Amazon Web Services 한국 블로그
Amazon EMR, Apache Spark 지원 시작
Amazon EMR에서 새로 출시한 막강 기능을 소개하기 위해 제 동료 존 프리츠(Jon Fritz)의 글을 게재합니다.
– Jeff;
![]() Amazon EMR(Elastic MapReduce) 서비스가 Apache Spark를 지원하게 된 점을 알려드리게 되어 기쁩니다. Amazon EMR은 Hive, Pig, HBase, Presto, Impala, 및 그 외 여러가지 하둡 생태계 애플리케이션을 이용하여 방대한 데이타를 처리하기 쉽게 해 드리는 서비스입니다. 스파크(Spark) 또한 이 목록에 공식적으로 추가 시키게 되어 저희 Amazon EMR팀도 기쁘게 생각합니다. 물론 많은 고객들이 이미 예전부터 별도 스크립트를 이용하여 스파크를 설치해 사용해 왔지만, 이제부터는 Amazon EMR 콘솔 또는 CLI, API등을 통해 스파크가 설치된 Amazon EMR을 바로 띄울 수 있습니다.
Amazon EMR(Elastic MapReduce) 서비스가 Apache Spark를 지원하게 된 점을 알려드리게 되어 기쁩니다. Amazon EMR은 Hive, Pig, HBase, Presto, Impala, 및 그 외 여러가지 하둡 생태계 애플리케이션을 이용하여 방대한 데이타를 처리하기 쉽게 해 드리는 서비스입니다. 스파크(Spark) 또한 이 목록에 공식적으로 추가 시키게 되어 저희 Amazon EMR팀도 기쁘게 생각합니다. 물론 많은 고객들이 이미 예전부터 별도 스크립트를 이용하여 스파크를 설치해 사용해 왔지만, 이제부터는 Amazon EMR 콘솔 또는 CLI, API등을 통해 스파크가 설치된 Amazon EMR을 바로 띄울 수 있습니다.
Apache Spark: 차세대 Hadoop MapReduce
저희는 대규모 스케일 데이터 프로세싱과 배치 프로세싱, 비정형 데이타 애드 혹(ad hoc) 분석, 기계 학습 등에서 하둡 맵리듀스(Hadoop MapReduce)를 매우 성공적으로 활용하는 고객 사례를 많이 보았습니다. 이제 하둡 생태계의 새로운 분산처리 프레임워크인 아파치 스파크는 잡(job) 처리성능의 꾸준한 향상과 특정 워크로드의 개발 가속도 등을 통해 매력적인 엔진임을 스스로 증명해 보였습니다.
스파크는 DAG(Directed Acyclic Graph, 비순환 방향 그래프) 실행 엔진을 이용하여 데이타 변환을 위한 질의계획(query plan)을 더욱 효율적으로 만들 수 있습니다. 또한, 스파크는 인메모리(in-memor) 및 무장애(fault-tolerant) 분산 RDD(Resilient Distributed Datasets), 중간 결과값, 입력, 출력을 디스크 대신 메모리에 보관하기 등의 기술도 제공합니다. 이 두 가지 기능 요소로 인해 특정 워크로드에서는 하둡 맵리듀스에 비해 훨씬 우수한 성능을 보여줄 수 있습니다. 하둡 맵리듀스는 잡을 맵리듀스 프레임워크에 순차적으로 들어가도록 강제하고 중간 결과값은 디스크에 저장함으로써 부가적인 I/O를 만들어내기 때문이죠. 스파크의 향상된 성능은 특히 기계 학습과 빠른응답을 요구하는 질의문 등에 흔히 사용하는 인터랙티브 워크로드 (interactive workload)에서 빛을 발합니다. 거기에 더해 Scala, Python, Java API 등을 자체 지원하고 SQL 및 인기 있는 여러가지 기계 학습 알고리듬, 그래프 처리, 스트림 처리 등을 위한 라이브러리도 내장하고 있습니다. 이런 강력한 통합 개발 옵션을 이용하면, 스파크 애플리케이션을 개발하고 운영하는 것이 하둡 맵리듀스 API 위에 얹어 놓은 여러 추상화 계층 위에서 작업하는 것보다 더 간편할 수 있습니다.
Spark on Amazon EMR 소개
오늘부터 Amazon EMR이 아파치 스파크도 지원합니다. 여러분은 Amazon EMR 콘솔 또는 AWS 커맨드 라인 인터페이스(CLI), Amazon EMR API 등을 통해 확장 가능하면서(scalable) AWS가 관리해 주는 스파크 클러스터를 Amazon Elastic Compute Cloud (EC2) 인스턴스 타입 위에 쉽고 빠르게 생성할 수 있습니다. Amazon EMR 컨테이너에서 엔진 구동 시, 스파크는 EMRFS 이점을 활용해 Amazon Simple Storage Service(S3) 데이타 직접 접근하기, Amazon S3에 로그 밀어넣기, 비용을 낮추기 위한 EC2 스팟 인스턴스 등을 이용할 수 있으며, 또한 Amazon EMR에 통합되어 있는 IAM 역할(Roles), EC2 보안그룹 (security groups), S3 저장소 암호화 (server-side 및 client-side) 등의 AWS 보안 기능도 사용할 수 있습니다. 거기에 더해, Amazon EMR에 스파크를 구동하는 데에는 기존에 Amazon EMR을 구동하는 비용 외에 더 추가되는 비용은 없다는 것도 장점입니다.
스파크는 빠른 응답을 위한 스파크 SQL (Spark SQL), 인터랙티브 SQL 질의, 확장가능한 분산 기계 학습 알고리듬을 내장한 독창적인 MLlib 라이브러리, 무장애(resilient) 스트림처리 애플리케이션을 위한 스파크 스트리밍 (Spark Streaming), 그래프 처리용 GraphX 등을 내장하고 있습니다. 또한, 추가적으로 스파크 모니터링이 필요할 때에는 Amazon EMR 위에 강글리아(Ganglia)를 설치할 수도 있습니다. 배치잡이 필요하다면 EMR Step API를 통해 스파크 스텝을 추가하는 식으로 스파크에 워크로드를 보낼 수도 있고, 인터렉티브한 워크플로우가 필요하다면 스파크 API를 이용하거나 클러스터 마스터 노드에서 스파크 셸(Spark Shell)을 통해 직접 질의를 주고받을 수도 있습니다.
고객 활용 사례
오늘 출시 이전부터 이미 많은 고객들이 Amazon EMR 위에 부트스트랩 액션을 통해 스파크를 설치해 사용왔습니다. 몇 가지 사용 사례를 들면:
- 퓰리쳐상을 수상한 일간지인 워싱턴 포스트사는 독자들에게 보여주기 위한 부가 콘텐츠 추천 엔진으로 스파크를 사용합니다.
- 사용자와 지역 비즈니스를 잊는 소비자 애플리케이션인 옐프(Yelp)는 전시 광고 클릭 비율을 높이기 위해 스파크에 내장된 기계 학습 라이브러리인 MLlib를 활용합니다.
- 대형 복합 미디어 정보 회사인 허스트 코퍼레이션(Hearst Corportation)사 미디어 기사 효과와 토픽 트렌드를 실시간으로 보기 원해 200개가 넘는 웹사이트 자산에서 나오는 클릭스트림 데이터를 빠르게 처리하기 위해 스파크 스트리밍을 이용합니다.
- 크룩스(Krux)사는 본사의 데이터관리 플랫폼 제품이 Amazon S3에 저장되어 있는 로그 데이터를 처리할 수 있도록 만들기 위해 스파크를 도입하고 EMRFS (EMR File System)를 활용합니다.
스파크로 분석하기 – 초간단 예제
Spark on Amazon EMR을 이용하여 데이타 처리하기 작업을 얼마나 빨리 시작할 수 있는지 예제를 보여드릴텐데요, 미국 국내 항공편에서 비행편 지연과 취소에 대해 몇 가지 질문을 해보겠습니다.
미국 연방교통국(The Department of Transportation)은 지난 1987년까지의 비행편 정보를 담은 데이타를 공개해 두었습니다. CSV 포맷인 해당 파일을 제가 다운 받아서 컬럼 기반의 Parquet 포맷(좀 더 나은 성능을 보임)으로 변환 시킨 다음에, 누구나 접근할 수 있는 읽기 전용 S3 버킷에 업로드 해두었습니다 (s3://us-east-1.elasticmapreduce/samples/flightdata/input). 데이타 세트는 압축 상태로 4GB 정도 (압축 풀린 상태에서는 79GB) 이고 162,212,419개 행(rows)을 담고 있기 때문에 질의문을 던지려면 스파크 같은 분산 프레임워크를 사용하는 게 합리적입니다. 제가 던지려는 질의는 비행기를 가장 많이 출발 시킨 공항 10개, 15분 이상 항공편이 지연되었던 건수가 가장 많은 공항, 60분 이상 지연되었던 건수가 가장 많은 공항, 비행 취소 건수가 가장 많은 공항 등입니다. 그리고 분기별 항공취소 건수도 궁금하고 가장 인기 있는 경유 공항 10개도 알고 싶네요.
이 질문들을 우선 SQL 질의문으로 작성했구요, 이를 실행하기 위해 스칼라 프로그래밍 언어로 스파크 애플리케이션을 작성했습니다. 코드는 여기서 다운받을 수 있습니다. s3://us-east-1.elasticmapreduce.samples/flightdata/sparkapp/FlightExample.scala 코드 일부를 아래에 발췌 했으니 함께 보시죠.
val parquetFile = hiveContext.parquetFile("s3://us-east-1.elasticmapreduce.samples/flightdata/input/")
//Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("flights")
//Top 10 airports with the most departures since 2000
val topDepartures = hiveContext.sql("SELECT origin, count(*) AS total_departures FROM flights WHERE year >= '2000' GROUP BY origin ORDER BY total_departures DESC LIMIT 10")
topDepartures.rdd.saveAsTextFile(s"$OutputLocation/top_departures")인메모리 RDD 안에 “flights”라는 테이블을 만들고, 각 SQL 질의들은 I/O 비용을 줄이기 위해 이 테이블을 이용한다는 점에 유의해 주세요. 그리고, EMR안에 있는 스파크는 S3 데이타를 HDFS에 복사할 필요 없이 직접 접근하기 위해 EMRFS를 사용합니다. 이 애플리케이션은 제가 JAR로 묶어서 여기에 올려두었습니다 https://s3.amazonaws.com/us-east-1.elasticmapreduce.samples/flightdata/sparkapp/flightsample_2.10-1.3.jar.
이 애플리케이션을 m3.xlarge 노드 세 개로 구성한 Amazon EMR 클러스터에 스파크와 함께 띄워보겠습니다. 샘플 데이터 세트가 미국 동부 리전에 있기 때문에, 클러스터도 해당 리전에서 띄워야 한다는 점 꼭 기억해 주세요. Amazon EMR 콘솔에서 Create Cluster 페이지로 가셔서, Termination Protection과 Logging을 비활성화 시키세요 (Cluster Configuration 항목에 있습니다). Software Configuration 항목으로 내려가서 Additional Application에 스파크(Spark)를 추가하세요.
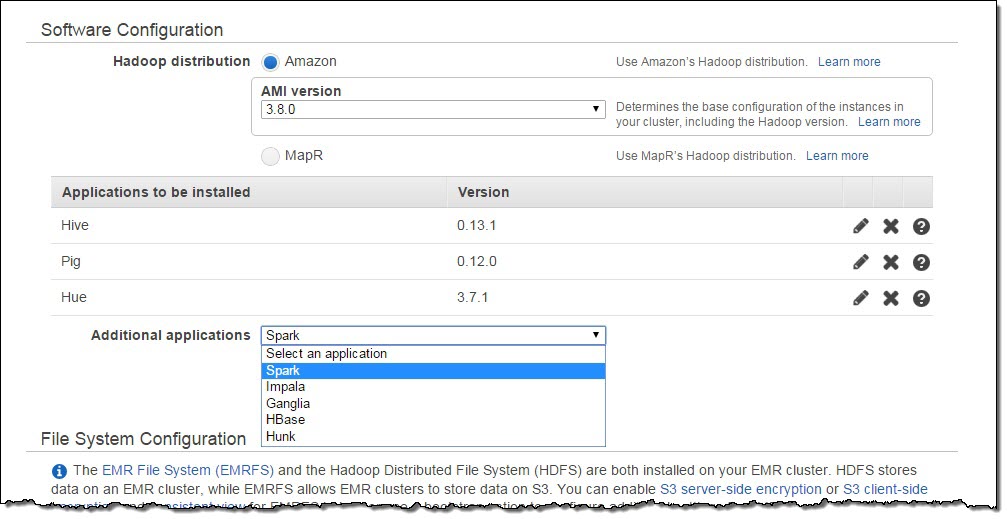
Configure and add를 클릭한 다음에, Arguments 텍스트상자에 -x 를 입력하세요. 이 파라미터는 스파크 익스큐터(executor) 기본설정값을 바꾸는 것인데요, 이 익스큐터가 여러분 애플리케이션을 실제로 수행하는 그 프로세스입니다.
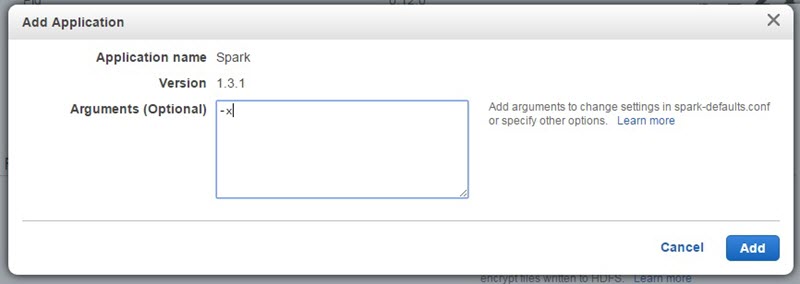
AMI 3.8에 내장된 스파크는 아파치 기본값인 익스큐터 2개와 램(RAM) 1GB로 설정되어 있기 때문에, 여러분의 스파크 애플리케이션을 구동 시킬 때에는 이 설정을 덮어쓰기 해서 클러스터 자원을 더 많이 활용토록 하는 것이 좋습니다. -x는 클러스터 생성 시 만든 코어노드 수 만큼 익스큐터를 생성케 하고, 각 익스큐터마다 RAM과 vcores 값을 해당 코어노드가 허용하는 최대값으로 설정합니다. 실제 잡 수행성능은 익스큐터 설정에 따라 다르기 때문에, 미리 테스트를 해보고 설정 최적값을 찾아보시길 권합니다. 또한, 실제 스파크 수행(Spark-submit) 명령줄에 추가 파라미터를 전달함으로써 이 설정값을 덮어쓰는 것도 가능합니다.
다음으로, 스텝 2개를 추가하기 위해 페이지 바닥쪽에 있는 Steps 항목으로 내려가세요. 첫 번째 스텝에서는 S3에 있는 스파크 애플리케이션 JAR 파일을 클러스터 마스터 노드로 복사할 껍니다. Custom Jar 스텝을 추가하면서 JAR 위치를 s3://elasticmapreduce/libs/script-runner/script-runner.jar로 설정하고 Arguments 텍스트상자에는 /home/hadoop/bin/hdfs dfs -get s3://us-east-1.elasticmapreduce.samples/flightdata/sparkapp/flightsample_2.10-1.3.jar /mnt/를 입력하세요. Action on failure 옵션은 Terminate cluster로 설정한 다음 Add를 클릭하세요.
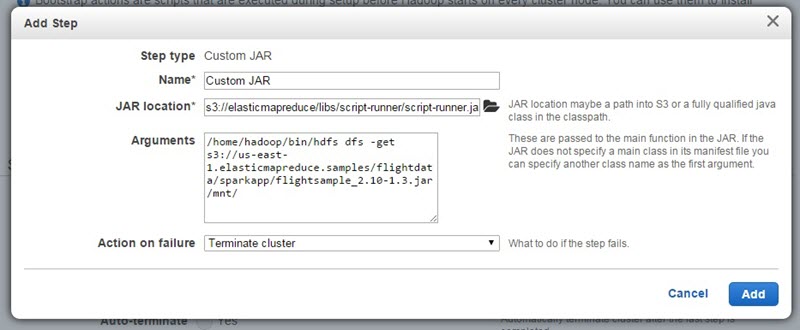
두 번째 스텝으로는 스파크 애플리케이션(Spark application) 스텝을 추가합니다.
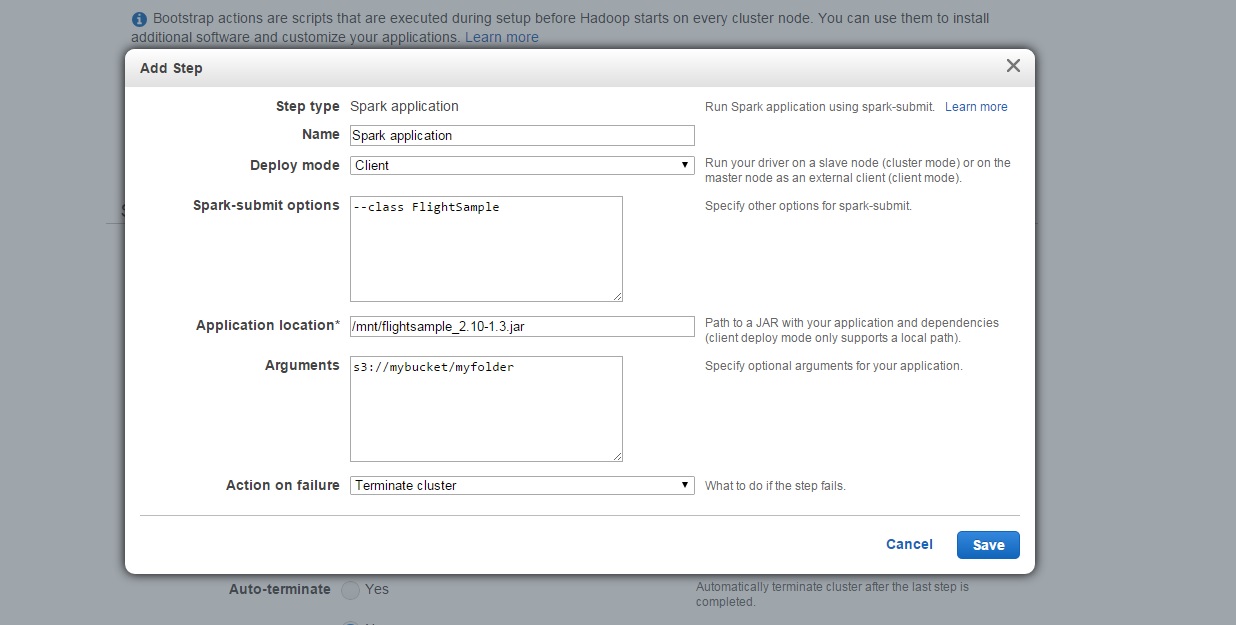
Configure and add를 클릭하면 뜨는 설정 페이지에서 Deploy Mode는 Client를 선택하세요. 이는 애플리케이션을 로컬 경로에서 시작시키기 위함입니다 (첫 번째 스텝에서 S3에 있는 애플리케이션을 클러스터로 복사해 두어야 합니다). Spark-submit options에는 --class FlightSample를 입력하고 Application location란에는 /mnt/flightsample_2.10-1.3.jar를 입력하세요. Arguments에는 스파크 결과값을 저장할 S3 버킷 경로를 집어넣은 다음에, Action on failure는 Terminate cluster를 선택하고 Add를 클릭합니다.
Amazon EMR은 클러스터를 띄우고 여러분의 애플리케이션을 실행한 다음에, 잡(job)이 끝나면 클러스터를 종료(terminate)시킵니다. EMR 콘솔에서 Cluster Details 페이지를 보면 작업의 진행상황을 모니터할 수도 있구요. 일단 작업이 완료되면, 해당 질의문 결과값은 여러분이 지정한 S3 버킷에서 확인할 수 있습니다. 여러분이 직접 해보시도록 여기에 그 결과를 적지 않겠습니다만, 시카고 오헤어 공항을 자주 이용하신다면 꼭 한 번 이 예제를 돌려보세요.
오늘 바로 Amazon EMR 클러스터에 스파크를 얹어서 띄워보세요!
Spark on Amazon EMR에 대한 더 자세한 내용은 Spark on Amazon EMR 페이지를 방문해 보시기 바랍니다..
존 프리츠(Jon Fritz), AWS 시니어 제품 매니저
이 글은 New – Apache Spark on Amazon EMR의 한국어 번역으로서, 미국 AWS 프로페셔널 컨설턴트로 일하고 있는 이종남님께서 수고해 주셨습니다.