Amazon Web Services 한국 블로그
Amazon SageMaker와 Apache Airflow을 통한 기계학습 워크플로 구축하기
기계 학습(Machine Learning, ML) 워크플로는 데이터 수집 및 변환을 가능하게 함으로써 ML 작업 순서를 오케스트레이션하고 자동화합니다. 그런 다음 ML 모델을 학습, 테스트 및 평가하여 결과를 얻습니다.
예를 들어 Amazon SageMaker에서 모델을 학습하고 모델을 프로덕션 환경에 배포하여 추론하기 전에 Amazon Athena에서 쿼리를 수행하거나 AWS Glue에서 데이터를 통합하고 준비 할 수 있습니다. 이러한 작업을 자동화하고 다양한 서비스에서 오케스트레이션하면 반복 가능하고 재사용 가능한 ML 워크플로를 구축 할 수 있습니다. 이러한 워크플로는 데이터 엔지니어와 데이터 사이언티스트 간에 작업을 공유할 수 있습니다.
시작하기
ML 워크플로는 모델의 정확성을 높이고 더 나은 결과를 얻기 위해 주기적이고 반복적인 작업으로 구성됩니다. 최근 아마존은 이러한 워크플로를 구축하고 관리할 수 있는 Amazon SageMaker로 통합이 가능한 새로운 기능을 발표하였습니다.
- AWS Step Functions 는 엔드 투 엔드 워크 플로우에서 Amazon SageMaker 관련 작업을 자동화하고 오케스트레이션합니다. Amazon S3에 데이터 세트 게시를 자동화하고 Amazon SageMaker를 사용하여 데이터에 대한 ML 모델을 학습하고 예측을 위해 모델을 배포 할 수 있습니다. AWS Step Functions는 Amazon SageMaker 및 기타 작업이 성공 또는 실패 할 때까지 모니터링하고 워크플로의 다음 단계로 전환하거나 작업을 재 시도합니다. 내장 된 오류 처리, 매개 변수 전달, 상태 관리 및 ML 워크플로 실행시 모니터링 할 수있는 시각적 콘솔이 포함되어 있습니다.
- 많은 고객들이 현재 다중 단계 워크플로를 구성(authoring), 스케줄링 및 모니터링을 위해 오픈 소스 프레임워크인 Apache Airflow를 사용하고 있습니다. 이러한 Airflow와 통합으로 모델 학습, 하이퍼파라미터 튜닝, 모델 배포 및 배치 변환을 비롯한 다양한 Amazon SageMaker 와 함께 통합 운영이 가능합니다. 이를 통해 동일한 오케스트레이션 도구를 사용하여 Amazon SageMaker의 ML 워크플로를 관리 할 수 있습니다.
이 블로그 게시물은 Amazon SageMaker 및 Apache Airflow를 사용하여 ML 워크플로를 구축하고 관리하는 방법을 보여줍니다. 우리는 유사한 동영상을 평가한 고객의 과거 데이터를 기준으로 특정 비디오에 대한 고객의 평가를 예측하는 추천 시스템을 구축할 것입니다. 2백만명 이상의 아마존 고객이 160,000개가 넘는 디지털 비디오 과거에 평가한 별점 평가를 사용합니다. 이 데이터 세트에 대한 자세한 내용은 AWS Open Data 에서 확인할 수 있습니다.
하이-레벨(High-level) 솔루션
먼저 데이터를 탐색하고 데이터를 변환하며 데이터에 대한 모델을 학습합니다. Amazon SageMaker의 학습(Learning) 클러스터를 사용하여 ML 모델을 개발합니다. 그런 다음 테스트 데이터 세트에 대한 배치 예측을 수행하기 위해 엔드 포인트에 배포합니다. 이러한 모든 작업은 Amazon SageMaker와 Apache Airflow를 통합해 오케스트레이션 및 자동화할 수 있도록 워크플로에 연결됩니다.
다음 다이어그램은 추천 시스템을 구축하기 위해 구현할 ML 워크플로를 보여줍니다.

워크플로는 다음 작업을 수행합니다.
- 데이터 전처리: Amazon S3에서 데이터를 추출하고 전처리하여 학습 데이터를 준비합니다.
- 학습 데이터 준비: 추천 시스템을 구축하기 위해 Amazon SageMaker 빌트인 알고리즘인 Factorization machines 를 사용합니다. 이 알고리즘은 현재 Float32 tensor에 포함되는 recordIO-protobuf 형식만 지원합니다. 이 작업에서는 사전 처리 된 데이터가 RecordIO Protobuf 형식으로 변환됩니다.
- 모델 학습: 학습 데이터를 사용하여 Amazon SageMaker 의 빌트인 알고리즘인 Factorization machines 모델로 학습하고 모델 아티팩트를 생성합니다. The training job 은 Airflow Amazon SageMaker operator가 시작하게 됩니다.
- 모델 하이퍼 파라미터 조정: 최적의 모델을 찾기 위해 factorization machine의 하이퍼파라미터를 조정하는 조건/선택 작업을 말합니다. 하이퍼파라미터 tuning job 은 Amazon SageMaker Airflow operator가 시작합니다.
- 배치 추론(Batch inference): 훈련 된 모델을 사용하여 Airflow Amazon SageMaker operator를 사용하여 Amazon S3에 저장된 테스트 데이터 세트로 부터 추론(inferences)을 얻게 됩니다.
참고 : 언급 된 스크립트, 템플릿 및 노트북은 다음 GitHub repo로 부터 clone 할 수 있습니다.
Airflow 개념 및 설정
이 솔루션을 구현하기 전에 Airflow 개념에 익숙해져야 합니다. 만약, Airflow 개념에 이미 익숙한 경우 오퍼레이터(operators) 섹션으로 넘어가도 됩니다.
Apache Airflow는 워크플로 및 데이터 처리 파이프라인을 오케스트레이션하기 위한 오픈 소스 도구입니다. Airflow를 사용하면 Python을 이용해 프로그래밍 방식으로 데이터 파이프라인을 구성, 스케쥴링 및 모니터링하여 일반적인 워크플로 관리 및 라이프 사이클의 모든 단계를 정의 할 수 있습니다.
Airflow 구성 요소
- DAG(Directed Acyclic Graph, 방향성 비 사이클 그래프): DAG는 Python을 이용해 파이프 라인, 즉 코드로 구성을 정의하여 워크플로를 실행하는 방법을 설명합니다. 파이프라인은 독립적으로 실행할 수있는 작업으로 나누어 방향성이 있는 순환되지 않는(유향 비순환) 그래프로 설계되었습니다. 그런 다음 이러한 작업은 논리적으로 그래프로 결합됩니다.
- Operators: Operators는 파이프라인에서 하나의 작업을 표현하는 DAG의 단일 구성 요소입니다. Operators는 DAG가 실행될 때 해당 작업에서 수행 할 작업을 결정합니다. Airflow는 operators를 일반적인 작업을 위해 제공합니다. custom operators 에 의해 사용자 정의가 가능하므로 확장 가능합니다. Airflow Amazon SageMaker operators는 AWS에서 제공하고 있는 Airflow 와 Amazon SageMaker를 통합하기 위한 custom operators 중 하나입니다.
- Task: operators가 인스턴스화 되면 이를 “task”라고합니다.
- Task instance(작업 인스턴스): task instance는 DAG, task 및 시점을 특정하는 작업 실행을 나타냅니다.(Task는 워크플로가 실행하기 전이라면 Task Instance 는 워크플로가 실행된 것을 말합니다.)
- Scheduling(스케쥴링): DAG 및 Task는 요청 시 실행하거나 DAG에서 cron 식으로 정의 된 특정 빈도로 실행되도록 스케쥴링할 수 있습니다.
Airflow 아키텍처
다음 다이어그램은 Airflow 아키텍처의 일반적인 구성 요소를 보여줍니다.
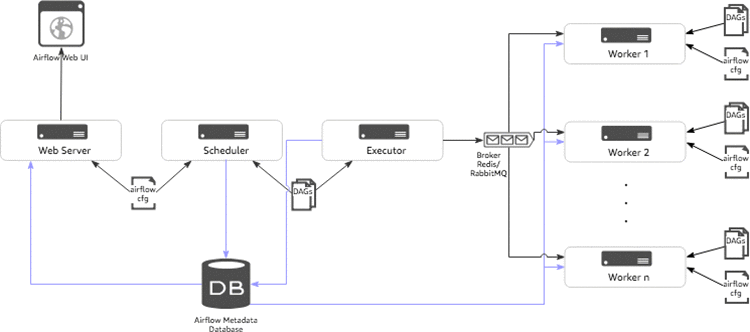
- Scheduler: scheduler는 DAG 및 task를 모니터링하고 종속성이 충족된 task instance를 트리거하는 지속적인 서비스입니다. scheduler는 Airflow의 configuration에 정의된 executor를 호출하게 됩니다.
- Executor: executor는 task instance를 실행하는 방법을 제공합니다. Airflow는 기본적으로 다른 유형의 executor를 제공하며 Kubernetes executor와 같은 custom executor을 정의할 수 있습니다.
- Broker: broker는 메시지를 대기열에 넣고(task가 실행되도록 요청) executor와 worker 간의 커뮤니케이터의 역할을 합니다.
- Worker: task가 실행되고 task의 결과를 반환하는 실제 노드입니다.
- Web Server: Airflow UI를 렌더링하는 웹 서버입니다.
- Configuration file: 사용할 executor의 설정, Airflow의 Metadata database 연결, DAG 및 저장소 위치와 같은 설정을 구성합니다. 동시 실행 및 병렬 처리 제한 등을 정의 할 수도 있습니다.
- Metadata Database: DAGS, DAG의 실행, task, 변수 및 연결과 관련된 모든 메타데이터를 저장하는 데이터베이스입니다.
Airflow-SageMaker 오퍼레이터
Amazon SageMaker operators는 Airflow가 Amazon SageMaker와 통신하고 다음 ML 작업을 수행 할 수 있도록 Airflow 설치와 함께 사용할 수 있는 custom operators입니다.
- SageMakerTrainingOperator : Amazon SageMaker 학습 작업을 생성합니다.
- SageMakerTuningOperator : Amazon SageMaker 하이퍼파라미터 튜닝 작업을 생성합니다.
- SageMakerTransformOperator : Amazon SageMaker 배치 변환 작업을 생성합니다.
- SageMakerModelOperator : Amazon SageMaker 모델을 생성합니다.
- SageMakerEndpointConfigOperator : Amazon SageMaker 엔드 포인트 구성을 생성합니다.
- SageMakerEndpointOperator : 추론을 호출하기 위해 Amazon SageMaker 엔드 포인트를 생성합니다.
이 블로그 게시물의 Machine Learning 워크플로 구축 섹션 에서 operator의 사용법을 확인합니다.
Airflow 설정
scheduler, worker 및 web server가 포함된 단인 인스턴스의 간단한 Airflow 아키텍처를 설정합니다. 일반적으로 프로덕션 워크로드에는이 설정을 사용하지 않습니다. AWS CloudFormation을 사용하여이 블로그 게시물에서 구성 요소를 생성하는 데 필요한 AWS 서비스를 시작합니다. 다음 다이어그램은 배포할 아키텍처의 구성을 보여 줍니다.

스택에는 다음이 포함됩니다.
- Airflow 구성 요소를 설정하기위한 Amazon Elastic Compute Cloud(EC2) 인스턴스.
- Airflow 메타데이터 데이터베이스를 호스팅하기위한 Amazon Relational Database Service(RDS) Postgres 인스턴스.
- ML 워크플로와 함께 Amazon SageMaker 모델 아티팩트, 출력 및 Airflow DAG를 저장하기위한 Amazon Simple Storage Service(S3) 버킷. 템플릿에 S3 버킷 이름을 묻는 메시지가 표시됩니다.
- Airflow 구성 요소가 메타데이터 데이터베이스, S3 버킷 및 Amazon SageMaker와 상호 작용할 수 있도록 AWS Identity and Access Management(IAM) 역할 및 Amazon EC2 보안 그룹.
이 CloudFormation 스크립트를 실행하기 위한 전제 조건은 custom operators를 추가하거나 문제 해결과 같은 Airflow를 관리하기 위해 Amazon EC2 키 페어를 설정해야 합니다.
![]()
CloudFormation 스택이 리소스를 생성하는데 최대 10분이 걸릴 수 있습니다. 리소스 생성이 완료되면 Airflow 웹 UI에 로그인할 수 있어야 합니다. Airflow 웹 서버는 기본적으로 포트 8080에서 실행됩니다. Airflow 웹 UI를 열려면 브라우저를 열고 http://ec2-public-dns-name:8080을 입력하십시오. EC2 인스턴스의 퍼블릭 DNS 이름은 AWS CloudFormation 콘솔에있는 CloudFormation 스택 의 Outputs 탭 에서 찾을 수 있습니다 .
기계 학습 워크플로 구축
이 섹션에서는 Amazon SageMaker operators를 포함한 Airflow operators를 사용하여 recommender를 빌드하는 ML 워크플로를 작성합니다. 함께 제공되는 Jupyter 노트북 을 다운로드 하여 ML 워크플로에 사용 된 개별 작업을 확인할 수 있습니다 . 여기서는 가장 중요한 부분에 대해 강조해 설명합니다.
 데이터 전처리
데이터 전처리
- 앞에서 언급했듯이 데이터 세트에는 160,000 개가 넘는 디지털 비디오에서 2백만 명 이상의 아마존 고객의 평점이 포함되어 있습니다. 데이터 세트에 대한 자세한 내용은 여기를 참조하십시오 .
- 데이터 세트를 분석한 결과, 고객의 5% 정도만 5개 이상의 비디오에 대해 평가했고, 25%의 비디오가 9+ 등급이 평가되었습니다. 레코드에서 long tail 데이터를 정리합니다.
- 정리 후 각 고객과 비디오에 등급 매트릭스의 행과 열을 나타내는 고유한 순차적 색인을 제공하여 데이터를 희소 형식(sparse format)으로 변환합니다. 이 정리된 데이터는 다음 task를 위해 선택 및 처리될 수 있도록 S3 버킷에 저장합니다.
- 다음 Airflow DAG 의
PythonOperator스니펫은 전처리 함수를 호출합니다. - 참고 : 이 블로그 게시물의 경우 데이터 전처리 작업은 Pandas 패키지를 사용하여 Python에서 수행됩니다. 또한 이 작업은 Airflow worker 노드에서 실행됩니다. 이 작업은 대규모 데이터 세트로 작업할 때에는 AWS Glue 또는 Amazon EMR에서 실행되는 코드로 대체할 수 있습니다.
데이터 준비
- 우리는 추천 시스템을 구축하기 위해 Factorization Machines(Amazon SageMaker 상에서)를 사용합니다. 이 알고리즘은 recordIO protobuf 형식으로 Float32 tensors에 저장합니다. 정리된 데이터 세트는 디스크에 Padas DataFrame 입니다.
- 데이터 준비 과정의 일부로 Pandas DataFrame은 고객 및 비디오가 포함 된 원-핫 인코딩(One-hot encoding)된 feature vectors의 희소 행렬(sparse matrix)로 변환됩니다. 따라서 데이터 세트의 각 샘플은 고객과 비디오에 대해 두 개의 값만 1로 설정된 넓게 분포된 부울 벡터(Boolean vector)가 됩니다.
| Cost 1 | Cost 2 | …………… | Cost N | Video 1 | Video 2 | …… | Video m |
| 1 | 0 | …… | 0 | 0 | 1 | …… | 0 |
- 데이터 준비 작업에서는 다음 단계가 수행됩니다.
- 정리된 데이터 세트를 트레인 데이터 세트와 테스트 데이터 세트로 분리합니다.
- 원-핫 인코딩 된 feature vectors(고객 + 비디오)와 별 등급 평가가 있는 레이블 벡터로 희소 행렬을 만듭니다.
- 두 데이터 세트를 protobuf 인코딩 파일로 변환합니다.
- 모델 학습을 위해 준비된 파일을 Amazon S3 버킷에 복사합니다.
- 다음 Airflow DAG 의 PythonOperatorAirflow 스니펫은 데이터 준비 함수를 호출합니다.
모델 학습 및 튜닝
- Airflow Amazon SageMaker Operators를 사용하여 학습 작업(training job)을 시작하여 Amazon SageMaker Factorization Machine 알고리즘을 학습합니다. 아래 방법으로 모델 학습을 수행할 수 있습니다.
SageMakerTrainingOperator를 사용하여 데이터에 적합한 하이퍼파라미터를 설정하여 학습 작업을 실행하는 데 사용합니다.# train_config specifies SageMaker training configuration train_config = training_config( estimator=fm_estimator, inputs=config["train_model"]["inputs"]) # launch sagemaker training job and wait until it completes train_model_task = SageMakerTrainingOperator( task_id='model_training', dag=dag, config=train_config, aws_conn_id='airflow-sagemaker', wait_for_completion=True, check_interval=30 )
-
- SageMakerTuingOperator 를 사용하여 데이터 세트의 하이퍼파리미터 구간을 테스트하는 다수의 job을 실행하여 최적의 모델을 찾는 하이퍼파마리터 튜닝 작업을 실행 합니다.
# create tuning config tuner_config = tuning_config( tuner=fm_tuner, inputs=config["tune_model"]["inputs"]) tune_model_task = SageMakerTuningOperator( task_id='model_tuning', dag=dag, config=tuner_config, aws_conn_id='airflow-sagemaker', wait_for_completion=True, check_interval=30 )
- SageMakerTuingOperator 를 사용하여 데이터 세트의 하이퍼파리미터 구간을 테스트하는 다수의 job을 실행하여 최적의 모델을 찾는 하이퍼파마리터 튜닝 작업을 실행 합니다.
- Airflow DAG에서 조건별 작업을 생성하여 학습 작업을 바로 실행할지, 하이퍼파라미터 튜닝 작업을 실행하여 최상의 모델을 찾는 작업을 실행할 지 결정할 수 있습니다. 이러한 작업은 동기식 또는 비동기식 모드로 실행할 수 있습니다.
branching = BranchPythonOperator( task_id='branching', dag=dag, python_callable=lambda: "model_tuning" if hpo_enabled else "model_training") - 학습 또는 튜닝 작업의 진행 상황은 Airflow Task Instance에 대한 로그에서 모니터링 할 수 있습니다.
모델 추론
- Airflow SageMakerTransformOperator 를 사용하여, 모델 성능 평가를 위한 테스트 데이터 세트에서 배치 추론 수행을 Amazon SageMaker 배치 변환 작업(batch transform job)을 생성합니다.
# create transform config transform_config = transform_config_from_estimator( estimator=fm_estimator, task_id="model_tuning" if hpo_enabled else "model_training", task_type="tuning" if hpo_enabled else "training", **config["batch_transform"]["transform_config"] ) # launch sagemaker batch transform job and wait until it completes batch_transform_task = SageMakerTransformOperator( task_id='predicting', dag=dag, config=transform_config, aws_conn_id='airflow-sagemaker', wait_for_completion=True, check_interval=30, trigger_rule=TriggerRule.ONE_SUCCESS ) - 프로덕션 환경에서 모델을 배포하기 전에 실제 등급과 예측된 고객 등급을 비교하여 모델 성능을 검증하는 작업을 추가하여 ML 워크플로를 확장 할 수 있습니다.
다음 섹션에서는 Airflow DAG에서 ML 워크플로를 형성하기 위해 이러한 모든 작업을 함께 연결하는 방법을 살펴 봅니다.
워크플로 전체 통합하기
Airflow DAG은 위에 ML 워크플로라고 설명한 모든 작업을 통합할 수 있습니다. Airflow DAG는 Airflow operators로 개별 작업을 나타내고, 작업 종속성을 설정하며 DAG에 작업을 연결하여 요청시 또는 스케쥴링 간격으로 실행하는 Python 스크립트입니다. Airflow DAG 스크립트는 다음 섹션으로 구성됩니다.
- 일정 간격, 동시 실행등의 매개 변수를 사용하여 DAG를 설정하십시오.
dag = DAG( dag_id='sagemaker-ml-pipeline', default_args=args, schedule_interval=None, concurrency=1, max_active_runs=1, user_defined_filters={'tojson': lambda s: JSONEncoder().encode(s)} ) - Airflow 용 Amazon SageMaker Python SDK를 사용하여 각 운영자에 대한 학습, 튜닝 및 추론 구성 설정합니다.
- 트리거 규칙을 정의하고 이를 DAG 오브젝트와 연결하는 Airflow operators를 사용하여 개별 작업을 만듭니다.
- 작업에 대한 종속성을 지정하십시오.
init.set_downstream(preprocess_task) preprocess_task.set_downstream(prepare_task) prepare_task.set_downstream(branching) branching.set_downstream(tune_model_task) branching.set_downstream(train_model_task) tune_model_task.set_downstream(batch_transform_task) train_model_task.set_downstream(batch_transform_task) batch_transform_task.set_downstream(cleanup_task)
DAG이 준비되면, CI/CD 파이프라인을 사용하여 Airflow DAG 리포지토리에 배포합니다. 위 Airflow 설정 섹션에 설명된 설정을 따른 경우, Airflow 구성 요소를 설치하기 위해 배치 된 CloudFormation 스택은 추천 시스템을 빌드하기 위한 ML 워크플로가 있는 Airflow instance의 리포지토리에 Airflow DAG을 추가하게 됩니다. Airflow DAG 코드는 이곳에서 다운 받으시기 바랍니다.

요청 또는 스케쥴에 따라 DAG을 트리거한 후 tree view, graph view, Gantt chart, task instance logs 등 여러 가지 방법으로 DAG를 모니터링 할 수 있습니다 . Airflow DAG을 작업하고 모니터링하는 방법 은 Airflow 설명서를 참조하십시오 .
정리하기
이제 마지막 단계로 리소스를 정리하십시오.
AWS 계정에서 불필요하게 과금되지 않으려면 다음을 수행하십시오.
- 테스트를 마친 후 Airflow 설정 상에서 CloudFormation 스택으로 생성 된 모든 리소스 를 삭제합니다. 이곳의 단계에 따라 스택을 삭제할 수 있습니다 .
- AWS CloudFormation에서는 비어있지 않은 Amazon S3 버킷은 삭제할 수 없으므로 CloudFormation 스택에서 생성 한 S3 버킷을 수동으로 삭제 해야 합니다.
마무리
이 블로그 게시물에서 ML 워크플로를 작성하는 데는 약간의 준비가 필요하지만 실험 속도, 엔지니어링 생산성 및 반복적인 ML 작업의 유지 관리 속도를 향상시키는데 도움이 됩니다. Airflow Amazon SageMaker operators는 ML 워크플로를 구축하고 Amazon SageMaker와 통합하는 편리한 방법을 제공합니다.
피쳐 엔지니어링, 앙상블 학습 모델 생성, 병렬 학습 작업 생성 및 데이터 배포 변경에 맞게 모델 재학습과 같이 ML 워크플로에 더 적합한 작업으로 Airflow DAG을 사용자 정의하여 워크플로를 확장할 수 있습니다.
참고 문헌
- Airflow Amazon SageMaker operators 에 대한 자세한 내용은 Amazon SageMaker SDK 설명서 및 Airflow 설명서 를 참조하십시오.
- 이 블로그 게시물에 사용 된 Factorization Machines 알고리즘 에 대해 알아 보려면 Amazon SageMaker 설명서를 참조하십시오 .
- 이 블로그 게시물에 언급 된 리소스 (Jupyter Notebooks, CloudFormation 템플릿 및 Airflow DAG 코드)를 GitHub 리포지토리에서 다운로드하십시오.
함께 읽어 볼 만한 블로그
- Apache Airflow, Genie 및 Amazon EMR을 통한 빅데이터 워크플로 오케스트레이션 – 1부
- Apache Airflow, Genie 및 Amazon EMR을 통한 빅데이터 워크플로 오케스트레이션 – 2부
 Rajesh Thallam은 빅 데이터 및 기계 학습 워크로드를 실행할 수 있도록 돕는 AWS의 전문 서비스 아키텍트입니다. 이 블로그 게시물을 도와 준 동료 인 David Ping과 Shreyas Subramanian에게 감사의 말씀을 전합니다.
Rajesh Thallam은 빅 데이터 및 기계 학습 워크로드를 실행할 수 있도록 돕는 AWS의 전문 서비스 아키텍트입니다. 이 블로그 게시물을 도와 준 동료 인 David Ping과 Shreyas Subramanian에게 감사의 말씀을 전합니다.
이 글은 AWS Machine Learning 블로그의 Build end-to-end machine learning workflows with Amazon SageMaker and Apache Airflow의 한국어 번역으로 AWS한국사용자모임의 김정민님이 번역해 주셨습니다.