おすすめ育児グッズ向け SNS を AWS 新人が作ってみた
2022-08-02 | Author : 佐山 朝葉 (監修 : ポール, 清水 崇之)

はじめに
こんにちは、アソシエイトソリューションアーキテクトの佐山です。
皆さん、AWSJ では入社後にどのような研修があるかご存じでしょうか ?
本記事では、キャリア採用の新人 SA 向けプログラムのうちの 1 つ、疑似プロジェクトについて紹介します。
私は、所属チームのマネージャー・メンターのサポートを受け、AWS Amplify を用いた SNS アプリケーションを作成しました。
操作画面でのデモをご覧ください。
本記事では、前半で実際にどんな研修なのか、チームマネージャー、メンター、そしてメンティーによる対談、そして後半は、AWS 新人が作ってみた SNS サイトの実装手順をご紹介します。
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
前半:どんな研修?チームマネージャー・メンター・メンティー対談
西日本のソリューションアーキテクトチーム
- 左:メンター ポール (@bulbulpaul / ソリューションアーキテクト)
- 中:さやま (アソシエイトソリューションアーキテクト 2022 年 4 月入社)
- 右:マネージャー しみず (AWS芸人 / @shimy_net /シニア マネージャー/ソリューションアーキテクト)

1. 疑似プロ・Working Backwards とは ?
しみず
「よく出来てるじゃないですか、なんすかこれ ?」
ポール
「いやいや、いきなり何言ってるか分からないです。仕事してくださいよ ?」
しみず
「あっ、『疑似プロ』という新人 SA 向けのトレーニングプログラムの一環でさやまさんに作ってもらったものを見ていました。『疑似プロ』は、アマゾンカルチャーのひとつである Working Backwards に沿ったサービス開発を理解するためのトレーニングプログラムです。Working Backwards というのは プレスリリース (PR) や FAQ を先に作ることで、お客様の課題やニーズをちゃんと整理してからシステム開発に着手しようという考え方です。このフレームワークを使うことでお客様が本当に求めるモノを提供できるかもしれません。そういったアマゾンカルチャーを含めて学んでいただきました。」

PR/FAQ
「ありがとうございます ! こちらが実際に作成した PR/FAQ です。」

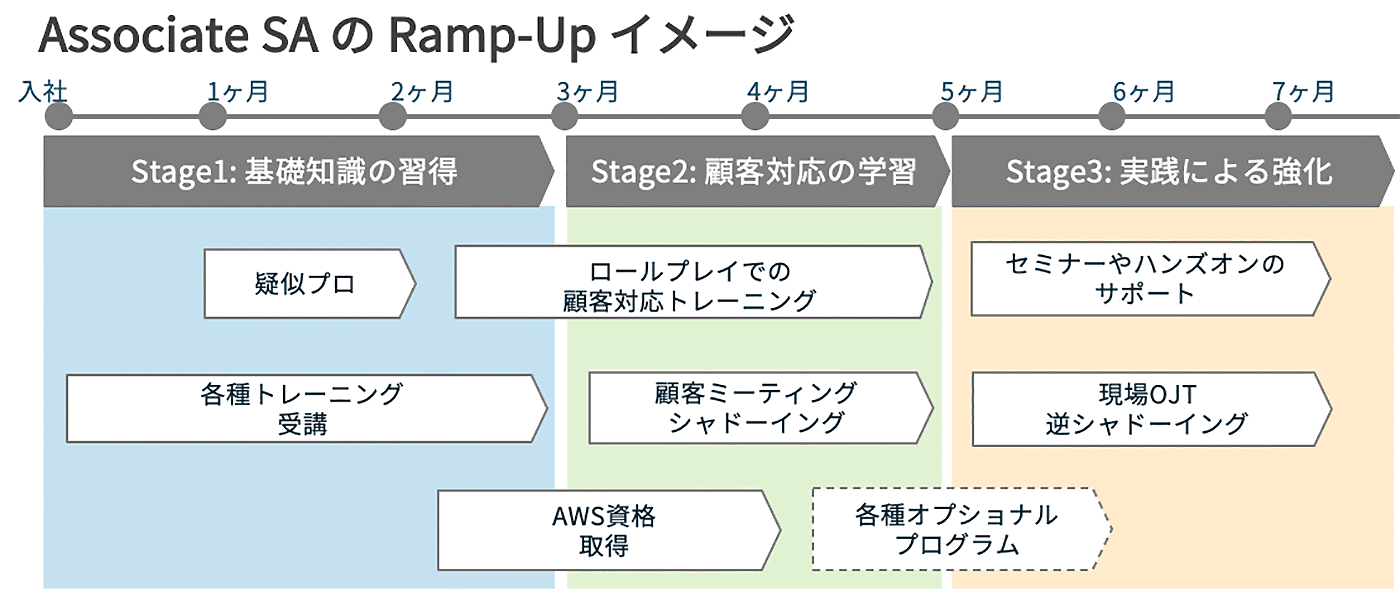
Associate SA の Ramp-Up イメージ
しみず
「新人 SA 向けのトレーニングプログラムも充実してきており、『疑似プロ』のほかにも座学、ロールプレイセッション、ハンズオンワークショップ、OJT、などなど、新人 SA の立ち上がりを支援するトレーニングプログラムがたくさんあります。」
しみず
「当人のレベル感によってカスタマイズしますが通常は 3ヶ月以上の時間をかけて育成しています。さやまさんのトレーニングには『疑似プロ』も組み込んでアプリ構築にもチャレンジしていただきました。」
さやま
「ということで、私がアプリを作りました !」
しみず
「ということで、今回はさやまさんとメンターのポールさんも参加いただいて、『擬似プロ』の体験談を聞いてみたいと思います。」
2. 初 AWS プログラミング、どうやって乗り切りましたか ?
さやま
「ポールさんがメンターを担当してくれました。疑似プロだけでなく、トレーニング期間全体を通じてサポートいただいてます。」
ポール
「メンターのポールです。」
しみず
「疑似プロを進める中でメンターとして意識した点はありますか?」
ポール
「さやまさんが AWS を使ったアーキテクチャ設計や開発経験が少ないって事だったので、まずはしっかりと手を動かしてもらってそこから情報を咀嚼して整理してもらいたいと思っていましたね。ちょっといじわるな言い方ですが、『たくさん困ってもらおう』『壁にぶち当たってもらおう』と。」
しみず
「なるほど、日々の筋トレは大事ですよね。少しキツいかなくらいの負荷を毎日かけてやると効率的に筋肉がつきます。ただ、負荷をかけすぎると体を壊しちゃうので、今回はその見極めができるポールさんにメンターをお願いしました。」
ポール
「さやまさんと話す中でしっかりと腹落ちさせたいタイプと言っていたので、その中で気になった点は咀嚼して納得するまで落とし込むアクションをしてくれるかな ? と思っていました。」
メンターの印象
しみず
「さやまさんのポールさんに対する印象はどうですか ?」
さやま
「親身にサポートしてくださる優しい先輩ですね。毎週の 1on1 や、適宜設けたアーキテクチャレビューの時間で相談してました。疑問点を都度解消できて、とってもありがたかったです。」
ポール
「コミュニケーションにコストをかけようと意識してましたね。入社時からリモートワークで個人ワークも多く、疑似プロに関しても一人で考えることが多いプログラムです。その中で何か課題があっても気付きづらいですよね。」

失敗も大事
ポール
「あとこれは少し反省してますが、無茶を言うてしまいました。『マネジメントコンソールで作るより CDK で書いたほうが早いよ。』とか。それはさすがに突っ込まれました。」
しみず
「そこは Chalice もお勧めしてほしいなぁ (謎の Chalice 推し)」
ポール
「あとは答えを教えちゃいそうになるので大変。というかすぐ答えとか教えてしまう問題・・・。しみずさんマネージャー的にその辺のフォローとかどう考えてました ?」
しみず
「そうですねぇ、本人に転んでもらうことって大事だと思うんです。教える側としては事前に障害物を取り除きたくなっちゃうんですが、それをしてしまうと本人は障害物 (課題) があることにも気づけずに、結果的に成長につながらないですよね。私はマネージャーになってからは『最近どうっすか ?』から会話を始めるようにして、できるだけ『本人に喋ってもらう』『本人に気づいてもらう』ように気をつけています。それはさておき Chalice はお勧めです。」
ポール
「いや、Chalice 好きすぎでしょ (笑)」
しみず
「ちょりーっす」
さやま & ポール
「・・・(一同沈黙)」
ポール
「ところでさやまさんは AWS を使ったアーキテクチャ設計や開発をやることになって、どんな点で苦労されました ? それをどうやって乗り越えていきましたか ?」
さやま
「作りたいテーマに対して、どのサービスをどう使えばいいのかがわからなくて大変でした・・・。AWS の代表的なサービスと用途の理解には、Practitioner Essentials デジタルコース (日本語実写版) が役立ちました。あとは AWS Hands-on for Beginners やサービス毎のハンズオンコンテンツをまずは触ってみて使い方を知って、実装に取り込む、エラーでつまる、ということを繰り返してましたね。」
しみず
「エラーメッセージをしっかり読んで、何が起こっているのを把握しながら進めるのも経験してもらえたのはよかったですね。推測じゃなく現実に起こっている事実から原因突き止めて改善することは非常に重要だと思います。」
3. 作り終えての学びは ?
さやま
「 Working Backward に沿って開発すると、サービスの軸をぶらさず顧客志向で進められること、また AWS は社内外の学習コンテンツが豊富なので、まず手を動かすと初学者でも色々作れること、を実感しました。開発経験があまり無く、始まる前は不安でしたが、ポールさんやチームの方々のアドバイスのおかげでやりきることができました。一人前のアマゾニアンに一歩近づけた気がします ! 清水さん、読者のみなさんにメッセージとかありますか ?」
しみず
「西日本ソリューションアーキテクトチームでは、大阪と福岡のポジションのソリューションアーキテクトを募集しています。SIer、スタートアップ、サービスプロバイダー、通信企業など様々なキャリアから、そして AWS 未経験でジョインしたソリューションアーキテクトも多いです。ご興味のある方はぜひチャレンジしてください。」
後半 : AWS 新人が作ってみた SNS サイトの実装手順紹介
4. サービス概要
「おすすめの育児グッズ情報を信頼できる知人と共有できる SNS」です。
- 育児グッズ選びは大変である
- 知人の口コミは参考になる
- COVID-19 の影響により知人からの情報収集の機会が減った、
という調査結果を踏まえ、育児グッズ選びの困難さへの解決策になるサービスを目指しました。5 つの機能 (投稿、閲覧、フォローリスト、検索、おすすめ投稿のメール配信) を持つ Twitter ライクな SNS です。
※本記事では、どのような流れで作成したかをご紹介します。全てのソースコードは掲載しておりません。
5. アーキテクチャ
「AWS SNS」とネット検索し、見つけたワークショップ AMPLIFY SNS WORKSHOP をベースに拡張していきます。完成形のアーキテクチャ図はこちらです。ピンクにハイライトをしている個所が、ワークショップで作成できる部分です。アーキテクチャの工夫点は下記の 3 点です。
-
"友人の友人" を効率的に取得するために、グラフデータベース Amazon Neptune を使用する
-
“おすすめ投稿のメール配信” の処理負荷を平準化するために、随時処理部分 (Amazon DynamoDB Streams を使用した投稿データの感情分析) とバッチ処理部分 (Amazon EventBridge を使用したメール配信)にわける
-
ユーザー毎にカスタマイズしたメールを一斉配信するため、Amazon SQS とAmazon SES を組み合わせる
アーキテクチャ図
6. ベースとなる AMPLIFY SNS WORKSHOP を動かす
AMPLIFY SNS WORKSHOP を実施します。
ライブラリエラーの解消法がわからず、動かすまで 2 週間かかりました。今回はエラー解消のために、手順従ってライブラリをインストールした後に下記を実行しています。
インストール
react と react-dom のインストール
npm install react react-dom7. SNS 機能をカスタマイズする
7-1. 友人の友人の投稿を閲覧できるようにする
"友人の友人" を効率的に取得するために、グラフデータベース Amazon Neptune でフォロー関係を管理します。
まず、"誰が誰をフォローしているか" を DynamoDB に書き込み、その DynamoDB Streams をトリガーに AWS Lambda の関数を実行し、Neptune を更新します。Neptune の起動や Lambda の設定は、Amazon Neptune でゲームの友人レコメンドエンジンを構築する を参考にしました。

[ソースコード] フォロー管理グラフDB更新 lambda
const gremlin = require('gremlin');
const async = require('async');
const traversal = gremlin.process.AnonymousTraversalSource.traversal;
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection;
const t = gremlin.process.t;
const __ = gremlin.process.statics;
let conn = null;
let client = null;
//関数:フォロー関係の追加
async function insertRelationship(followeeId,followerId) {
//フォローするユーザーのノードを作成(未作成の場合)
await client.V(followeeId)
.fold()
.coalesce(
__.unfold(),
__.addV('User').property(t.id, followeeId).property('username', followeeId)
)
.id().next();
//フォローされるユーザーのノードを作成(未作成の場合)
await client.V(followerId)
.fold()
.coalesce(
__.unfold(),
__.addV('User').property(t.id, followerId).property('username', followerId)
)
.id().next();
//フォローしている、フォローされていることを示すエッジ用のIdを定義
const eId_follow = followeeId+followerId+'follow';
const eId_follower = followerId+followeeId+'followee';
//フォローしていることを示すエッジを作成
await client.E(eId_follow)
.fold()
.coalesce(
__.unfold(),
__.V(followerId).addE('follow').to(__.V(followeeId)).property(t.id, eId_follow).property('inV', followeeId)
)
.id().next();
//フォローされていることを示すエッジを作成
await client.E(eId_follower)
.fold()
.coalesce(
__.unfold(),
__.V(followeeId).addE('followee').to(__.V(followerId)).property(t.id, eId_follower).property('inV', followerId)
)
.id().next();
}
//関数:フォロー関係の削除
async function removeRelationship(followeeId,followerId) {
//フォローしている人とされている人の間にあるエッジを削除
await client.V().has('User','username', followerId)
.bothE().hasLabel('follow')
.has('inV',followeeId)
.drop().iterate();
await client.V().has('User','username', followeeId)
.bothE().hasLabel('followee')
.has('inV',followerId)
.drop().iterate();
}
//メイン:Neptuneに対してフォロー関係の更新
exports.handler = async (event, context) => {
var eventname = '';
var followeeId = '';
var followerId = '';
//Neptuneへ接続
const getConnectionDetails = () => {
const database_url = 'wss://' + process.env['NEPTUNE_ENDPOINT'] + '/gremlin';
return database_url;
};
const createRemoteConnection = () => {
const url = getConnectionDetails();
const c = new DriverRemoteConnection(
url,
{
mimeType: 'application/vnd.gremlin-v2.0+json'
});
c._client._connection.on('close', (code, message) => {
console.info(`close - ${code} ${message}`);
if (code == 1006){
console.error('Connection closed prematurely');
throw new Error('Connection closed prematurely');
}
});
return c;
};
const createGraphTraversalSource = (conn) => {
return traversal().withRemote(conn);
};
if (conn == null){
console.info("Initializing connection");
conn = createRemoteConnection();
client = createGraphTraversalSource(conn);
}
//DynamoDBストリームから取得したフォロー関係の処理
for (let record of event.Records){
//フォロー関係と、イベント(追加or削除)の取得
if(record.dynamodb.Keys.followeeId != null){
followeeId = record.dynamodb.Keys.followeeId.S;
followerId = record.dynamodb.Keys.followerId.S;
eventname = record.eventName;
}
//イベント(追加or削除)に応じた関数を実行しNeptuneを更新
try{
if(eventname==='INSERT'){
let insert = await insertRelationship(followeeId, followerId);
}else if(eventname==='REMOVE'){
let remove = await removeRelationship(followeeId, followerId);
}
} catch (error) {
console.error(JSON.stringify(error));
return { error: error.message };
}
}
};7-2. 新規投稿に応じて、タイムラインを構築
“友人の友人まで“ の投稿を閲覧可能にするために、あるユーザーが新規投稿をすると関連するユーザーのタイムラインを更新します。(例 : 下記図で X さんが投稿すると A さん, B さんのタイムラインを更新。)
Lambdaは、AWS AppSync から投稿データを受け取った後、Neptune から対象ユーザーリストを取得し、タイムライン情報を更新します。投稿の元データは、投稿データのDBに格納しています。
AWS Amplify で作成した Lambda から、VPC 内の Neptune に Gremlin で接続 できるようにする方法は、こちらの記事 (Amazon Neptune と AWS Amplify を利用したグラフアプリケーション開発) を参考にしました。

ソースコード] 投稿内容反映 Lambda ※AMPLIFY SNS WORKSHOP の差分個所
const gremlin = require('gremlin');
const traversal = gremlin.process.AnonymousTraversalSource.traversal;
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection;
const t = gremlin.process.t;
const __ = gremlin.process.statics;
const neq = gremlin.process.P.neq;
const without = gremlin.process.P.without;
const values = gremlin.process.column.values;
const P = gremlin.process.P;
let conn = null;
let client = null;
:※AMPLIFY SNS WORKSHOPに記載の部分は省略
//投稿者の投稿を閲覧できるユーザーリストをNeptuneから取得
//(投稿者本人、投稿者をフォローしている人、更にその人をフォローしている人)
//Neptuneへ接続
const getConnectionDetails = () => {
const database_url = 'wss://' + process.env['NEPTUNE_ENDPOINT'] + ':' + process.env['NEPTUNE_PORT'] + '/gremlin';
return database_url;
};
const createRemoteConnection = () => {
const url = getConnectionDetails();
const c = new DriverRemoteConnection(
url,
{
mimeType: 'application/vnd.gremlin-v2.0+json'
});
c._client._connection.on('close', (code, message) => {
console.info(`close - ${code} ${message}`);
if (code == 1006){
console.error('Connection closed prematurely');
throw new Error('Connection closed prematurely');
}
});
return c;
};
const createGraphTraversalSource = (conn) => {
return traversal().withRemote(conn);
};
if (conn == null){
console.info("Initializing connection");
conn = createRemoteConnection();
client = createGraphTraversalSource(conn);
}
//投稿者のIDを取得
const followeeId = event.identity.username;
//投稿者をフォローしている人のリストをNeptuneから取得
let friendlist =
await client.V().has('User','username', followeeId).as('user')
.out('followee')
.values('username')
.toList();
//"投稿者をフォローしている人"をフォローしている人のリストをNeptuneから取得
let nextfriendlist =
await client.V().has('User', 'username', followeeId).as('user')
.out('followee').aggregate('friends')
.out('followee')
.where(without('friends'))
.where(neq('user'))
.dedup()
.values('username')
.toList();
//取得結果をマージし、投稿者の投稿を閲覧できるユーザーリストを作成
//(投稿者本人、投稿者をフォローしている人、更にその人をフォローしている人)を
let followers = friendlist.concat(nextfriendlist);
followers.push(followeeId);
//投稿を閲覧できるユーザーのタイムラインに表示するように、タイムラインDBを更新
const results = await Promise.all(followers.map((follower)=> createTimelineForAUser({follower: follower, post: post})));
return post;7-3. フォローリストを取得できるようにする
フォローしているユーザーリストと、「もしかして友人かも ?」というレコメンドを表示します。「もしかして友人かも ?」というレコメンドは、フォローしている人 (= 友人) の多くがフォローしている人は友人の可能性が高い、という考えに基づきます。フォローリストは DynamoDB から、レコメンドは Neptune から取得します。

[ソースコード] フォローレコメンド取得 Lambda
const gremlin = require('gremlin');
const async = require('async');
const traversal = gremlin.process.AnonymousTraversalSource.traversal;
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection;
const t = gremlin.process.t;
const __ = gremlin.process.statics;
const neq = gremlin.process.P.neq;
const without = gremlin.process.P.without;
const values = gremlin.process.column.values;
const P = gremlin.process.P;
const order = gremlin.process.order;
const local = gremlin.process.scope.local;
const desc = gremlin.process.order.desc;
let conn = null;
let client = null;
//フォローしている人の多くがフォローしている人(上位5名)を取得
exports.handler = async (event, context, callback) => {
//Neptuneへ接続
const getConnectionDetails = () => {
const database_url = 'wss://' + process.env['NEPTUNE_ENDPOINT'] + ':' + process.env['NEPTUNE_PORT'] + '/gremlin';
return database_url;
};
const createRemoteConnection = () => {
const url = getConnectionDetails();
const c = new DriverRemoteConnection(
url,
{
mimeType: 'application/vnd.gremlin-v2.0+json'
});
c._client._connection.on('close', (code, message) => {
console.info(`close - ${code} ${message}`);
if (code == 1006){
console.error('Connection closed prematurely');
throw new Error('Connection closed prematurely');
}
});
return c;
};
const createGraphTraversalSource = (conn) => {
return traversal().withRemote(conn);
};
if (conn == null){
console.info("Initializing connection");
conn = createRemoteConnection();
client = createGraphTraversalSource(conn);
}
//レコメンドを取得したいユーザーのIDを取得
const username = event.identity.username;
//ユーザーがフォローしている人の多くがフォローしている人(上位5名)を取得
let recomendlist =
await client.V().has('User', 'username', username).as('user')
.out('follow').aggregate('friends')
.out('follow')
.where(without('friends'))
.where(neq('user'))
.values('username')
.groupCount()
.order(local)
.by(values,desc)
.limit(local,5)
.toList();
//レコメンドユーザーリスト(IDと何人のフォロワーがフォローしているか)を作成
var keys = Object.keys(recomendlist[0]);
var counts = Object.values(recomendlist[0]);
var array = [];
keys.forEach((elem,index)=> {
array.push({'username':elem,'count':counts[index]});
});
return array;
};7-4. 画像投稿を可能にする
画像も投稿できるようにします。Amplify では、CLI とライブラリを使用して Amazon S3 を利用するストレージサービスを簡単に作成可能です。作成は、こちらのハンズオン (AWS で React アプリケーションを構築する) を参考にしました。
7-5. コメント投稿を可能にする
せっかくなのでコメント投稿もできるようにします。投稿 ID に紐づけて管理をするために、コメントデータ用の DynamoDB を Amplify で作成します。
※実装したモデルでは、同じ時間に投稿が重複すると上書きされるため、本来は更に工夫すべきです。
[ソースコード] graphql スキーマ
type Comment
@model (
mutations: {create: "createComment", delete: "deleteComment", update: null}
timestamps: null
subscriptions: { level: public}
)
@auth(rules: [
{allow: owner, ownerField:"owner", provider: userPools, operations:[read, create, delete]}
{allow: private, provider: userPools, operations:[read, create, delete]}
])
@key(fields: ["postId", "timestamp"])
{
postId: ID!
timestamp: Int!
commentId: ID
content: String!
owner: String
}7-6. フロントエンドを実装する
本記事では詳細は割愛しますが、React + AppSync + Amplify で構築しています。

8. おすすめ投稿のメール配信機能を作る
8-1. メール配信用のユーザー管理 DB を作る
メール配信処理用にユーザー名とメールアドレスのみを保持するユーザー管理 DB を作成します。Amplify の認証機能で使用している Amazon Cognito で ユーザー確認を実施したことをトリガー に DynamoDB に書き込みます。
[ソースコード] ユーザー管理 DB 更新 Lambda
import os
import json
import datetime
import zoneinfo
import boto3
userdb = boto3.resource('dynamodb').Table(os.getenv['USER_TABLE_NAME'])
#ユーザー管理テーブルへ、ユーザーID・メールアドレス・タイムスタンプを書き込み
def lambda_handler(event, context):
userdb.put_item(
Item = {
'user':event['userName'],
'address':event['request']['userAttributes']['email'],
'timestamp':datetime.datetime.now(zoneinfo.ZoneInfo('Asia/Tokyo')).strftime("%Y%m%d%H%M%S")
}
)
return event;8-2. 新規投稿を感情分析して、データベースに格納しておく
投稿データ DB の DynamoDB Streams を Lambda でトリガーし、新規投稿があるたびに Amazon Comprehend で感情分析をします。結果は投稿 ID と共に評価データ DB に格納しておきます。Lambda と Comprehend の接続はこちらのハンズオン (AWS Hands-on for Beginners) を参考にしました。

[ソースコード] 投稿の感情分析 Lambda
import os
import json
import boto3
from decimal import Decimal
comprehend = boto3.client('comprehend')
ratingdb = boto3.resource('dynamodb').Table(os.environ['RATING_TABLE_NAME'])
#投稿本文をcomprehendで感情分析し、評価データDBを更新
def lambda_handler(event, context):
#DynamoDBストリームから取得した投稿を1つずつ処理
for record in event['Records']:
#投稿本文を取得しcomprehendを実行
content = record['dynamodb']['NewImage']['content']['S']
response = comprehend.detect_sentiment(
Text=content,
LanguageCode='ja'
)
#投稿タイムスタンプを取得し、comprehend実行結果と共に評価データDBへ書き込み
timestamp=int(record['dynamodb']['NewImage']['timestamp']['N'])
ratingdb.put_item(
Item = {
'postId':record['dynamodb']['NewImage']['id']['S'],
'timestamp':timestamp,
'type':'sentimentscore',
'sentimentscore':{
'positive': Decimal(response['SentimentScore']['Positive']),
'negative': Decimal(response['SentimentScore']['Negative']),
'neutral': Decimal(response['SentimentScore']['Neutral']),
'mixed': Decimal(response['SentimentScore']['Mixed']),
}
}
)
return {
'statusCode': 200,
}8-3. おすすめ投稿メールを作成し配信する
ユーザーのタイムライン内の投稿のうち、最も感情分析の Positive の値が高い = 熱量がある投稿内容、と判定しメールで配信します。
ユーザー数が増えた際に Lambda 関数がタイムアウトすることを防ぐため、SQS にユーザーリストをキューイングしておき、Lambda 関数にて一定数毎に配信するようにしました。
同一メールの重複配信を防ぐために FIFO キューを利用し、Lambda 関数が最大 5 並列になるように実装しています。FIFOキューでのLambda関数の並列実行(メッセージグループID設定)は、こちらの記事 (New for AWS Lambda – SQS FIFO as an event source) を参考にしました。
Amazon Simple Notification Service (Amazon SNS) でもメール配信は可能ですが、ユーザー毎にカスタマイズした文面を配信するために、Amazon Simple Email Service (Amazon SES) を利用します。
定期配信のために、EventBridge で設定したスケジュールに従って Lambda 関数を実行 しています。

[ソースコード] ユーザー情報取得 Lambda
import os
import json
import boto3
from boto3.dynamodb.conditions import Key
sqs = boto3.client('sqs')
queue_url = os.environ['QUEUE_URL']
queue_group = 'SQSキューグループ名'
userdb = boto3.resource('dynamodb').Table(os.environ['USER_TABLE_NAME'])
#ユーザーリストを取得し、ユーザー毎にIDとメールアドレスをSQSのキューへ登録
def lambda_handler(event, context):
# ユーザーリスト取得
response = userdb.scan()
userlist = response['Items']
while 'LastEvaluatedKey' in response:
response = userdb.scan(ExclusiveStartKey=response['LastEvaluatedKey'])
userlist.extend(response['Items'])
#FIFOキューで使用するgroupIdの定義
groupId = 0
#ユーザー毎にユーザー情報をSQSに追加
for record in userlist:
#MassageGroupIdを5つに分割するための処理(0~4になるようにリセット)
if groupId = 5:
groupId = 0
#SQSへユーザー情報を追加
items = json.dumps(record)
response = sqs.send_message(QueueUrl=queue_url, MessageBody=items, MessageGroupId=queue_group+groupId)
groupId += 1 #ユーザー毎にMassageGroupIdのインクリメント
return {
'statusCode': 200
}
[ソースコード] 配信メール作成 Lambda
import os
import json
import boto3
from boto3.dynamodb.conditions import Key
import pandas as pd
dynamodb = boto3.resource('dynamodb')
ratingdb = dynamodb.Table(os.environ['RATING_TABLE_NAME'])
timelinedb = dynamodb.Table(os.environ['TIMELINE_TABLE_NAME'])
postdb = dynamodb.Table(os.environ['POST_TABLE_NAME'])
sesclient = boto3.client('ses')
SOURCE_ADDRESS = '※配信元アドレス※'
START_TIMESTAMP = 1651330800 # 2022-05-01T0:10:00 ※UNIX時間
END_TIMESTAMP = 1656601200 # 2022-07-01T0:10:00 ※UNIX時間
SUBJECT = '今週のおすすめ投稿'
#ユーザーへのおすすめ投稿を判定し、SESでメール配信
def lambda_handler(event, context):
#期間内の投稿内容の評価結果(comprehend結果)を評価データDBから取得
response = ratingdb.query(
IndexName="type-timestamp-index",
KeyConditionExpression=Key('type').eq('sentimentscore') & Key('timestamp').between(START_TIMESTAMP, END_TIMESTAMP)
)
#おすすめ投稿の判定のために、評価結果のリストを、pandasデータフレームに格納
rating= response['Items']
ratingdf = pd.json_normalize(rating)
#ユーザー毎の配信作成。SQSのキューを1つずつ処理
for record in event['Records']:
record=eval(record['body']) #body 内をstring -> dict
user = record['user']
#ユーザーのタイムライン情報(投稿ID)をタイムラインDBから取得
response = timelinedb.query(
KeyConditionExpression=Key('userId').eq(user) & Key('timestamp').between(START_TIMESTAMP, END_TIMESTAMP)
)
timelinelist=response['Items']
while 'LastEvaluatedKey' in response:
response = timelinedb.query(
KeyConditionExpression=Key('userId').eq(user) & Key('timestamp').between(START_TIMESTAMP, END_TIMESTAMP),
ExclusiveStartKey=response['LastEvaluatedKey']
)
timelinelist.extend(response['Items'])
#期間内のタイムラインに投稿が1件以上ある場合、処理を継続
if response['Count'] != 0:
#おすすめ投稿の判定のために、タイムラインの投稿リストを、pandasデータフレームに格納
timelinedf = pd.json_normalize(timelinelist)
#投稿リストから自分の投稿を削除
timelinedf = timelinedf[~timelinedf['postUserId'].str.contains(user)]
#自分以外の投稿が1件以上ある場合、メール配信処理を実施
if len(timelinedf) != 0:
#評価結果データフレームとタイムラインデータフレームを投稿IDでマージ
reportdf = pd.merge(ratingdf, timelinedf, on='postId',how='inner')
#結果のscore部分をfloatに変更し、positiveの値がもっとも高い投稿IDを抽出
reportdf = reportdf.astype({'sentimentscore.positive': float})
reportpostindex = reportdf['sentimentscore.positive'].idxmax()
reportpostdf = reportdf.loc[reportpostindex,["postId"]]
reportpostdf = reportpostdf.astype(str)
#投稿IDを持つ投稿の詳細を投稿データDBから取得
response = postdb.get_item(
Key={
'id':reportpostdf['postId']
}
)
reportpost = response['Item']
#投稿詳細とユーザーデータを使用してユーザーへemail送信
response = sesclient.send_email(
Source=SOURCE_ADDRESS,
Destination={
'ToAddresses': [
record['address'],
]
},
Message={
'Subject': {
'Data': SUBJECT,
},
'Body': {
'Text': {
'Data':
record['user']+"さんへのおすすめ投稿\n\n"+"商品名:"+reportpost['title']+"\n"+"説明:"+reportpost['content']+"\n"+"投稿者:"+reportpost['owner']+"\n",
}
}
}
)9. Amplify 以外を CDK で管理する
Amplify 以外の部分を、AWS Cloud Development Kit (AWS CDK) で管理できるようにします。こちらのハンズオン (TypeScript Workshop :: AWS Cloud Development Kit (AWS CDK) Workshop) で基本を理解し、CDK のサンプル集 を参考に作成しました。特にNeptuneは こちら を参考にしました。
構成図
[ソースコード] CDK stack.ts
CDK stack.ts
import { Duration, Stack, StackProps } from 'aws-cdk-lib';
import * as sqs from 'aws-cdk-lib/aws-sqs';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import * as cdk from 'aws-cdk-lib';
import * as dynamodb from 'aws-cdk-lib/aws-dynamodb';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as events from 'aws-cdk-lib/aws-events';
import * as targets from 'aws-cdk-lib/aws-events-targets';
import * as ec2 from 'aws-cdk-lib/aws-ec2';
import * as neptune from '@aws-cdk/aws-neptune-alpha';
import { Construct } from 'constructs';
import { DynamoEventSource, SqsEventSource } from 'aws-cdk-lib/aws-lambda-event-sources';
import { ImagePullPrincipalType } from 'aws-cdk-lib/aws-codebuild';
import { AssetCode, LayerVersion, Runtime } from 'aws-cdk-lib/aws-lambda';
import { SecurityGroup } from 'aws-cdk-lib/aws-ec2';
export class GijiprosnscdkStack extends Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
//cognitoの新規ユーザー登録に応じてユーザー管理DBを更新する部分
//ユーザー管理 DynamoDB
const user_table = new dynamodb.Table(this, 'user_table', {
partitionKey: { name: 'user', type: dynamodb.AttributeType.STRING }
});
//ユーザー管理DB更新lambda
const updateUserDB = new lambda.Function(this, 'updateUserDBHandler', {
runtime: lambda.Runtime.PYTHON_3_9,
code: lambda.Code.fromAsset('lambda'),
handler: 'updateUserDB.lambda_handler',
environment:{
USER_TABLE_NAME: user_table.tableName
}
});
//ユーザー管理DB更新lambdaへユーザー管理DB読み書き権限追加
user_table.grantReadWriteData(updateUserDB)
//新規投稿に応じて、本文を感情分析し評価データDBを更新する部分
//評価データ管理DynamoDB
const rating_table = new dynamodb.Table(this, 'rating_table', {
partitionKey: { name: 'postId', type: dynamodb.AttributeType.STRING },
});
//評価データ管理DynamoDBを期間でデータ取得するためにGlobalSecondaryIndex追加
rating_table.addGlobalSecondaryIndex({
indexName: 'type-timestamp-index',
partitionKey: {name: 'type', type: dynamodb.AttributeType.STRING},
sortKey: {name: 'timestamp', type: dynamodb.AttributeType.NUMBER},
});
//投稿の感情分析lambda
const updateRatingDB = new lambda.Function(this, 'updateRatingDBHandler', {
runtime: lambda.Runtime.PYTHON_3_9,
code: lambda.Code.fromAsset('lambda'),
handler: 'updateRatingDB.lambda_handler',
environment:{
RATING_TABLE_NAME: rating_table.tableName
}
});
//投稿の感情分析lambdaへcomprehend 実行ポリシー追加
updateRatingDB.addToRolePolicy(new iam.PolicyStatement({
actions: [
"comprehend:*"
],
resources: ["*"],
}))
//投稿の感情分析lambdaへ管理DB読み書き権限追加
rating_table.grantReadWriteData(updateRatingDB);
//Amplifyで作成した投稿データDynamoDBの情報取得
const post_table = dynamodb.Table.fromTableAttributes(
this, 'post_table', {
tableArn: '※投稿データDBのARN',
tableStreamArn: '※投稿データDBのストリームARN'
}
);
//投稿の感情分析lambdaに投稿データDBのdynamodbストリーム追加
updateRatingDB.addEventSource(
new DynamoEventSource(post_table,{
startingPosition: lambda.StartingPosition.LATEST
})
)
//おすすめ投稿のメール配信部分
//ユーザー情報取得Lambda
const createDataforReport = new lambda.Function(this, 'createDataforReport',{
runtime: lambda.Runtime.PYTHON_3_9,
code: lambda.Code.fromAsset('lambda'),
handler: 'createDataforReport.lambda_handler',
environment:{
USER_TABLE_NAME: user_table.tableName
}
})
//ユーザー情報取得Lambdaからのユーザーリスト送信先 SQS FIFOキュー
const userListqueue = new sqs.Queue(this, 'userListqueue', {
visibilityTimeout: Duration.seconds(300) ,
fifo: true,
contentBasedDeduplication: true
});
//ユーザー情報取得LambdaへSQSURLを環境変数として設定
createDataforReport.addEnvironment('QUEUE_URL', userListqueue.queueUrl);
//ユーザー情報取得LambdaへSQSポリシー追加
createDataforReport.addToRolePolicy(new iam.PolicyStatement({ actions: ['sqs:SendMessage'], resources: [userListqueue.queueArn] }));
//ユーザー情報取得LambdaへDynamoDB読み取りポリシー追加
user_table.grantReadData(createDataforReport);
//定期的にユーザー情報取得Lambdaを起動するためのEventBridge設定
new events.Rule(this, "reportRule", {
// JST で毎月最終日の 16:00 に定期実行
// see https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/events/ScheduledEvents.html#CronExpressions
schedule: events.Schedule.cron({minute: "0", hour: "16", day: "L"}),
targets: [new targets.LambdaFunction(createDataforReport, {retryAttempts: 3})],
});
//配信メール作成Lambda用に、Amplifyで作成したLambdaLayer(pandas)の情報取得
const pandasLayer = LayerVersion.fromLayerVersionArn(this, 'pandasLayer', '※lambdalayerのARN');
//Amplifyで作成したタイムラインDynamoDBの情報取得
const timeline_table = dynamodb.Table.fromTableName(
this, 'timeline_table', '※タイムラインテーブル名'
);
//配信メール作成Lambda
const createReportEmail = new lambda.Function(this, 'createReportEmail',{
runtime: lambda.Runtime.PYTHON_3_9,
code: lambda.Code.fromAsset('lambda'),
handler: 'createReportEmail.lambda_handler',
environment:{
RATING_TABLE_NAME: rating_table.tableName,
POST_TABLE_NAME:post_table.tableName,
TIMELINE_TABLE_NAME:timeline_table.tableName,
},
layers:[pandasLayer]
});
//配信メール作成LambdaのイベントソースにSQSを設定
createReportEmail.addEventSource(new SqsEventSource(userListqueue));
//report生成lambdaへアクセスが必要なDynamoの読み取り権限、SES実行権限追加
rating_table.grantReadData(createReportEmail);
post_table.grantReadData(createReportEmail);
timeline_table.grantReadData(createReportEmail);
createReportEmail.addToRolePolicy(new iam.PolicyStatement({
actions: [
"ses:*"
],
resources: ["*"],
}))
//Neptuneのデータ更新部分
//参考元 https://github.com/aws-samples/aws-cdk-examples/tree/master/typescript/neptune-with-vpc
//Neptune用VPC作成
const neptuneVpc = new ec2.Vpc(this, "NeptuneVpc", {
cidr: "172.32.0.0/16",
maxAzs: 2,
natGateways: 1,
enableDnsHostnames: true,
enableDnsSupport: true,
subnetConfiguration: [{
cidrMask: 24,
name: 'db',
subnetType: ec2.SubnetType.PRIVATE_WITH_NAT,
}, {
cidrMask: 24,
name: 'dmz',
subnetType: ec2.SubnetType.PUBLIC,
}],
});
//作成したプライベートサブネットの情報取得
var neptunePrivateSubnets = neptuneVpc.privateSubnets;
//Neptune用サブネットグループ作成
const neptuneSubnets: ec2.SubnetSelection = { subnets: neptunePrivateSubnets };
//Neptuneクラスター作成
const clusterParams = new neptune.ClusterParameterGroup(this, 'ClusterParams', {
description: 'Cluster parameter group',
parameters: {
neptune_enable_audit_log: '1'
},
});
const dbParams = new neptune.ParameterGroup(this, 'DbParams', {
description: 'Db parameter group',
parameters: {
neptune_query_timeout: '120000'
},
});
const neptuneSG = new ec2.SecurityGroup(this,'neptuneSG',{
vpc: neptuneVpc,
allowAllOutbound: true,
})
neptuneSG.addIngressRule(neptuneSG,ec2.Port.allTraffic());
const neptuneCluster = new neptune.DatabaseCluster(this, "NeptuneCluster", {
dbClusterName: "MyGraphDB",
vpc: neptuneVpc,
vpcSubnets: neptuneSubnets,
securityGroups: [neptuneSG],
instanceType: neptune.InstanceType.T3_MEDIUM,
clusterParameterGroup: clusterParams,
parameterGroup: dbParams,
deletionProtection: false,
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
//Neptune 書き込みアドレスの出力
const neptuneClusterWriteAddress = neptuneCluster.clusterEndpoint.socketAddress;
//フォロー管理グラフDB更新lambda
//Amplifyで作成したフォロー管理DynamoDBの情報取得
const followrelationship_table = dynamodb.Table.fromTableAttributes(
this, 'followrelationship_table', {
tableArn: '※フォロー管理DBのARN',
tableStreamArn: 'フォロー管理DBのストリームARN'
}
);
//フォロー管理グラフDB更新lambda用のlambdaレイヤー作成(gremlin,async)
const gremlinLayer = new LayerVersion(this, 'gremlinLayer',
{
code: AssetCode.fromAsset('lambdalayer/gremlin_async'),
compatibleRuntimes:[Runtime.NODEJS_12_X,Runtime.NODEJS_14_X]
})
//フォロー管理グラフDB更新lambda
const updatefollowrelationship = new lambda.Function(this, 'updatefollowrelationship', {
runtime: lambda.Runtime.NODEJS_12_X,
code: lambda.Code.fromAsset('lambda'),
handler: 'updatefollowrelationship.handler',
environment:{
NEPTUNE_ENDPOINT: neptuneClusterWriteAddress,
NEPTUNE_PORT: '8182',
},
vpc:neptuneVpc,
securityGroups: [neptuneSG],
layers: [gremlinLayer]
});
//フォロー管理グラフDB更新lambdaにフォロー管理dynamodbストリーム追加
updatefollowrelationship.addEventSource(
new DynamoEventSource(followrelationship_table,{
startingPosition: lambda.StartingPosition.LATEST
})
)
}
}10. まとめ
本記事では、キャリア採用 アソシエイトソリューションアーキテクトの研修プログラムのうちの 1 つ、疑似プロジェクトについて紹介しました。
作成したデモアプリに、オブザーバビリティ や セキュリティ に関する機能追加をして、今後も AWS サービスについて手を動かしながら学んでいこうと思います。
ソリューションアーキテクトにご興味をもっていただけた方は、ぜひこちら (ソリューションアーキテクト キャリア採用) のページも参照ください。大阪や福岡でもソリューションアーキテクトを募集していますので、ぜひご応募おまちしています。
筆者 / 監修者プロフィール

佐山 朝葉
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 西日本ソリューション部 ソリューションアーキテクト
国内外での実証実験の推進や人事を経験後、AWS って面白そう & 地元である関西で子育てしたいな、と思い 2022 年入社。西日本のお客様を支援していきます。

ポール (@bulbulpaul)
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 西日本ソリューション部 ソリューションアーキテクト
研究開発やカレンダーサービス開発のエンジニアを経て 2020 年にアマゾン ウェブ サービス ジャパンへ入社。ポールという出落ち感の強いニックネームを持つただの関西人。
Kotlin, Python, サーバーレス, 釣りとお酒が好きです。

清水 崇之 (@shimy_net)
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 西日本ソリューション部 ソリューションアーキテクト / 部長
最先端技術を追いながら世界を爆笑の渦に巻き込みたい、そんな AWS 芸人になりたいと思って AWS に入社して早 7 年。サウンドプロデューサー としても活動中。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages