- AWS Builder Center›
- builders.flash
ストリーミングデータを簡単にキャプチャ、処理、保存 ! Amazon Kinesis Data Streams をグラレコで解説
2023-11-01 | Author : 米倉 裕基 (監修 : 山﨑 翔太)
はじめに
builders.flash 読者のみなさん、こんにちは ! テクニカルライターの米倉裕基と申します。
本記事では、リアルタイムで大規模なストリーミングデータをキャプチャ、処理、保存できる AWS のサーバーレスストリーミングデータサービス、Amazon Kinesis Data Streams について紹介します。
※ 本連載では、様々な AWS サービスをグラフィックレコーディングで紹介する awsgeek.com を、日本語に翻訳し、図の解説をしていきます。awsgeek.com は 、Jerry Hargrove 氏が運営しているサイトです。
builders.flash メールメンバー登録
Amazon Kinesis Data Streams について
現代のビジネスとテクノロジーの環境では、ウェブサイトの活動、オンライン取引、センサーデータ、ユーザー行動など、さまざまなソースからリアルタイムでデータが大量に生成されています。こうした日々生み出される膨大なデータをうまく分析し活用することで、市場動向を把握したり、顧客行動からインサイトを得たり、システムの健全性を監視するなど、ビジネスにおける競争力を高めることができます。Amazon Kinesis Data Streams は、多様なデータソースからリアルタイムで発生するデータを効率的に収集、処理、保存するために設計されたストリーミングデータサービスです。
本記事では、Amazon Kinesis Data Streams の主な機能と特徴を以下の項目に分けてご説明します。
-
Amazon Kinesis Data Streams の概要
-
主要なコンポーネント
-
シャードの機能と役割
-
データレコードとパーティションキー
-
データフローとリアルタイム処理
-
データの暗号化とセキュリティ
-
料金体系と最適化のポイント
それでは、項目ごとに詳しく見ていきましょう。
Amazon Kinesis Data Streams の概要
Amazon Kinesis Data Streams (以下 KDS) は、AWS が提供するリアルタイムのストリーミングデータサービスです。
KDS は多岐にわたるデータを処理できます。例として、アプリケーションログ、ソーシャルメディアフィード、ウェブサイトのクリックストリーム、金融市場データ、センサーデータなどを挙げることができます。
KDS はデータストリームの作成、そのストリームへのデータの送信、そしてリアルタイムでデータを処理するコンシュマーアプリケーションの作成をサポートします。また、KDS はフルマネージド型のサーバーレスサービスで、インフラストラクチャとストリームの管理、データの暗号化など、多くの管理タスクを請け負います。
KDS の主な特徴
リアルタイムデータ処理:
多様なデータソース:
耐久性と信頼性:
また、KDS は低レイテンシーや、高スループット、キャパシティモード、セキュリティなどの面で、多くの特徴を備えています。その他 KDS の特徴について詳しくは、「Amazon Kinesis Data Streams features」をご覧ください。
主要なコンポーネント
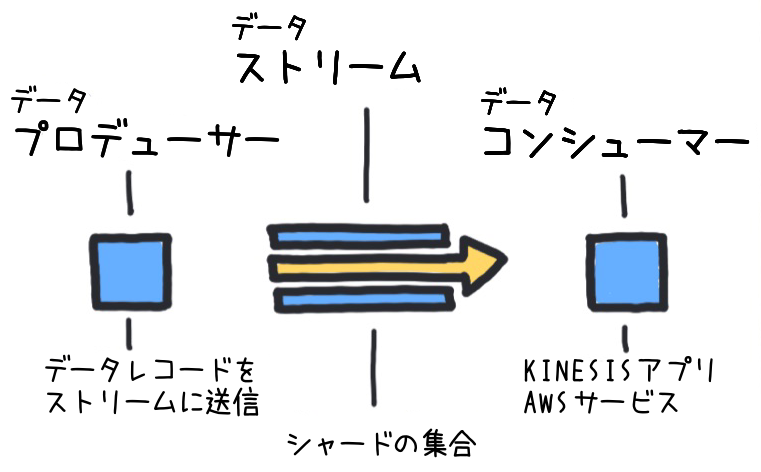
KDS の基本構造は、「データプロデューサー」、「データストリーム」、および「データコンシューマー」の 3 つの主要なコンポーネントから成り立っています。これらのコンポーネントは緊密に連携し、効率的なストリーミングデータ処理システムを構築します。
|
コンポーネント |
役割 |
|
データプロデューサー |
データプロデューサーは、データストリームにデータレコードを送信するアプリケーションを指します。例えば、ウェブサイトの訪問者行動やセンサーデータなどが含まれます。 |
|
データストリーム |
データストリームは、データの流れを持つ「パイプ」のような存在で、内部に複数の「シャード」を持ち、各シャードがデータを保管します。例えば、ログデータやトランザクションデータなどがこのストリームを通じて流れます。 |
|
データコンシューマー |
データコンシューマーは、KDS からデータを読み取り、何らかの処理を行うアプリケーションです。データ処理や保存のために、さまざまな AWS サービスへのデータルーティングが行えます。 |
コンポーネントの連携
データプロデューサー、データストリーム、およびデータコンシューマーの 3 つのコンポーネントが連携し、KDS はこれらを通じて大量のデータを効率的に処理し分析するストリーミングデータ処理システムを構築します。
データプロデューサーは生成したデータをデータストリームに送信し、それを適切なシャードに振り分けます。データコンシューマーはこれらのデータをリアルタイムに処理し分析します。
KDS の主要なコンポーネントについて詳しくは、「Amazon Kinesis Data Streams の用語と概念」をご覧ください。
データの保存
KDS では「追加のみ」許可される形でデータがシャードに保存され、各データレコードは時間順にシーケンスされます。このため、データの一貫性が高まり、一度保存されたデータが後から改竄されるリスクが低くなります。
データは、実際のデータと少量のメタデータが一まとめにされた「データブロブ」という単位で保存されます。メタデータには、シーケンス番号とパーティションキーが含まれています。
シャードの容量
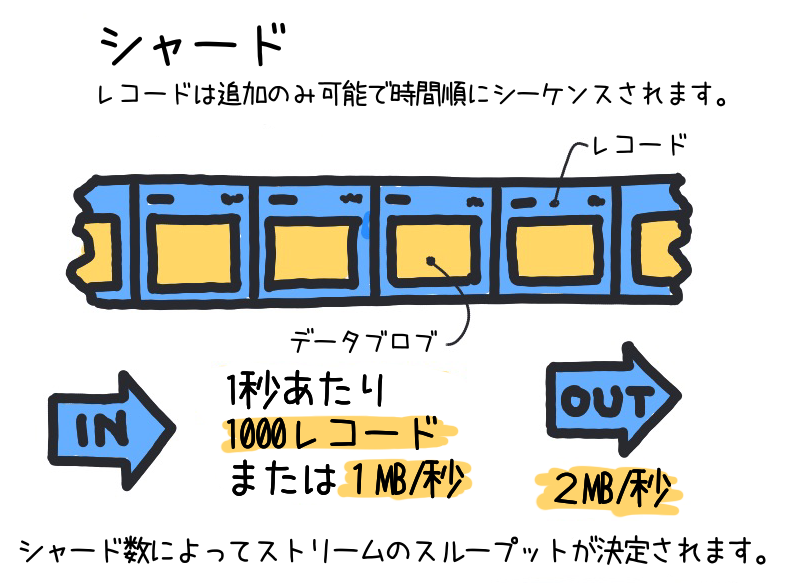
KDS では、各シャードに特定のスループット容量が割り当てられます。通常、1 つのシャードは、1 秒あたり 1MB のデータを書き込み、また 1 秒あたり 2MB のデータを読み取ることができます。また、各シャードは 1 秒あたり最大 1,000 のレコードを書き込むことができます。
シャードの数が多ければ多いほど、KDS ストリーム全体のスループットも比例して増加します。具体的には、1 つのシャードが 1 秒あたり 1MB のデータを書き込む能力がある場合、10 個のシャードを持つストリームは、1 秒あたり最大 10MB のデータを書き込むことができます。このように、シャードの数がストリームのスループットを決定する重要な要素であり、適切なシャード数の設定はパフォーマンスに大きく影響します。
また、KDS ではデータストリームの容量モードとして「プロビジョニングモード」と「オンデマンドモード」の 2 つを提供しています。プロビジョニングモードでは、ユーザーがシャード数を事前に設定する必要がありますが、オンデマンドモードでは、データの処理量に基づいてシャード数が自動的に調整され、容量の計画や手動でのインフラストラクチャ調整が不要になります。予測不能なワークロードが予想される場合、オンデマンドモードが適しています。
シャードについて詳しくは、デベロッパーガイドの「シャード」セクションをご覧ください。
データレコードとパーティションキー
KDS でデータを送信する際の基本単位が「データレコード」です。データレコードは、「シーケンス番号」と「パーティションキー」という情報を持っており、これらの属性によってストリーミングデータの効率的な処理とデータの順序保証が可能になります。
シーケンス番号
各データレコードには一意の識別子である「シーケンス番号」が付与されます。シーケンス番号はデータレコードがシャード内でどの位置にあるかを示し、データレコードが追加されるたびにインクリメントされます。
コンシューマーは、このシーケンス番号を利用して特定のデータレコードにアクセスすることができます。同じシャードの中ではデータの順序が保証されているため、コンシューマーは必要なデータを効率的に取得できます。
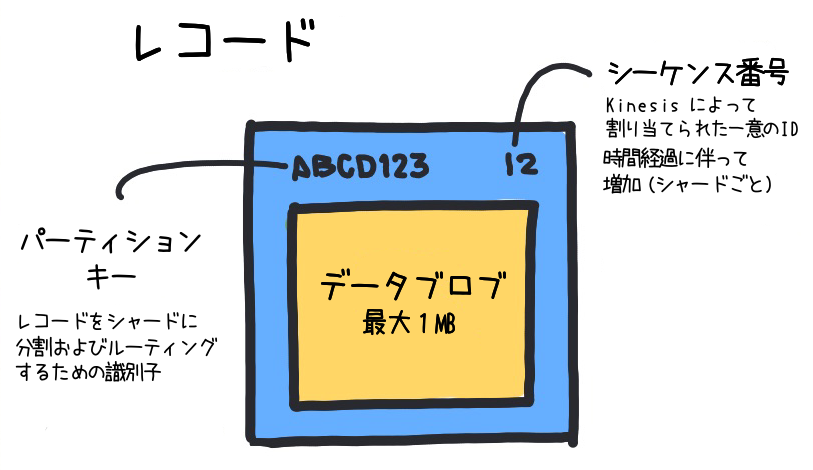
パーティションキー
パーティションキーは、データがどのシャードにルーティングされるかを決定するためにユーザーによって設定される値です。KDS はパーティションキーを基に、データレコードを適切なシャードに効率よくルーティングし、各シャードに均等なデータ量が保たれるようにします。これにより、スループット (データの処理速度) が最適化されます。
パーティションキーの選定は重要で、ストリーム全体のスループットに直接影響を与えます。例えば、ある特定のパーティションキーが過度に使用されると、そのシャードにデータが集中してしまい、他のシャードが十分に活用されない可能性があります。このため、パーティションキーを選定する際には、データの均等な分布と高いスループットを実現することが重要です。
データレコードについて詳しくは、デベロッパーガイドの「データレコード」セクションをご覧ください。
データフローとリアルタイム処理
これまでに、KDS の主要なコンポーネント、シャード、そしてデータレコードとパーティションキーについて説明しました。ここでは、それらの要素がどのように組み合わさって、KDS が高度なリアルタイムデータ処理を可能にするのかを説明します。データプロデューサーからデータストリームへのデータの流れと、その後どのようにデータコンシューマーがデータを利用するのか、全体のフローを見ていきます。
KDS へのデータ書き込み
データを KDS に送信するには、標準の API やライブラリを使うなどいくつかの方法があります。
-
KDS API によるデータ送信:
KDS API は、単一または複数のデータレコードを送信する PutRecord と PutRecords メソッドを提供しています。これらのメソッドを使うことで、アプリケーションから直接、簡単かつ効率的にデータを KDS に送信することが可能です。 -
高度なデータ送信:
もっと高度なデータ送信や効率的なバッチ処理が必要な場合には、Amazon Kinesis Producer Library (KPL) を利用できます。KPL は AWS が提供するライブラリで、データの効率的な送信やエラーハンドリングを容易にします。さらに、Amazon Kinesis Agent を利用することで、Linux や RHEL などからログやファイルを送信することも可能です。また、テストデータを KDS に送信するには Amazon Kinesis Data Generator (KDG) が利用できます。その他にも、Fluentd のプラグイン Fluent plugin for Amazon Kinesis を含め、様々なオープンソースソフトウェアや SaaS サービスで KDS のプロデューサー機能が提供されています。これらを利用してデータを連携することもできます。
KDS へのデータの書き込みについて詳しくは、「Amazon Kinesis Data Streams へのデータの書き込み」をご覧ください。
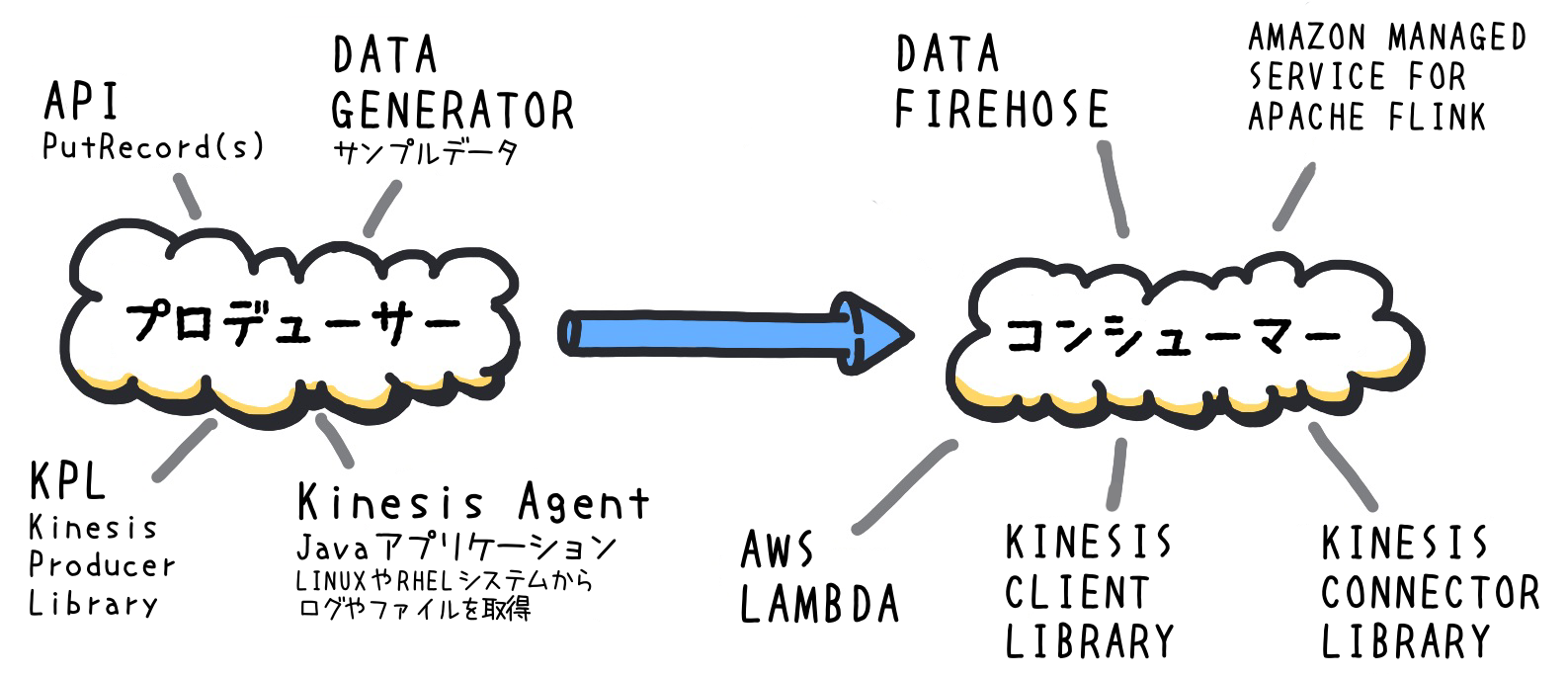
KDS からのデータ読み取り
データストリームからデータを読み取る側、すなわちデータコンシューマーには多くの選択肢があります。Kinesis 系統のサービスや他の AWS サービスを始め、Apache Spark、MongoDB、 Splunk など多くのサードパーティー製サービスとも連携でき、豊富な連携オプションの中から用途に合うデータコンシューマーを自由に選択できます。
-
既存のサービスを利用:
リアルタイム分析には Amazon Managed Service for Apache Flink が、特定のイベント処理には AWS Lambda が有用です。また、データを永続的に保存する場合、Amazon Kinesis Data Firehose を経由して Amazon S3 や Amazon Redshift、Amazon OpenSearch Service などに簡単に保存できます。さらに、AWS re:Invent 2022 で発表された Redshift の新機能、Streaming Ingestion を利用することで、Redshift にネイティブに連携し、KDS からのデータストリームをリアルタイムで読み取って処理することが可能になります。 -
独自のアプリケーションを利用:
既存のサービスに合わない独自の処理が必要な場合、Amazon Kinesis Client Library や Amazon Kinesis Connector Library を使用してカスタムアプリケーションを開発することもできます。たとえば、特定のフィルタリングやデータ変換が必要な場合、これらのライブラリを使って実装することができます。
KDS からのデータの読み取りについて詳しくは、「Amazon Kinesis Data Streams からのデータの読み取り」をご覧ください。
KDS では、多様な手段でデータ送信とデータ受信が可能です。KDS 以外の Kinesis アプリや、他の AWS サービスを連携することで、柔軟にストリーミングデータを効率よく処理する強力なデータパイプラインを構成できます。この一連のデータフローが、KDS の多様な用途に応用できる柔軟性と拡張性を提供しています。
KDS を使った一連のデータフローについて詳しくは、「ストリームの作成と管理」をご覧ください。
データの暗号化とセキュリティ
ビジネスやアプリケーションが重要なデータを処理する際には、データの暗号化とセキュリティは何よりも重要です。KDS は、これらの要求に対応するために、多くのセキュリティ機能を提供しています。ここでは、KDS が提供する主要なセキュリティ要素を説明します。
データの暗号化
KDS は、データの暗号化をサポートしており、データは送信、保管、および受信の各段階でセキュアに保たれます。
-
サーバー側の暗号化:
KDS は、データがストリームに書き込まれたり取り出されたりする際に、自動的にデータを暗号化・復号化することが可能で、これによりデータの保管と転送の安全性を確保します。 -
クライアント側の暗号化:
KDS はクライアント側の暗号化を直接サポートしていませんが、VPC 内のアプリケーションでデータの暗号化および復号化の処理を実装することは、セキュリティを強化する有効な手段です。
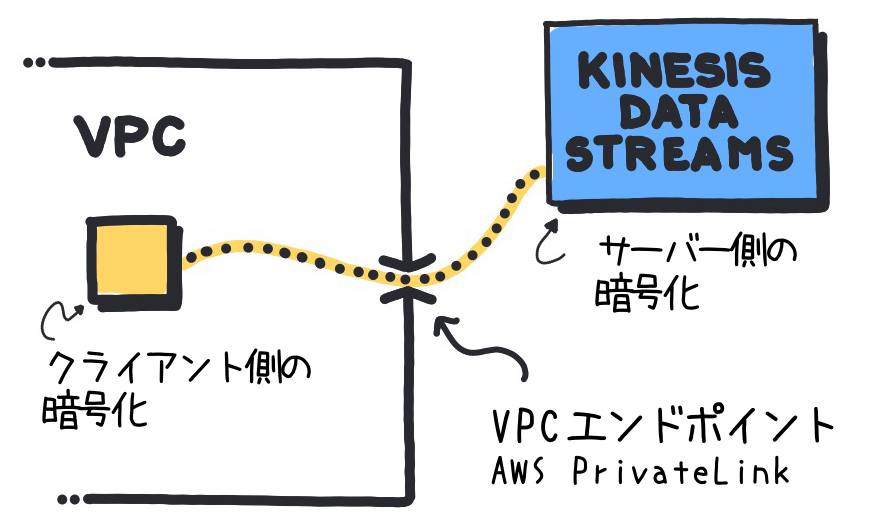
VPC 経由での通信
Amazon Virtual Private Cloud (VPC) 内での KDS の利用は、VPC エンドポイントと AWS PrivateLink を活用することにより、パブリックインターネットを経由せずに KDS にアクセスし、データの送受信がセキュアなネットワーク環境で行われることを可能にします。VPC エンドポイントを使用することで、KDS との通信が AWS のネットワーク内で保たれ、インターネットへの露出を避けることができます。
アクセス制御
AWS Identity and Access Management (IAM) を使用すると、AWS アカウント内でユーザーやグループを作成し、各ユーザーにユニークなセキュリティ資格情報を割り当てることができます。IAM ポリシーでは、許可されるアクションとそれらのアクションが適用されるリソースを明示的にリスト化することができ、KDS のプロデューサーとコンシューマーに通常必要とされる最小の権限を明示することができます。
これらのセキュリティとアクセス制御の対策を通じて、KDS はデータ処理プロセス全体で高いセキュリティを実現し、信頼性の高いリアルタイムストリーミングデータサービスを提供します。KDS のセキュリティについて詳しくは、「Amazon Kinesis Data Streams のセキュリティ」をご覧ください。
料金体系と最適化のポイント
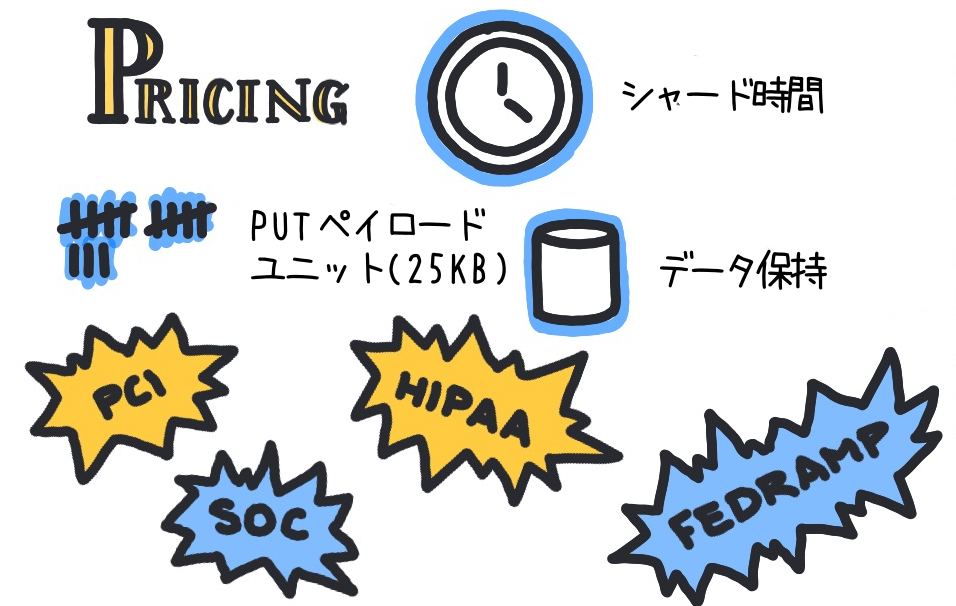
KDS の料金は主にシャード時間、PUT ペイロードユニット、およびデータ保持期間に基づいて計算されます。ここでは、KDS の料金体系と最適化のポイントについて簡単に説明します。
基本料金とデータ保持期間
KDS の料金は、主にシャード時間、PUT ペイロードユニット (25 KB)、およびデータ保持期間に基づいて計算されます。
-
シャード時間:
シャード時間は、1 シャードを 1 時間利用することを意味しています。1 シャードは、1 秒に 1MB のデータを読み取る、または 1,000 レコードを書き込む能力を持ちます。シャード時間の利用量に基づき、料金が請求されます。 -
PUT ペイロードユニット (25 KB):
データをストリームに書き込む操作を指します。25 KB ごとのデータ書き込みに対して料金が発生し、書き込むデータの量に応じて料金が計算されます。 -
データ保持期間:
データ保持期間は、データを KDS 内で保持する時間を指します。保持期間が長いほど、それに応じた料金が発生します。デフォルトでは 24 時間のデータ保持が提供され、拡張データ保持で最長 7 日間、長期データ保持で最長 365 日間のデータ保持が可能です。保持期間を延長することで、データのアクセスと再利用が可能になりますが、コストが高くなるため、適切なバランスを見つけることが重要です。
最適化のポイント
コストとパフォーマンスのバランスを最適化するためには、シャードの数とデータの保持期間を適切に設定することが重要です。Amazon CloudWatch を利用することで、リアルタイムでシャードとデータ使用量の監視が可能となり、必要に応じて効率的にコストを最適化することができます。
また、2021 年 11 月に AWS はオンデマンドキャパシティモードを KDS に導入しました。これにより、手動でデータストリームのキャパシティを簡単に更新できるようになり、書き込みと読み取りスループットを毎分提供できるようになりました。オンデマンドキャパシティモードは、突発的なトラフィックの増加や予期せぬ使用量の変動に素早く対応することができ、コストとパフォーマンスの最適化に貢献します。
コンプライアンス
KDS では、データの暗号化、アクセス制御、および監査証跡などの機能を実装することが容易であり、これにより、FedRAMP、HIPAA、PCI、および SOC といった主要なコンプライアンス要件を満たすことができます。これらのコンプライアンス要件を満たすことで、ビジネスは法律と規制の要件を満たし、顧客データの安全を保護し、信頼と満足度を向上させることができます。さらに、これらの機能を効率的に実装および管理することで、コンプライアンスに関連するコストを削減することも期待できます。
KDS の利用料金について詳しくは、「Amazon Kinesis Data Streams の料金」をご覧ください。
まとめ
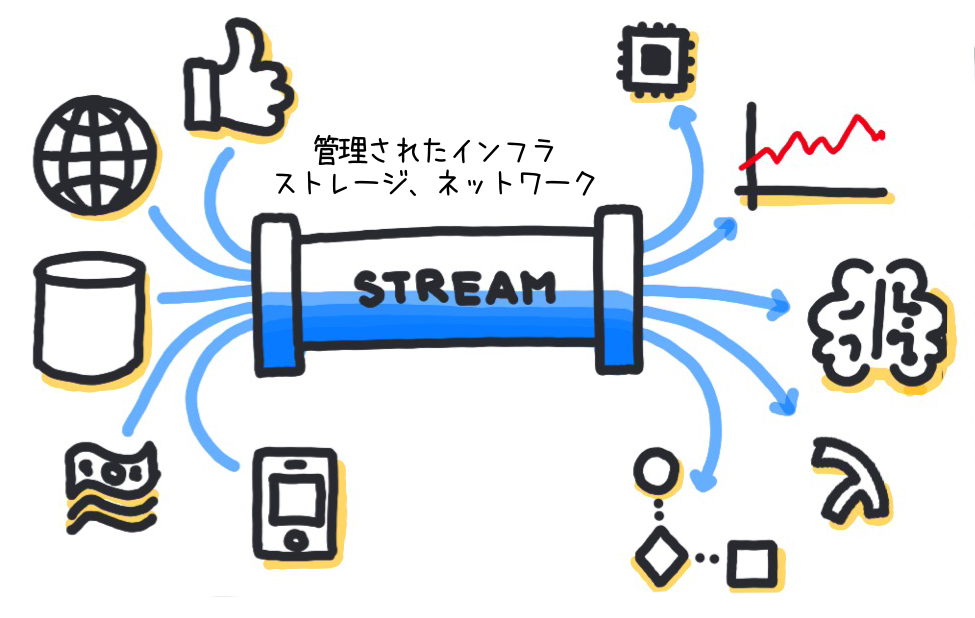
最後に、本記事で紹介した機能の全体図を見てみましょう。
本記事では、ストリーミングデータサービス KDS の機能や概念について紹介しました。KDS は、データのリアルタイム処理が必要な幅広い業界とアプリケーションで利用されています。例えば、金融サービス業界での取引データのモニタリング、製造業でのセンサーデータのリアルタイム分析、広告業界でのクリックストリーム分析など、多岐にわたる用途で活用されており、KDS の柔軟性と強力なリアルタイムデータ処理能力が活かされています。
本記事を読んで KDS に興味を持たれた方、実際に使ってみたいと思われた方は、ぜひ製品ページの「Amazon Kinesis Data Streams」や、AWS Black Belt の「Amazon Kinesis Video Streams 基礎編」など入門者向けのコンテンツも合わせてご覧ください。
全体図
筆者・監修者プロフィール

筆者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。
趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。
現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 インターネットメディアソリューショングループ
部長 / シニアソリューションアーキテクト
大規模インターネット企業グループを担当するソリューションアーキテクトチームをリードしています。
アーキテクチャの話をするのが好きです。分散処理やビッグデータ分析が専門領域です。
映画を観るのが好きで、娘と一緒に映画館に行くのが今の小さな夢です。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages