- AWS Solutions Library
- Guidance for Automated Restore and Copy for Amazon S3 Glacier Objects
Guidance for Automated Restore and Copy for Amazon S3 Glacier Objects
Overview
How it works
Automated Archive Restore with S3 Batch Operations Copy
The first architecture is an overview that shows you how to request restoration of archived objects with Amazon S3 Batch Operations and copy using Batch Operations Invoke Lambda.
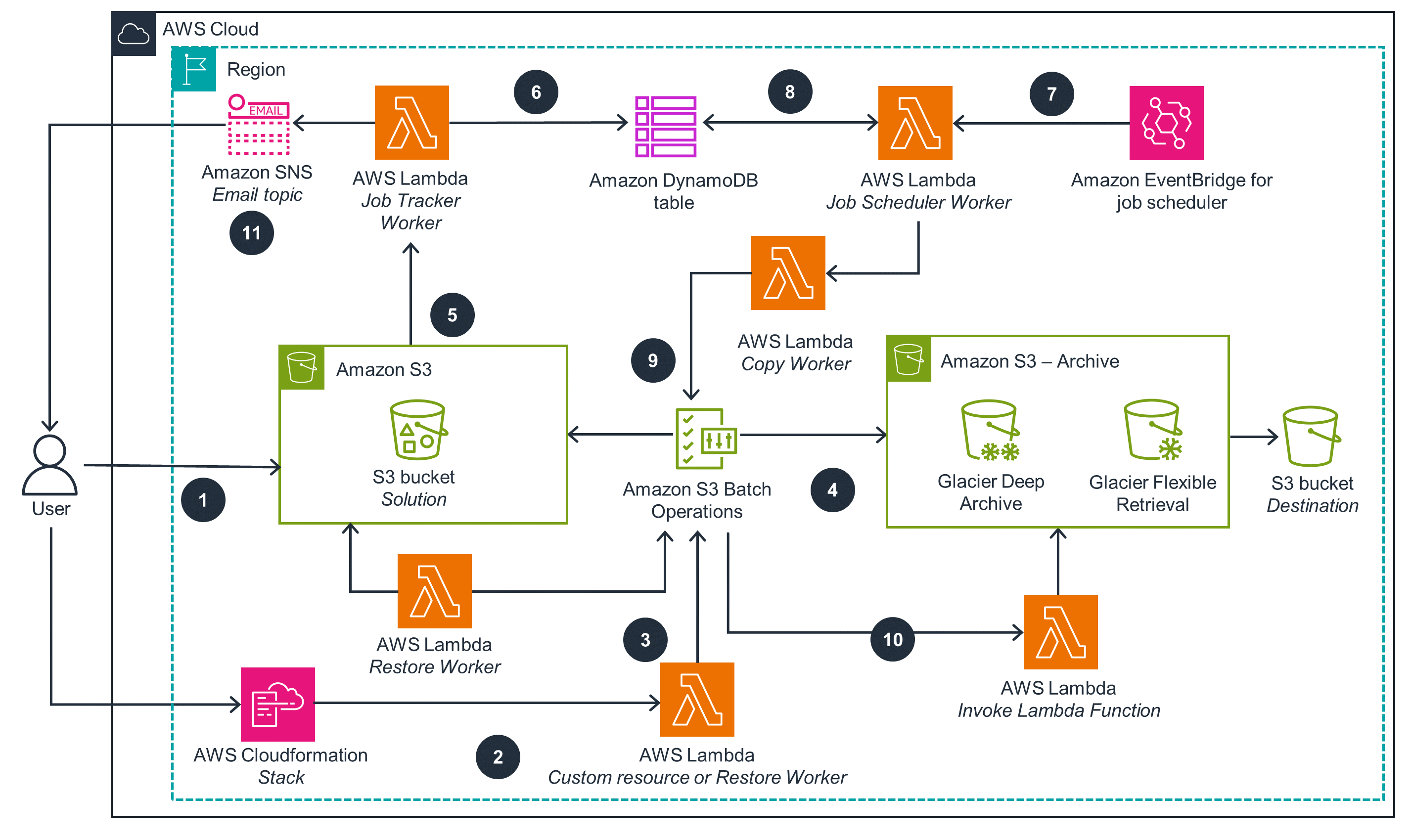
Automated Archive Restore with Event Driven Copy
The second architecture shows restoration of archived objects with Amazon S3 Batch Operations and event driven copy.
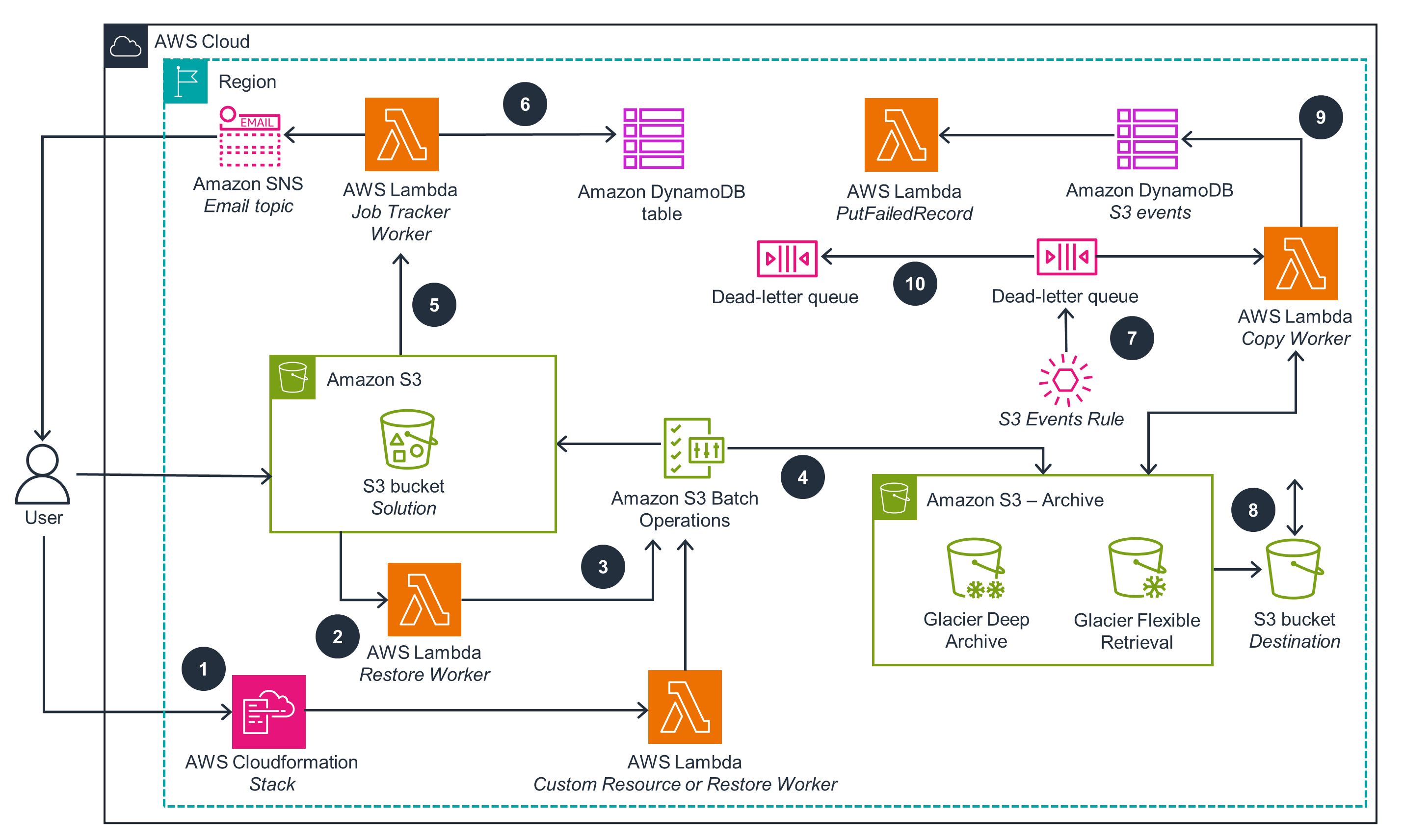
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
This Guidance can be re-deployed using the AWS CloudFormation template. The solution includes an SNS notification function that provides job status and failures.
Data stored in DynamoDB and Amazon S3 are protected by default through AWS encryption. By default, S3 buckets have access control lists (ACLs) disabled and public block access enabled.
Step Functions has retry and exponential back-off enabled to retry the Lambda functions it invokes. Step Functions states in the Guidance implement a retry and back-off mechanisms. Amazon S3 Batch Operations also retries Lambda service-related errors. Additionally, AWS Software Development Kits (SDKs) used in the Lambda functions have default retry and back-off configuration.
Amazon S3 Batch Operations is designed to manage large-scale operations. Lambda functions automatically scale to handle the number of concurrent invocations. You can enable provisioned capacity for DynamoDB which will reserve sufficient system resources to meet your requirements.
S3 Glacier provides multiple options for archive retrieval, including bulk retrieval, the lowest cost option that allows you to retrieve petabytes of data within 5-12 hours. S3 Glacier Flexible Retrieval provides free bulk retrieval for archived items that you’d want to retrieve infrequently, such as 1-2 times a year. Additionally, Amazon S3 Batch Operations allows you to manage billions of objects at scale without the need to provision costly and complex compute.
Amazon S3 Lifecycle rule is applied to the guidance S3 bucket to have objects expire after 180 days. The solution DynamoDB items are set to expire 60 days after restore and copy job completion. Automating expiration helps you avoid unnecessarily using storage resources for items that you no longer need.
Implementation resources
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages