていれば、(ワーカーが正しい頻度を確認することで) ワーカースキルを推定できます。これは、卵が先か鶏が先かという問題に近いものになります。どちらも分からないときは、([1] の場合と同様に) いくつかの数理的形式を解明してこれらを同時に学習する必要があります。このアルゴリズムは、ワーカーのスキルだけでなく最終ラベルを繰り返し学習し、反復によってワーカーのスキルと最終ラベルの予測に大きな変化が発生しなくなったときのみ終了することでこれを達成します。興味のある方は、ぜひ元の論文を読むことをお勧めします。以後の分析では、私たちで修正を加えた Dawid-Skene (MDS) モデルを使用します。
集計方法の比較
この投稿をより実践的に読み進めていただくための 2 通りの方法があります。analysis notebook をダウンロードすると、次のことが行えます。
- 302 個の鳥のイメージ (Google Open Images のデータセット から取得) を含む当社の 注釈が付いていないデータセット をダウンロードする。
- Ground Truth コンソールまたは Ground Truth API のいずれかを使って別のデータセット向けに新しいジョブを実行する。
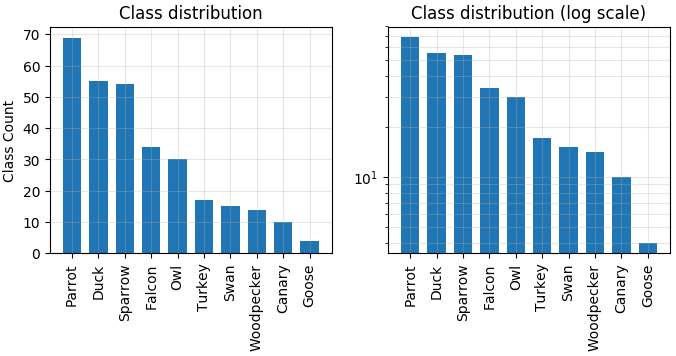
以下の解説では、注釈が付いていない 302 個の鳥のデータセットを使用します。次のグラフは、データセットにおけるクラスの分布を示しています。このデータセットは均衡がとれておらず、”owl” と “falcon”、あるいは “sparrow” と “parrot” と “canary” など相互に間違えられる可能性のあるカテゴリが含まれているので注意が必要です。
次に、修正した Dawid-Skene (MDS) モデルが 2 つのベースラインと比べてどのように実行されているかをみてみます。
- Single Worker (SW)。イメージの注釈付けを 1 人のワーカーのみに依頼し、彼らの応答を最終ラベルとして使用します。
- Majority voting (MV)。最終ラベルは、最も多く投票を集めた、均衡をランダムに破ったものになります。
次のグラフは、各イメージにラベルを付けるアノテーターの数を増やした場合の、エラー (= 1 – 精度) の変化を示したものです。点線は SW のベースラインの平均的パフォーマンスです。当然ながら、アノテーターの数が増えても変化はありません。たとえ何が起こっても、私たちは 1 つのイメージにつき 1 つの注釈しか見ないからです。たった 1 つの注釈だけで、MDS と MVの両方のパフォーマンスが SW のパフォーマンスに一致します。集計に対する応答がないためです。ただし、使用する注釈の数がどんどん増えていくと、統合の方法 (MDS と MV) は SW のベースラインを上回りはじめます。

ここで、2 人のアノテーターによる Majority voting のパフォーマンスが 1 人のアノテーターによるパフォーマンスとほぼ同じであるという、興味深い状況が観察できます。これは、1 つのイメージに対して 2 人のアノテーター (A および B) がいる場合、そこに一致があれば、最終的なアウトプットは、参加したワーカーが 1 人 (A または B) のみの場合と同じになるためです。もし一致せずに均衡がランダムに破られると、B が均衡を勝ち取り、最終的なアウトプットは、参加したワーカーが 1 人 (B) のみだった場合と同じになります。このことは、当社のモデルには当てはまりません。なぜなら、A が他の多くのワーカーと一致する傾向がある場合、モデルは B よりも A を信頼することを学習し、より良いパフォーマンスに導かれるからです。
もうひとつの非常に面白い洞察に満ちた可視化の方法が混同行列です。これは、あるクラスがデータセット内で別のクラスと間違えられる頻度を示しています。以下の表は、MDS を使用した後および MV を使用した後の、生の注釈 (集計されずに個々のワーカーから得られたすべての応答) の正規化された混同行列の列を示しています。理想的な混同行列は、対角成分が 1 でその他が 0 の単位行列です。したがって、他のクラスと区別がつかないクラスは絶対ありません。未加工の混同行列はかなり「雑然としている」ということに注意してください。 たとえば、「goose (がちょう)」ラベルが「duck (あひる)」、「swan (白鳥)」、および「falcon (はやぶさ)」に割り当てられることもあります。同様に、「parrot (オウム)」が「sparrow (スズメ)」や「canary (カナリア)」と間違ってラベルを張られることもよくあります。多数決と改良版 Dawid-Skene の両方で多数のエラーが訂正され、MDS では単位行列に近い混同行列をやや効率的に発生させてエラーを訂正しています。ただし、このデータセットによって 5 個の注釈が付いたMDS に相当する MV が比較的容易に引き起こされることに注意してください。

試験実行では、302 のイメージから、MDS が 273 のイメージの実際のラベルを復元し、その一方で MV が 272 の実際のラベルを復元したことを報告します。MV が間違ってラベルをつけて MDS が何とか訂正したイメージは 2 つで、MDS が間違ってラベルをつけて MV が何とか訂正したイメージは 1 つです。ここで留意すべきは、私たちの結果の絶対数がすべて、大まかなアルゴリズムの見本にすぎないということです。これはアルゴリズムが完全に決定論的ではないからであり (ランダムタイブレークなど)、私たちのモデルが着実に進歩していく予定だからです (パラメータ、チューニング、改良など)。
MDS は正しく識別したものの MV はしなかったイメージを見てみましょう。このケースでは、MDS は信頼ベースの判断を下したのに対して MV はランダムタイブレークにより間違った答えを導き出したようです。しかし、平均して MDS の方が MV より優れたパフォーマンスを発揮していることからわかるように、ランダム性だけでパフォーマンスの差が決まるわけではありません。いくつかのデータセットでは、MV のパフォーマンスが MDS に匹敵する場合があります。具体的には、データセットが比較的簡単である、またはワーカーの質がある程度均等である場合です。このデータセットでは、MV のパフォーマンスはアノテーター数が 5 の MDS に近づきますが、アノテーターが少なくなると差が開きます。2 つのアルゴリズムを試した別のいくつかのデータセットでは、パフォーマンスの差はさらに大きくなる場合があります。

MV は正しく識別したものの MDS はしなかった唯一のイメージです。

MDS と MV 両方が誤って識別したイメージも、興味深いことに性質的に最も難しい部類に含まれるものです。混同行列で言及されているように、「オウム」、「ツバメ」、「カナリヤ」は、互いに混同されてラベル付けされがちです。

結論
このブログ記事では、パブリックワーカーによる応答の集計がいかにラベルの精度を向上させられるかについてご説明しました。302 枚の鳥イメージデータセットを使用する場合、ワーカーがわずか 2 人でも、応答を集計する際のエラーは 1 人の場合と比べて 20% 減少します。また、今回使用したアルゴリズムは、ワーカーのスキルに対する推測を組み込むことで、幅広いアノテーター数に対応する普及している多数決技術よりも優れたパフォーマンスを発揮します。このアルゴリズムによる精度向上の可能性は、データセットおよびワーカー数により異なります。データセットが高難度で、スキルレベルがまちまちなワーカーを含むパブリックの労働力を利用する場合には、たいてい向上が見られます。
Ground Truth は現在、他に 3 つのタスクタイプをサポートしています。テキスト分類、物体検出、セマンティックセグメンテーションです。テキスト分類の集計方法は本記事で紹介した画像分類と同じですが、物体検出およびセマンティックセグメンテーションの場合、ラベルの集計には別のアルゴリズムが必要です。しかし、基本的な考え方は変わりません。質が低い可能性のある複数のアノテーションを結合させて、より高精度なラベルに仕上げるのです。
Open Images Dataset V4 に関する情報開示
Open Images Dataset V4 は、Google Inc. が作成したものです。場合により、イメージまたは付随するアノテーションを修正しています。元のイメージとアノテーションをこちらより入手できます。アノテーションは、Google Inc. が CC BY 4.0 ライセンスの元に使用しています。イメージは、CC BY 2.0 ライセンスがあるものを使用しています。Open Images V4 について、データ収集とアノテーションからデータに関する詳細な統計およびそれについてトレーニングしたモデルの評価にいたるまで、以下の論文が詳しく説明しています。
A.Kuznetsova、H. Rom、N. Alldrin、J. Uijlings、I. Krasin、J. Pont-Tuset、S. Kamali、S. Popov、M. Malloci、T. Duerig および V. Ferrari。The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. arXiv:1811.00982, 2018. (pdf)
[1] Dawid, A. P., & Skene, A. M.(1979).Maximum likelihood estimation of observer error‐rates using the EM algorithm.Journal of the Royal Statistical Society: Series C (Applied Statistics), 28(1), 20-28 (pdf).
著者について
 Sheeraz Ahmad は、AWS AI Lab の応用科学者です。カリフォルニア大学サンディエゴ校で博士号を取得した Sheeraz は、機械学習と認知科学をまたいだ研究に取り組み、生物がいかに学習して決定を下すかについての計算モデルを構築しました。Amazon では、クラウドソーシングによるデータの品質向上に取り組んでいます。余暇には、ボードゲーム、SF 小説、ウェイトリフティングを楽しんでいます。
Sheeraz Ahmad は、AWS AI Lab の応用科学者です。カリフォルニア大学サンディエゴ校で博士号を取得した Sheeraz は、機械学習と認知科学をまたいだ研究に取り組み、生物がいかに学習して決定を下すかについての計算モデルを構築しました。Amazon では、クラウドソーシングによるデータの品質向上に取り組んでいます。余暇には、ボードゲーム、SF 小説、ウェイトリフティングを楽しんでいます。
 Lauren Moos は、AWS AI のソフトウェアエンジニアです。Amazon で機械学習に関する幅広い問題に取り組んでいます。ストリーミングデータ向けの機械学習アルゴリズム、ヒューマンアノテーションの固定、コンピュータビジョン等です。最も興味を持っているのは、機械学習の認知科学および現代哲学との関係性です。余暇には、読書、コーヒー、ヨガを楽しんでいます。
Lauren Moos は、AWS AI のソフトウェアエンジニアです。Amazon で機械学習に関する幅広い問題に取り組んでいます。ストリーミングデータ向けの機械学習アルゴリズム、ヒューマンアノテーションの固定、コンピュータビジョン等です。最も興味を持っているのは、機械学習の認知科学および現代哲学との関係性です。余暇には、読書、コーヒー、ヨガを楽しんでいます。