Amazon Web Services 한국 블로그
신규 오토 스케일링 반응형 정책 업데이트
이 글에서 지금까지 AWS에서 오토스케일링을 사용하는 방법을 한번 집중 해부해보고, 이에 대해 그 이면에서 어떤 일들이 일어나는지 사항을 먼저 이야기 해보면 좋을 것 같습니다.
리소스 실행 및 종료 – 오토 스케일링을 위해서는 EC2 인스턴스를 필요한 만큼 실행하거나 없애야 하는데, AWS API를 활용하여 RunInstances 및 TerminateInstances 그리고 부가적으로 DescribeInstances를 사용 합니다.:
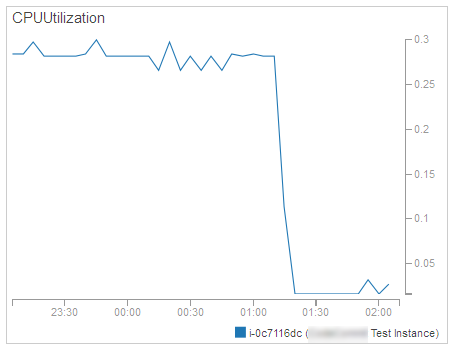
리소스 모니터링 – CPU 사용량, 네트웍 트래픽 등 다른 요소에 의해서 인스턴스가 개별적 혹은 그룹으로 얼마나 많은 리소스를 사용하느냐는 스케일링을 선택하는 주요 기준이고 Amazon CloudWatch를 활용해 왔습니다:
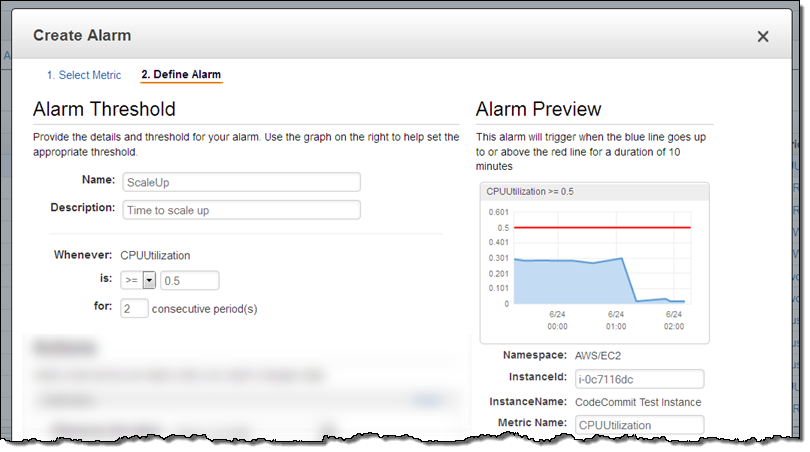
알림 보내기 – 자원의 사용량을 추적하여 스케일-인/아웃 시에 CloudWatch를 통해 알림을 보낼 수 있습니다.:
스케일링 실행 – 마지막으로 알람이 오면 실행을 하는데 이는 오토스케일링이 시작이 되는 것입니다.
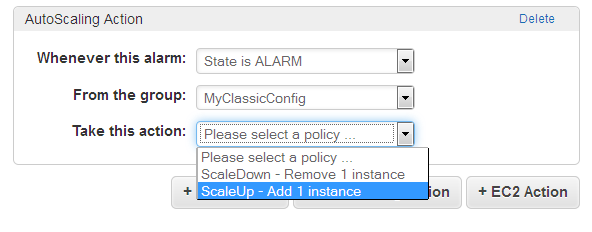 이 동작은 특정 오토스케일링 그룹 내에서 실행 되며, 이에 따라 특정 인스턴스를 시작 및 종료를 하게 되며 특정 퍼센테이지 혹은 숫자를 통해 인스턴스 숫자를 조정합니다.
이 동작은 특정 오토스케일링 그룹 내에서 실행 되며, 이에 따라 특정 인스턴스를 시작 및 종료를 하게 되며 특정 퍼센테이지 혹은 숫자를 통해 인스턴스 숫자를 조정합니다.
신규 스케일링 단계별 정책
오늘 부터 이전 보다 더 유연한 새로운 오토 스케일링 정책을 수행하는 단계를 소개해 드립니다.
그 목적은 트래픽이나 로드가 갑자기 증가할 때 대응하는 오토 스케일링 시스템을 만드는데 있습니다. 이제 magnitude라는 알람을 기반으로 원하는 스케일링 정책을 정할 수 있습니다. 예를 들어 평균 CPU 사용량을 50%로 잡고 있는데, 조금씩 CPU가 늘어나는 구간 즉, 50-60% 혹은 60-70%, 80% 이상 등 다양한 구간에서 인스턴스를 추가할 수 있습니다.
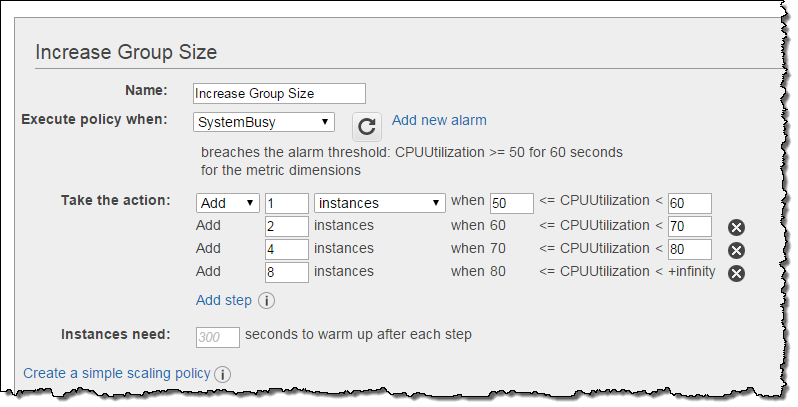
위에서 보시다시피 고정된 숫자의 인스턴스가(1, 2, 4 또는 8) 그룹에 있습니다. 사용 퍼센티지 기반으로 인스턴스 숫자를 정하고 단계별로 50%, 100%, 150% 및 200%로 증가시킬 수 있습니다. 이러한 비율은 스케일을 줄일때도 정책을 활용할 수 있습니다.
이러한 단계별 정책을 통해 알람을 통해 평가하여, 스케일링이 일어나는 도중에 인스턴스 헬스체크를 해서 문제가 있는 것은 새 것으로 교체합니다. 이를 통해 더 빠른 요구에 응답할 수 있습니다. CPU 로드가 계속 올라갔다면, 정책 중 첫 번째 단계가 시작되어 첫 워밍업(약 120초 정도) 기간 동안 더 빠르게 반응할 수 있습니다. 시스템 로드가 계속 증가하더라도 유연하게 대처할 수 있습니다. 여러분이 같은 리소스에 대해 다중 단계의 (CPU 사용량 및 네트워크 트래픽을 기반으로) 스케일링 정책을 만들 수 있다면, 갑작스런 트래픽에도 유연하게 대처할 수 있을 것입니다.
새로운 오토스케일링 정책은 AWS Command Line Interface (CLI)이나 Auto Scaling API를 사용하시면 됩니다.
새로운 기능은 오늘 부터 바로 사용 가능합니다.
— Jeff;
이 글은 Auto Scaling Update – New Scaling Policies for More Responsive Scaling의 요약 편집입니다.