Amazon Web Services 한국 블로그
AWS Clean Rooms ML – 데이터 공유 없이 기계학습 모델 적용 가능 (미리 보기)
오늘은 AWS Clean Rooms ML 미리 보기 기능을 소개합니다. 이 기능을 사용하면 사용자와 사용자의 파트너가 원시 데이터를 서로 복사 또는 공유하지 않고도 집단 데이터에 기계 학습(ML) 모델을 적용할 수 있습니다. 이 새로운 기능을 통해 ML 모델을 사용하여 예측 인사이트를 생성하는 동시에 민감한 데이터를 지속적으로 보호할 수 있습니다.
이 평가판에서 AWS Clean Rooms ML은 기업이 마케팅 사용 사례에 사용할 유사 세그먼트를 생성할 수 있도록 지원하는 데 특화된 첫 번째 모델을 소개합니다. AWS Clean Rooms ML 유사 기능을 사용하면 자체 사용자 지정 모델을 학습시킬 수 있고, 파트너를 초대하여 소규모 레코드 샘플을 가져와 협업하며, 모든 사람의 기본 데이터를 보호하면서 유사 레코드 세트를 확장하여 생성할 수 있습니다.
앞으로 몇 달 안에 AWS Clean Rooms ML은 의료 모델을 출시할 예정입니다. AWS Clean Rooms ML이 내년에 지원할 여러 모델 중 첫 번째 모델이 될 것입니다.

AWS Clean Rooms ML을 사용하면 인사이트를 얻을 수 있는 다양한 기회를 열 수 있습니다. 예를 들면 다음과 같습니다.
- 항공사는 단골 고객에 대한 신호를 받고, 온라인 예약 서비스와 협력하며, 비슷한 특성을 가진 사용자에게 프로모션을 제공할 수 있습니다.
- 자동차 대출 기업 및 자동차 보험사는 기존 리스 소유주와 특성을 공유하는 잠재 자동차 보험 고객을 식별할 수 있습니다.
- 브랜드와 게시자는 시장 내 고객들의 유사 세그먼트를 모델링하여 관련성이 높은 광고 경험을 제공할 수 있습니다.
- 연구 기관 및 병원 네트워크는 기존 임상 시험 참가자와 유사한 후보를 찾아 임상 연구를 가속화할 수 있습니다(곧 출시 예정).
AWS Clean Rooms ML 유사 모델링을 사용하면 각 협업에서 학습되고 바로 사용할 수 있는 AWS 관리형 모델을 적용하여 클릭 몇 번으로 유사 데이터 세트를 생성할 수 있으므로, 자체 모델을 구축, 교육, 조정 및 배포하기 위한 개발 작업을 수 개월 단축할 수 있습니다.
AWS Clean Rooms ML을 사용하여 예측 통찰력을 얻는 방법
오늘은 AWS Clean Rooms ML에서 유사 모델링을 사용하는 방법을 선보이며, 사용자가 파트너와 이미 데이터 협업을 설정했다고 가정합니다. 이 방법을 알아보려면 AWS Clean Rooms 정식 출시 – 데이터 공유없이 파트너와 협업 포스팅을 참조하세요.
AWS Clean Rooms 협업에서 수집된 데이터를 사용해서, 사용자는 파트너와 협력해 ML 유사 모델링을 적용하여 유사 세그먼트를 생성할 수 있습니다. 데이터에서 대표적인 레코드 샘플을 소량 추출하여 기계 학습(ML) 모델을 만든 다음, 특정 모델을 적용하여 비즈니스 파트너의 데이터에서 유사한 레코드의 확장된 세트를 식별하는 방식으로 작동합니다.
다음 스크린샷은 AWS Clean Rooms ML을 사용하기 위한 전체 워크플로를 보여줍니다.
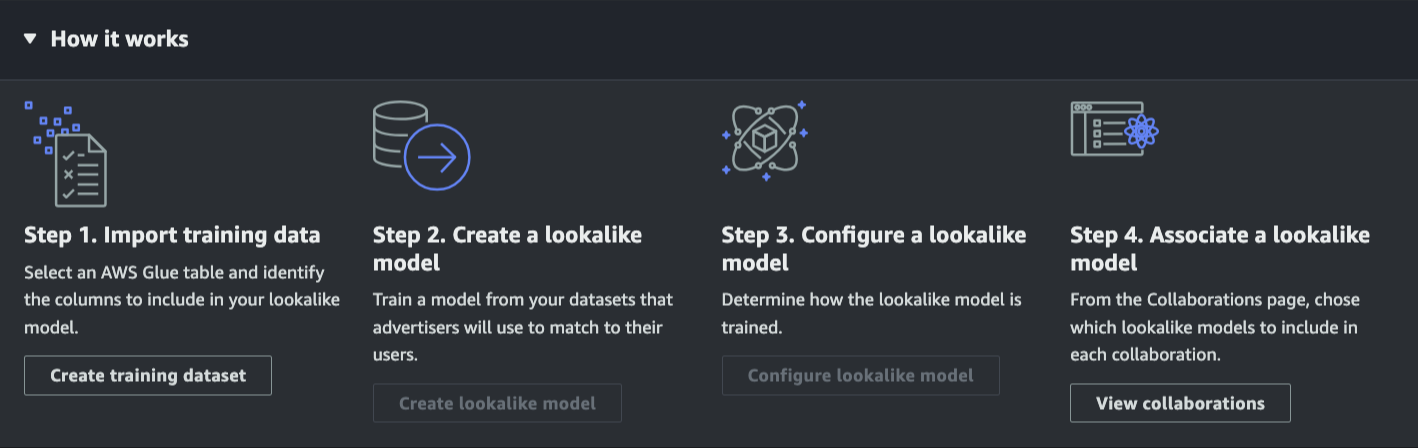
AWS Clean Rooms ML을 사용하면 복잡하고 시간이 많이 소요되는 ML 모델을 직접 구축할 필요가 없습니다. AWS Clean Rooms ML은 사용자 지정 프라이빗 ML 모델을 훈련하므로, 데이터를 보호하면서도 시간을 몇 개월 절약할 수 있습니다.
데이터 공유의 필요성 제거
ML 모델은 기본적으로 서비스 내에 구축되기 때문에, AWS Clean Rooms ML을 사용하면 ML 모델을 구축하기 위해 데이터를 공유할 필요가 없으므로 데이터 세트와 고객 정보를 보호할 수 있습니다.
사용자 항목 상호 작용이 포함된 AWS Glue 데이터 카탈로그 테이블을 사용하여 교육 데이터 세트를 지정할 수 있습니다.
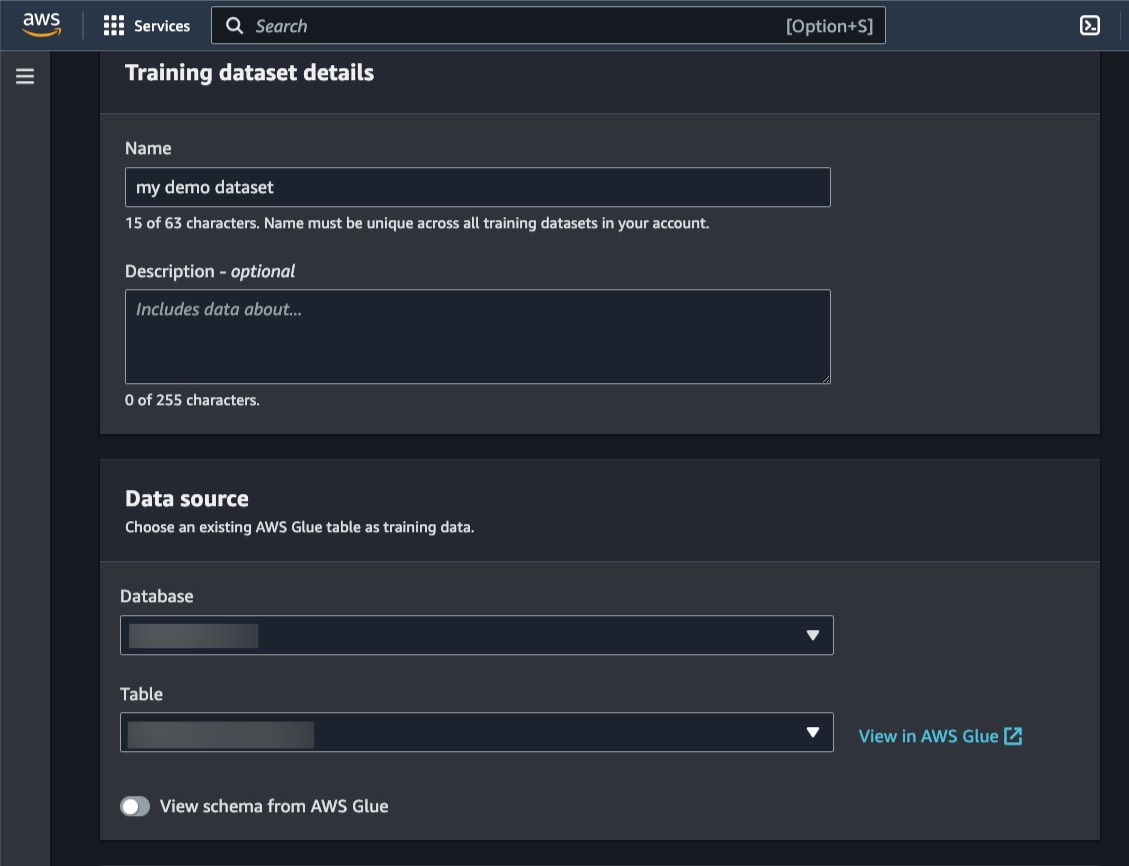
훈련할 추가 열에서 수치 및 범주형 데이터를 정의할 수 있습니다. 이는 동영상 시청 시간(초), 기사 주제 또는 전자 상거래 항목의 제품 카테고리와 같은 데이터 세트에 보다 많은 기능을 추가해야 하는 경우에 유용합니다.

사용자 지정 학습된 AWS 구축 모델 적용
학습 데이터 세트를 정의하면 이제 유사 모델을 생성할 수 있습니다. 유사 모델은 양 당사자가 기본 데이터를 서로 공유할 필요 없이 파트너의 데이터 세트에서 유사한 프로필을 찾는 데 사용되는 기계 학습 모델입니다.
유사 모델을 생성할 때는 훈련 데이터 세트를 지정해야 합니다. 단일 교육 데이터 세트에서 유사 모델을 여러 개 생성할 수 있습니다. 또한 상대 범위 또는 절대 범위를 사용하여 훈련 데이터 세트의 날짜 창을 유연하게 정의할 수 있습니다. 이는 사용자가 읽은 기사와 같이 AWS Glue 내에 지속적으로 업데이트되는 데이터가 있을 때 유용합니다.
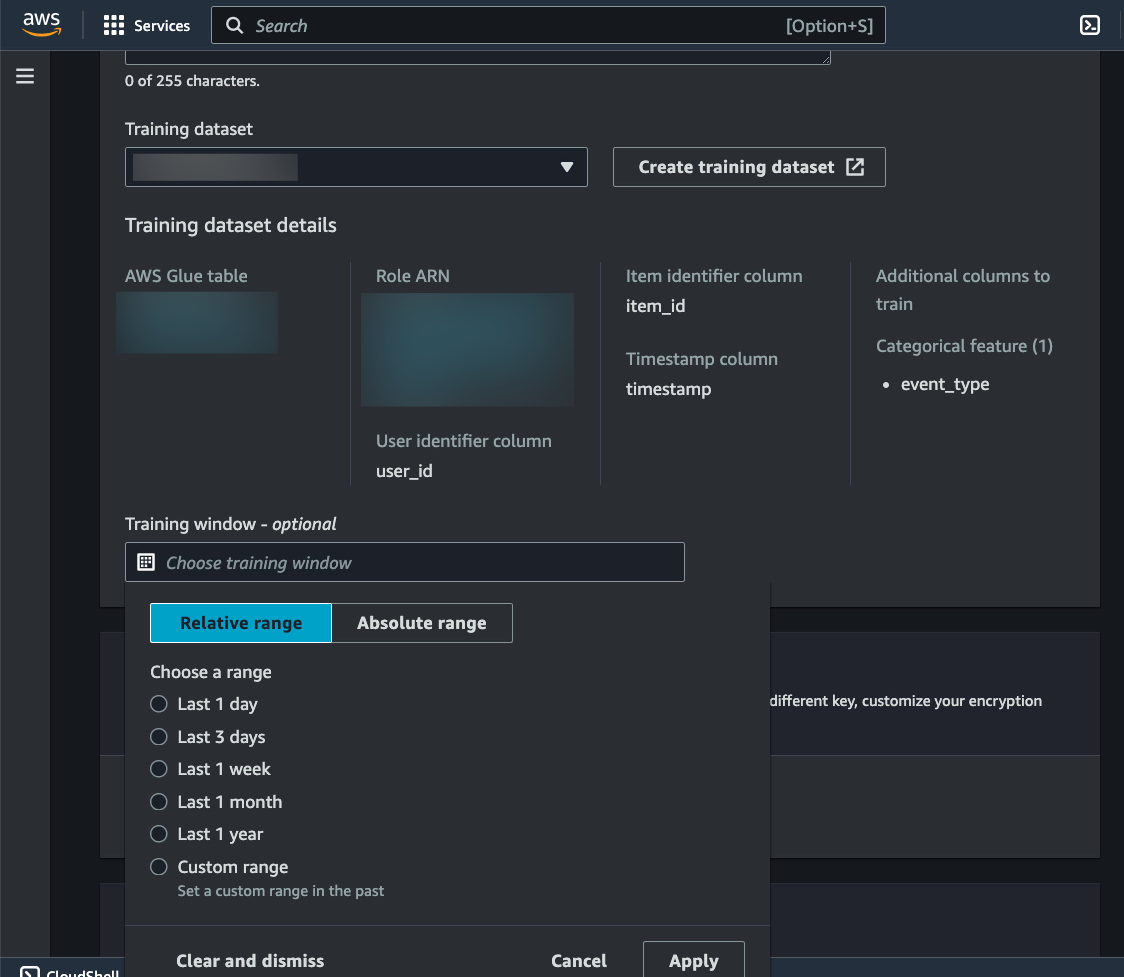
튜닝이 간편한 ML 모델
유사 모델을 생성한 후에는 AWS Clean Rooms 협업에 사용하도록 구성해야 합니다. AWS Clean Rooms ML은 적용된 ML 모델의 결과를 사용자와 파트너가 조정하여 예측적 통찰력을 얻을 수 있는 유연한 제어 기능을 제공합니다.
유사 모델 구성 페이지에서 사용하려는 유사 모델을 선택하고, 필요한 최소 매칭 시드 크기를 정의할 수 있습니다. 이 시드 크기는 훈련 데이터의 프로파일과 겹치는 시드 데이터의 최소 프로파일 수를 정의합니다.
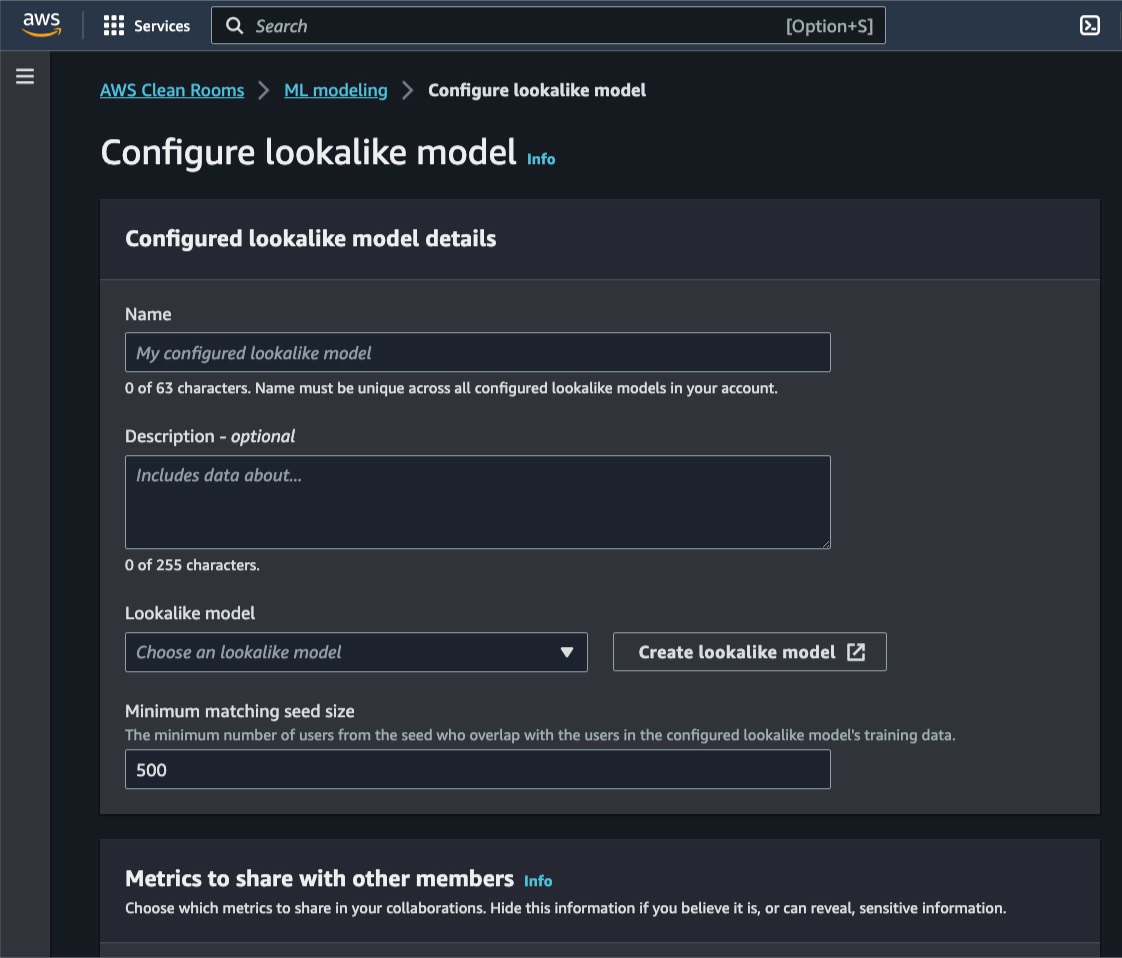
또한 공동 작업의 파트너가 지표 수신을 지표에서 수행해 다른 구성원과 공유할지 여부를 유연하게 선택할 수 있습니다.
유사 모델을 적절하게 구성했으면 이제 구성된 유사 모델을 협업과 연결하여 파트너가 사용할 수 있도록 ML 모델을 제공할 수 있습니다.

유사 세그먼트 생성
유사 모델이 연결되면 파트너는 이제 유사 세그먼트 생성을 선택하고, 협업에 사용할 관련 유사 모델을 선택하여 인사이트 생성을 시작할 수 있습니다.
유사 세그먼트 생성 페이지에서 파트너는 시드 프로필을 제공해야 합니다. 시드 프로필의 예로는 상위 고객 또는 특정 제품을 구매한 모든 고객이 포함됩니다. 결과 유사 세그먼트에는 시드의 프로파일과 가장 유사한 훈련 데이터의 프로파일이 포함됩니다.

마지막으로 파트너는 ML 모델을 사용해 유사 세그먼트의 결과로 관련성 지표를 얻을 수 있습니다. 이 단계에서 점수를 사용하여 결정을 내릴 수 있습니다.
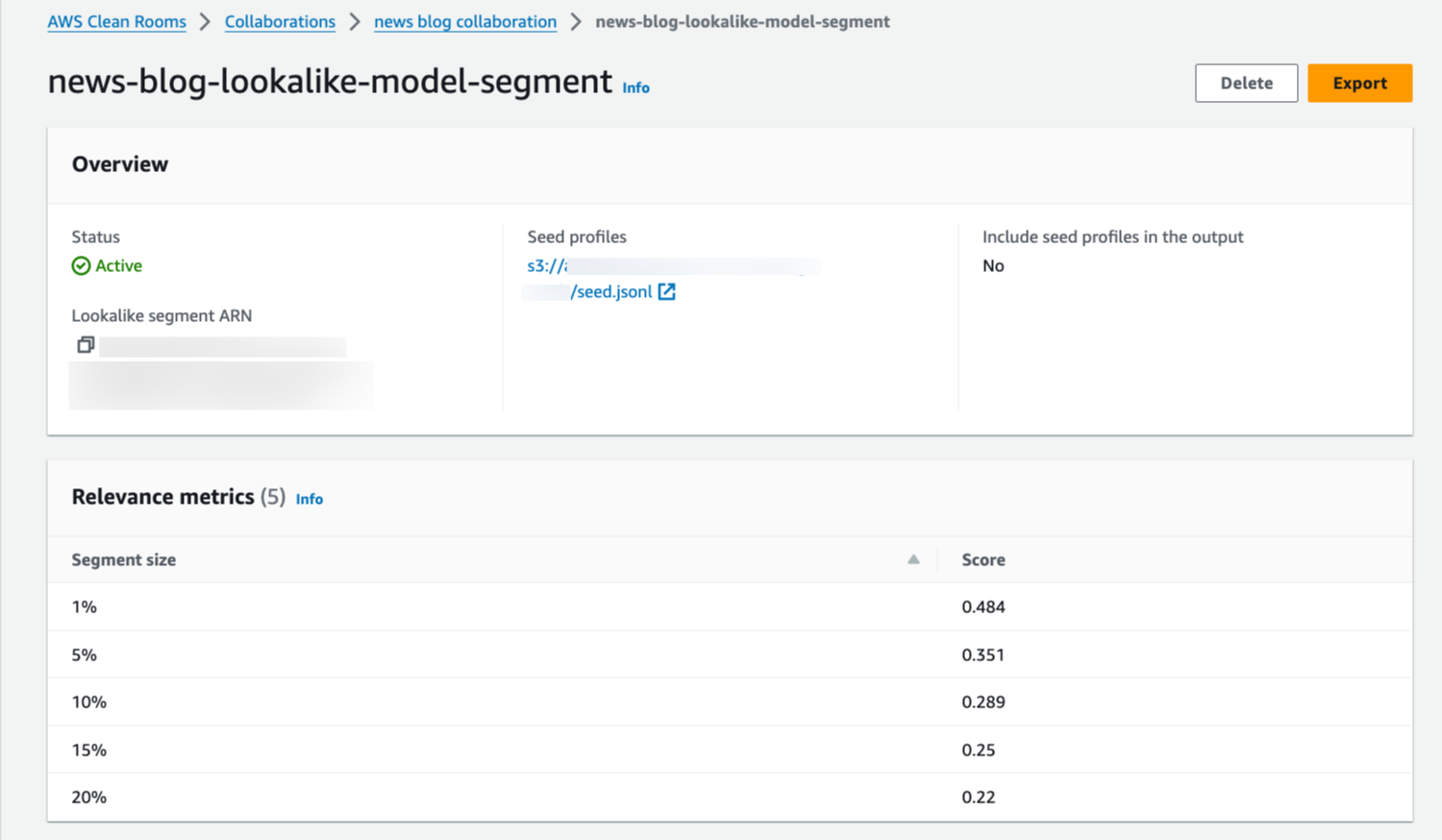
데이터 내보내기 및 프로그래밍 API 사용
유사 세그먼트 데이터를 내보낼 수도 있습니다. 데이터를 내보내고 나면 JSON 형식으로 데이터를 사용할 수 있으며, AWS Clean Rooms API 및 애플리케이션과 통합하여 이 출력을 처리할 수 있습니다.

평가판 참여하기
AWS Clean Rooms ML은 현재 AWS Clean Rooms을 통해 미국 동부(오하이오, 버지니아 북부), 미국 서부(오레곤), 아시아 태평양(서울, 싱가포르, 시드니, 도쿄), 유럽(프랑크푸르트, 아일랜드, 런던) AWS 리전에서 평가판으로 사용할 수 있습니다. 추가 모델에 대한 지원이 진행 중입니다.
AWS Clean Rooms ML 페이지에서 기본 데이터를 공유하지 않고 파트너와 기계 학습을 적용하는 방법을 알아보십시오.
자 이제 효과적으로 협업해 보세요!
— Donnie